

OlivierL
-
Posts
76 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by OlivierL
-
-
Hi,
I wonder if this is a bug of LabVIEW or if I misinterpret the "Range" function in the case selector.
In the VI Attached, a string is used to select a case in a Case Structure. there is a case for "0".."9" that LabVIEW accepts but if you input the string "9", LabVIEW executes the Default case. If you change the case to "0".."9", "9", then first of all LabVIEW doesn't return an error saying that values are not unique and it behaves as expected if you pass the string "9". Can anyone explain why LabVIEW would exclude the last value in the range?
Cheers,
Olivier
-
- Popular Post
- Popular Post
Looking forward to another NI Week and Lava G BBQ.
Thanks a bunch David for posting on the other thread. I had given up after seeing no new messages by the end of June.
-
 3
3
-
PY: Did you ever find a way to work around your problem? I found new information that may be useful to you.
I played around some more with the functionality today and it really seemed that the invoke Node called "App:Disconnect From Slave" had to be called from within the RT target itself to work, as suggested on the NI forum. Then I tried some other tests to see if it is possible to Run a VI directly on a RT target (that is in your project). At first, I thought that it was not possible and couldn't figure it out until I found this link: http://forums.ni.com/t5/LabVIEW/Loading-and-Running-a-VI-on-a-cRIO-from-a-PC/td-p/796657 . I think that this actually gives you your solution by explaining that each target has its own application instance (also search for "Working with Application Instances" as a "Concept" in the LV[2014 in my case] help file). The way to acquire them is (or at least my way since I couldn't directly give the IP address of the RIO) was:
- App-> Project.ActiveProject -> Targets -> [index proper one] -> Application -> "Disconnect From Slave"
Notes:
- "Project.ActiveProject" appears to be a VI scripting (bue background)
- The "Application" property node is located near the very end of the list
This silently disconnects the cRIO and may be able to remove your popup if done shortly after requesting the RT to restart. With the same App reference, you can also programmatically launch a VI to the Target from the Host (same as pressing the Run arrow with cRIO target selected.) It could definitely be useful for you as well if you need to delay the restart to prevent the pop up. I mean, Deploy your application to the CompactRIO with the "Run As Startup" enabled, then get the App reference and run a simple VI that resets the CompactRIO after a few seconds of delay. During that time, call the "Disconnect From Slave" Invoke Node and your pop-up should be gone...
Let me know if this works for you!
-
Thanks. I should've added that the conversation moved to here: https://lavag.org/topic/19341-security-who-cares/page-2#entry116714
-
Interesting read! Thanks for the link. I guess our situation is different than most others as we only need the tunnel for security. I'm sure that will change in the future so we'll keep an eye on the topic of interactive SSH sessions.
-
So a quick test definitely confirms that the MyRIO has SSH tunnel support enabled and a connection can be established from Windows using "plink.exe" (Putty) with System Exec. The command to System Exec:
d:\Installed\Putty\plink.exe -ssh admin@192.168.0.66 -pw Passwrd -C -T -L 127.0.0.1:9988:192.168.0.66:8899 (9988 is the port on the Host/PC, 8899 is the port I open in LabVIEW on the target, 192.168.0.66 is the MyRIO address.)
Neat, thanks for the heads up Shaun. This is a lot faster and easier than our original idea and it is my answer to your original question about my take on security for remote systems.
Sidetracking a bit here but once we've launched a System Exec in the background (wait until completion? set to False), is there any way to get that process back and parse the information (output to stdout) or to stop it?
-
Is the screen shot a connection to a RIO unit? Have you been able to test down to port forwarding to the LabVIEW app running on the RIO? I'll try to find some time this week to do my own tests but your toolkit is interesting.
For the VPN, it would only be to connect from our office to the client's LAN for example. For the dedicated Host PC, I understand it would only require SSH.
-
I posted on a separate thread because I thought the two topics differed enough but I'm happy to continue here.
I totally missed the SSH option in conjunction with the VPN (for remote access.) That was the missing link that pushed us to think of a more creative workaround. Especially with the Linux boxes, I think that SSH and proper configuration of the firewall to only accept local connections should be good enough for us. The only caveat left in the chain is integrating the SSH client within the LabVIEW application. Fortunately, we would only need to support a single platform (Windows). Has anyone done it so that the username/passwords can be requested from within the application and the tunnel established over a .dll or command line utility? There appears to be a port of OpenSSH for Windows but it seems to run on Cygwin. Putty's command line utility (plink) could also be a good contender to create a tunnel which appears to be builtin the application?
Using those standard tools would likely require a lot less development while offering proper encryption.
-
ShaunR's recent topic on Security reminded me of a situation we explored in the summer and need to revisit at some point. We were looking for a method to protect the communication with a cRIO.
The situation is that we need to communicate between a cRIO and a host on an unsecured network (manufacturing environment.) We concluded that we needed some form of encryption as well as a standard login mechanism but identified that having a single symmetrical key would not provide enough protection (for various reasons and specific use cases.)
Therefore, we looked into SSL and LabVIEW Web Services because it already includes that library and all the security features that we need. We figured out that it would definitely offer the protection required but that would mean rewriting most of existing code to use Web Service instead or establish some for of communication through a new Web Service. Considering the amount of unknown and risks associated with modifying our code, we looked into an alternative and came up with the following scheme:

In short, we would use a Web Service for the initial login and create a new symmetrical key which would be passed to the host and to the main application on the target (cRIO) and would be used to encrypt/decrypt all data during the session. This way, we could still program all of our code in LabVIEW and easily download/deploy the services and applications to the Target using NI standard tools but benefit from proper security and only have to add fairly simple wrappers to some sections of our existing code.
I wonder if anyone else has already gone down that route to add protection to an existing application. Would you suggest a different implementation method or an easier path to a similar result? Is there some obvious pitfalls in this approach that we do not see?
-
1
-
-
We have used NS on a project recently with a cRIO and we found a few caveats that we were not expecting:
- The NS engine uses ~10% of each core on the cRIO (9067) as soon as a connection is established (we had three streams)
- There is also an impact on the host CPU, even if very little amount of data is transferred
- All NS are unidirectional and limited to one connection (based on your description, you are better off with TCP)
- The NS properly register that the end point is disconnected ONLY if the connection ends gracefully (completing executing on the Host for example.) If you disconnect the network cable, neither the Host nor the cRIO registered the problem automatically and the stream no longer worked when the cable was reconnected. You would need to build that yourself...
- Memory management in the NS is less than ideal. One of our NS was transferring arrays and we had set the depth of the NS to 100k elements. LV thought it was a good idea to go through each of the 100k in the buffer even is there was ever only 1 or 2 arrays in the buffer. The result was that both the cRIO and the PC were trying to allocate >1GB of memory space that it didn't really need. Sure, bad programming but you would hope for better reaction than what appeared, for the longest time, to be a memory leak. If your messages are long and you create a large buffer, expect to run into strange problems down the road for obscure reasons...
I would suggest you go straight to the TCP method. It will require a little bit more work upfront but you will have more flexibility, less overhead on the CPU and the ability to handle multiple connections easily.
NS is great at delivering a simple option to quickly get started with and streaming large amount of data in simple situation but doesn't offer much IMHO benefit over TCP when scaling up.
-
1
-
You're right. If the same mechanism is used regardless of the option selected (Call & Forget / Call and Collect), there is a need for some mechanism that the "Proxy" VI fills. That makes sense.
I'm still not going to move to ACBR but it is interesting to understand (or so we think) what's happening under the hood.
Did Stephen ever find the solution to his issue throughout all this?
-
Can you also confirm that the ABCR versions do NOT die when removed?
Yes it keeps running.
So why does the ACBR keep running in your case and not the "Run VI"? My guess comes from different implementation of the two methods. Whereas "Run VI" launches the Sub VI as a Top Level VI, "ACBR" actually creates a proxy (Use "Call Chain" in your SubVI to see this). That special Proxy VI then calls the SubVI as a subVI instead of a top level VI. Therefore, another references is created (in the Proxy) to the subVI so even if you close the original reference, the Proxy keeps running and keep Sub VI in memory. In the case of RunVI, if you close the reference, then the SubVI (Running as "Top-Level") becomes identical to any other Top Level VI and stops since no reference is opened and FP is closed, stops its execution.
I ran another test and I was surprised by the result; If you do not close the reference, in both cases, Blinker.vi keeps running (I removed the error from the Queue stopping the While loop) in the background. I thought that it would be aborted by the ACBR ("Run VI" actually runs as a top level VI so I expected it to behave as such, with no knowledge of the VI who launched it.) I assumed that the Proxy's reference would be tied to the calling VI but it is not. Moreover, the behavior (Blinker.vi keeps running) is the same whether you close the original reference or not! "Proxy" appears to have no knowledge of the caller ("subpanel test ABCR.vi") status. Now that I think about it, I guess this makes sense as it is the behavior I've seen within the Actor Framework where the Actors keep running in the background under certain debugging cases.
-
-
Hi PY, there is an invoke Node called "App:Disconnect From Slave". Assuming that your pop-up message comes from the Project window, this should do the trick. Unfortunately, it doesn't appear to work as expected in my LV2014 project (nothing happens to the connection status of my RT target in my project). Calling this (it it works) before the reboot should spare you from seeing the pop-up but again, I can't get it to work here...
-
I still see that not having a static ref to the sub-VI anywhere in memory and using the "Run VI" method always aborts the VI, even if the "Auto dispose" is set to true. So it appears to be a plain "Run VI" vs "ABCR" thing. Note: Even putting the strict reference in a disable structure keeps the reference in memory, you really need to remove it fromt he code altogether.
As suggested by James, are you closing the reference after the "Run VI" call? you must not.
Similarly, is it possible that you don't close your reference anymore in your test using the ACBR? That might explain why they stay in memory.
-
I have definitely seen the exact same behavior when probing a queue, in previous versions of LV. Sometime I would get a longer description and sometimes a shorter one, for the exact same wire. I'd be very interested to know if anyone from NI has an answer.
-
I just cannot reproduce the behavior that you are describing. I've never really used the ABCR as I prefer use the Run Method instead but I played with it this morning.
I tried with both with a non re-entrant VI and with a re-entrant VI using option 0x80 and both VI keep running in the background (infinite While loop) even after closing the reference and removing each from the sub panel. It appears to me that the ACBR has the equivalent of "Auto-dispose VI Ref" set to "True" as the VI runs even if the reference is closed in the caller and the FP is also closed.
In your test, does your VI called with ABCR keeps running or does it stop executing? Is it set to re-entrant?
-
I really like the idea. If your vision is to expand NI Vision which is already a pretty good base, I would be interested in the added functionalities. We have been doing Vision projects in the past and among other features, the lack of a better OCR has been a pain. I agree with ShaunR that supporting such a tool is the main challenge over time. If the project gets off the ground and we can share some of our functionalities, I'd be willing to do so.
Good luck!
-
1
-
-
Due to the fact that the FP must be closed before entering into the subpanel, if you happen to close the reference you used when inserting, then upon exiting the subpanel, the VI will abort (Closed FP, no managed references in memory). As long as the VI is in the subpanel, the subpanel seems to manage it's own reference to the VI. I suppose this would suggest that yes, the subpanel closes a reference to the sub-VI when the sub-VI exits the subpanel.
I wouldn't say that the subpanel "closes a reference" but rather than LabVIEW does its basic job of stopping the execution of a VI which already had no opened references and no longer has a FP opened, which, as you suggested, was the main reason for keeping it running in the first place.
@drjdpowell,
So the method to avoid the VI auto-aborting seems to be linked to the usage of a strict VI reference when opening the reference and less the method used afterwards. Good to know.Also, on the "Strict VI Reference", I believe that it actually loads the VI in memory during execution and therefore, creates the reference that keeps it running in the background. This does the exact same thing as putting the VI as a subVI elsewhere in code executing.
-
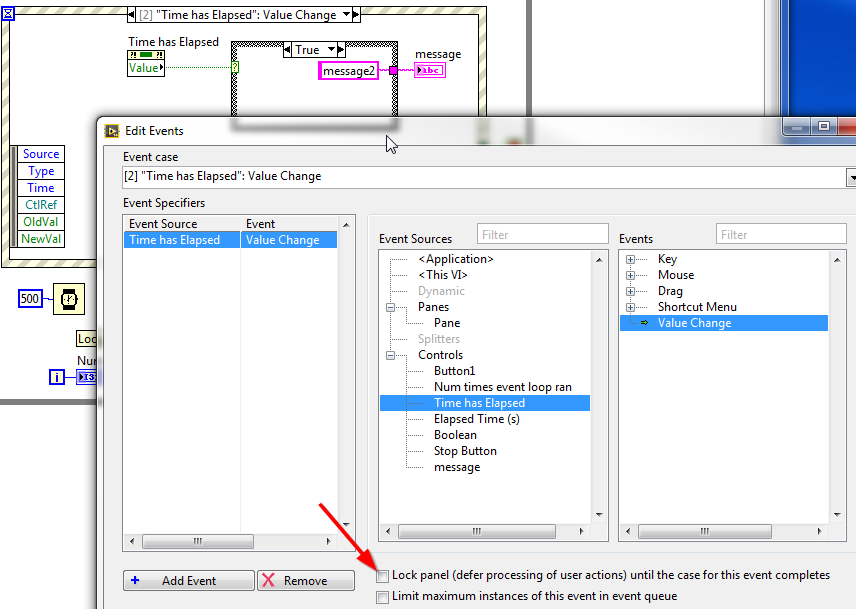
Your question is actually interesting here. I had to think about it but in the end. it has to do with LabVIEW Locking the Front Panel. As soon as you press a button, LabVIEW now has 2 events in its Queue and since both events "Lock panel" and each processing is delayed by 500ms. the button becomes unresponsive because LabVIEW no longer accepts any more events. To understand this better, try unchecking the option in the "Edit Events" of "Timer has Elapsed".
Look at the VI attached for another implementation that is closer to what we normally do here and is cleaner in my opinion. Not sure if it meets your requirements though.
Hope this helps you.
-
Just found this post this morning. We have this erratic behavior also in my code in LV2014. We discovered it last month on our project. I spent some time investigating it this morning and found the following:
- XScale-Increment appears to have nothing to do wit it
- The fact that you "Autoscale with Pane" has no effect either has our property node "Width" & "Height" produce the same effect
- In our case, we do not use the "Increment" property so the problem generally has to do with the Y-Scale in general
- After a resize to a larger window, LabVIEW appears "resize the graph" (shrink on the left hand side) automatically to fit the scale with higher accuracy (let's say 0.25 increment instead of 1). When you force the increment back to 1, LabVIEW seems to return the graph to where it used to be but in the process, it seems to me that LV alters some reference it uses as to the real "X-origin" of the Scale. When you do the process multiple times, it keeps shifting the scale further left.
- After some thinking, I thought it might be possible to force the graph to move the other way if the problem was the one I suggested and it actually worked. Look at the attached file.
Is there any way to report this to NI to associate it with the right CAR?
Did anyone found a real practical solution to the problem? In our case, I plan to change using the VI to loading a clone so if the display gets messed up, we'll have a "reload" button from the unmodified original vi.
-
I also went through those issues a few years ago when I was doing more programming and less management. Both wrists were getting pretty bad and my back was hurting also. Swapping mouse to the left side definitely helped, despite being very difficult at first but you can do it just like you can learn to drive on the other side of the road after 20 years of driving if you need to.
For a while, I used LVSpeak for a while which I found to work fairly well to replace many other commands and quick drop which reduced the movement of both hands. I did get used to Auto-tool to further reduce frequent repetitive keyboard actions.
I had a "ah-ah" moment when I switched offices when things were still bad with my body. Doing the exact same job but overnight, at a different desk and on a different chair, the pain slowly disappeared. Minor adjustments in you desk can make a huge difference and despite the professional advice being a great idea, they won't guide you through this slow and iterative process.
Have you tried a stand up desk? It changes your working position when you transition from sitting to standing and it helps your body a lot. Finally, regular breaks are super useful, though very hard to implement. An addiction like smoking can help you with the regular break every hour though
 ... Good luck!
... Good luck! -
I would questions someones engineerings abilities who finds 150 Euros to be expensive for something which can make the difference between a properly working system and one which regulalry looses communication and/or trips the computer in a blue screen of death. If an engineer has to spend two hours to debug such an error caused by a noname serial port adapter then the more expensive device has paid itself already more than once. And two engineering hours are just the top of the ice peak, with lost productivity, bad image towards the customer and what else not even counted in.
Rolf, I agree with you but some managers seem to really like the gamble of the 10 Euros one which has 90% chances of working just fine, especially if a system failure has little consequences. For the times where we can't convince the clients to get the better one from the start, we keep a few reliable devices on hand and swap them at the first sign of trouble and we no longer spend time debugging until the devices have been swapped. That seems to a strike a good balance that pleases everyone.
-
LabVIEW (or rather 'G') is entirely flow-based, so this makes sense. This answers my question to some extend. I actually like to define boundaries between things as clear as possible in order to make my sources accessible for the other developers in my team. So as an example: If my Actor acquires some data and provides it for the outside world, it might have its own visual representation and maybe you can control it (so basically MVC in one Actor). On the other hand I require multiple visual representations to fit the data on different screen resolutions (pure VC units). There are boundaries I have to define. I can either have a 'default' resolution in my core Actor with additional VC Units, or the core Actor is never shown and all resolutions are from separate Actors as VC units.
I guess I'll have to play around and think about this for a bit.
Thanks for the hint, I'll look into them.
Hi Logman, As you suggest, VC can (should?...) be merged into one VI in my opinion. We design most of our code with VC merged into one VI (actually offen multiples VI for different interfaces) while the Model is really just doing its core task.
Also, we try to not use the GUI of the Model/Actor directly so it can run in a higher priority thread instead of in the UI thread. It makes a difference for us in some cases on Windows and it helps us when using our libraries on a Real-Time targets as we already have the all GUI clearly separated and are able to easily debug from any PC (assuming your actors support some kind of TCP communication) even when the Target is running independently.
-
1
-
String case selector "Range"
in LabVIEW General
Posted
wow, you are correct. That is how the feature is documented and implemented! Thanks for posting this. I can't understand why NI chose that implementation but it probably goes back a couple of decades and it might not have been intentional...