

John Lokanis
-
Posts
797 -
Joined
-
Last visited
-
Days Won
14
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by John Lokanis
-
-
QUOTE(LV Punk @ Dec 14 2007, 04:09 AM)
launching 100s every minute from several instances of a reentrant vi ?
?Care to describe your system a bit more?
Sure.
I am building a test executive that is capable of testing N units at the same time. Each unit under test can have N tests, all of which (in theory) can be executed at the same time. So, for a given unit under test, the test executive will spawn a test engine that handles all testing operations (including a UI that is viewable on demand in a sub panel) and will also report back status to the test executive (overall progress, time, pass/fail/etc). Each engine will get the proper test suite from a database and then will start launching tests. It will launch tests until the unit under test returns a test blocking issue (shared resource needed). It will then wait for the block to go away and will resume launching tests. Meanwhile, another thread in the engine will monitor results coming back from completed tests. Since all the tests are plug-in VIs loaded from an external library of VIs, the engine launches a handler for each test that monitors it's status, performs watchdog checking and passes the results back to the engine before self terminating.
It is this handler that I am trying out the pass by queue call method.
The engine is currently a VIT. All of it's subvi's are reentrant, since I need to spawn N of these engines at any given time. The hander is also reentrant, obviously. And all the tests are called reentrantly.
The engine itself has 6 parallel threads (Incoming GUI, GUI Handler, Test Result Monitor, Test Launcher, Database Hander, Two independent Tree Control threads (I use two trees to display state and results)). Since the only limit to the number of tests running in parallel is the target hardware, there could be (practically) 10 tests running at once on each DUT. If I am testing 50 DUTs at the same time, that would be 50(duts)*(6(threads per engine)+(10 tests + 10 test handlers)) = 1300 parallel threads in a moderately loaded system.
That is why I have dual quad core Xeons and 4G RAM in the box.
Also, even though each step in the system is not super CPU intensive or time critical, the sum of all the VIs running at once is significant. So, I have needed to be vary careful about not blocking other threads and staying out of the UI thread as much as possible. For that reason, my Tree threads maintain tree state in a shift register and only update the actual tree control when the user requests to see the test details.
It has been interesting to see just how far you can push this parallel programming stuff and what pitfalls are out there. Maybe I'll write a book if I ever get this project done!

-
Thanks for the replies.
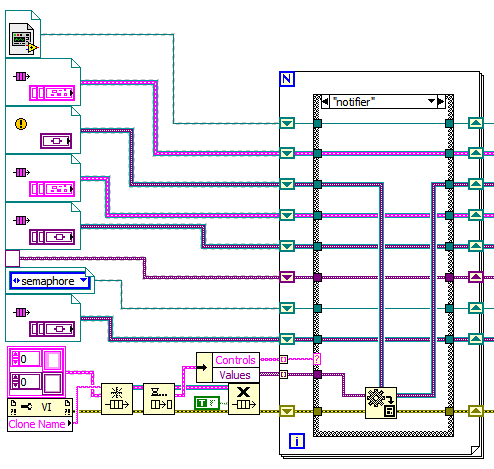
The Xnode solution looks a lot like the VI I wrote to write the values directly (using option1). I am still concerned about the thread swap to the UI thread when doing this. I am launching 100s of these VIs from several instances of a reentrant VI every minute in my system and want to avoid anything that might make a bottle neck. That is why I came up with the queue idea. Here is a screen shot of the VI that gets the data:
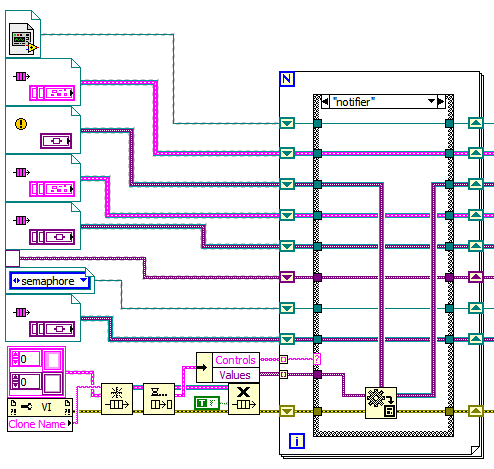
As you can see, all you end up with is the wires with the data on them, just like they had come from a FP control.
I have also attached the VI that is used to send the data.
-John
-
I have been trying to figure out the best way to pass data to a dynamically spawned VI. Here is the setup
The VI is reentrant.
I want to have the VI run independently (don’t wait for completion), so I cannot use call by reference. I must use the Run method.
I need to pass in a bunch of input parameters of varying data types.
Option 1:
Open a reference to the VI.
Pass in input parameters by using the Ctrl Val.Set method to set the FP control values.
Run the VI
Option 2:
Open a reference to the VI.
Get the new VI’s clone name.
Create a Queue of (cluster of string and variant) type using the clone name to name the queue.
Fill the Queue with the input parameters (using the string for their name and variant for their value).
Run the VI.
Inside the VI, Obtain the queue from the clone name.
Dequeue all the elements, feed them into a for loop and use the string to select a case for each value.
The for loop has a shift register for each expected parameter value.
In each case, set the value of the appropriate shift register using the variant. (use the Variant to Data function). It helps if you initialize all the shift registers with a constant of the expected data type.
Take the output of all the shift registers and use them as the input parameters in your code.
Do a Force Destroy on the clone named queue.
So, why for option2 since it seems much more complex? Well, the idea was the Ctrl Val.Set method modifies FP terminals so it should/might/does cause a thread swap to the UI thread, something that is not good when speed is concerned. Also, option 2 means you have no FP terminals at all, so the VI should stay completely out of the UI thread (unless you do something else stupid).
What do you all think? Am I chasing my tail or is this a good idea?
-John
-
QUOTE(LV Punk @ Nov 30 2007, 04:14 AM)
I read your posts on Info-LabVIEW and I can understand your pain.I recall reading this BLOG post by Brian Tyler made in February 2007. I immediately thought "What impact might this have on LabVIEW".
I too was sorry to see Bryan go. Even though he is now living in my neck of the woods, he was a great resource to me when he was at NI. I am actually using tow of the .net techniques he bloged about in my current project.
I have added to a thread on the NI forums about this issue as well. You can read it here:
http://forums.ni.com/ni/board/message?boar...ssage.id=287625
Here is the workaround I have be using with some sucess and much pain:
To work around this issue, you need to rewrite your VIs in 8.5. You cannot have any of the offending VIs open while fixing a VI or have ever opened them in your current session of LV8.5. Here is my process:
1. Open a bad VI.
2. Take a screen shot of the block diagram.
3. Paste the screenshot into any image editor/viewer so you can refer back to it.
4. Delete any .net nodes in the block diagram that call the GAC assemblies. Also, delete any refnum controls or indictors that you might pass in or out of the VI that refer to GAC assembly references.
5. Save the VI (it will be broken).
6. Close the VI.
7. Reopen the VI and verify you do not get the GAC warning message.
8. Close LabVIEW 8.5. (You must do this so LabVIEW 'forgets' about the GAC assemblies location. Otherwise, if you try to fix the VI now, it will just be broken again.)
9. Open LabVIEW 8.5.
10. Open the edited VI.
11. Recreate the VI components you deleted, using the snapshot as a guide.
12. Be sure to reconnect any front panel terminals to their proper points on the connector pane.
13. Save the VI.
14. Close the VI.
15. Open the VI and verify you do not get the GAC warning.
16. Test the VI (if you can test it in place).
Repeat this for every VI you have that has .NET nodes and/or front panel terminals that are associated with any assemblies in the GAC.
Special note: When you load a VI that calls other VIs that you already fixed, they will be re-broken in memory. After you delete the offending nodes/terminals from the parent VI, save it BUT DO NOT SAVE the sub-vis or you will re-break them. After you restart LabVIEW, to fix the parent, the sub-vi should load ok without the warnings. If you ever see the GAC warning after restarting LabVIEW to fix the VI you edited, stop what you are doing and retrace your steps. You could easily re-break everything you are doing if you are not careful.
I am 2 days into my edits and about half way done. So far, so good. Fingers crossed. I have even tested some of the fixed VIs and they will now build, so I am confident in the workaround.
-John
-
If you try to open a VI wtih LV8.5 that uses .NET but was written in LV8.20, you will get an error similar to this:
C:\Development\Source\Common\SQL.NET\SQL.NET Open SQL Server Connection.vi
- The .NET assembly expected to be at "C:\Development\Source\Common\SQL.NET\SQL.NET Open SQL Server Connection.vi\<GAC>\System.Data" was loaded from "<GAC>\System.Data".
This is even after first converting the VI to 8.5 and even mass compiling it.

The VI will still run, but you cannot build an EXE using the VI.
The only solution is to re-write the VI from scratch in LV8.5.
To do this, you must memorize the VI's code or take a screen shot of it, then CLOSE LabVIEW. Then open LabVIEW again, start with a blank VI and build the VI from the screen shot. Then Save the VI when done. DO NOT open any of the 'broken' VIs at the same time as you are editing you new VI, or it will corrupt the New VI and you will have to start all over.
Repeat these steps for any VI that uses any .NET assembly. :headbang:
There is no fix. This has been stated to be a known issue and we will have to wait for 8.5.1 or whatever they call it to get this working.
So, unless you do not use any .NET or you have a lot of free time on your hands, DO Not upgrade to 8.5...

(no, I am not upset at all...)
 :beer: :beer: :beer:
:beer: :beer: :beer: (sorry for overdoing the emoticons...)
-
QUOTE(Anish Prabu @ Nov 17 2007, 08:05 AM)
I have modified your code little bit to avoid the unnessary memory allocations. See the code for details. the Array that is unbundled is passed as a tunnel and edited (replace array element) so LabVIEW duplicates the memory for the array.The modified code makes use of the same memory of the complex data structure.
- Anish Prabu T.
CLA
Thanks! This looks like the least amount of buffer allocations possible.
For those of you with exp with the map class, will that really improve the memory useage of this complex array? I thought I remember reading somewhere that LV stores arrays as linked lists already, so using the map class to construct a linked list would be functionally equivalent.
-
QUOTE(Anish Prabu @ Nov 17 2007, 08:05 AM)
I have modified your code little bit to avoid the unnessary memory allocations. See the code for details. the Array that is unbundled is passed as a tunnel and edited (replace array element) so LabVIEW duplicates the memory for the array.The modified code makes use of the same memory of the complex data structure.
- Anish Prabu T.
CLA
Thanks! This looks like the least amount of buffer allocations possible.
For those of you with exp with the map class, will that really improve the memory useage of this complex array? I thought I remember reading somewhere that LV stores arrays as linked lists already, so using the map class to construct a linked list would be functionally equivalent.
-
QUOTE(Norm Kirchner @ Nov 13 2007, 12:31 PM)
I have always supported not using the display of the tree to store the data, rather, storing the data in a separate source and merely using the tree as a tool to display that data when needed, which goes in-line w/ what you are trying to do.Maybe this code snibbit will help show what I mean when I say "assist"
http://lavag.org/old_files/monthly_11_2007/post-208-1194985856.jpg' target="_blank">
I see you are using Varient Attributes. While this is a natural data structure for representing a tree of data, I have found that accessing/adding/updating attribute elements is a very slow process in LV. I suspect that this is due to the memory allocation issue again. This would be fine for small datasets, but in my case, the tree is displaying a 24 hour looping test with over 100 elements per loop, and 100s of iterations in 24 hours, so the dataset gets huge fast. Couple that with the multiple instancs of this strucutre (50-80 on average) and my poor 8 core 4GB PC comes to a grinding halt!
I am thinking I may need to start over with this whole process.
-
QUOTE(Norm Kirchner @ Nov 13 2007, 11:45 AM)
Something just smacked me right in the face w/ regards to inplaceness and memory structures and variant attributes.I'm assuming that if you try to store data in the Variant DB that the compiler can never figure out if you are doing in-place operations/modifications of an already existing attribute.
Does anyone have feedback on that?
The reason being, is that I have created some modifications to the TreeAPI that allows you to embed data with a specific tag and have it travel around w/ it. The problem at the moment is that I store the data in a Variant DB.
I'll post the code to the CR discussion board soon.
I am wondering the same thing. How can I do an 'InPlace' edit to my structure if that edit is to replace a string with a longer one? Or, add an element to a sub array of a cluster? This seems like it would force a memory allocation. My problem is finding a way to represent the data a Tree control can contain but outside the Tree Control itself. This data is quite complex when you get into multiple child rows and cell BG colors. I used to just write the data to the tree 'on the fly' but when you have 80 instances of the VI with the Tree all running in parallel and you don't need to display any of them unless a user chooses to, it seemed like a better idea to store the 'source' data in an array of clusters and then only write to the tree when it is displayed.
Anyone have a better idea? I am about to abandon the tree control altogether...
-
QUOTE(ragglefrock @ Nov 12 2007, 10:42 PM)
The new Inplace element structure would indeed help avoid extra memory allocations, but you can also get about 90% of the improvements you'd see here without it, simply by keeping an important thing in mind regarding LabVIEW's inplaceness algorithm, which I'll explain.LabVIEW is really good at operating on data inplace when you unbundle something, then bundle it back in. However, LabVIEW can't be certain when it's safe to operate inplace if you either unbundle or bundle conditionally. That's exactly what you're doing, and it's causing LabVIEW to back up the entire data structure for every operation, which becomes exceedingly costly. To avoid this, try to always unbundle and bundle regardless of the situation. In other words don't place one of these nodes in a Case Structure when you don't have the partner node in that same Case Structure.
The better solution in your case would be to always unbundle the data, but then to decide whether you bundle back in the same untouched data or the modified data. LabVIEW's a lot better at processing that.
It's true that the inplace element structure would save you an extra allocation when you index and then replace array subset. Here LabVIEW always makes a temporary copy. However, I'm guessing this is not the cause of the big problem you are seeing. I'm attaching a modified version of your VI below. Note that I really didn't spend much time analyzing this except to make sure the buffer allocation dots went away for the main Tree Data structure. You should definitely double-check everything to make sure it functions the same as it did.
Thanks for the reply and the VI. Unfortunatly. I am still stuck on 8.20 at this time. Any chance you can post an 8.20 version of the VI or a screenshot of the important changes ot the BD?
I will try to edit the VI based on your comments above in the meantime.
Thanks again,
-John
-
I have a very large application that is experiencing a memory fragmentation problem. The root cause of the problem seems to be the fact that I am building and modifying an array of complex clusters. This data structure is used to mirror the data displayed by the tree control. I have done this to avoid writing to the tree control until the user chooses to display the VI that contains the tree. The idea was to encapsulate all GUI writes into a single VI and to avoid them altogether if the data is never requested to be displayed. But the result is a large and ever growing data structure that slowly fragments the memory of the PC until the app slows to a standstill. In my app I create N instances of this data structure to track all the DUTs being tested and then I run it for 24 hours. So, by the end of the test period, 100s of MB have been consumed and every little memory allocation takes forever.
After digging into the code for causes and solutions, I find that there are some functions where memory buffers are being created that I don't understand and can't seem to eliminate. These allocations seem to be making copies of the entire data structure and some of it's largest components, causing ever increasing memory allocations. I was hoping someone could point out the obvious mistake and offer a solution.
Also, I was wondering if the new InPlace structure in LV8.5 could solve this problem. How complex can the code within the InPlace structure be and does ALL of it have to be in place operations?
Attached is the code and an RTF document with some screen shots of the code showing the offending allocations.
Thanks for any ideas you can offer,
-John
-
I have built applications that use this concept. I even have one where there are two parallel loops, each with its own event structure. The top one responds to user interaction. The bottom one runs the test process. They can fire events at each other to start tests or to exit when done or an error occurs. This seemed like a good idea at the time but ended being very complex to 'keep straight in my head' and therefore, to debug. Here are a few reasons why I no longer do this:
1. You can fire off events within the event structure to 'queue up' the next event, but once fired you cannot recall them. So, if you are in one event case and you decide to fire off a series of three cases to perform the next 3 needed operations, then you are stuck with that order. If the first or second one of those cases produces an error, you cannot go to the error case until all three complete.
2. There is a much better way to accomplish this with a queued state machine. I didn't know much about these when I first tried the event state machine concept.
3. Events seem to work best when there is some sort of asynchronous interaction happening, like a human or an external device. I use an event structure to poll a TCP connection (using the timeout case) and place the data into a queue which is then processed by a consumer loop. Sometimes, the data sent to the consumer contains a pattern when requires something to be sent out the TCP connection. In that case, I fire a user event from the consumer to tell the polling event loop to send the necessary command to the TCP port and then go back to polling for new data. This works very well.
Good luck with your implementation!
-John
-
Well, I think I have this working as fast as possible now. Since the only feature of the cell that I use and that cannot be defined with the Add method is the color, I have changed my code to only write color changes to the cell properties for new rows. This sped it up a bit but it is still quite slow. I also am using a dialog box with a progress bar to entertain the user while the color updates are completed. I used a few tricks to only show this dialog for long updates (more than 300 rows).My GUI design requires each row to potentially have a different color in a specific cell. This is because I am using the tree to show test results and I want to color the cell that shows PASS or FAIL in green or red, respectively. So, the idea of coloring a whole column at once would not work, unfortunately.the real solution here is for NI to extend the Add method to include inputs for setting the cell colors, fonts, text sizes, etc... This could be done by passing in arrays for the child cells and element for the leftmost cell. This would allow the functionality of the control to be extended while still being fully backwards compatible with the current implementation. The Add method really needs to support all elements of the control.Another alternative would be to create a data type that could store all the tree information. Perhaps a typedef's cluster or arrays of clusters? The point would be to be able to write this data to the tree control in one action and have the tree display the data instantly. That would allow the developer to build up this data structure in their code quickly and only write it to the control for display when the GUI is needed by the user.Anyways, I hope someone at NI is paying attention...
-John
By the way, nobody seemed to notice or comment on the fact that writing the cell colors from the last tag to the first is faster than writing from the first to the last. Doesn't this seem strange to anyone? My first guess what it was a memory allocation effect (by writting the last tag first, you allocate the memory for all the cell colors at once) but this seems strange since the Add method should be allocating the entire memory structure at once. Any ideas?
-
Unfortunatly, the coloring of the cells is an integral part of my display, so eliminating that is not an option. I will try your idea about only changing the color in the for loop and moving the symbol and test changes to the Add function call. If only I could specify the color of each cell in the add function...
Thanks for the idea.
-
Note: My comments apply to LV8.20. If you are using a newer version, YMMV...
I have been trying to find a way to manage the Tree Control better in my code. I use a Tree to show the results of a series of tests. This works nicely since the tests are hierarchical in nature. My system can test many DUTs at once but I only display the results on one DUT at a time. So, I build a parallel data structure to hold the information normally written to the tree and I only update the tree when the user selects a certain DUT. This eliminates writes to the tree control except in cases where the user actually want to see the detailed data.
Unfortunately, writing to the tree is VERY slow. Adding items is quick when you use Add Multiple Items To End, but if you also want to set the colors of individual cells, then it is painstakingly slow.
The usual tricks of Defer Updates helps a little, but not much. So, I came up with an experiment to see what can be done about this. My discovery was that the order you access the tags in the tree dictates how slow that update is. If you write your changes form the first tag to the last, each write gets slower in an exponential manner. If you update in reverse order (last tag first) then the write speed is more constant (and quicker on average). Even so, it is still ridiculously slow.
I have attached a VI that demonstrates these effects. Take a look and try the various options. Please post your results here and if you find a better solution. As for me, my best results were with Defer Update on, Update Tags in reverse and Write Tag with each update. (the defaults of the VI). In this instance, it took about 49 seconds to run the VI.
thanks for any ideas you can add.
-John
-
I put the ideas in the thread to use and made an example of a transparent background splash screen that fades in and then stays visible while a startup process completes. Take a look at the attached VIs to see how this is done. You can replace the graphic with your own to customize this example.
Be sure to use the PNG format for your graphic. I recommend Paint.NET as a good free editor for creating PNGs. The one in this example was built by lifting a graphic off NI's website.
Hope you find this useful.
-John
-
Thanks for the code. I hacked together a simple VI to get around this issue for now. It only works on the formula left to right, one works with +, - *, / and will stop when it hits the end o the string or any non number or operator char.
see attached.
-John
-
Has anyone written a VI that will take a simple math formula in a string like:
1+2-3
4+(5*3)
3-(4+5)
And return the computed result?
I know that NI provides this function in the Eval Formula String.vi in the Gmath library but that is the problem. They put this in a lvlib file. I am trying to build an application with the OpenG builder that includes this function and discovered that the OpenG builder cannot deal with lvlib files properly. Since my application is dependent on the namespace feature of the OpenG builder, my only option is to reinvent this math function myself outside of a lvlib.
I have tried to find a way to extract this from the lvlib with no luck.
So, can anyone help me not have to reinvent this wheel?
Thanks for any help you can offer,
-John
-
I recently found a new way to get the reference of the current VI. There are several ways to do this but I think this new one is the cleanest I have seen so far.
The original way I used to do this was to open a VI reference to the tip of the call chain, as shown in the 'old way.jpg' attachment.
The problem with this method is it requires you to later close that reference (every open must have a close).
The second method I started to use was to drop a property node and link it to the VI. I would simply not use the output property. This is shown in the 'second way.jpg' attachment.
The new way is to just create a reference that is linked to the VI. I stumbled across this when playing around with passing object references to subvis. The only problem I see is there is no direct way to create this reference. You must always first create a reference to some FP object and then relink it to the VI itself. See the 'new way.jpg' attachement.
Does anyone know of any advantage or disadvantage to any of these methods?
thanks,
-John
-
I recently pointed this out to an NI Dev who is working on an improved Project view for a future release. They said they would try to resolve this issue. I agree it is very annoying as implemented now.
-
Not sure if this is a bug or a 'feature' but I have run into an issue that is causing me some grief:
I cannot register for an event on a FP object if the FP of the originating VI is not currently open.
Here is how to see this:
Make a VI that has an event loop structure with a register for events function. Wire a control refnum of a Boolean into the register function and select the value change event. Setup the event structure respond to this event and send the NewVal to the stop loop terminal.
Make another VI with a Boolean control and create a refnum for this control. Drop your first VI onto the diagram and wire the refnum to it.
Run this second VI and see it wait for you to press the button.
Make a third VI that calls the second VI. Close the first two Vis and run this new one. You will get a message that states:
"LabVIEW: The VI front panel is not open."
OK, so on some level it makes sense to not allow events for FPs that are not open, since you would not be able to manipulate those controls. But, with VI Server calls like Value(Sig), that is not really true. I often 'push' buttons on Vis that are not open to stop them or perform some operation remotely that the user could do if the panel was open. And, I often have Vis that I only show the FP some of the time (such as in a sub-panel when they are selected from a listbox). I still want to pass their FP refs down to their sub-vis and listen for events.
So, does anyone know some workaround for this that does not involve polling? That is how I have had to solve this so far, and I dislike polling almost as much as global variables...

Thanks for the input.
-John
-
I have a VI that I use a ton in my code. The problem is, it is kinda slow. I am looking for a way to speed it up.
The point of this code is to get a reference to a front panel control by name. The VI has an input for the VI Ref that has this control on the front panel and the name of the control to find (string).
The output is the control's reference.
I use this to monitor front panel objects from deep in my calling tree. One good example is to monitor an Abort button on the GUI's front panel and be able to stop a loop in some deeply buried sub-vi. The sub-vi just check the status of a button called 'Abort' on it's top static caller.
If you have any thoughts on how to accomplish this code in a way that uses less CPU cycles, please post it here.
thanks for the help.
-John
-
I am attaching the .llb again. I made some edits and improvements as well. You can now write data to nodes in the middle of the tree and the branches will be maintained. I also optimised the code a bit more.
BTW: This is written in 8.20. I don't have a 7.1.1. system setup to downgrade the code to an older version. Sorry.
-
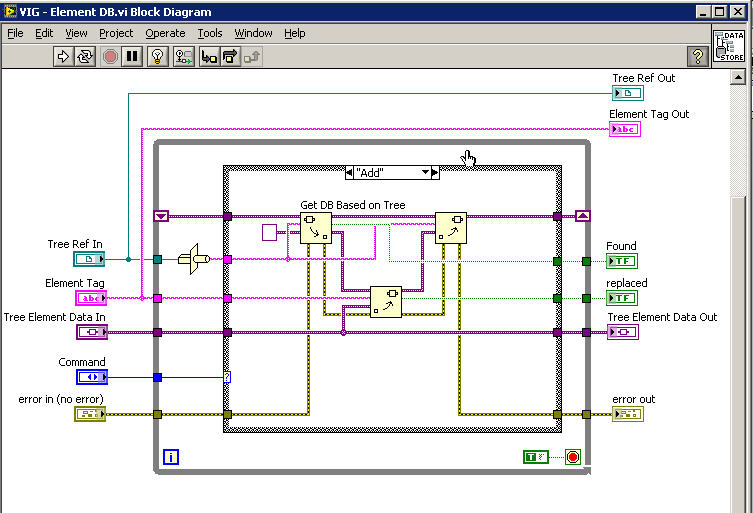
Hi,
I have put together a set of VIs to store data in a tree structure within LabVIEW. This method uses variant attributes to build the tree. Insertion is slower than a direct write to an array of clusters would be but reading back data is very fast. The reason insertion is slow is due to the dataflow nature of LabVIEW. The Tree must be rebuilt with each write.
Take a look at the code and let me know if you find any bugs or improvements. This would be a good tool to implement with LabVOOP, but I have not yet dived into that subject so it will have to wait.
The basic idea of the structure is that a variant can have attributes that are name-value pairs. The name must be a string, but the value can be anything. It can even be another variant that has it's own set of attributes. This is what enables the tree to be built. I have implemented three functions: read, write and delete. Each one operates on a single node in the tree. The data input is a variant. If a node in the branch path does not exist when writing, it is automatically added. The tips of each branch are the only places where actual data is stored in the variant. All branching nodes only contain attributes describing their sub-branches.
The path to a tip node is described as an array of strings. Each element in the array is a node in the tree that leads to the tip where the data is stored.
I also included some code that adds the top level caller VI name to the top of the path. This allows you to use the structure across several VIs and keep the data separate. We use this in a system where we spawn many VIs from a single VIT and need to maintain "global" local data.
Storage of the tree is implemented as a LV2 Global.
I hope you find this useful. If I have reinvented someone else's wheel, please send me a link to their code so I can compare and learn.
-John
BTW: When building this I found a bug in LabVIEW 8.20. The Get Variant Attribute function has an input called 'default value' that is supposed to default to an empty variant if nothing is wired. In practice, this function actually defaults to the last found variant from previous calls. So, to get it to work as described in the help, you need to wire an empty variant into this input.
Memory Fragmentation
in Application Design & Architecture
Posted
Just an update:
It was not memory fragmentation afterall but rather a resource leak cause by this little bugger:
Always always ALWAYS close the reference that this thing returns! :headbang:
So, in the end, as usual the problem was my own creation...
Time to go drink many :beer: :beer: :beer: ....