

John Lokanis
-
Posts
797 -
Joined
-
Last visited
-
Days Won
14
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by John Lokanis
-
-
Well, either way, I still want to encapsulate the reference. I just don't see why I cannot use a strict type VI ref in class data. I can use other type def'd data types in class data. What is special about this case?
-
I have a system class wrapped in a DVR that I pass to all processes in my application. This allows me to create communication channels between these processes (ie: a message system) and limit it to only the processes that I pass this DVR to. If I want to have two parallel systems, I just create two instances of the system class and wrap each of them in a DVR and pass it to the proper processes. This allows me to segment my system into multiple independent systems within one application instance. If I was to use a functional global as you suggest, I would be limited to a single 'system' within the application instance. (same as the current 'global' I am using)
Now, this does not matter as much if all the 'hander' VIs are based on the same reentrant VI, but it does come into play when I call my system cleanup code. I cannot put the close reference in there if I have multiple 'systems' within a single application instance with different lifetimes. Otherwise, I would 'clean up' the reference when one system was shutdown, even though the other system was still running.
I also wonder about the pool of shared clones. It might be more efficient to have each system create its own reference to use when dynamically launching processes because it might mean LabVIEW creates a separate pool of clones for each reference. But that is getting a bit more under the hood and we will need to hear from AQ or others about the reality of that situation.
-
- Popular Post
- Popular Post
-
 3
3
-
I am trying to solve a performance problem with my application and I have run into an issue I do not understand.
For some reason, I cannot create a class data element that is a strictly typed vi reference. I can create a generic one just fine, but if I try to make it strict, I get an error.
The reason I am trying to do this is to avoid the overhead and 'root loop' issues with the Open VI Reference call. In my application I am dynamically launching multiple child objects using a more generic 'handler' VI. I simply open a reentrant instance of this 'handler' vi, pass in the child class and the 'handler' calls my 'run' method in the child class via dynamic dispatch. The problem I ran into was the Open VI Reference was bogging down the system. So, I decided to use the Start Asynchronous Call with options 0x40 and 0x80. The idea was to open a single reference to my 'handler' when my application starts and then store this in the class data of an object that I pass to all my VIs (for data sharing). I would then use this reference to call the Start Asynchronous Call function (it requires a strictly typed vi reference). But, I was stopped when I tried to add the strictly typed vi reference to the class data.
As a workaround to prove my fix would solve my speed issue, I created a global variable (horror!) and stored the strictly typed vi reference in that. I then used this global when calling the Start Asynchronous Call function. This worked fine and my performance issues are gone. But I would really like to put that reference in a class instead of in a global.
I even tried using a generic vi refnum, thinking I could cast it to the strictly type refnum before sending it to the Start Asynchronous Call but I found that you cannot cast a generic VI refnum to a strictly typed vi refnum.
So, any ideas? This does not seem like a strange thing to want to do. Perhaps there is some reasoning behind it that I am not aware of. Any thoughts on a way to accomplish my goal via a different route?
thanks for any feedback,
-John
-
1
-
-
Here is a new idea I have been meaning to post:
Please take a look and Kudo!
-
Went to post on the exchange and found that the same basic idea already existed. So I am linking to it here. Please give this your Kudos...
Basically, I am looking for the property node to have consistent behavior when working with classes. For those of you who use property node access to your class data and use composition, this will lead to much cleaner code.
-
This topic is one of the reasons I gave up on source code control for the early stages of a project. I have reverted to the 'zip and copy to server once a day' method for backups. Once the project is stable and working, I will put the whole thing into Perforce for future maintenance. But at this point, I seem to rename 50% of my classes as I code them and decide they need to do something different or need to be split into multiple classes.
And don't get me started on how I should have designed it on paper first so I didn't have to rename so many things. I went into this project with exactly those intentions and I now believe that anybody who says they actually do this successfully is lying to you.
-
The class hierarchy window contains none of this information. It only shows you what classes are children of other classes. Messages are not children of the processes that execute them.
The VI hierarchy window is just a mess, showing every single VI connection from a VI perspective, but again, not the information I am looking for.
The node map is intended to show links between processes/actors via the messages they send/receive. This only works for messages systems where the message is a class. The idea is the process appears as a central node with the messages it can receive surrounding it. If one of those messages in turn sends a message to another process when it is executed, then a link is shown from the sending message to the receiving message.
The idea is you can see all the messages a process can be sent and you can see what other processes are sending what messages to each process. So, you can then trace the propagation of an action through the application.
For example: The user presses button X. The UI code sends a message to the UI message process that button X was pressed. The UI process then executes this message, causing it to send another message to the main controller process to execute action X. The main controller process then executes this message, causing it to send another message to the external comm process to send command X to some external device/application. The node map would show all those links so you could visualize what was happening and see the message flow. Ideally, you would be able to click on each node and view the underlying code in LabVIEW, but, I have not developed it to the point where that is possible.
I have not seen another method to help visualize the message flow of an application. I have looked at sequence diagrams but those show specific intra-process communication for specific conditions. They do not expose all the potential links in the system. Command pattern message based system are tightly coupled but it is not easy to visualize that coupling. I think we need a way to do this to help us understand complex system implemented with these type of architectures.
-
I am thinking of expanding on this for a CLA Summit presentation. But before I invest a lot of time, I am wondering how many others think a tool like this would be useful. If you are interested, please reply or 'like' this post so I have an idea of the level of interest in this subject.
thanks,
-John
-
1
-
-
Yes, always from inside the project. I cannot reproduce the 330x result. This is what I get running outside the project from the desktop:
Of course, now I get the same results from all locations. Must have been something weird about my machine at the time.
(Also running Win7 and LV2013)
-
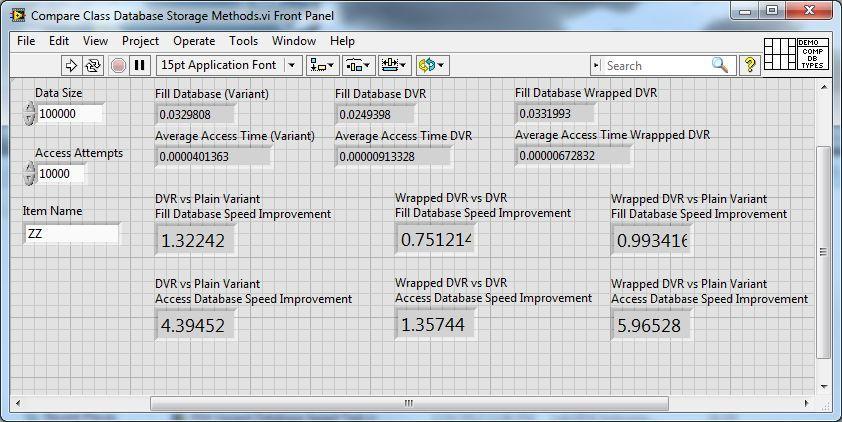
This is a very strange problem. I have put together a demo project to demonstrate the speed differences in array vs variant attribute storage methods. I also included a test of different variant database designs to show some pitfalls.
I first built this project in the following folder on my machine:
C:DevelopmentSourcesandboxVariant Attributes
It seemed to be working well and demonstrating the effects I was after.
I then moved the folder to my desktop:
C:UserslokanisDesktopVariant Attributes
When I opened the project from here, and tested it, the demo ran 1000x faster and no longer demonstrated the effect I was after.
Next I tried moving it to here:
C:tempVariant Attributes
And I got a result closer to the original location but still not the same.
Here is the code: Variant Attributes.zip
Run the VI: "Compare Class Database Storage Methods.vi"
Any ideas what is going on?
BTW: the point of the demo is to show that storing large elements in a variant database is faster if you store DVRs of the elements. This should avoid large data copies.
-
Cool. Now what other speed improvements are lurking under the hood that we don't know of yet? It would be nice to have a list so we could re-factor our code to take advantage of them.
-
Interesting. I just tried removing the indicators outside the frame and turning off debug and error handling. I saw no difference in the absolute speeds or the relative speed factor between the methods. I wonder why you see a difference.
-
LV 2013 added a new function (or just exposed it) that gets the name of a class.
I wanted to see if this would be faster than the old method I used before based on the path of the class. So I created a little experiment. It turns out the new functions is MUCH faster.
I am concerned that what I am seeing is real, however, and not due to some compiler optimization with the way I created the experiment. So, please if you have a moment, take a look and tell me what you think.
(I added code to strip the file extension because that is the use case in my application, but removing that makes little difference.)
thanks,
-John
ps. If you are wondering, I am using this in a logging operation of message system, so improving speed is important since every single message sent will cause this code to execute.
-
I have that but it does not work for some reason. Still does not address my issue. (even if it did work).
-
I have looked at that but don't see a function that does what I am trying to do. Maybe I am missing something?
-
Does the clone class function rename the new class FP controls correctly in this version (when cloning native LVOOP classes)?
I have also seen a lot of LV2013 crashes when cloning a class. Seems (anecdotally) related to having additional VIs open (not in the source class) that have broken arrows. It also does not like it if I switch to my mail program while the cloning is being performed.
-
Has anyone come up with a way to auto-update the accessors for a control in the class private data when you change it's type or rename it?
I find myself doing this a lot as I re-factor code. It means removing VIs from the project and then deleting them on disk, then building new accessors. Or, I could manually edit the accessors but that is even slower.
I am just curious if anyone has created a scripting VI to automate this.
thanks for any tips.
-John
-
Updated the thread on the NI site. Please reply there.
-
Yup. That thread is exactly what I am doing. Wish I would have seen that first. It would have saved me a lot of time.
Still agree that we need IPE support for attribute access. That would still improve my solution.
Well, I am now off to find other places to use DVRs in my message system. I bet there are a few more places I can improve things...
-
Funny you mention that. As I attempted to re-factor this problem away, I ended up trying two things.
1. Store the node values in a separate variant.
2. Store a DVR of the node data in the attributes of that separate variant instead of storing the node data directly in the attribute.
In my case, I am implementing a subscription message system. The system needs to allow for multiple subscriptions and each subscription needs to keep track of all of its subscribers and the last message sent. That allows me to broadcast to all active listeners and for new listeners to request the current value of they subscribe between broadcasts.
The benefits:
I can add subscribers and remove them from a variant tree that contains no data other than the attribute names. I expect to have under ~500 subscriptions in the system at max load and each subscription would have under 10 subscribers. So the tree is not too big.
Having the data stored as DVRs allows me to avoid that massive copy when I extract the node data tree from the system (I store system data in a DVR itself so all processes have access to it). The other benefit is I no longer need to write back any changes to the node data in the tree. I just update the DVR's content. The variant tree never changes.
One caveat: My node data is a message. All messages inherit from a common ancestor. I tried to create a DVR of this ancestor and use that as my node data type, but LV will not let you modify the data in a DVR if the type is a class, even if the new data is a child of that class. Not sure I fully understand the reason for this, but the workaround is to store the data in the node ad a DVR of a variant. That just means an extra cast when I want to access the data. Seems kinda silly to have this limitation but I am sure they have their reasons.
Anyways, problem solved and speed is no longer an issue. Now to add some cleanup code to free all those DVRs on shutdown...
Thanks for all the help and tips. This is why I love LAVA!
-John
-
Ok, new version isolating the node data to a separate attribute produces and 8% overall speed increase. The original copy of the branch from the main tree seems to be the overwhelming issue. Here is the new code:
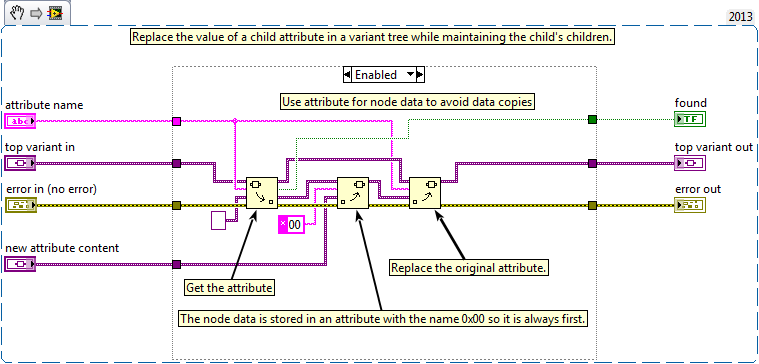
I did not include a snippet of the other changes I needed to make:
- Populate the top child with an empty NodeData Attribute when adding that branch.
- Deleting the NodeData attribute from the array when getting the list of branch children.
At this point, I am wondering if I could get a speed improvement from redesigning this using LVOOP objects instead of variants.
-
Kinda. I had to cast the generic variant to a variant using the 'to variant' prim when I added the child to the top variant. After that, it allowed me to use the IPE to update it. Not sure if that is what you mean.
It is not possible to make the first 'get attribute' inplace since I am getting an attribute value by name and replacing it. The IPE only provides access to the node data, not its attributes, as pointed out in the Idea Exchange link you provided in your first comment to the thread.
-
Does there need to be a "Swap Values" prim in there?
where?

strictly typed vi refnum in a class?
in Object-Oriented Programming
Posted
Figured it out. My 'handler' VI has an input of type 'system class' and I was trying to add the strictly typed refnum of the handler to that 'system class'. Looks like I will have to find an acceptable hack to fix this. I am thinking of passing the class to the handler as a generic reference and then casting it in the handler to the proper type. Any better ideas?