All Activity
- Past hour
-

Creating Strictly Typed VI References Without A Saved VI
bessire replied to bessire's topic in LabVIEW General
I did see that "Save:To Buffer" method. I also haven't seen a method for loading the output of that. All of the VI server methods I've seen so far have required a file path. I have only briefly looked at the ones visible on an invoke node with a lot of extra ini tokens, so there are probably some deprecated or hidden ones to go through still. I looked through all of the Call Library Function Nodes in code shipping with LabVIEW 2025 and a few extra modules, but nothing seemed promising. The Application Builder code has some interesting calls but I think they only work with a built application, which I haven't tried. There are some other methods in various DLLs that do seem promising such as "NormalVILoadProc", "NormalVIInitProc", and "NormalVIDisposeProc", I just don't know how to call them yet. I'll take a look at all of the property and invoke nodes next, but I doubt there's anything exposed there that doesn't involve passing in a file path. - Today
-
 Literally never. Which is why I value your input into the community so much. (No sarcasm intended). Would love to sit down and have a few beers/coffee sometime and muse about the state of many things LabVIEW-ish and other stuff.
Literally never. Which is why I value your input into the community so much. (No sarcasm intended). Would love to sit down and have a few beers/coffee sometime and muse about the state of many things LabVIEW-ish and other stuff. -
 When have you known me to have a weak opinion? If you have to have a consortium to manage it and spawn an entire industry in order to use some code then it has just become a means to justify an ends. Wizards and scripting are symptoms of excessive boiler-plate generation, lack of reusability and, even worse, trying to hide it. I'm not against frameworks, per say, and In that respect I would argue that DrJPowells solution is the best of the bunch although it uses the OpenG tools heavily so it is not usable to me. By the way. I don't have a personal framework as such. Services are communicated to and from with messages and all messages are strings. You don't need lots of framework for that-just a couple of VI's in a polymorphic. The Services themselves can be anything you like, as long as it works - choose your poison! They come up with this kind of "solution" every few years and then run with it until it the next thing. First it was State Machines, then QMH, then it was Actor Framework. Oh and what about that silver bullet of Systems Software that I can never remember the name of? It's all "One Ring" software. In current years it seems to be this special QMH with knobs on (and committees, working groups and special events that everyone can go to to pat each other on the back). The sales pitch is usually that "this" framework will mean interns churn out the code of 20 year experienced CLAD's. It never does, of course. It always ends up as bug ridden 10,000 VI monstrosities that take 10hrs to compile. They've been trying to replicate experienced programmers' outcomes with processes for over 50 years. It has been such a failure (the philosophy rather than any individual framework) they had to convince everyone that continuous updates were the answer. To paraphrase the words of a wittier person than I, "If the milk turns out to be sour, I ain't the kinda pussy to drink it."
When have you known me to have a weak opinion? If you have to have a consortium to manage it and spawn an entire industry in order to use some code then it has just become a means to justify an ends. Wizards and scripting are symptoms of excessive boiler-plate generation, lack of reusability and, even worse, trying to hide it. I'm not against frameworks, per say, and In that respect I would argue that DrJPowells solution is the best of the bunch although it uses the OpenG tools heavily so it is not usable to me. By the way. I don't have a personal framework as such. Services are communicated to and from with messages and all messages are strings. You don't need lots of framework for that-just a couple of VI's in a polymorphic. The Services themselves can be anything you like, as long as it works - choose your poison! They come up with this kind of "solution" every few years and then run with it until it the next thing. First it was State Machines, then QMH, then it was Actor Framework. Oh and what about that silver bullet of Systems Software that I can never remember the name of? It's all "One Ring" software. In current years it seems to be this special QMH with knobs on (and committees, working groups and special events that everyone can go to to pat each other on the back). The sales pitch is usually that "this" framework will mean interns churn out the code of 20 year experienced CLAD's. It never does, of course. It always ends up as bug ridden 10,000 VI monstrosities that take 10hrs to compile. They've been trying to replicate experienced programmers' outcomes with processes for over 50 years. It has been such a failure (the philosophy rather than any individual framework) they had to convince everyone that continuous updates were the answer. To paraphrase the words of a wittier person than I, "If the milk turns out to be sour, I ain't the kinda pussy to drink it." - Yesterday
-
Phew that is a pretty strong opinion! Although I personally am not a fan of the overall style of DQMH none of my problems are with the scripting/wizards or placeholder text. I think any framework that tries to do "a lot" will be complicated... your own personal framework (which you likely find trivial to use) is likely to be a bit weird to others. DQMH is extremely popular for a reason... To paraphrase the words of a wiser person than I, "please don't yuck someone elses yum"
-
 hotaru805886 joined the community
hotaru805886 joined the community -
 luoxl joined the community
luoxl joined the community -
Any framework that needs scripting, wizards and inserts comments for you to update it; isn't worth the diagram space it consumes.
-
 BYU joined the community
BYU joined the community -
 Yes, I actually like the DQMH, but I haven't gotten used to it and am still learning. My goal is to rewrite all the apps in the DQMH framework eventually. I have a long way to go, though. Cheer, M
Yes, I actually like the DQMH, but I haven't gotten used to it and am still learning. My goal is to rewrite all the apps in the DQMH framework eventually. I have a long way to go, though. Cheer, M - Last week
-
@Mahbod Morshedi no need to apologise at all. This is a journey for everyone and all the opinions here are given with absolute kindness in mind, just sometimes the message gets lost in text. If you add new features to your application, there is no need to make a new wire. Assuming you have some kind of core cluster you would just have a single wire through the whole application and you can add new stuff into this cluster. Now, that will start to get clumsy at some point (when it reaches what we sometimes call "megacluster" status). To prevent this from happening it is normally better to try partition your application into independent things, (loops) that contain just the data they care about. Then each thing becomes simpler. Then you need to figure out how to communicate between these things and you go down a rabbit hole. Have you looked at one of the popular frameworks like DQMH?
-
 aaha20 joined the community
aaha20 joined the community -
 Abrahamx2 joined the community
Abrahamx2 joined the community -
 Mi9D joined the community
Mi9D joined the community -
 YYFW joined the community
YYFW joined the community -
Hi All, Thank you for all the help and helpful comments: 1 - You all were correct about redefining variant attributes. I realised that, and good god, it is easier to use. 2- For the polymorphic VIs, I appreciate the primitive data form of the polymorphic instance. However, I am a scientist in the lab, developing several software programs that facilitate the acquisition, display, processing, and exporting of data from various equipment and experiments. Since I am just learning all these tools and admittedly not a very good programmer, I occasionally make a tweak or add a new feature. Then I realise, 'Oh well, I need this extra data cluster for backup data, and it has to be labelled...' In cases like this, a new data wire is created, and it is too much of a hassle to go back and fix things, add a new terminal, or change VIs to deal with this new data type or to accommodate this new wire. That made me look into variants and consider a single wire to rule them all. However, to extract the data (Unique clusters or any other types), I thought it would be best not to have to modify any VIs. I imagine I make a polymorphic VI, so for any new thing I want to add, I have to copy the same VI and change the data type of the variant to 'data'. I hope that clarifies my intention. I agree that my lack of understanding of the correct procedures and jargon can cause a lot of headaches for you guys, and I apologise. Cheers, M
-
 Cesar Mompar joined the community
Cesar Mompar joined the community -
 That's what I mean: I think it should be a LabVIEW primitive for built-in types. There is no error passing so if the input variant if of the wrong type, you get the default type, but that's fine for my purpose. I am supposed to know what I am doing when I lay down my wires, right?
That's what I mean: I think it should be a LabVIEW primitive for built-in types. There is no error passing so if the input variant if of the wrong type, you get the default type, but that's fine for my purpose. I am supposed to know what I am doing when I lay down my wires, right?
-
 jdzxgsfd joined the community
jdzxgsfd joined the community -
yes but I think X means creating polymorphic instances for all the unique typedefs/clusters inside, so not just the normal primitives that you can create once and forget about.
-
 arashed07 joined the community
arashed07 joined the community -
I think you'll find the polymorphic VI is used to get the data back out again. One of the issues with LV is that it's very easy to get data into a generic form but it's a bugger getting it back out again due to strict typing. I used the polymorphic method for reconstitution when I created a JSON parser that encoded to string (the ultimate variant) and one chose a polymorphic instance as to how you wanted it back out (string, U64, DBL etc).
-
 I have this .vi that uses a multiple tasks, and recordings are saved into separate files for each tasks. Each task is meant to be recorded with different acquisition rates. From data postprocessing I realized that each task data are not time-synced. Is there any quick solution to fix this issue with my .vi? RR_Trigs_1.vi
I have this .vi that uses a multiple tasks, and recordings are saved into separate files for each tasks. Each task is meant to be recorded with different acquisition rates. From data postprocessing I realized that each task data are not time-synced. Is there any quick solution to fix this issue with my .vi? RR_Trigs_1.vi -
yup, completely agree with this ^^^^ I have done something similar in the past where I used a global variant as a data store, and then used attributes to store/get data (and some convenience VIs to convert to the known types). It was a bit of an experiment in a system that had many data generators (different interfaces to independent pieces of hardware) and several hundreds of data variables (tags) all communicated over OPC-UA, so had a fairly sophisticated method to set/get by name as I didn't want to deal with such a mega-cluster anywhere. It worked fine, but in the end I would not really recommend it for simple systems where you just dont want to make the proper data types.
-
You are reinventing variant attributes and the corresponding primitives (see my post above). This being said, there is a lot of things to be commented on your code from a G-style point of view :-) but I'll leave that to others. As far as wrapping the Variant to Data primitive into a polymorphic VI, see my comment above as well. A nicety, but is this really worth the hassle? I have done that myself for a few common types (numerics, string, path, and array of such) and I find that very handy, but I wouldn't bother for types I use occasionally, and in particular, application-specific types. Just my opinion.
-
Is it possible to use TestScript as a type of test sequencer in LabVIEW where the UI can display the 'script', which would be python code, and be able to run in single step mode or at least be able to highlight the current python line being executed.
-
 I am fairly new to source control in general and am trying to get git integrated with LabVIEW and am using TortiseGIT on my machine. I saw the pinned post about "run this script and things will be set up for ya" regarding LV Compare/merge, but it didn't work for me, so I am manually adding in the file extensions to TortiseGIT and I ran into a bit of a snag that I wanted to get some input on. I have LV 32 and 64 bit installed on my PC and am unsure how to handle adding in LV Compare/Merge. I say this because, as far as I am aware, TortiseGIT can only run 1 program per file type. When talking with ChatGPT about it, ChatGPT recommended making a script that checks the file's "bitness" then running the correct version of LV Compare/Merge and use that script as the "program". To me, it makes sense, but I also do not know what I do not know. I wanted to see if other people have run into this issue and what their solutions were. If it's a "google it" thing, can I get some direction regarding what I should be searching for? I don't mind putting in the legwork to learn, but I also don't know where to start with this issue and I've been flailing around in the dark for a bit and it's getting super frustrating. Thanks.
I am fairly new to source control in general and am trying to get git integrated with LabVIEW and am using TortiseGIT on my machine. I saw the pinned post about "run this script and things will be set up for ya" regarding LV Compare/merge, but it didn't work for me, so I am manually adding in the file extensions to TortiseGIT and I ran into a bit of a snag that I wanted to get some input on. I have LV 32 and 64 bit installed on my PC and am unsure how to handle adding in LV Compare/Merge. I say this because, as far as I am aware, TortiseGIT can only run 1 program per file type. When talking with ChatGPT about it, ChatGPT recommended making a script that checks the file's "bitness" then running the correct version of LV Compare/Merge and use that script as the "program". To me, it makes sense, but I also do not know what I do not know. I wanted to see if other people have run into this issue and what their solutions were. If it's a "google it" thing, can I get some direction regarding what I should be searching for? I don't mind putting in the legwork to learn, but I also don't know where to start with this issue and I've been flailing around in the dark for a bit and it's getting super frustrating. Thanks. -
So I have been given this monster FPGA project to patch. The main target VI is a monster with a BD of 9034x10913px, with 72 different loops . Yes there is some documentation an comments, but that does not really cut it. The logic uses I haven't counted how many tens or hundreds of different FIFOs and memory locations, read and written by this or that loop of the hyerarchy. Why, Why, don't I have a"Find all instances" for FIFOs , like there is for VIs, to navigate them?
-
 Maybe the question is if you have to be committed to this array of clusters of string+variant for some specific reason, or if it is an attempt to implement some architecture which might have a different implementation. I.e., I don't understand if yours is a general question about design, or a specific question about the mechanics of converting variants to data.
Maybe the question is if you have to be committed to this array of clusters of string+variant for some specific reason, or if it is an attempt to implement some architecture which might have a different implementation. I.e., I don't understand if yours is a general question about design, or a specific question about the mechanics of converting variants to data. -
Hi All, this is the VI I am using. Maybe it will be more clear this way. Cheers, M Data Tag.vi
-
Without getting into it too much , big picture , how limited would we be with PXIe and Base ?
-
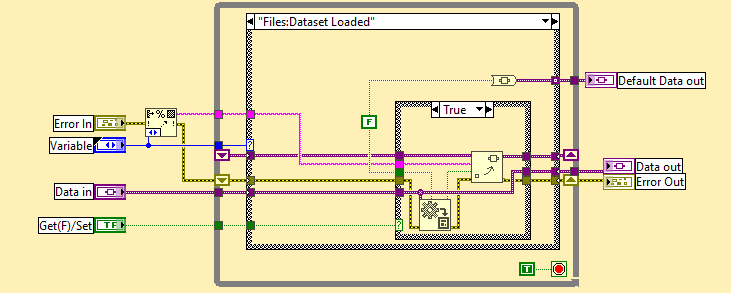
Maybe the OP is trying to achieve a generic storage container (functional global of sort) using a variant. Something akin to this: Here I am using a typedef enum (Variable) to ask for a specific item, which is stored as an attribute of a single variant. There is no need to use a DVR to avoid copies of the variant (if that is the concern), as the only thing which is needed is a copy of the accessor VI (shown above) wherever a variable is needed. There is no need to bother with a polymorphic VI as the output variant is of the requested type and will easily convert to the right type of wire with the drop of Variant to Data primitive, as long as the resulting wire is connected to a terminal. If not (for instance it is connected to a numeric primitive), then yes a polymorphic wrapper VI might be neat (but still a lot of work). When adding a new attribute, simply modify the Variable typedef and add a case. No VI should break. The only drawback of this approach is that that VI has to be non-reentrant and therefore, wherever it is used, this will interfere with parallelism. This can be to some extent avoided with DVR read action, which might be the reason the OP chose that approach. My 2 cts.
-
Well then I don't get the question I suppose.
-
Looking at the example of the OP, it looks he's already aware of typedefs. To him to say what exactly he meant.
-
Have you looked into typedefs? This solves the problem of VIs breaking if you modify the data structures as there is then only a single instance of the definition of a data type.
- Earlier
-
Thank you, Neil and Enserge, I agree with you; however, while preparing my app, I realised that every time I needed to add a new function, I had to change data types or add a new cluster, which led to VIs breaking. This was the only solution I could think of to be compatible with every wire time in the terminals. Cheers

.thumb.jpg.5d2ee2fea691c9fe3fab4270ba8e531d.jpg)