

Kas
-
Posts
55 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Kas
-
-
In general it is almost always beneficial to spend some time in advance modeling what you want it to do before actually touching any code. The cases where it isn't are typically trivial.
You are right, but since my University work (Electronic and Physics), any programming work I've needed was done by trial and error. I concentrated fixing the problem without thinking of how. So now my brain doesn't work until I start coding and fix whatever needs fixing along the way. In the end, Panic time arrives and I'm off to LAVA
 .
.I've been using LabView for a long time, but its always been on-and-off. Its only recently that I'm more invested on it and I'm finding it rather difficult shaving of the bad habits of programming I've accumulated over the years. It was very easy to learn LabView the wrong way
. -
Hi Shaun.
Would it be of any help if start doing a flow chart of the execution functions of the program? I haven't done it yet, but I just wanted to check if it would be of any help.
Kas
-
Well, I wouldn't have approached it this way but if you really need to, then just use this error message code as an indicator if the file is already open or not. i.e. check if you are receiving this error 5, and if so then you know the file is already open.
Are you trying to write to this file or deleting it, or trying to open it again?
Kas
-
I am still maintaining that delegating much of the current UI functionality into separate modules will be beneficial in terms of maintenance, readability and robustness.
I definetly agree with you in this. Initially, I was planning on having the "Upload VI" as nothing more than a very simple VI that does nothing more than reading the updates, logs etc. But as the project went on and new functionality that I wanted to add to the main VI, then the Main VI became too congested and I started making the Upload VI more complicated until it became what you see now.
Having separate modules for this, and having a communication link for data and messages for these modules would certainly be the way forward, but unfortunately, I'm used to statemachine type of structures and not much in module based work.
I started thinking on how to handle different errors, i.e. have each module sort its own errors out or delegate them to a central error handling module, where error logging then comes into play. While all that is going on than I remembered various race issues that can creep up (specially if I continue using my current framework), and somewhere around here my head started hurting
 .
. So I thought coming here and get some help along the way
 .
. -
Hi Shaun. I just sent you the account details.
And no, there is no deadline for this project. After using "Usenet" for sometime now, I saw something that I needed and I started this on my own.
-
(Did I mention how much I hate the JKI statemachine )
Haha. I do, I remember from this thread, for both you and Daklu.
http://lavag.org/topic/16154-qsm-producerconsumer-template/#entry98307
So. If the main VI organises and "makes sure that only one of the jobs (i.e. either downloading or Uploading) can use the connection at a time". This is what I mean about modularisation.Correct, currently the Main VI does this through the "Check Availabiltiy" state. However, I'm worried the way that I am doing this may be abit of an overkill. i.e. I'm thinking that there should be a much easier way of doing the same operation that would result is less confusion. Usually, the simplest method is the best method, and I'm worried I haven't approached it that way. 0
So far, the main VI keeps track of all the jobs (i.e. Uploads and Downloads) through their properties of queues where they were initially generated from. Their state such as Pause, Cancel, Exit, Ready, etc. is kept track by the main VI and when the right conditions are met, the token is then given by the main VI to the right job. When that Job is paused, the Main VI then goes through the list again and checks the next Job that meets the right criteria, and so on.
As a first pass (very quick) glance, you seem to be sending a lot of messages and data to different loops which don't really do much apart from pass them to other loops or VIs (please correct me if I'm wrong).Well, the Upload VI, has 3 such loops. The Progress loop, the Log loop and Pre-processing loop. The progress loop updates the progress of the Upload VI (i.e. the progress bar, speed etc.) where the same values are then also sent back to the main Update loop of the Main VI. The same happens with the Log loop, where the log indicator of the Upload VI is Updated and the same log is also sent back to the Main Log on the Main VI. I kept this loops seperate because depending on the amount of Logs generated or the Updates, I didn't wand to occupy the Main loop that deals with Uploading articles itself.
I will also try and buy a block account from newsreaders so you can also run the program and see how it works. I will post the information as soon as I'm finished.
In the mean time, tweaknews https://www.tweaknews.eu/?page=order&product=1 seem to be providing free accounts for 10 days, but since I've used it in the past I can't create another account with them.
Thanks
Kas
-
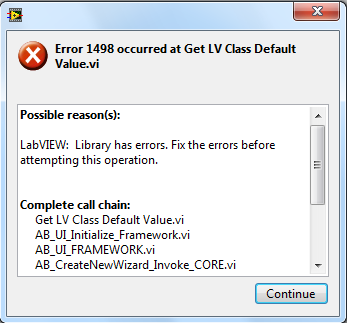
Ayayay, when things happen they all seem to happen at the same time. I get the attached error when trying the built specification. I think this may have to do with clashes between various VIPM packages that I've installed. I have to go though them and sort this out later.
As for the files itself, I'm now providing the full folder in my current LabView version i.e. 2012.
As usual the link is below since the attachment is bigger than the forum allows.
https://mega.co.nz/#!oA8SnRrJ!Uop2vwECVGQk_pCsovLhFnb9kCwtEwc0VMvD6ZVVm8E
As for what you've just mentioned Shaun, you are correct. The main VI first initializes the whole set of connections and then provides the exact same ones to all the jobs waiting. However, the main VI organizes and makes sure that only one of the jobs (i.e. either downloading or Uploading) can use the connection at a time. The reason I provide them all with the same connection is that when a job or process is paused, the next job in the main queue waiting starts to work straight away, since the previous job is now paused and no longer using these connections, the next job can now start using them until finished or the user pauses that job as well, and so on.
Kas
-
Hi guys.
This actually follows very closely to what Shaun suggested. The only difference is that it uses an intermediary VI i.e. in this case its the Upload Main VI. This upload main VI throws asynchronously called VI's for each connection. In this example maybe 30 asynchronously called VI's where they individually Upload a piece/chunk of data to the server and when finished they are closed and the TCP connection is passed back to the Upload Main VI for reuse again.
This is shown in the "TCP: Upload" state on the "Upload Main - GUI".
On that state I call "Upload Article" asynchronously where 1 call is 1 TCP connection.
Also, Attached I cleaned up the files a bit and placed them into a project as Daklu suggested. All the relevant VI's should now be there.
Thanks
Kas
P.S. I'm using some of Shaun's VI's for calculating the percentage and Transmission speed
, I found them from one of the examples in the forum (I think it was something to do with Bluetooth connections)Oups, for some reason this thread is not allowing me to Upload a file that bigger than 733.62K. My ZIP file is 1,184 KB.
So please use the link below instead.
https://mega.co.nz/#!NMdUXbLI!IxWKyhj8zrq60S2xOL4Mc3VTPC12qCsL3F00nxbrN4Y
-
Hello
I'm currently writing a personal application that deals with NNTP server protocol (i.e. a command based TCP communication) related to binary Usenet newsgroups. This application will be used for general data backup on Usenet.
While I have nearly finished the application itself (and it works), I am drastically falling into various problems, mainly parallel execution of various SubVI's and handling various errors within them.
Nearly all of these problems seem to come from a lack of a solid framework for the whole application itself.
The amount of commands that I'm dealing with are very few, (around 5) so building a basic version of this application is straight forward. However, my application follows the functionality similar to "Internet Download Manager" or various download accelerators that are found in internet, and this is where majority of the complexity is situated.
And so, I'm hoping if I can get some help/pointers in 2 categories.
1. I keep having a TCP Error 1 problem. So, a user may select to have up to 30 TCP connections simultaneously to the same server and port (I have tested this and it is supported). However, every once in a while, a TCP connection is timed out (this is normal). This connection is than closed (By sending a "QUIT" command) and opening a new one in its stead. So far all this works. The problem comes when trying to use this same connection for operations again. Every time I use it, it throws a error 1 out. and I cant seem to get rid of it.
2. This may be a more difficult problem to deal with since its more of a framework problem. I really want to use a proper programming structure for this application, but I've been using state machines, QMH based structures for a long time now, and I can't get out of this habit. The way this app is designed is full of holes, and I would like to make a proper structure for it. Unfortunately, I'm not into OOP programming yet so I went with normal Labview programming structure. This may also solve the problem 1 above.
Attached is a ZIP file that I've included everything so far. The program itself is not yet finished, but it works with basic uploading operations.
Everything is down-converted to LabView version 2009, but if there are any VI's missing then please let me know and I'll provide them.
Again, any solutions, thoughts are most appreciated.
-
Hello. Apologies for bringing this thread back again but I thought this is relevant to the thread.
Attached are some VI's that encode the message and prepares it for NNTP protocol. This includes the header, footer and encodes the message or file.
The attached example however seems to fail but the failure seems random.
When the whole message is prepared, it is sent through using the TCP/IP but conforming to the NNTP commands structure. Below are steps that I use to send the data to NNTP server.
NNTP Communication structure:
1. A server Address and Port is established.
2. User Authentication is carried out.
3. NNTP Server capabilities are checked.
4. Prepare the NNTP server to receive the data through the "POST" command.
5. First the main Header information is sent (i.e. information like "From", "Group Names", "Message ID" etc.).
6. Main data is then sent.
7. Check if the data was sent successfully.
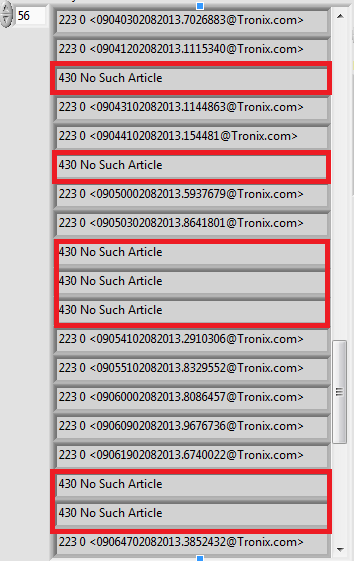
All the above steps come back as successful. Basically, all the steps 1 through 7 are OK when the data is sent. However, when the whole file (around 500 MB) is sent through by repeating the above steps, I also save the unique Message ID's so that the same file can be downloaded later on.
On this process, as soon as the file upload is finished, I go back and re-check the upload again using the "STAT" command, and even though its only few minutes later, the file doesn't seem to have been transmitted properly. There seem to be some pieces missing. Its as though those pieces no longer exist on the NNTP server. This process is also shown in the attached image.
So far, I have traced the problem to how the encoder is working and how the message is prepared in general.
For those that are not too familiar with NNTP protocols, the link below provides an introduction.
http://www.javvin.com/protocolNNTP.html
For those that are not too familiar with yEnc Encoding, the link below provides an introduction.
http://www.yenc.org/develop.htm
Sorry for providing reading material for this. I know that chances for help are greatly reduced if a person needs to read and learn before helping, but I'm hoping that someone may be allready familiar with the two concepts (yEnc and NNTP).
One of the problems that may contribute to this may be the yEnc Encoder. All the encoded lines should be constant in size (i.e. 128 bytes excluding the End-of-Line character). Looking at the attached encoder, it doesn't seem to guarantee that. The last line of the encoded message will obviously be less then 128 but based on the codding the previous lines seem to be either 128 characters long or 129 characters. This should however be always 128 characters plus the end of line. If anyone has a quick fix on this it would be great. I can than test and see if the situation improves.
I apologize for making this a long post, and if anything more is needed than please let me know.
Kas
-
Some advice: I have known some very bright students to fail miserably (or do much more poorly than they should have) on their final projects as they were totally overambitious of what they could achieve in a realistic timeframe.
Very true.
If you are new to Labview, new to various control architectures, new to electronics involved etc., then I would seriously sugest that you choose or amend the project that makes use of your current knowledge. Otherwise, majority of your time will be spent on research that you may or may not understand rather than doing the project itself.
As for the project itself, it sounds good.
-
Don't the VI's give you the option to create X number of zip files? Each Y Bytes big? Like you see often? filename.rar0, filename.rar1, etc...
I haven't really looked into that, but it wouldn't resolve the issue even if they do. Trouble is getting away from this 2GB limit. One workaround would be to go through cmd prompt, but I was hoping the native solution would work.
-
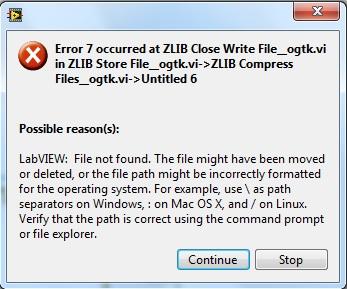
Has there been any more headway towards this? I get the attached error with files <2GB. The zip file is created up to 2GB but then the error comes up.
I'm using LabView 2012 32bit in Windows 7 64 bit.
Thanks
-
It's not just an update issue , if you hit F5 or reopen the directory the OS has not updated the number to its correct size?
Nice, that was it. I was monitoring the directory, but forgot to refresh. Everything seems to be there.
Thanks
Just a general comment: There is no need to set your file position inside of the loop. The position increments during the read. After a read, the position will be set to the next byte, so the the next read will start where the previous left off.
Didn't know about this little trick. It certainly simplyfies things.
Thanks again.
Kas
-
To anyone interested.
Attached is the final solution that also includes the encoder. For the sake of speed, the yEnc encoder is implemented using the same idea as the yEnc decoder. Both have been tested for as much as I could, and appart from some small initial bugs found on the decoder (now resolved), they both work.
Regards
Kas
-
Hello.
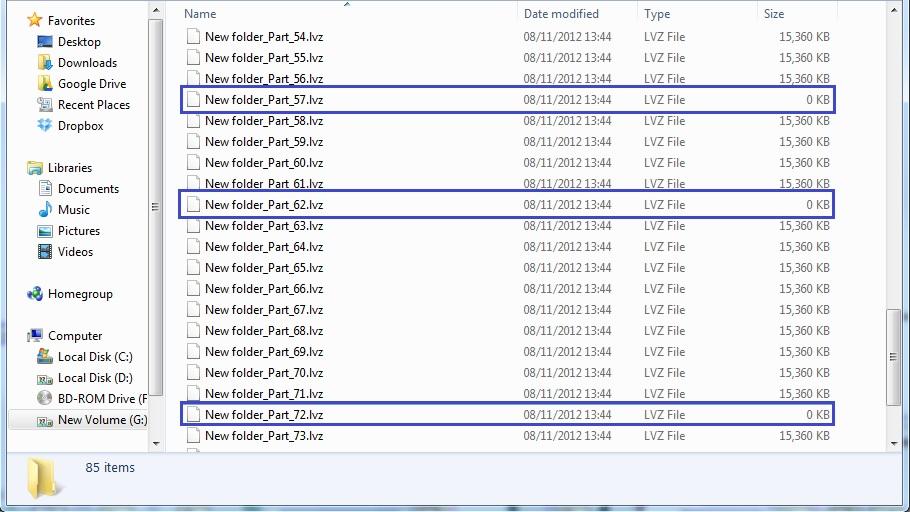
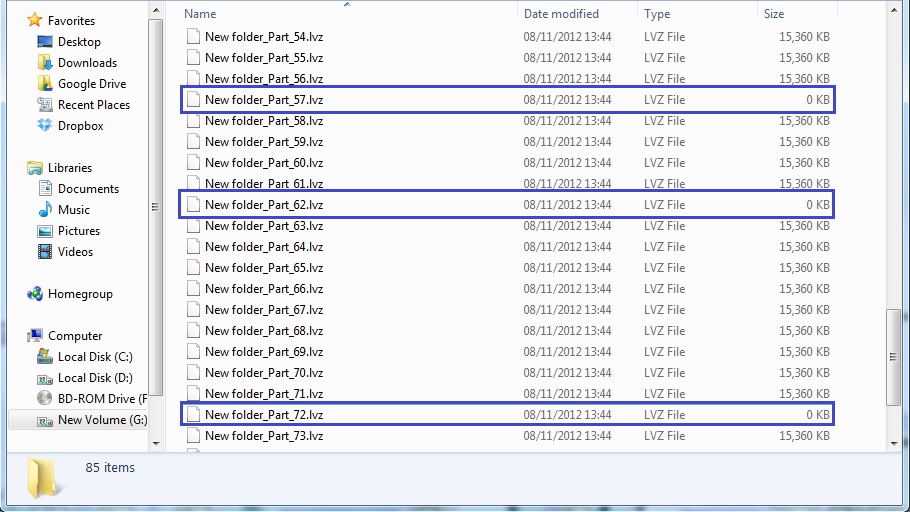
I'm trying to implement a large binary file splitter. With relatively small files (>200 MB), this seems to work ok. But with large files (<1 Gb), it fails. Randomly, I see a file being created with 0 KB size on it (attached picture). The problem seems to go away if I put a delay of 03s inside the loop, but anything less and the problem persists. I'm not sure if I'm doing something wrong (most likely) or if its a labview bug.
Thanks
Kas
-
 1
1
-
-
Attached is a VI if you're interested, which can take a folder of VIs and turn them all into reentrant.
Now why did I not think of that. So simple, and yet so useful. Cheers
kas
-
Aha. Thanks Shaun and asbo, now I get it. Initially, I thought of creating one reentrant VI for 1 segment. But since there can be 1000s of segments, I thought it might be best to have a set amount of reentrant VI's (depending on how many TCP conections I have, and then distribute the segments to be downloaded equally amongst the created reentrant VIs through queues. Since I'm allready sending each segment to the main vi for storing, then I guess I can use the same queue for sending a pointer "i.e. segment name" back to the main VI for monitoring purposes, instead of creating a new Download VI just for this. But now I understand the point that you guys were making.
Thanks again.
kas
A question that might have allready been answered. Do I have to make all the SubVI's within a reentrant VI's as "reentrant" or not. I tried it both ways and I didn't really see a performance difference.
-
Currently I store each segment to the HDD as it comes. This way I avoid memory issues when getting a large file. Each segment consists of few hundred KB but each file can be few hundred MB large, where a batch of files can be even bigger. So, everytime I download a segment I store it in HDD (where sometimes 1000s segments are needed for a complete file), which is why I don't wait for the file to be completed before storing it. After a file is completed, I then can parse the content through post processing.
If I understand your idea correctly, I'm not sure if this would solve the problem of knowing when a particular file is finished without holding all the segments in memory. Currently, each segment is sent back to the main VI with the file path that the segment should be stored to. This way, if a segment belonging to a different file comes in, then a new file is created based on the path name provided.
Sorry if I misunderstood your explanation, but if this is the case, would you be able to provide these two VIs? of course no coding required, I just want to see how you would re-arrange the queueing mechanism that you mentioned between these two VI's.
Thanks
Kas
-
Hi
I'm currently doing something that involves multiple TCP/IP connections and multiple downloads at the same time. I achieve this through reentrant VI's and queues. Effectively, everytime a reentrant VI is opened, I also create a queue with the clone name of that VI. This way, I can than enqueue all the segments and parts that need to be downloaded equally among the available reentrant VI's.
My problem is this. I am downloading multiple files at a time, where each file is made of multiple segments or parts to be downloaded. Some reentrant VIs are downloading parts from file (lets say) "B" while other reentrat VIs are still downloading segments or parts from file "A". How do I know when File "A" is finished so then I can put it through post processing mechanism.
This will probably come down to proper design architecture for Reentrant VI and queues, but so far I can't see a proper way of implementing this.
Attached is the code I've done so far.
Thanks
Kas
-
OK, I guess you mean the Case structure, not the for loop?
Sorry, that's what I meant.
To Everyone Involved:
Thanks for helping me sort this out.
Regards
Kas
-
Not an issue for a few hundred KB or even MB, but If you try to do this with really big files and then combine these in RAM for writing to disk as a single file then you may run into problems.
Very true, but since this is part of the bigger piece, I've placed the "Remove Header" and "Remove footer" in serial in order to make this as a single standin example. What I have in mind is to place "Get File Size" at the beginning in order to see if I should read the file as a whole or in parts (i.e. replace "-1" of the count in the "Read from Binary". Than have "Remove Footer" act a the STOP condition for the main yEnc decoder if this becomes the case.
The boolean keeps track of the LF/CR characters because the original code removed one of two starting '.' characters.
Only checking for equal 46 would remove all occurrences of double '.', not only at the start of a new line.
Actually I meant the for loop that deals with adding the period ".". Can we just link the "previous character" shift register directly to this loop instead of using bolean to determine this.

-
Mellroth, you hit the nail.
I have now just placed it together as the final solution. The attached is in LV 2011.
The second FOR loop that deals with either 46 or 106, is boolean initiated, is there a reason for it or would it be the same if we just wire the 46 shift register directly to the FOR loop instead of checking if 46 is equal to the previous run.
-
I would recommend reading the file in 128-byte chunks and processing that chunk right away. That way, you also know exactly where to look for your ".." and have one chunk of string that's easy to manipulate/subset, if necessary. To improve disk/computation parallelism, you could implement producer/consumer loops.
Well, this decoding section will allready be part of a bigger project (producer/consumer style). See, this is part of a program to do with NNTP server from the clients side using TCP\IP protocols. Majority of the incomming data comes in 15 MB chuncks, but this varies, and it can go up to 300 MB per part. The yEnc Decoding needs to happen once the whole part is downloaded, mainly because a yEnc encoded parts will have a header and a footer. The downloaded part is written to disc at certain intervals in order to free up memory (particularly when a single part is large).
I'm not sure if its a good idea to read every 128 bytes from the disk untill the whole 300 MB (maybe worst case scenario) is finished.
So I thought I read the whole lot at one go, but then have a clever yEnc Decoder that goes through this whole part as fast as possible.
Fast Fourier Transform
in LabVIEW General
Posted
Above FFTW only works for 32 bit versions. It was simple enough to grab the 64 bit DLL version from FFTW website and replace it.
Attached is for both 32 and 64 bit version.
LAVA_FFTW (32 and 64 bit).zip