

John Lokanis
-
Posts
797 -
Joined
-
Last visited
-
Days Won
14
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by John Lokanis
-
-
Before I totally reinvent the wheel, has anyone created replacements for the one and two button dialogs that do not block the root loop in LabVIEW?
The main features I would need them to have are:
Ability to resize to fit message and button texts, like the originals do.
Reentrant (so one does not block another, in case many threads want to call this at the same time, and yes I know this might not always make sense.)
Centers itself on the active calling window (and not the screen, like the 3 button dialog does)
Does NOT block the root loop!
I can almost do this with the 3 button dialog, but it centers itself on the screen and is not reentrant.
thanks!
-John
-
QUOTE (jdunham @ Sep 2 2008, 05:07 PM)
Is there something special about using VI Templates? Nowadays you can just launch clones of a normal reentrant VI, without any copying, by passing option 8 into the Open VI Reference function. How are the queues 'passed around'? I think you said you used unnamed queues, but then it's not clear how that fits in with your cloning (not that we really need to know, but it may shed some light on your issue).Yes, there is one thing very special about VITs vs reentrant clones. A VI spawned (and detached from the caller) using a VIT can run in the background and have it's FP displayed in a sub-panel and removed while it is running. A reentrant VI must be set to hidden FP in order to get it to run detached from the caller, but then it cannot be displayed in a sub-panel because it's FP is considered 'open'. So, if you want to spawn daemons with FPs that you wish to display in a sub-panel, they must be created from a VIT and not a reentrant clone.
I am using unnamed queues and passing the queue reference by value to all sub vis that need it because I have many spawned copies of the same code all using the same reentrant sub-vis and I need to make sure each spawned hiarchy uses it's own queue refs and not those from another spawned hiarchy. So each queue in the VI spawned from the VIT has only one create and one destroy.
-
QUOTE (jdunham @ Sep 2 2008, 02:49 PM)
if your application design is such that preallocating clones is a huge waste of memoryyes. that is the case. And I do not rely on any states of USRs. Instead, I use SEQs (single element queues) to save and recall states between parallel processes within my code. I am essentially treating these SEQs as dynamic memory pointers.
In my case, I launch many copies of the same VIT that call many reentrant VIs (all set to shared clones) that in turn create their own SEQs and pass them around to communicate between my producer and multiple consumers (7, in fact). So, if I was to preallocate, my memory usage would be through the roof (as it was before the shared close feature was added).
-
QUOTE (ragglefrock @ Sep 2 2008, 02:29 PM)
It sounds like you might as well have initialized shift registers to maintain the data while that subVI call is in place, but not necessarily to save it for the future.Yes, in most cases I do have initialzed SRs that contain data passed from one execution of the loop to the next (consumer structure). There are a few cases where the code in one case generates a reference that is passed to the next execution of the loop. In those cases, the SR contains meaningless data until the case that populates it executes. After that, the SR has a valid refnum. This is hte one where I did not intialize the refnum. So, I suppose I could initialize it with a void refnum (in this case a queue) but I figured that would not serve any purpose other than clarity.
So, it sounds like I don't need to worry about data between loop executions even if I have 100's of instances of this reetnrat VI. They should all play nice and not step on each other's data.
Back the the drawing board...
-
NI has stated that you should not use the shared clones reentrant type if your VI has uninitialized shift registers (Functional Global). This is because the data space is shared between all instances of the VI so state cannot be maintained.
My question is, what about consumers that have uninitialized shift registers? Since these VIs stay in memory and are running continuously, shouldn't they be immune to this problem? Can I have many instaces of this reentrant VI all running at once, without any data loss/corruption as long as they are all actively running (and waiting for their queue to feed them the next command?) I think this should work, but since I am seeing some strange behaviors, it would be good to get some second opinions.
Thanks,
-John
-
QUOTE (Aristos Queue @ Aug 31 2008, 10:52 PM)
Can you post your code on ni.com for an AE to investigate? That's going to be the best way to get NI to push further on this.I could zip up the code and send it to them, but they would not be able to run it. The code relies on a continuous flow of data between an in-house SQL server and the application. I suppose they could inspect it, but that would be about it.
Also, since I only see this error from the EXE version of the code and only after 100's of units are tested (many days of testing), I suspect it would be nearly impossible. My only hope now is to have an NI engineer visit our site and see the code in action or to find the bug myself. It would be great if I could find something I screwed up that is causing this, but I can't think of a single thing that could. I wish I knew of another condition that could cause the refs to become invalid...
Regarding the launcher, no, that part of the app continues to run even after the error. It displays the status of each of the spawned VITs and allows you to view their FP via another VI with a sub panel. I am able to interact with it even after the error is reported. Just not the VIT that reported the error.
-
QUOTE (Val Brown @ Aug 29 2008, 12:55 AM)
I use the Database Connectivity Toolkit instead of just using ADO/DAO or LabSQLFWIW, the Database Connectivity Toolkit is just a wrapper around ADO.NET. And not a very good one at that. It is extremely slow when working with large record sets.
If you truely want to be native, then write your own DB VIs calling ADO.NET yourself. If you use some of the tricks from Brian Tyler's old blog, you can get a 10x+ speed improvement.
-John
-
QUOTE (Aristos Queue @ Aug 29 2008, 08:25 PM)
That was the other thing I was going to say ... not only would you have to allocate millions of queues, you'd have to have them all continuously in play in order for the refnums to ever hit up against each other. Now if somewhere you're calling Obtain Queue and you're not calling Release Queue, you might be running your machine out of memory, and perhaps something strange is going on there (though I still can't imagine what would just cause the refnum to get deallocated).Well, I do not allocate millions of queues, but I do allocate 1000's over the course of running the app.
My concern is this: I spawn many instances of a VIT to run a set of tests on a product. Each of these instances is composed completely of reentrant VIs (so they will not block each other). These reentrant VIs are all of the 'shared clone' type. They create the unnamed queues and pass them around to move data between parallel portions of the program. The only code in the entire app that can kill these queues is in the cleanup VI that is forced by dataflow to be the last thing executed by this spawned (from the VIT) vi.
Now, the launcher that spawns these VITs sets the spawned VI to Autoclose reference. So, the launcher is not responsible for dealing with this reference. When the spawned VI finishes execution, it will leave memory, as will all of its queues, notifiers, etc.
So what is confusing to me is if each spawned VIT creates its own queues (in sub VIs) and then listens to the queues (in other sub VIs), and the only code that can destroy those queue refs is also in a sub-VI of that VIT that is forced to execute last by dataflow, how could I ever get the error "Refnum became invalid while node waited for it.". Even if the VIT was stopped by an external VI, this error would never happen and the code that logs the error to the event log would also not execute. So, something is stepping on my queue refs. If it was memory corruption, then what could be causing it? When I see this, my app is using about 100MB. The machine has 4GB of RAM and no other apps are running.
I suspect that the 'shared clone' reentrant mode and queue refs have some latent bug.
-
QUOTE (jdunham @ Aug 29 2008, 04:07 PM)
QUOTE (Aristos Queue @ Aug 29 2008, 04:18 PM)
We don't use a true GUID. We use a fixed count for the first several bits and a random value for the last few. In order to get any recycling of the unnamed queue IDs you would not only have to generate roughly 30 million queues, you would also need to get particularly (un)lucky on the other bits. That seems unlikely.What about memory corruption? I notice that when this problem occurs, the whole app also starts to slow down AND memory usage starts to increase.
BTW: This problem only happens in the EXE deployed to a target machine and only after running for several days. So, I really have no way to debug it with breakpoints or anything. At least I log the errors to the event handler...
-
QUOTE (PJM_labview @ Aug 29 2008, 02:56 PM)
Yes, if I was creating the queue that way, it would be a problem. But I am not.
http://lavag.org/old_files/monthly_08_2008/post-2411-1220050049.jpg' target="_blank">
The Dequeue element gets an error stating the reference has become invalid while waiting. How could this happen??
-
Thanks for the reply. That is definitely a way to cause a queue to be deallocated. In my case, however, I don't think that is possible. The structure of my code has a main vi that calls a sub VI to create the queue and then passes the queue ref to another sub VI that listens to the queue. When the listener quits, it passes its error cluster to the sub VI that destroys the queue. Since all of these VIs are part of the main VI, i don't see how it is possible that the queue reference would be automatically removed from memory. The VI that get the error is running as a sub VI of the same VI that called the VI that created the queue.
The interesting thing is everything seems to work well for a long time and then it all goes to heck. As you can see from the error, the 'main.vi' has been spawned from a template 422 times and the reentrant subVI that got the error is one of 34 in memory right now, all listening to their own 'version' of this queue.
I think the LV engine get 'confused' and screws this up. I can see many examples of this happening in various parts of my code where queues either become invalid while waiting or are invalid when passed to a subVI, even though a release was never called and their creator VI is still in memory and supposedly 'reserved for run' still...
Perhaps there is some issue with all these VIs being reentrant? I only use the shared clones mode, but none of them have a uninitialized shift register...
-
I have run into a very strange problem. I am getting sporatic occurances of an error with one of my queues. Here is the error:
Error 1122 occurred at Dequeue Element in Process GUI Events.vi:34->Engine 422.vi
Possible reason(s):
LabVIEW: Refnum became invalid while node waited for it.
The wierd thing is, as far as I know, this can ONLY happen if the queue is destroyed in some parallel process while this VI is waiting for an element to be enqueued. But, I have searched all the VIs and the only one where the queue is destroyed is in the cleanup VI that comes after this VI and is connected by the error wire. So, there is no way that cleanup VI could execute before the VI that is waiting.
I have a sneaking suspicion that there are some latent bugs in the queue feature. I have a large number of reentrant VIs running and I create a lot of unnamed queues that I pass inside a cluster to sub VIs. So, there are many many instances of this queue (all unique, supposedly) that exist within each tree of reentrant VIs. I thought labVIEW used a GUID to name unnamed queues so they could never step on each other, but maybe because I have so many, the 'name' is getting reused?
Any other ideas? I am at a total loss.
thanks,
-John
-
QUOTE (Val Brown @ Aug 28 2008, 03:01 PM)
Does this make use of any OpenG code or is it all native LV?This example is strictly standard LV code. No add-ons of any kind were used.
The example is written in LV8.5. I don't have older versions so I cannot down-rev it if you do not have 8.5. I would avoid .NET in 8.2 anyways since there were significant bugs.
That said, I use OpenG in many places in my apps and strongly recommend other use it too.
-
I'm not completely sure I understand all your questions, but if you are asking if this format can be read, the answer is yes. However, I have found that in LabVIEW, you cannot make a generic XML reader easily. In most cases, you need to know the format of the XML document when you write the LV code to parse it.
That does not mean that you cannot have variable length sections, like you excerpt shows. You can use the features in the MSXML.NET assembly to determine child count and iterate through the elements, building an array in LV. This is something I do all the time. I have a much more complex XML file that describes an entire test hierarchy that has N test plans with N test suites, each with N tests, each with N parameters and N measurements. I am able to read this into a complex array of clusters of arrays of clusters, etc...
So, it can be done, but you need to think carefully about the structure of the XML you will receive and then design you code to deal with the sections that are variable in length.
I also noted that your example stored the data in elements but still used attributes to specify information about each element. So, you will need to deal with extracting that part of the data and use it to organize the elements in their proper order, unless you can assume they will always be formatted in ascending numerical order (which is likely but nothing is ever guaranteed).
Anyways, I think the example code gives you a good start toward reading this but I suspect you will need to modify it to fit your format. My goal was not to make a generic XML reader but rather demo the basics of accessing XML data and protecting it with a schema.
You might also check out JKI's EasyXML tools. I think they might be useful to help parse your XML.
-
QUOTE (MJE @ Aug 26 2008, 05:37 AM)
My only suggestion would be to stay away from the XML file specifying the schema file.Yes, that is an option, but then they would have to select the schema file or I would have to hard code it's name into the code. Also, if I choose to put the schema in another directory, I would have to hardcode that full path into the code. If I left the schema in the same directory and used the reletive path of the XML doc, then there is nothing that would stop them from seeing it and editing it as well.
Finally, by having the schema specified in the XML and having it local to the XML, other XML editors can use this to enforce the schema when editing the file. This helps avoid errors when making edits. My goal is to help the user not make a mistake when editing that would cause the file to be unreadable. If they wish to be malicious, then I really don't care.
But if someone sees value in having the schema specified externally, that can be done. As one of my old professors used to say: 'That exercise is left for the student'.
BTW: I'm glad you like the callback trick! I'l have to post a few more examples of interesting 'tricks' I have come across over the years...
-John
-
-
Here is an example of how to read an XML file, extract attributes of elements and also validate it against a schema.
I use this to read user-editable configuration files for my project. By using XML with a schema, I can control the format of the file and verify that it adheres to this format when reading it. This allows me to abort application startup with a meaningful error message if someone makes an invalid edit to the configuration file.
This is also a good primer on how to read XML files using .NET calls. I hope you find this useful.
I also suggest you read some of the tutorials on the net about XML and XSD (schema) to understand how to create and edit your own files. In addition, I recommend XMLSpy by Altova for working with XML and XSD files.
-John
-
Here is an example of how to read an XML file, extract attributes of elements and also validate it against a schema.
I use this to read user-editable configuration files for my project. By using XML with a schema, I can control the format of the file and verify that it adheres to this format when reading it. This allows me to abort application startup with a meaningful error message if someone makes an invalid edit to the configuration file.
This is also a good primer on how to read XML files using .NET calls. I hope you find this useful.
I also suggest you read some of the tutorials on the net about XML and XSD (schema) to understand how to create and edit your own files. In addition, I recommend XMLSpy by Altova for working with XML and XSD files.
-John
-
My local NI rep just told me about a new OOP training class that is being offered on a Carnival Cruise out of Galveston, TX. If you don't belive me, go to NI's site and look up the OOP class and check the schedule.
http://sine.ni.com/apps/utf8/nisv.custed_d...ce_list_id=1000
-John
-
At the risk of inciting controversy or being redundant to other threads in the past, I am wondering how many people feel that LabVIEW should change its image with regards to the programming language G?
I grow weary of constantly having to explain to people what 'LabVIEW' is. Most seem to think of it as an application, like Excel, that interfaces to other 'real' code. I have a hard time convincing them it is just the development environment for writing programs in the G language.
I also am tired of having all of the applications I create generically referred to as 'LabVIEW'. Often, co-workers will say "this is where our C code is called by LabVIEW" and I want to correct them and say, "no, this is where you C code is called by the test system, that just happens to be written in G. It could have been written in any language and LabVIEW has nothing to do with it." The reason this bugs me is they try to blame errors in their interface on LabVIEW. Lack of understanding breeds fear and contempt.
And NI is not helping matters. I really think it is time they stop calling it LabVIEW. Or, at the very least, make a separate version that is strictly for G programming and have all the HW specific stuff be an add-on called LabVIEW. I mean, how many of us do anything that has to do with a Lab anymore? LabVIEW has left the lab and is out in the world doing everything, everywhere. It needs to be rebranded if it wants to get wider acceptance.
So, here are my crazy ideas:
Call the dev environment something other than LabVIEW (G-View?, DataFlow Studio?)
Make a stronger effort to call the language G and not LabVIEW.
Change the name of VIs to something else. They are not virtual instruments, they are user interfaces, sub routines, functions, etc... And change the file extension to .g
Make the point that any application can be written in G. And if that is not true, then work to add features to make it true. I know more and more of the features of each release are written in G. Why not work towards going all the way and have the G compiler written in G! That is one definition of a true programming language that a lot of CS people use. NI should strive to reach that goal.
Well, that is enough ranting for now. I feel better already. I suppose if no one agrees, then this thread will die quickly and I will get back to work. But, I do hope there are others out there who long to be understood by their co-workers and employers as true software developers.
-John
-
If you are worried about the user editing an INI file and putting in bad values, my solution is to use a small XML file and an .XSD (schema) file. When the app boots, it reads the xml file for its 'ini' settings. I first validate the XML against the schema to verify it has no errors. If they messed up the XML, then the app will report the error and what line is invalid, then exit.
This is not that hard to do if you have used any .NET functions before in your LV code. I can post some examples if that would help.
-John
-
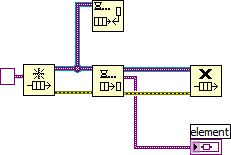
There is always a way to avoid the sequence structure... -
QUOTE (BobHamburger @ Aug 20 2008, 09:30 PM)
As far as I'm concerned, I wouldn't miss it if the sequence structure were completely removed from LabVIEW. IMHO, it simply has no place in the dataflow-dependency paradigm.Like I said in my post above, there is still a GOTO statement in C, but nobody uses it anymore! So, removing them may not be a good idea, but LV training classes should definitely show new DEVs how to avoid them.
Actually, they are a good indicator of LV exp when reviewing someone's code who applies for a position.
I am afraid the new diagram cleanup feature may help hide some applicants lack of experience. But, on the other hand, it might help teach them good style...
-
QUOTE (crelf @ Aug 20 2008, 07:51 AM)
That might be true (don't know without any metrics), but that doesn't necessarily make it unusable.I agree with that. I also use .NET a lot in my code. It is great for accessing lots of powerful OS functionality. I also use it with XML files and databases. Like I said in my first post, the only cavet is to not do any large enumerations within a loop. Unfortunatly, since .NET was designed to work with Virtual Machine languages (VBScript, JavaScript, etc), most of it's data access is in the form of enumerations (get the count, then loop on the count and get each item) instead of passing blocking of memory directly.
The ArrayList 'trick' on Brian's BLOG shows how to get around this. I use this when retriving record sets from a database and it speeds things up by at least 20x.
The problem is the overhead LabVIEW experiences when calling out to .NET. I will see if Brian can provide a description of this and what, if anything, can be done to improve the situation.
-John
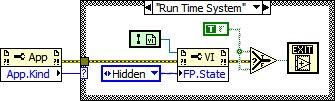
One and two button dialogs that stay out of the root loop
in User Interface
Posted
Well, I managed to get the 3 button dialog to do most of this by modifing the source code. I ended up changing the server call to center the window to instad call a subvi that takes the call chain and searches it for the nearest parent with an open window and then centers itself inside that window. This is as close as I can get to what the system dialogs do.
Looking forward to the refactoring of the 3 button dialog by the coding challenge, if anyone has time to do it. If you want to add my little trick, let me know and I will post the VI.
-John