

Mark Smith
-
Posts
330 -
Joined
-
Last visited
-
Days Won
5
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Mark Smith
-
-
QUOTE (NeilA @ Apr 3 2009, 12:11 PM)
It does indeed, a great write, up thank you very much for taking the time. It clarifies what I worked out today and more. I was uncertain about the internecine avoider.vi, I even had to look the name up on google lol. However after doing some investigating I see that it just negates any TCP port issues, is that correct?I am going to try and investigate the implementation next week after the weekend, if I have any good progress and come up with anything useful to others I will post it up.
Many Thanks,
Neil.
The internecine avoider (I had to look up as well) is from the \vi.lib\Utility\tcp.llb and is part of LabVIEW - as far as I can tell it just prevents two services from listening on the same port since then you wouldn't have any control over which service actually got the connection. There's some other interesting stuff in that llb, as well.
And if you get something useful, please post it! I'm always learning from the code available here on LAVA.
Mark
-
QUOTE (NeilA @ Apr 3 2009, 03:33 AM)
This is the thing, I have the request and response templates for each of the 10 or so methods that will be used. I have already made methods for decyphering the xml in the soap body when used with my SOAP to REST conversion and REST LV invocation. I have written a robust client for the methods in the other direction so, I am familiar with SOAP messaging. Therefore it is literally a server. I dont need a template etc. it will be just (for now) an implementation for this system with methods that map to an older messaging system so we know that the messages are mature and unlikely to change drastically in the future.QUOTE (NeilA @ Apr 3 2009, 03:33 AM)
The problem I had was with the incoming TCP connection, but after looking at your server I see that you use a producer consumer pattern to dequeue TCP references. Is it possible to explain a bit further what you are doing in the server vi? Is there any particular reason that you use the set server vi (I have not seen this before)?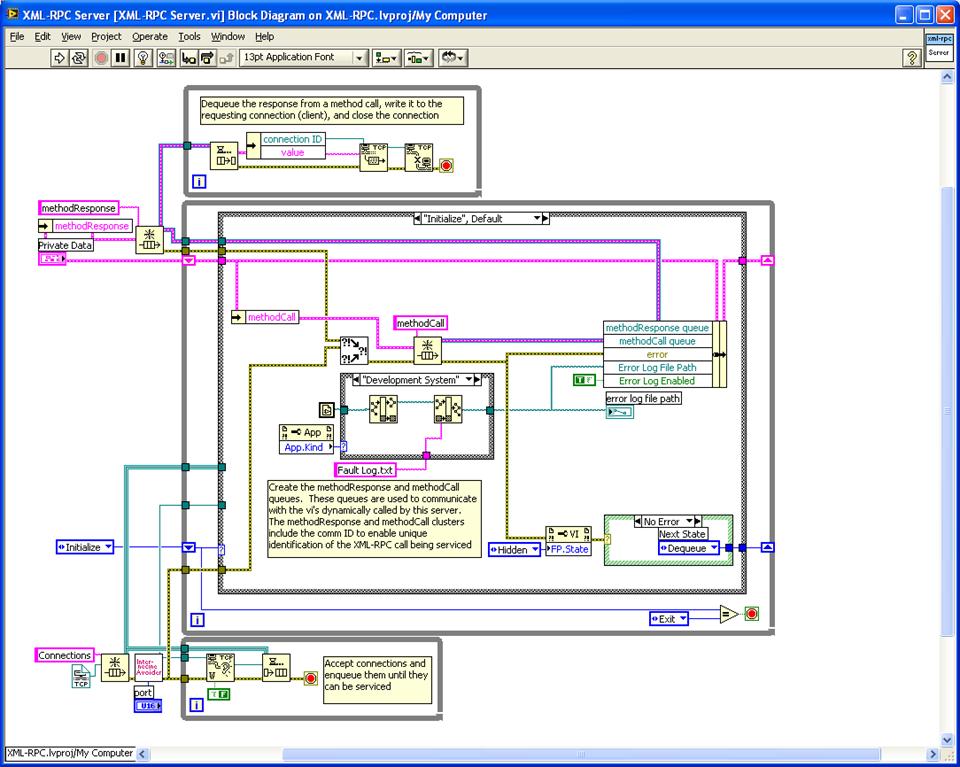
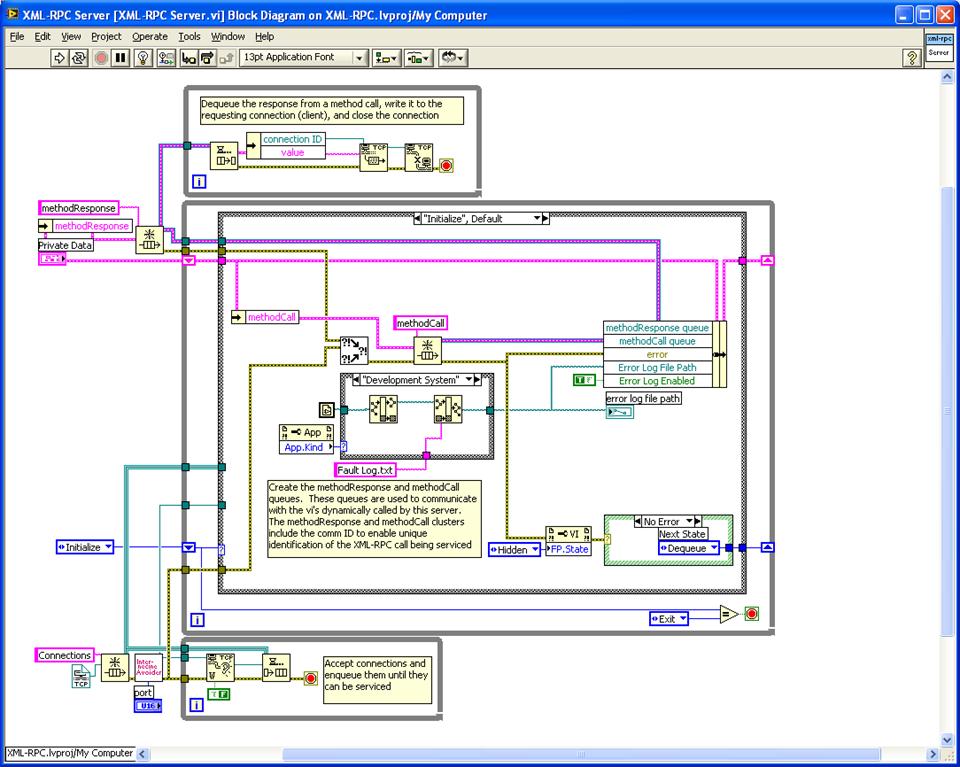
Initialize: The server VI creates a queue for connections and opens a listener with the Wait on Listener - whenever a new connection is accepted, it gets dequeued in the "Dequeue" case. The initialize also creates queues for the message request and the message response and establishes a path for the Fault Log and hides the front panel. Queuing up the connection requests means that the server can service those requests even if they come faster than the methods requested can respond.
Transitions to Dequeue or Error
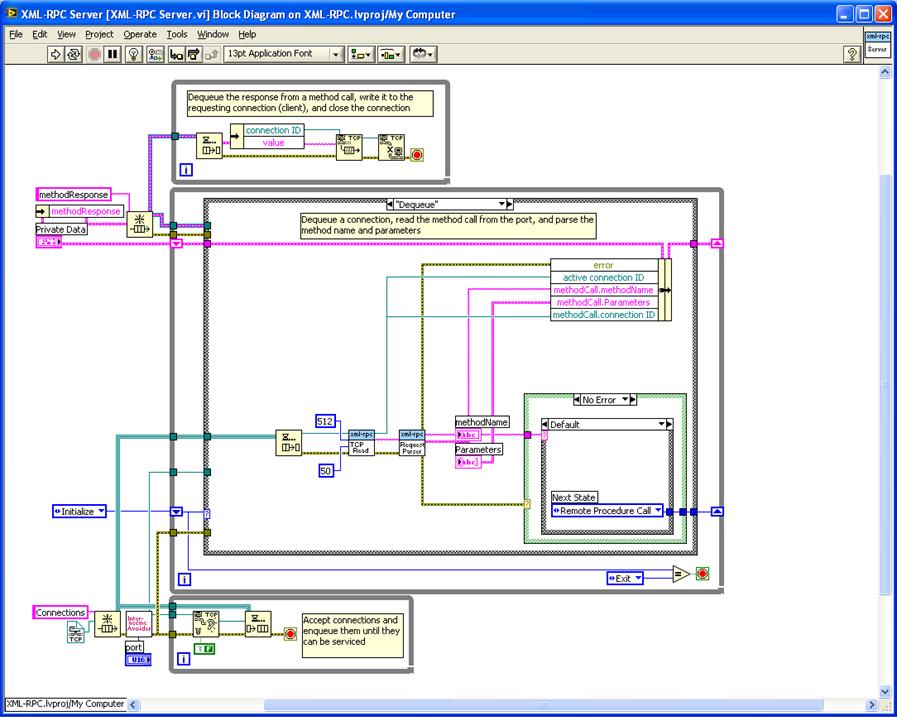
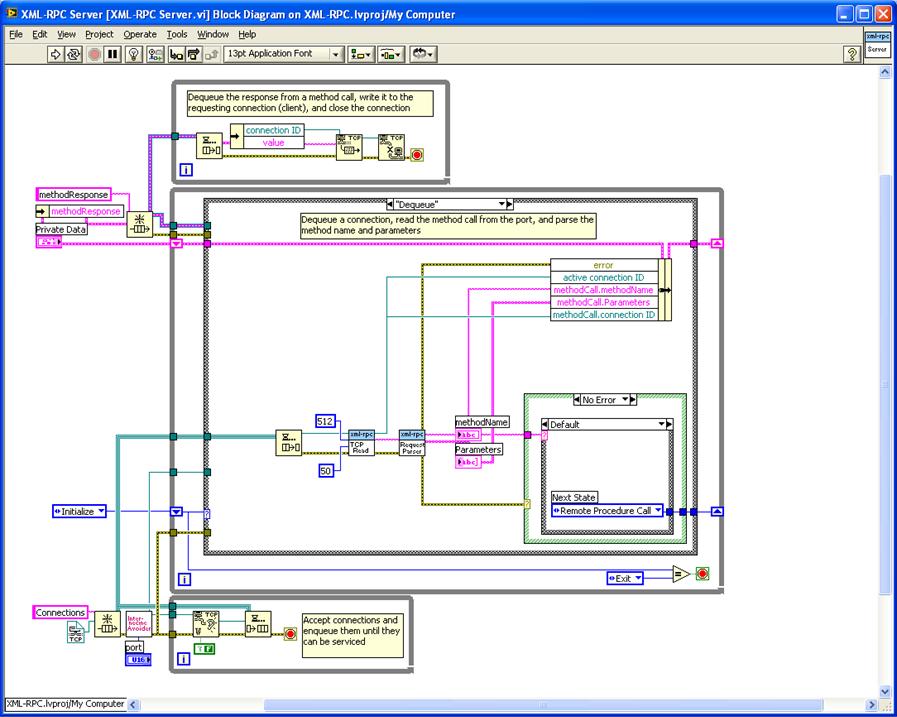
Dequeue: In this case, a connection gets dequeued and the TCP Read All reads the data from that connection. Inside the TCP Read All the logic is to read enough of the HTTP header to make sure you get the "Content-Length" field and use that value to make sure you've retrieved the entire message (or timed out or gotten an indication the client has closed the connection) before you stop reading. Now you should have a complete XML-RPC method invocation message in HTTP - in your case, you should have a complete SOAP invocation. Now, the message gets passed to the XML-RPC Request Parser that checks that it is a valid Method Call and if it is it parses out the method name (in this implementation, the method name is the VI that will get called) and the parameters (if any) that get passed to the VI. Here's where you would parse your SOAP invocation into the VI that will service the request and the parameters to pass.
Transitions to Remote Procedure Call (if the message is a Method Request) or Server State or Exit (if the message is from the Set Server VI) or Error
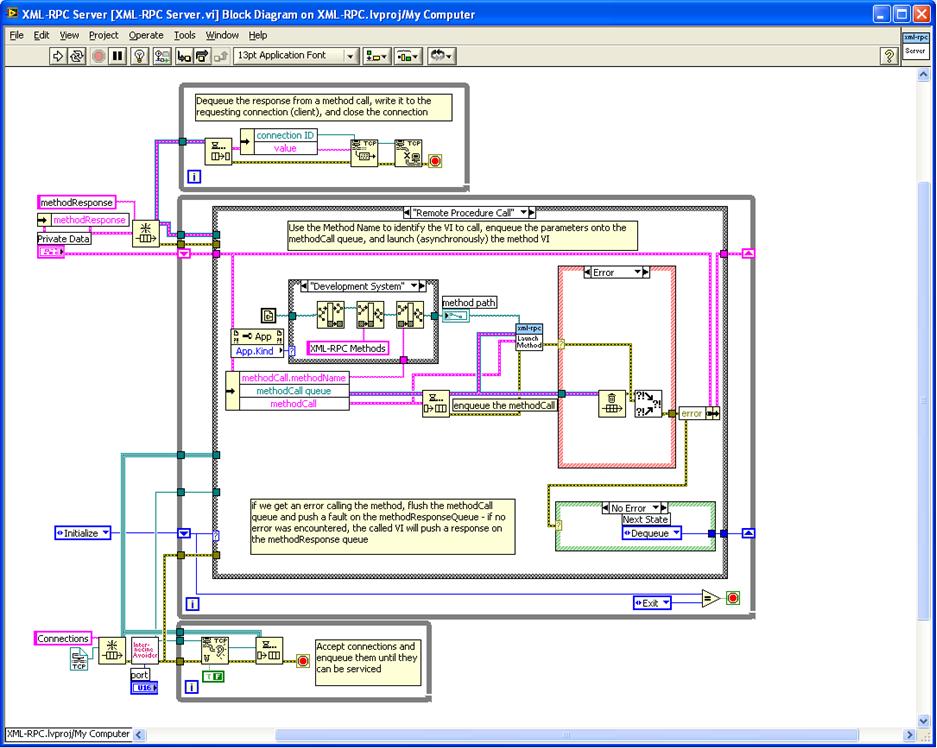
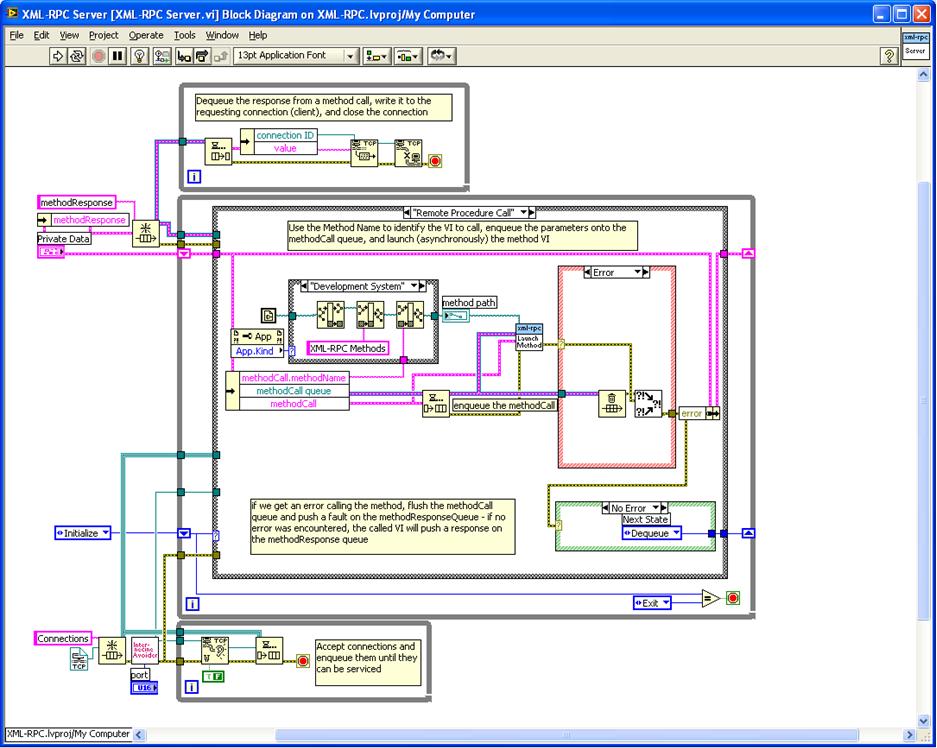
Remote Procedure Call: In this case, as documented on the diagram, we use the Method Name to identify the VI to call, enqueue the parameters onto the methodCall queue, and launch (asynchronously) the method VI. If we get an error calling the method, flush the methodCall queue and push a fault on the methodResponseQueue - if no error was encountered, the called VI will push a response on the methodResponse queue. The MethodResponse will have a connection ID the identifies which connection made the request and expects the response. When the MethodResponse gets put on the queue it's already a fully formatted XML-RPC Response. The called VI is responsible for wrapping the response in the XML-RPC Response format.
Transitions to Dequeue (to wait for the next request) or Error
The Server State case just responds to commands form the Set Server VI, the Error case converts errors to XML-RPC faults (reported to the caller) and logs faults to file, and the Exit case just cleans up on the way out.
The Set Server State VI exists because the Server runs "headless" - no front panel. If you want to open the server front panel or stop it or change the debug level, you need this UI component - or you could pass it the appropriate XML-RPC method call from any client. But you can start the server directly and never use the Set Server State if desired.
Hope this helps!
Mark
-
QUOTE (NeilA @ Apr 2 2009, 12:00 PM)
I have made some methods that I invoke using REST. I have been helped to write a C# layer that converts SOAP calls to REST URI (long story , my team decided on SOAP over a year ago before I worked here, and that is that) any way I had a lot of trouble importing SOAP WSDL to do some calls back the other way so I built my own client using string manipulation and TCP vi's to send calls and collect the responses (these work well so far). This got me to thinking about making my own server! I was wondering if I could use a similar technique to the XML-RPC work in the code repository. There are similarities between the two protocols that make me think it could be possible. It sounds like hard work but my soap to REST implementation is a bit dodgy and I really don't like the way that I cant debug the methods through the calls as they are run in memory in a different instance.
, my team decided on SOAP over a year ago before I worked here, and that is that) any way I had a lot of trouble importing SOAP WSDL to do some calls back the other way so I built my own client using string manipulation and TCP vi's to send calls and collect the responses (these work well so far). This got me to thinking about making my own server! I was wondering if I could use a similar technique to the XML-RPC work in the code repository. There are similarities between the two protocols that make me think it could be possible. It sounds like hard work but my soap to REST implementation is a bit dodgy and I really don't like the way that I cant debug the methods through the calls as they are run in memory in a different instance. I had the REST implementation working fine but after making the SOAP client I found I needed a lot of tidying in my project and the REST implemention has not worked since. This is what once again highlighted the the debug issue when using REST. I would like to keep it simple by implementing my own server for SOAP and be done with aditional layers etc. The problem here is I had trouble after tidying the project what could happen after building an executable and moving machines etc. for the additional time spent now I may have a better more robust deliverable later.
So, has anyone had similar experiences with REST and application instance issues( I was helped out a lot by guys on here before and followed the steps that were given to me then but to no end this time)? Has any one attempted to write there own SOAP Server? Do you think it may be possible to use some of the XML-RPC ideas to get a SOAP server running?
Thanks in advance!
Neil.
Neil,
As the developer of the XML-RPC LabVIEW server, I thought I'd throw in my two cents worth. First, I am not any kind of expert on web services, either SOAP or the RESTful protocol the LV 8.6 Web Server uses. I developed the XML-RPC server to support a project where the intention was to deploy LVRT targets (cRIO chassis) and then be able to control and monitor the distributed systems from any platform (the orginal spec was a Java app running under Linux as the system manager). I kept the implementation pure G with as little bells and whistles as I could so I could be confident I could deploy the project as an executable under LV as old as 7.1 and to any target that supports LabVIEW. The XML-RPC protocol was chosen because most languages and platforms have XML-RPC toolkits (Java, .NET, python, perl, etc) and because the protocol is very simple and lightweight - the whole spec can be printed on seven pages (at 10 point font)! This made it practical to roll my own server including the protocol parsing and packaging. I'm not so sure the same can be said of SOAP. I briefly looked at the spec and it seems like it might be an order of magnitude more difficult to create the necessary parsers and message packaging tools. I also poked around a little and I had a hard time finding any useful information about SOAP parsers/packagers - most of the SOAP protocol stuff is wrapped in WSDL and then that is wrapped in a server-specific implementation (ASP, for example). If you can find a simple SOAP parser, that could simplify using the XML-RPC server as a framework for a SOAP server. But the SOAP protocol is still just XML so if one can do XML-RPC then one can do SOAP - it just will take longer.
But it would just be a SOAP server - it seems that generally SOAP calls are made thru a web server. The web server must recognize the SOAP protocol and dispatch it correctly but also handle anything else that a web client might throw at it. My XML-RPC server just returns an error if it sees ANYTHING other than an XML-RPC call. But the up side is that the server architecture is straightforward and easy to follow, which can't be said of most other implementations.
Mark
-
QUOTE (Paul_at_Lowell @ Mar 24 2009, 11:03 AM)
http://zone.ni.com/devzone/cda/epd/p/id/3409
Mark
Edit: added link
-
QUOTE (Cat @ Mar 23 2009, 11:33 AM)
So I have my new toy (Desktop Execution Trace Toolkit), and I'm having all sorts of problems running it. The example project they send along is trivial, to say the least. My project has a lot of vis doing a lot of things, and the trace runs out of space (999999 event limit) very quickly. I know there's filtering, but it seems to work only intermittantly, or not at all. You maybe able to run it with executables, but you don't know what vi is generating the event in that mode, so it's not really very helpful. And as far as I can tell in executable mode you can only start it up once (at least when running source code, if your event queue fills up you can stop and start it again). Oh, and I manage to crash it once or twice an hour.I've searched around the NI site and can't find anything more useful than what little online help the software comes with. I've spent 2 days trying to get it configured for what I need to do and keep running into road blocks. I'm kinda frustrated, because this is the first time my team leader has actually cracked open the wallet to pay for something like this, and if I can't figure out how to use it, it may be the last time. I must admit, I'm expecting a lot from something we just paid $999 for. Maybe I shouldn't be expecting so much...
I know this is a relatively new product, but does anyone out there have experience with it and wouldn't mind answering a few questions?
(As a side note, is there some way I can change this topic to "Desktop Execution Trace Toolkit" or something else more pertinent?)
Probably doesn't make you feel any better, but I was at the local NI Developer Day last week and they demoed the execution trace toolkit. The guy running the demo (who's a pretty sharp LabVIEW guy from the NI home office) managed to crash it and had a hell of a time to get it to do what it was supposed to. He admitted he wasn't very familiar with the tool, but I did get the distinct impression it may not be ready for prime time. When it did work you could see how useful it can be when it does work. NI generally makes good stuff, but they may have jumped the gun on release of this product.
Sorry I can't really help.
Mark
-
QUOTE (Cat @ Mar 20 2009, 09:06 AM)
Now I'm really confused.Maybe the problem is semantics, and I don't understand what you mean by "there is still a reference to the dynamic VI on Big Top's block diagram". Do you mean that just having the icon for the vi on the BD (that never gets run) creates a reference to that vi (as opposed to loading it into memory), and that's the one that's not getting closed??
After I've closed the front panel and exited the dynamic vi, I expect the vi to still be in memory because it's sitting in Big Top. I *don't* expect it to still be running, tho. Maybe I should be using "abort", but that seemed like overkill.
Closing the front panel won't stop a VI that's been loaded dynamically - you can close and then re-open the panel and the VI will still be running. Closing all refs will. As long as the VI is running some sort of blocking process (loop, wait to dequeue, something) and there's a ref around, it will continue to run. Sounds like your VI panel gets closed but it never actually stops except when all refs go dead, so you may want to look at how you command the VI to actually stop.
Mark
-
QUOTE (LVBeginner @ Mar 19 2009, 06:57 AM)
Does anybody know which port is used by ActiveX objects? I'm using WinHTTP and I want to know which port is used for outgoing packets.Thank you
I think typically the outgoing port will get assigned by the OS sockets layer for most implementations - it just selects an unused port. Run "netstat" from the Command Prompt and you can see what local ports are used for a connection. I don't know anything specific about WinHTTP that might be different.
Mark
-
QUOTE (bsvingen @ Mar 18 2009, 05:25 PM)
I have no idea who you are working for, or what tests are being done. But since this has not popped up before the application was finished, you should be 100% certain of what they actually mean. To "stop" the tests is usually not the same as "aborting" the tests. If it involves powerful/dangerous/(costly and easely breakable) equipment there could be a world of difference between those two concepts.I agree here - if they want to shut down the test is a more or less orderly matter, that's one thing, but a true abort suggests "things have gone to hell and we need to stop this thing ASAP" - like the abort button when the Enterprise has started its self-destruct sequence. They should be handled quite differently. In most of the systems I've worked on, we never included a software or computer controlled "abort" although we did include stop and interrupt functions/buttons. If the system needed a real abort, that's what the big red mushroom switch that disconnected the mains or whatever was for.
Mark
-
QUOTE (Cat @ Mar 19 2009, 05:27 AM)
I'm thinking about taking the NI OOP class. It appears I've missed the cruise, so I'll have to settle for a regular ole office building.I stopped programming in C about the time C++ was getting popular, so I don't know much about object-oriented programming in general. Every time my cow-orker who is a C#.NET, etc whiz tries to explain it to me, it sounds like he's talking about ways of accessing typeDef-ed clusters with data and their associated info. It must be more complicated than that. I looked at the LV OOP stuff back when it came out in 8.2, but it seemed like it was adding code on top of what I was already doing. Once again, I assume my lack of knowledge is the problem.
My question is this: Do I need to learn C++ before I take the NI OOP course? I've read thru all the doc links I can find on this site and they've managed to underscore how little I know about the basic language of OOP. If they teach the class in that language (ie, here's how you all did it in C++ and now here's how we'll do it in LV) I'm sure I'll manage to stumble along, but won't get as much out of the course as I possibly could.
-
QUOTE (vugie @ Mar 19 2009, 05:38 AM)
I think the chart referenced in the link above explains why more people don't use 7-zip - you get about a 24% reduction in file size compared to zip but you pay a performance penalty in time of over 300%. Also, I would expect zip is more widely supported - does the native windows zip know what to do with a 7-zip file? I don't know.
But back to the original question - we need to know more about your data to offer any useful suggestions. For instance, if you're storing waveform info scanned from a 16-bit card then you can get full fidelity by storing a waveform header with scaling info and store each data point in two bytes. If you just dumped that data as doubles, you'll use four times as much space.
Mark
-
QUOTE (rolfk @ Mar 18 2009, 06:03 AM)
No it is not exactly as you seem to think. Lets take your example:The proxy address is usually in the form of "myproxy.mysite.net:8080" since it seldom uses the standard HTTP port of 80.
So you parse that address into the DNS name (everything up to the colon) and the port number, using 80 if there is no port number. Now pass this information to TCP Open.
Then you have a HTTP Request of the form "GET /index.html HTTP/1.1". Since the Proxy must know to what server to forward the HTTP request you have to modify this by prepending the server address to the absolute path of the resource. So the command to send to the proxy will be "GET http:/www.google.com/index.html HTTP/1.1".
That's all.
Rolf Kalbermatter
Thanks - I thought I was missing something obvious
 BTW, I certainly appreciate all of your very knowledgeable advice on all the threads I follow!
BTW, I certainly appreciate all of your very knowledgeable advice on all the threads I follow!Mark
-
QUOTE (rolfk @ Mar 18 2009, 02:20 AM)
That is because a proxy is only meant for HTTP (and possible other similar protocols like FTP sometimes). The LabVIEW TCP/IP nodes access directly the Winsock library and the thing that does for IP what a proxy does for HTTP is called a network router .
.So it is not a problem of the LabVIEW TCP functions but simply a question of proper setup of your network. Basically a proxy simply acts as a web server that does hand the HTTP requests through to the end server (that could again be another proxy and so on). The way to handle such a case in LabVIEW is by making a thin layer above the TCP/IP nodes. By the way the OpenG HTTP functions do some proxy server handling. But it seems they have not been packaged yet, however they are on the OpenG Toolkit CVS server repository on sourceforge.
Basically you open a connection to the proxy instead and then you have to parse every HTTP request and prepend the actual end address of the desired server to every relative URL in there.
Rolf Kalbermatter
Rolf,
Thanks for the information. Can you give a simple example of how one could create an address string that would get to a site like "www.google.com" through a proxy server called "myproxy.mysite.net"? Can you pass this composite address to the LabVIEW TCP Open Connection and expect it to work?
Thanks,
Mark
-
QUOTE (jaehov @ Mar 17 2009, 12:56 PM)
http://en.wikipedia.org/wiki/Method_(compu...#Static_methods
This also applies to static properties
In LabVIEW, when you browse the pulldown list of methods or properties from the .NET Property or Invoke node, the static members are preceded by . You can use the static methods or properties without first instantiating an object.
Mark
-
QUOTE (jaehov @ Mar 17 2009, 12:24 PM)
http://lavag.org/old_files/monthly_03_2009/post-7622-1237317801.jpg' target="_blank">
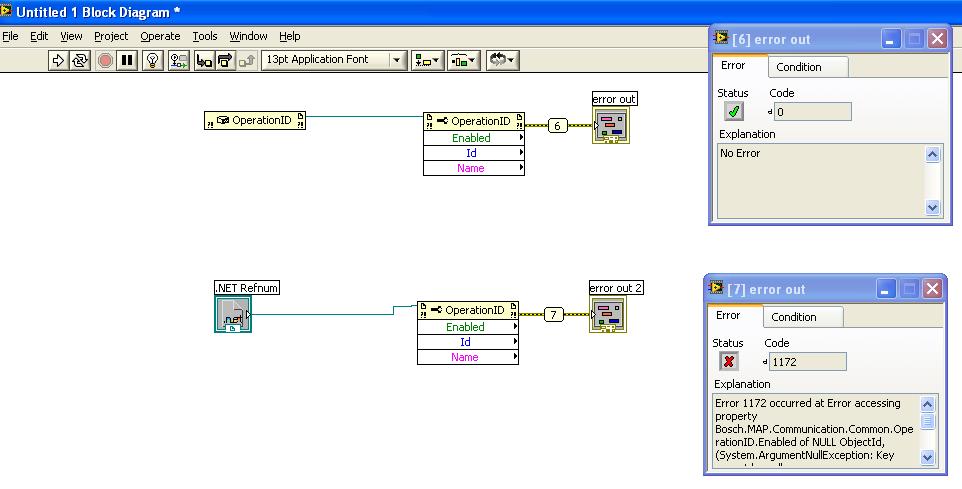
Hello Techies
I wanted to make a reference to a .NET .dll for use in Labview.
I started out by creating a .NET Refnum control and then connecting that to a Property Node. I could see all the properties, but when I ran the VI, I got Error 1172
(see the attachment)
My 2nd idea was to use a Constructor (for the object I wanted), then connect that to the Property Node. Now this seems to work with no error.
My question is:
1) Is there a better way of referencing the dll in my VI other than using a Constructor (...then getting the properties?) or am I doing this correctly with the 2nd idea?
thanks
The Rookie
Nope, that's what you have to do. Unless you're trying to access static methods or properties, you have to instantiate the object with the constructor node before any object exists that has any methods or properties.
Mark
-
John,
Here's an interesting article from the home team
http://www.sandia.gov/LabNews/081219.html
I think presently the best way to build a massively parallel test system is not by using a multi-core machine (at least not over four cores) but by using multiple machines that coordinate over some common interface (gigabit ethernet and TCP/IP?). This allows the architect access to more memory and bandwidth per thread (and typically per hardware device) than you can get from just adding more cores to the processor. Of course, it costs more

Mark
-
QUOTE (neBulus @ Mar 6 2009, 12:12 PM)
Here is Dan Mondrik confirming there was an issue with opening and closing VISA sessions. Yes that post is old but I work across LV versions and there only has to be one version that is buggy for me to adapt my rules. Here is a more recent reference to VISA and leaks that recomends making sure they are the most recent version of VISA. I never said the leak rate was high. I have apps that run for years without restarting so even a slow leak is of concern to me.I have an LV 8.6 machine running a test to see if this issue exists in a more recent version. So far it holding so that issue may have been fixed.
Task manager memory showed (Kbytes)
So there is now about 10M less memory available. No there is nothing else running on that machine and I have let it run with the Windows Task manager up. I'll leave this running over the week-end because I really don't like talking bad about LV if I don't have to.
If you get Process Explorer from
http://technet.microsoft.com/en-us/sysinte...7c5a693683.aspx
you can get more detailed info about just what is using the memory than from the task manager - it will show the actual memory consumed by a specific process and may lead to an answer quicker.
Mark
-
QUOTE (Mark Yedinak @ Mar 5 2009, 09:24 AM)
QUOTE (jdunham @ Mar 5 2009, 10:49 AM)
At that point you could just keep the versioning for each specific file. But then you'd have a poor-man's implementation of Subversion [smell the irony?], so you should just convince your IT group to put the real Subversion on the server. In that case you'd just run a simple svn update before executing any test.When you do something like this w/Subversion, do you use the command line and build a batch file to execute or do you use an API?
Thanks,
Mark
-
OK, so I was wrong the first time
 , but I think this may be why I've never had any luck with getting the host names to resolve correctly and it could be the problem here
, but I think this may be why I've never had any luck with getting the host names to resolve correctly and it could be the problem herehttp://forums.ni.com/ni/board/message?boar...essage.id=90988
I can connect to my proxy server using it's host name but I can't connect to anything else because there's evidently no automatic (easy) way to use a proxy server with the LabVIEW TCP/IP tools
I learn something everyday (at least I hope so)
Mark
Edit: Try looking at the configuration of your web browser (assuming it can reach the requested host) and see if it's using a proxy server
-
-
QUOTE (LVBeginner @ Mar 4 2009, 09:47 AM)
Ok I have this simple HTTP server for testing purposes of the LabVIEW server and TCP/IP sockets. Now I can't get the TCP Open Connection function to open a connection. I get error 56 which is timeout error. I have turned TCP/IP on and I have turned the web server on in the LabVIEW options. I have also tried different ports but I can't establish a connection. Can somebody please help me out.I'm using LabVIEW 8.0 and have attached a screenshot of the .vi.
TCP Open Connection won't do a domain name lookup for you and resolve the address - put the IP address of the server in the address box and try again
-
QUOTE (Cat @ Mar 3 2009, 08:08 AM)
One way to get more info about the conditions when the program crashes would be to run a network protocol analyzer in the background (Wireshark is a good choice) to log the TCP/IP traffic. Then, when the program goes haywire, you have a record of what was happening to the network at least. If this log doesn't show any weirdness, then you can start looking at other parts of the program. This should be relatively easy to do (download Wireshark http://www.wireshark.org/ ) and install it and set up message logging on the stream in question.
Mark
-
I think this is exactly what you should expect. LabVIEW won't have any knowledge of which .NET assemblies get called unless LabVIEW specifically links to them with an Invoke/Property/Constructor node. So the LabVIEW builder won't automatically include any of the .NET assemblies it doesn't know about. If the referenced assemblies are part of the .NET runtime (like anything in mscorlib namespace) it's in the GAC (global assembly cache) and available to all other .NET assemblies without any other effort on the developer's part. If the assemblies referenced are developer defined (not part of the .NET framework), then the developer has to specifically get them on the target machine. You could put them in the GAC (but they must be strongly signed), but the easiest way is just to include them with your app by going to the Source Files pane on the Build Specification for your DLL and add the assemblies you need to Always Included. Then, all of the assemblies you need will get copied to your Support Directory - the path is shown on the Destinations page of the Build Specification - which defaults to the Data folder unless you change it. Without a good reason to change it, you should just leave it as is since the LV exe will always look first in the Data folder for support files. So the search path is LV exe -> Data Folder -> top level .NET assembly -> Looks for other .NET assemblies in 1) Data folder (.NET always looks in the same folder as the root assembly) -> GAC -> custom destination(s) - set by the calling assembly' s manifest? I not sure I recall this correctly.
Mark
Edit: Another possible course is to create a top level assembly in the .NET environment and build it as a DLL and then call that from LabVIEW. Visual Studio will detect dependencies and allow you to build a DLL and installer that includes all of the dependencies of the .NET DLL.
-
-
QUOTE (neBulus @ Feb 20 2009, 08:47 AM)
Close but not exactly...If I did not share this and it ended up being the issue, I'd feel bad.
The Modbus libraries that NI had their web-site where OK if that was all you were doing so they make a nice demo. They did not play well with other process. I went through and refactored them adding "zero ms wiats' to loops and some other stuff.
Maybe instances are fighting with each other and can play nicer together if they just share the CPU better.
Ben
Ben,
You may have the answer - IIRC (from my fuzzy recollection of RTOS class), you can starve a thread/process/whatever so that it never executes if higher priority tasks are still requesting CPU cycles. So, of the some of the code is written so that it always operates at a lower priority adding the zero msec wait ("Wiring a value of 0 to the milliseconds to wait input forces the current thread to yield control of the CPU" - LV Help) should make sure it executes. So maybe when the close connection is called asynchronously it never really gets executed because it never gets a high enough priority but when called serially it's not competing for cycles and does get executed correctly and the port gets released for re-use. This is all complete speculation, so TIFWIIW.
Mark
Newbie Q: Writing to controls
in User Interface
Posted
QUOTE (Michael Malak @ Apr 7 2009, 10:22 AM)
This is the one place where using local variables (or property nodes) is considered good LabVIEW style - to write values to a control, right click the control on the BD and select Create->Local Variable - now, whatever you wire to the local will get written to the control
Mark
[Edit]
Just one more thing - you can save a lot of time doing this sort of thing if you group controls into a cluster and then use some tool that automates persisting that cluster to file. Then you can do one simple write to save the initial values and one read to repopulate the cluster - or, if you need to separate the controls on the UI, you can then unbundle the cluster on read. There are several approaches that essentially automate the write and read from file. I've attached an example that uses the LabVIEW Schema XML Tools, but if you would prefer to save the config data in ini style files, a couple of good options are the OpenG Config File Tools
http://wiki.openg.org/Main_Page
and David Moore's Read/Write anything VI's
http://www.mooregoodideas.com/File/index.html
Mark
Download File:post-1322-1239123211.zip