

NimbleThink
-
Posts
5 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by NimbleThink
-
-
Depending on what algorithm you require for postprocessing there are open-source programs which can perform the post-processing for you.
I use "R" a lot; an open-source version of S-plus, a statistical programming language invented at AT&T Bell Labs.
It has many powerful statistical functions and excellent graphics capabilities (better than LabVIEW).
The only post-processing I do in LabVIEW are those requiring specialized signal analysis such as trigger detection, FFT's, etc.
Leif Kirschenbaum
-
Hello everybody,
I am writing a Labview program (using LV 7.1.1) to control valves on a chemical installation (each valve is connected to a digital I/O of the board), there are 30 to 40 valves in all, and there is a physical separation in that we use three different instruments. Some valves are only to allow reactants in/out, others will need to be pulsed during the experiments.
I am wondering how to write the tasks in MAX, would you recommend a single task per valve, with the advantage that it will have a human-readable name in the programs and that I can create arrays of tasks later, or maybe directly a task per instrument (i.e., containing about 10 DIO for 10 valves) to more simply deal with arrays of bool later? Or maybe many redundant tasks (I mean tasks that act on the same channels) to pull out like global variables, in the latter case I would use a 10-channels task for initialization and then a single-channel task for pulsing or opening a valve?
What would be the recommended way? Most flexible and simpler to code for?
Now, I have tried the one-task-per-valve approach and then, these tasks put into an array. But I have a problem with finding which channel to switch for changing the state of a single valve in the array. I have written an ENUM to name the tasks in the array, but it is not very flexible (because the ENUM and the array of tasks are separated and easily fall out of sync: different files, different coding priorities...). The latter may actually be my biggest problem here.
I think you are on the right track with an array of tasks, however the tracking of the tasks is a problem, as you say.
I am working on a similar situation where I have multiple references for various instruments and I need to keep track of what role each instrument performs.
My suggestion:
create a global which is a cluster
put in this cluster an array of tasks
add an array of strings
[optional]
create an ENUM, customize it, edit the list of items and create an item for each valve type ("in", "out", etc.) and save it as a Type Def. customized control.
add an array of ENUM
Now when you initialize your system you create an array of tasks. At the same time create an array of strings labelling these tasks, in fact you could cleverly construct these strings like "IN:water", "OUT:water", "IN:blue dye", "OUT:HF", or whatever you need.
Then write both the array of tasks and the array of strings into the global.
Later when you need the valve which controls water output, read the string array from the global, then search the array for the string "OUT:water". (In fact if you have logic which specifies the liquid name and the valve direction you could programmitically construct the search string using the concatenation function.) Then read the tasks array and use the index from the string array search to retrieve the proper task.
This way you don't need to keep track of the order of the tasks, you only need to make sure that when you initialize your program that the tasks and the string descriptions are saved in matching order.
If needed you can put error checking later in your program which will read the tasks array and the strings array from the global and check to see if they are the same length: if they are not, then throw and error and gracefully exit with a dialog.
Best of luck.
Leif Kirschenbaum
-
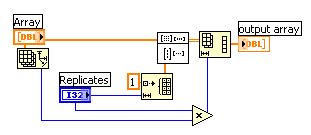
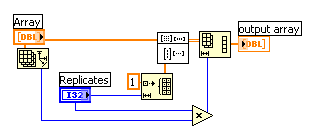
I have need to replicate elements in an array.
The "Interleave 1D Arrays" is not feasible due to:
1) too large a number of replicates (>5)
2) variable number of replicates (345, 625, etc.)
I know that a For loop (with a pre-initialized array of size length M x number of replicates N) could work, however I avoid them (for speed) and so came up with the following:
Multiply the input array with an array populated with the number of replicates using the Outer Product then reshape from a 2D array back to a 1D array.
Any other suggestions?
-
Here are some questions:
Can you convert a sequence structure to a state machine?
[assuming that they answer "yes"]
Please explain all the advantages and disadvantages of a state machine versus a sequence structure.
How might you implement a state machine where the next state not only depends on the current state but also the prior state?
-Leif Kirschenbaum
QUOTE (jlokanis @ Aug 20 2008, 09:32 AM)
At risk of being off topic, I will answer your question:Sequence structures (IMHO) exist to allow text based programmers who do not 'get' the idea of dataflow to explicitly control the sequence of execution. They are like the 'GOTO' statement of G programing!

I have yet to find a situation where they are required. We use the error wire to control execution where needed. We also modularize our code as much as possbile (lots of sub-VIs). And we limit our diagrams to one screen (99% of the time).
The key things I do not like about sequence strucutures are:
1. Violates dataflow within a single diagram.
2. Stacked strucutures hide code and force the code to have wires that flow backwards to pass data between cases.
3. Flat structures make for large diagrams that are messy.
Don't get me started on Globals either... (that horse has been beat to death anyways on LAVA and InfoLabVIEW)
-John
Orthogonal/Model II/Deming regression
in LabVIEW General
Posted · Edited by NimbleThink
Has anyone coded up an orthogonal fit regression?
This is a Model II regression (error in both Y and X variables).
It may be known by references to Deming models or to early published work by York [1].
It is used to perform a linear fit when you have error in both X and Y.
Thanks.
[1]
LEAST-SQUARES FITTING OF A STRAIGHT LINE
Derek York
Can. J. Phys./Rev. can. phys. 44(5): 1079-1086 (1966)