

Mark Smith
-
Posts
330 -
Joined
-
Last visited
-
Days Won
5
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Mark Smith
-
-
Well, one approach would be to make specific implementations that inherit from an interface class for everything that gets indexed in the for each loops. So, you have a parent DUT class that all of the unique types of DUTs (four?) inherit from. Then the next for each loop invokes the correct test methods on the DUT. It appears here that the TestCase would need to know what kind of device is being tested - I would propose that it might be better that each DUT (and here I mean the DUT object, not the actual physical device) knows which tests need to be performed on it and contains those tests in a collection. So the sequencer program flow would be almost the same, except it might look something like
foreach deviceUnderTest in devicesUnderTestCollection foreach testCase in deviceUnderTest.TestsCollection testCase.Execute() next testCasenext deviceUnderTest
The if-thens aren't really needed - if the deviceUnderTest isn't part of the collection, it doesn't get tested and if the testCase isn't part of the deviceUnderTest tests collection it doesn't get executed. Now, the test case knows that it is a member of a specific device's test collection and it can get private member data about the DUT without passing any parameters as function arguments. This could include data from the calibrations file(s).
As far as data format, unless there's strenuous objections to XML (it's sometimes debatable whether or not it's "human readable"), use the LabVIEW flatten and unflatten from XML functions - these can serialize the data structures or the objects depending on what you need.
Mark
-
Still willing to play along...
I have some re-use code that I have been re-using since LV 6 that provides Event logging services that can used to track system start-up shut-down and any errors that may have happened. It is based on an AE. All my developers have to do is drop this widget in their error chains and they always have a way to track back an error. It is so simple it isn't worth showing.
It has three actions
Start (Open log file write start-up time and create queue for new messages)
Log if error (post to queue if an error)
Stop (close log and kill queue)
So with three wrapper (one for each) that gives us three VI's the developer has to use.
So how would I write a LVOOP replacement that would actually be a one-to-one replacement?
From what I understand of LVOOP, I'm either going to hide an AE in a LVOOP method, or my developers are going to start running more wires to use the LVOOP version.
Take care,
Ben
OH! OH! - I actually have a useful answer (as opposed to my earlier post) to this one because I do the same thing with classes.
I have an ErrorLogger class that has three public methods - Start Daemon, Stop Daemon, and Enqueue Error. Any time you want to start logging errors, start the daemon, To log an error, just drop the Enqueue Error VI in the error wire. When you want to stop logging errors, just call Stop Daemon. The daemon opens a ref to the error queue and starts waiting for anything on the queue.
The Start Daemon vi has controls that let the user set the path to the log file, the max error log size (it starts throwing away old messages when the max size is reached), and whether or not enable error dialogs.
The Enqueue Error vi just has error in and error out terminals - it gets a ref to the error queue by name and closes it when it exits.
The Stop Daemon just has error terminals (all of my VI's have error terminals)
All of the other stuff (like whether or not the Start Daemon has to create a new directory to create the error log file and the daemon itself) is in the private methods of the class and the user needs never worry about any of that.
The HUGE advantage of this approach over a single action engine is that the Enqueue Error vi is reentrant - one part of the code can be spewing errors and logging them (and my code often does
 ) while another part of the code that also could log errors isn't blocked waiting on the AE.
) while another part of the code that also could log errors isn't blocked waiting on the AE.Mark
-
 1
1
-
-
for me, the wireless transmission of data using AEs is the biggest paradigm shift holding me back from going to LVOOP.
Having to bundle all the classes I want to use onto my main shift register just seems weird, especially as its ByVal and not ByRef so just in my mind seems not efficient.
re: public / private methods of AEs, isn't everyone doing this?
re: polymorhphic method VIs - this is a great idea!
If you really don't like wires there's always C++ (ducking for cover now).....................

-
So, basically, we can't trust the average juror to use their conscience properly?

I hope that's not what I said, because that not what I meant. I mean to say that including instructions - in the typical case - to "judge the case on the facts presented in the courtroom, and oh, by the way none of that matters if you disagree with the law that the defendant is accused of" won't help the case come to any kind of conclusion. It's just a recipe for a mistrial and more taxpayer dollars spent on retrial. This isn't an argument for more laws and government - it's just an argument for having a consistent legal system so everyone knows what to expect.
Mark
-
In his writing on the subject, retired professor Kelley L. Ross commented:
"If [judges and juries] were to... hold themselves powerless to disobey unjust and morally despicable laws, they should be told that "obeying orders" was not accepted as a defense in the Nazi war crime trials at Nuremberg."
I think this is the crux of the matter - if a law is clearly unfair and "unjust and morally despicable" then we do have a responsibility to do the right thing and juries can and have nullified those laws. But instructing juries to consider "jury nullification" in a case such as the one mentioned in the original post to this thread, where there is no indication that the law is "unjust and morally despicable", seems ill advised.
Mark
-
I've avoided these kinds of threads until now, but I'll ignore my better judgment and offer an opinion here.
There's a word for a court system that allows (and maybe even encourages) "jury nullification" - it's called anarchy. Our legal system (I'm here in the US) would completely fall apart if every jury were encouraged to "vote their conscience" when deciding guilt or innocence to a specific charge or set of charges. If a jury can effectively re-write the law whenever they see fit, then none of us can possibly know which laws we should follow, which we should ignore, and which we should expect our neighbors to follow (is it now OK for our neighbor to come "borrow" our car without permission because he might find a jury that sincerely believes all property is communal?). Our system of laws provides each of us a frame of reference in which we make choices based on expected outcomes. If this frame of reference is constantly shifting, we have no idea what to expect and cannot make intelligent predictions about the consequences of our decisions.
One could extend this argument to all sorts of bizarre and admittedly unlikely scenarios but the argument is this: if a jury of 12 (or in many cases, even less) can simply ignore any law they don't like when deciding guilt or innocence there's no point in writing laws in the first place.
And for the specific case given - we all read news stories about arrests and indictments that don't seem to make any sense. Often, these are a case of practicing "defensive" law enforcement like doctors have to practice "defensive" medicine. If the officer doesn't make the arrest or the prosecutor doesn't make the indictment and something terrible happens later then they will be second guessed and maybe even subject to criminal prosecution themselves. For instance, maybe this person was just taping a birthday party - or maybe they have a side business of posting and selling new release movies. That's why we have a court system - to sort these things out.
Mark
-
I'm guessing you're using the state of the action engine to save configuration state? If so, an approach I've used that works well in OO architecture is to once again use a single VI for entry into the shared resource and then create classes (could be subclasses) that expose just the stuff required for a specific test - or alternately, methods for each specific test in a common class. Each method/class can include an action engine wrapper that just maintains state for that specific test's configuration. The main entry point still maintains state for the configuration of the entire resource and the specific test wrappers just expose the properties necessary for that test. And there's still just one main VI (shared by all of the classes/methods) that acts as the "gatekeeper".
Mark
-
I'm building a system that can run up to 4 concurrent chemical reactions. My plan is to have 4 independent "reaction" objects that each execute in parallel, but they all need access to some shared components such as the liquid handling system that adds chemicals to each reaction, and the analysis equipment to check reaction progress. I'm looking for comments on the best way to make sure that only one reaction at a time can access the shared equipment. It seems like the traditional approach would be a semaphore, but there are all these other options available. For example, I can put all the functions for the liquid handling system into a single FGV, make it non-reentrant, and prevent overlapping access. Or I can put the automation refnum (it uses ActiveX) into a DVR or single-element queue to limit access. What is your preferred approach? What if I have 2 analysis instruments, and each reaction should use the first one that's free?
Taking this a step further (and overlapping with the recent questions about singleton classes), say I create a class to wrap the liquid handling operations. Do I wire that class to all the reactions after opening the automation reference? Is there a clean way to store that reference inside the class so that I don't need to directly wire that class everywhere it might be used?
Thanks for any comments; I already have some of this working but I can't effectively discuss my design with coworkers (I'm the only programmer on the project) so I'm looking here.
Don't make this problem harder than it is! This is one place where LabVIEW's dataflow and default subVI calling mechanism make things easy. Just put the access point for the shared resource in a single, non-reentrant VI (this can be a method in OO architectures) and you're home free - no other call can access the resource until the previous caller is finished with it and all the calls will wait until the resource is free and then execute (essentially queue up and wait, except that you can't be sure exactly which will get to use freed resource first).
Mark
-
I'm a little late to the party here, but I'll put in a vote for LuaVIEW. I have found this to be a very powerful tool for writing Lua scriptable applications for deployment (and I don't mean LabVIEW scripting). I use an object oriented LabVIEW framework for building code that encapsulates the test equipment (and collections of test equipment) for stimulus and measurement and includes classes for data persistence, evaluation, and reporting. I then use Lua (in the OO style calling convention) to build scripts that are specific to particular tests. The heavy lifting gets done by LabVIEW, and the scripts can be very lightweight.
One huge advantage to this approach to my customers is that the deployed app is now scriptable in a language that feels mostly natural to them (most of my customers are in R&D type environments and are scientists and engineers and know languages like Python, Perl, etc). They don't need LabVIEW to modify tests or experiments - and couldn't use it any way, since they don't have the source code on the testers - and there is no additional licensing fee (there is a license fee for the development toolkit) for the deployments. So they can tinker as much as the project API allows - the API is the set of Lua callable LabVIEW functions I expose plus the Lua callable LabVIEW functions LuaVIEW exposes plus the entire native Lua 5.0 language (which is Turing complete) - without me having to worry that they mucked up my source code.
Heres' an example
----------------------------- test function --------------------------
function testOne()
-- create objects - uses unique names and an action engine to
-- create by-val objects that are retrieved by-ref
powerSupply = PowerSupply.new("powerSupply")
powerMeter = RF_Power_Meter.new("powerMeter")
dataSaver = DataSaver.new("dataSaver")
-- configure objects - I use LabVIEW clusters/classes flattened
-- to XML because they are easily embedded in a text script
powerSupply:configure([[
<Cluster>
<Name>UUT Power</Name>
<NumElts>5</NumElts>
<String>
<Name>Description</Name>
<Val>Configure UUT Input Power</Val>
</String>
<Refnum>
<Name>Power Supply (Agilent E6644) VISA Resource Name</Name> --6038A
<RefKind>VISA</RefKind>
<Val>GPIB0::5::INSTR</Val>
</Refnum>
<DBL>
<Name>Voltage</Name>
<Val>28.00000000000000</Val>
</DBL>
<DBL>
<Name>Current Limit</Name>
<Val>2.00000000000000</Val>
</DBL>
<EW>
<Name>foldback protection (0:off)</Name>
<Choice>off</Choice>
<Choice>constant voltage</Choice>
<Choice>constant current</Choice>
<Val>0</Val>
</EW>
</Cluster>
]])
powerMeter:config([[
<Cluster>
<Name>RF Power Meter</Name>
<NumElts>5</NumElts>
<String>
<Name>Description</Name>
<Val>UUT Power Measurement</Val>
</String>
<Refnum>
<Name>Agilent E4418B VISA Resource Name</Name>
<RefKind>VISA</RefKind>
<Val>GPIB0::13::INSTR</Val>
</Refnum>
<I32>
<Name>Unit A (0: dBm)</Name>
<Val>0</Val>
</I32>
<DBL>
<Name>Lower Limit A (-90.00E+0)</Name>
<Val>90.00000000000000</Val>
</DBL>
<DBL>
<Name>Upper Limit A (90.00E+0)</Name>
<Val>90.00000000000000</Val>
</DBL>
</Cluster>
]])
powerSupply:apply() -- applies power to the UUT
power = powerMeter:measure() -- take a measurement - RF Power in this case
dataFile:writeObjectAsXML(powerMeter) -- save the data taken by the powerMeter
powerSupply:remove() -- remove power from the UUT
return power
------------- end of function -----------------------------
-- the test script calls the functions
--#import c:\scripts\functions
result = testOne()
if resultOne >= someLimit then -- if we pass the first test
repeat
result = someOtherTest() -- this test loops until the limit is met
until (result < someOtherLimit)
end
----------- end of test ------------------------------------
The XML configs can be edited in the text editor (I use SciTE since it's free and Lua syntax aware) or I have an app that parses the script, extracts the LV clusters, and loads them into their respective controls for editing.
So, the specific tests become functions that get called in the main script - the main script (and functions) can have any feature of the Lua language - control structures, math functions, system calls, file IO, etc. It's powerful, flexible, and relatively easy to maintain. This approach lets LabVIEW do what it's best at (instrument control, DAQ, threading) and lets Lua do what it's best at (imperative, easy to read and follow test directions). New functions can be deployed to the API without changing the exe (plug-in style).
Mostly I just wanted to present this as an alternative to TestStand (disclaimer - I have no interest in LuaVIEW other than as a satisfied user and I have very little exposure to TestStand, so maybe I've completely misinterpreted what TestStand does). And don't read this as "TestStand is bad" - I don't know TestStand but I think NI in general puts out quality products. I am a LabVIEW user, after all

Mark
-
1
-
-
This might be the right direction to start in: http://support.mozil...ging+file+types
The problem is that Firefox never gives me a chance to do any of that stuff - it just opens the .lvproj file as XML in the browser. I think one might be able to hack the Firefox .rdf file and get this to work, but that's not very useful for my customers. This type of link works fine in Internet Explorer (at least version 6 - that's the latest I've got at work) so I think that maybe this is just a bug in Firefox. It makes a decision about the data as soon as it sees the XML tag without allowing for any other interpretation.
Thanks for the link,
Mark
-
Not a LabVIEW Problem!!! Read at your own risk

I have created a LabVIEW application that creates an HTML page for documentation purposes (modeled after doxygen) for my LabVIEW projects. I have included links that allow the user to click the link to a VI and open the source file in the development environment. This works fine and opens the Firefox "open with" dialog and I can then use LabVIEW to open the VI. However, I also have links to the LabVIEW project and class files (.lvproj and .lvclass extensions). The .vi extension is a binary, but the .lvproj and .lvclass files are xml. Firefox opens these links as text without ever opening the "open with" dialog and giving me a chance to select the LabVIEW IDE to open them with. How do I get (can I get) Firefox to not open these as text and instead give me a chance to use the IDE to open them?
Mark
also posted at http://support.mozil...forum/1/509984?
-
Maybe you don't need to convert a LabVIEW object to a .NET object. I'm not sure exactly what you need, but if you just want to use the Property Grid control in LabVIEW, that can probably be done. Check out these links
http://zone.ni.com/reference/en-XX/help/371361B-01/lvhowto/create_dotnet_controls/
http://zone.ni.com/devzone/cda/pub/p/id/230
Mark
-
Don't have any workarounds or explanations, but I can confirm that LabVIEW can be pretty annoying in the way it gets handles and never seems to let them go until you close LabVIEW. This behavior has been around as long as I can remember. I usually see it when I want to delete a folder that LabVIEW has accessed at some time and I can't do it until LabVIEW has closed.
Mark
-
...Or any of the Colorado fourteeners. The last one I (almost) climbed is Sunshine Peak - got almost to the top but the last couple of hundred feet was just too technical for me, since I am a hiker and not a rock climber. This took a couple of days since the hike to the base of the mountain is about ten miles from however you come in. If you just want to climb steep hills (and see gorgeous views) Yosemite Falls will do the trick. The trail is essentially a 3,000 foot tall stairway!
Mark
-
I have a server that listens on a port (27000) that I need to replace to fit in with my new system. The client code can't change. I have found a few articles that say you can build a server using the LabVIEW TCP primitives but having little knowledge about what is exchanged between client and server and how it all works. I have tried using the solution found in this link (read cutting a corner lol).
http://forums.ni.com...&thread.id=1941
I am unsure how to set the Local IP there doesn't seem to be a way to do this, only a way to read it. This is going to be a problem. As at first this was setting itself to 127.0.0.1 which is fine, but now it seems to use 0.0.0.0 which means the client app wont connect. From what I can read about the winsockcontrol activex component you should be able to set the IP but maybe I am missing something(I have not done much more than the Int2 ActiveX training).
I dont know how to monitor the client handshaking data but I am lead to believe it is winsock standard.
I don't know if any of you have seen this code before and know what the problem may be or have a LabVIEW primitive solution, but any help would be greatly appreciated.
Many Thanks in advance!!
Neil.
To look at the TCP/IP traffic, Wireshark is the defacto standard for Windows
As far as setting the IP address on the server (I think that's what you mean), you can use Control Panel->Network Connections->Local Area Connection and then right click for properties and change the IP address to a static one.
Lastly, the XML-RPC project in the Code Repository
http://lavag.org/ind...ads&showfile=66
has an example of a LabVIEW server.
Mark
-
Hi Mark,
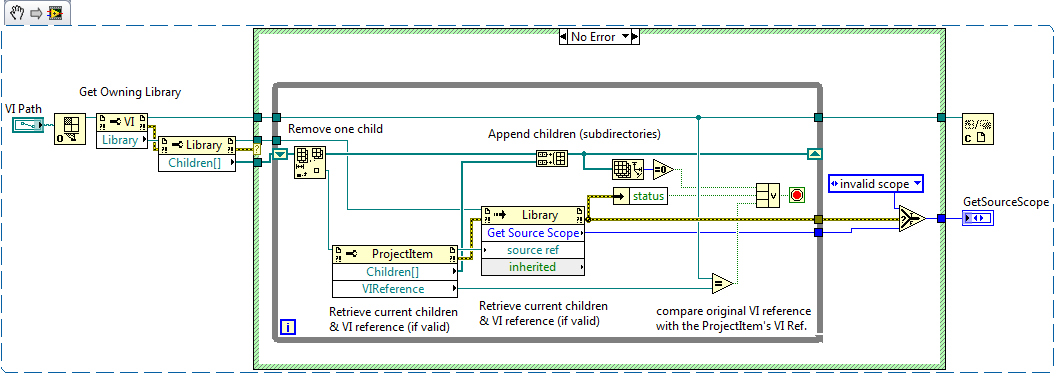
You can do it even if the class is not loaded. If your VI is not part of a library (lvclass, lvlib, xcontrol, ...) then it's scope will be "invalid". Otherwise, it's about the same thing except you start from the VI reference and check it's owning library reference. If it exists, then it's part of a library for which you can find a match by using the ProjectItem's VI reference. The VI reference is not always valid (because all library members are not automatically VIs) but if you can sort out the errors and invalid references, then you can match the correct ProjectItem with it's associated VI reference.
Note that this works for any libraries, not just lvclasses. If your VI is a private member of a lvlib, then it's gonna return the correct access scope too.
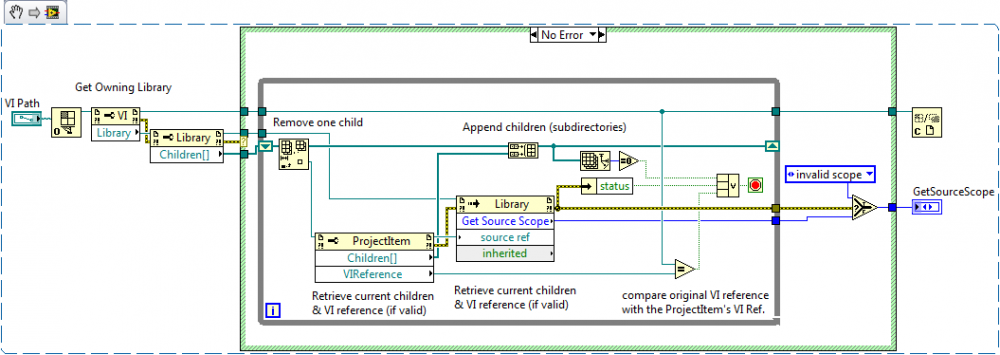
Thanks once again. This does explain what is actually happening. The VI knows it's part of a library but it appears that only the library knows the VI's scope. I thought from that original snippet from AQ (from the linked thread) that the VI also would know and might be able to report its scope, but apparently my interpretation was incorrect.
Mark
-
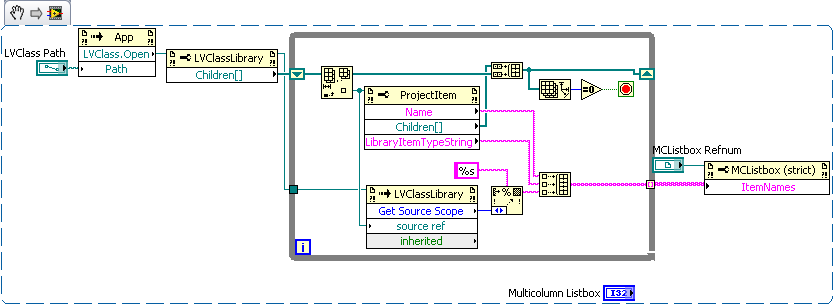
The children of a LVClass library are Project Items.
Sorry I don't have 8.6 available at the moment. Here's a screenshot (LV2009 snippet).
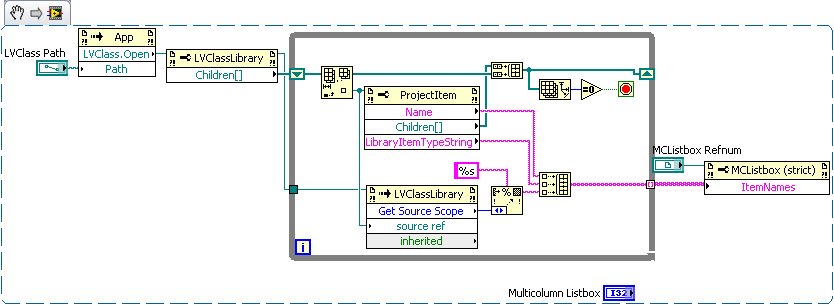
I was being lousy... there's another computer right next to me with LV 8.6...

Thank you ... LAVA to the rescue! This will let me do what I need. I'm still interested to know if could get the access scope directly from a VI ref to a class member.
Mark
-
I need to get the access scope of a VI programmatically - I'm creating a tool to produce documentation for my classes and I want to know whether or not a VI is public or private. If it's private, then I don't need to add it to the documentation since the developer will never use it directly (If someone already has a tool to do this sort of thing, I'd love to see it!) I searched the forum and found this thread
http://lavag.org/top...__fromsearch__1
where AQ says
"Asking a VI "are you a private VI" is easy enough -- use the VI ref to get the lib item ref and then ask for scope, which will take care of checking virtual folder settings. "
Except that the Get Source Scope method also wants a source ref (type is ProjectItem). How do I get this ref? Do I need to open a project and find this particular item? Or is it exposed somewhere else?
Thanks,
Mark
I'm using LV 8.6.1
-
Uncle! Uncle! - I don't often use queued state machines either - it was just an example
What I do use is lots of asynchronous code and lots of VI server calls to start the VIs in new threads and return - it's required by the nature of my current projects. And I never need more than one event handler per BD because the event handler always returns rather quickly. And I can leave the "Lock Front Panel Until This Event Completes" option checked and LabVIEW will prevent the user from clicking anything else until the event handler is ready - and that's all I have to do. Since I am simple-minded, I tend toward the simple solutions 
Mark
-
Yes, but... (apologies if I'm hijacking this thread)
I've been looking at some code I wrote quite some time ago that has an event structure that passes messages to a queue with lots of code underneath it.
I think the only reason I did it this way was there were a few bits of code I could reuse by just sending different inputs triggered from different events. I would have had to copy the same code to those events, otherwise, or put it in an event with a "value signaling" trigger (jcarmody, I believe this is what you were talking about?). But this was a rare case and usually I have code in events that is unique.
And even tho I'm doing it this way, I still have to be very careful about what controls are enabled/disabled when. My users like to randomly push buttons when they're bored...
But if it wasn't for the code reuse issue, I'm not sure what generally the benefits are to separating the event and the code for the event. I'm not buying the "more elegant" concept (which is subjective, anyway). I look at my event/queue code and see it being less readable since the action and reaction parts are separated. I also see twice as much BD space being used. And I see one loop having to rely on another loop for its stop signal (that's one of my least favorite "rabbit hole"). I don't call that "elegant".
So if there are real hard technical reasons why I should go to using the event-to-queue paradigm on a more regular basis (keeping in mind that I have no issue with using multiple event structures when necessary), please tell me! Old cats *can* learn new tricks.
(And bonus points if you can convince me it means LV will make fewer copies of my Really Big data sets
 )
)As usual, there is no "wrong" or "right" answer - only shades of gray......
But here's a couple of reasons to consider decoupling the actual "code that does something" from the UI
1) Responsiveness - if you have any action that takes a long time and your program is capable of doing something else (safely) then it's best to let the user continue to interact rather than locking them out and making them wait. For instance, an app that takes data for a long period (more than seconds) might be quite capable of loading and displaying previously acquired data sets while it takes new data.
2) Flexibility - if you have a state machine, for example, that can be queue-driven then you can call it in many different ways. If your state machine is effectively coupled to your UI, that's about the only way you can make it run. Having the "stand-alone" state machine makes it much easier to automate, both for test and deployment.
But sometimes it does make sense to just have the code in the event-driven UI, like a data viewer, for example. Here the only use case is human-driven interaction so there's no sense in mucking it up with anything complicated. But I would still argue that if you find yourself needing multiple event handlers in a UI, then the UI is trying to do too much and the program logic needs to be separated from the UI (like the Controller in Paul's example).
Mark
-
Basically, we have a low level "engine" VI which deals with low level commands for the system we're controlling. We then have several "intermediate" level vis which call this engine to perform specific tasks made up of multiple use of the low level commands. Above this we have the UI which as well as being able to call the low level stuff, calls the intermediate level VIs to perform the automated tasks.
I need to be able to interrupt the engine (from the UI), but at present since the code in the UI is within the event structure, when one of the intermediate VIs is called, it "blocks" the event structure loop until it completes, meaning that I can't interrupt the engine as my UI won't do anything until the intermediate VI completes.
The way I see it there are two solutions - the simplest is to add a second event structure loop which is only triggered by 2 or 3 "interrupt" type controls. This structure can be used to send interrupt commands down to the engine level (via the queue setup we have in place) even if the main UI event structure is waiting for an intermediate VI to complete.
The alternative is to shift to a queued state machine in the UI, so I have one event structure which, when triggered, fires instructions into the state machine which can then deal with the intermediate VIs - leaving the event structure free to fire interrupts down to the engine if necessary. The disadvantage here is that I need to recode what I've already done, and you add yet another state machine to the mix (the intermediate VIs calling down to the engine are largely queued state machines, as is the engine itself!).
Hope that clarifies what I'm trying to achieve!
Cheers for the comments
Paul
So, I think I understood the question and I still would avoid two event structures on the same BD. The reason is because every time I've gone down this rabbit hole ("Oh - we forgot to tell you we need an Abort button!") I've ended up doing your alternative two and building some sort of asynchronous message handler so the event structure never blocks. The only other thing that I've used that might be useful in your case is to launch a dialog panel on entry into the blocking case that exposes an "interrupt" button and handles queuing up the message to the state machine. This might even be as simple as adding this button to the blocking VI and then opening its front panel.
Just my observations - ymmv
Mark
-
I tried to bundle by name several references to clusters of controls, but find that when I drop the reference into the cluster constant box on the block diagram, the reference is not recognized by visually changing the border of the cluster box. The reference cannot be dropped into the cluster, which to me is rather strange as I look at what I am trying to do as making a struct containing pointers and seems reasonable to me. I am trying to do this since my front panel contains several clusters each containing a number of controls, and I am not trying to mix controls and indicators. If I can do this then I can pass in just one parameter to a subVI that has to work with all these clusters of controls instead of the many more parameters that I would have to pass in if I do each cluster as a separate parameter.
Any suggestions?
That's because the reference isn't a constant - the actual value gets assigned at run time so what you're essentially trying to do is get the current pointer value and assign it to a constant. This is probably a bad idea most anytime so LV keeps you from doing it. You can create a constant cluster with control ref constants (the easiest way I can think of would be drop controls from the refnum palette and then create a constant) and then bundle the actual control refs into that, but they can't carry control type information - you'd have to cast them to the correct type when you unbundle. I think what you could do is 1) create control refs from your controls 2) Create controls from the control refs (these will be strictly typed) 3) create a cluster on the FP with all of these control refs 4) save the cluster as a type def 5) use this type def to bundle/unbundle the control refs 6) pass the ref to this cluster between VIs
Caveat! It's usually a bad idea to pass control refs instead of data between VI's in LabVIEW because this will always force execution into the UI thread. Only pass refs if you have a good reason - if the data could be on a wire, put it on a wire.
Edit: Okay. I'm late to the show - what Ben said is the same only appears easier!
-
If I understand the question correctly, I think the best solution in this case is just to start the queued state machine that's handling the events in a separate thread. I presume you're calling the queued state machine inside the event case and it's blocking until it completes. If that's true, why not just handle the event case by putting the request on the state machine queue and returning immediately? Then the UI will be ready to handle any button clicks and pass the message on to the state machine thread - of course, I may have completely misunderstood the problem.
At any rate, I find having more than one event structure on a UI to be a complete PITA. I think there's only one event queue (the real experts can weigh in here) so I find you have to carefully enable/disable controls because any control not handled by the currently active event loop that gets in the queue can cause the application to block forever - the event structure you hope will handle the event can't execute because the other event structure is waiting. This can be avoided and I know some people make this work, but every time I've tried it I've eventually found a better way.
Mark
-
...With functional languages (lets forget OOP for now) like c, pascal, java script, VB, PHP et al, only the syntax really changes (pascal uses the asignment ":=" as opposed to "=" for C for example). Once you learn one its just a case of learning the IDE and syntax and away yoiu go
 But changing between paradigms is a bit different. Its much more difficult to change from C to Prolog for example even though they are both text based. Couple changing paradigms with changing from text to graphical just compunds the leap.
But changing between paradigms is a bit different. Its much more difficult to change from C to Prolog for example even though they are both text based. Couple changing paradigms with changing from text to graphical just compunds the leap.Not to be too pedantic - OK, so I am being a pain in the ass
 - but the languages you list above (c, pascal, etc) are actually called "imperative" languages by the CS types. Lisp is the best known "functional" language and ProLog is a "logic" language.
- but the languages you list above (c, pascal, etc) are actually called "imperative" languages by the CS types. Lisp is the best known "functional" language and ProLog is a "logic" language.Mark
How do you model this?
in Application Design & Architecture
Posted
So, to me this type of QSM is really just a huge function library where
1) the function calls are the case names
2) the queue becomes the "script" that defines what function is called
The problems here are that
1) There may not be any explicit arguments (or there may be, if the queue contains variant data or such) but there are probably many implicit arguments to each function (case) and they're often hard to track down
2) There are probably no explicit return values to the function calls (if you're luck there's at least error handling) but there's lot of data generated or changed
3) The script is not immutable - the queue (script) could be changed at any point in the run sequence (at runtime) and you can't usually tell what might or did change the queue by examining the queue itself. Self-programming applications can be kind of cool but they're not typically suited to reproducible, reliable test and measurement software.
So, I think the most one could do in documentation is treat this "state machine" like a function library and document what each function (case or "state") does - as you've already realized, you can't possibly document every flow thru the "states" since one could easily write code that puts functions on the queue in an endless, random loop. If that's not adequate (you have to know what the sequences will be) then throw away the code and start over.
And don't let those guys use QSMs again! If you need a test sequencer, try TestStand or if you want to script your applications (which I prefer) LuaVIEW is great.
Mark