

dterry
-
Posts
36 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by dterry
-
-
Well, looks like Google is better at this search thing than whatever platform LAVA runs on haha.
6 minutes ago, Tim_S said:I believe Mitsubishi PLCs also talk Modbus.
Good to know on this, I already have a Modbus abstraction that works well, so this could save me a lot of time! I'll look into it further.
7 minutes ago, Tim_S said:Meeting your update rate could be problematic. OPC is meant for process control (the acronym is "OLE for Process Control"). OPC goes through OLE which has the lowest priority Windows can assign. Anything with normal or high priority can block the OPC communication for 10s of seconds. OPC UA does not do this, so doesn't have the issue.
This is enlightening. I haven't been able to try the connection with the PLC yet, but did try with OPC UA on cRIO, so that probably explains why I saw no issues with updates. That will be difficult to work around, since the PLC is governing a high speed motor that I will need to programmatically monitor and control
 10 minutes ago, Tim_S said:
10 minutes ago, Tim_S said:For logging and alarming, I believe LabVIEW DSC has that built in otherwise you have to make your own. I believe DSC can do OPC UA.
Yea, it does have logging and alarming built in, as well as OPC UA (same API as LVRT), I just had bad experiences with it in the past and was hoping there was something better (or that it has gotten better in the past 5 years).
Thanks for all of your input, definitely helps me get started!
-
Hello all,
I recently was presented with the task of integrating a Mitsubishi PLC into our systems. After a good deal of googling, I think the best (maybe only) way to get the data out is going to be via OPC, thanks to their proprietary Melsoft protocol. If anyone else knows a better way, feel free to stop me here.
Now, we are currently expanding our data generating capabilities (hence the PLC), and I have been thinking about rearchitecting the way we collect data from all over our facility to be more flexible. Since I may be required to use OPC anyways, I was considering using an OPC server to aggregate all of the facility data, and then redistribute to control rooms, historical logging, etc. To do this, we would need to integrate our cRIOs and operator PCs into the OPC environment as well.
I don’t see OPC mentioned very often (in fact it returns 0 results on LAVAG), and a lot of the stuff I see these days seems to be more “roll your own” or lower level (raw TCP/UDP, 0MQ, Network Streams, Transport.lvlib etc.) rather than a monolithic abstracting bridge like OPC. Unfortunately, I won’t have time to roll my own in the near future, but LVRT supports supports OPC UA, so I could potentially integrate the cRIOs fairly easily. Unfortunately, I think I would have to use LabVIEW DSC (or datasockets...) to integrate the PCs.
I would be very grateful if anyone has the experience to comment on the following or anything else related to using OPC.
- What are viable update rates for OPC tags? I will need at the very (very) least 250 ms update rates.
- Is OPC typically low latency (time from data generated to to client received)?
- Does anyone have a recommendation for a product (NI OPC, Kepware, etc.)?
- Is OPC still popular, or are there other options for data aggregation that would be better suited to a new application?
- What are the options for logging and alarming with OPC?
- What are the options for talking to OPC from LabVIEW?
- How robust are the OPC connections in regards to reconnecting if a wireless connection is temporarily lost?
Thanks in advance!
-
ShaunR,
It seems like the database you sent is encrypted. Is there a password? Right now, I get errors because the file path ("TM.3db-> 12345" + AppDir) seems to resolve to <Not a Path>. I replaced it with a hardcoded path, and got the "Enter Password" dialog. Taking a SWAG, I entered "12345", but it threw error 26 [file is encrypted or is not a database]. I found that the password dialog was being bypassed (see below), but it worked fine once I rewired it.
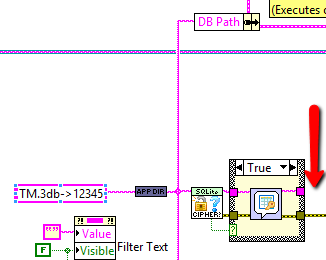
From what I can tell, the schema you put together looks some like my E-R diagram above. It helped to be able to see it somewhat implemented, and I think I may end up going this route, and dealing with the consequences (enforcing names/types/values, complex queries, application side logic, etc.).
On 1/31/2017 at 9:56 AM, dterry said:- One Table for Abstract or Parent Class, with another table for parameters in TEXT or BLOB format.
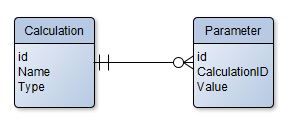 OR
OR 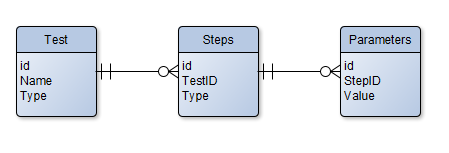
Thanks a ton for your help with this! It has been very enlightening and helpful in narrowing my focus for configuration management!
-
-
I like the UI for sure. Still not sure on the schema (as referenced in the last post) but I'd like to see it in person to understand better. Trying to check it out, but the installer is throwing an error.

-
This does work, I have used it many times. Anecdotally, the main issue I have run into when flattening classes to string is getting the versions correct on both sides. If you have changed the class in one app but not another, you can get a 1403 error in certain cases (LabVIEW: Attempted to read flattened data of a LabVIEW class. The data is corrupt. LabVIEW could not interpret the data as any valid flattened LabVIEW class.).
Some additional reading on the subject:
LAVA Thread-
 1
1
-
-
That's fair. Developing new applications is really a balancing act between stable technology and staying relevant. Think of all those poor XP reliant applications after it got sunsetted!
-
Overall, my first guess at a database structure would be something like this:
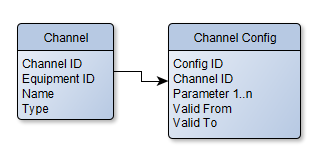
But this presents the question how to handle different sets of parameters. Perhaps you just have n number of Parameter columns and interpret the data once loaded? If you ever need more parameters, add another column? Or would you consider something like below? To me the schema below seems hard to maintain since you have a different table each time you need a different type of calc. Is there such a thing as OO Database Design? Haha
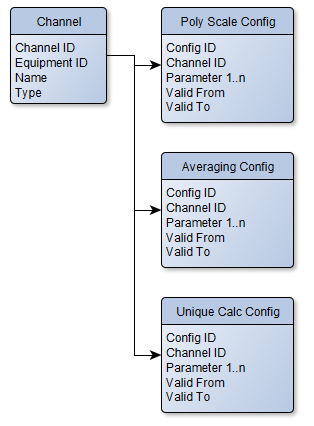
Other questions that come to mind:
- To pull these data, you would still need a config file which says "I need Channel ID X", correct?
- Some of my configs are fairly lengthy. Do you have a typical limit on the number of columns in your tables
Still scratching my head on these, does anyone have any feedback?
From my own research, storing classes is kind of a cluster. It looks like the two main options could:
- Some combination of "Table for each class", "Table for each concrete implementation", or "One table with all possible child columns". This feels super un-extensible.
- One Table for Abstract or Parent Class, with another table for parameters in TEXT or BLOB format.
OR Anybody have any experience or warnings about do this?
-
1 hour ago, ShaunR said:
Well They are all config files so I'll have to make up some tests and test limits.

I think I might add it to the examples in the API-without your data of course.
I'll have a play tomorrow.
Sorry ShaunR, still not really understanding what you are asking for. Here are a few test files.
Is there a place I can get a trial of the API you keep referencing?
-
My guess is the green FB node wasn't necessary. I would remove it and use standard debugging techniques to with the problem. Do highlight execution and probes work in sim loops?
-
On 1/25/2017 at 1:09 PM, Shleeva said:
I know I probably need some feedback nodes, or something else with indirect feedthrough, but I don't know where to put it and how to configure it. I'm still pretty new to LabView, modeling and simulation.
Fair warning: I haven't touched CD&Sim toolkit in 6 years, but I wanted to try to help out.
I think your cycle is outlined by the blue arrows below. Have you tried adding a feedback node in the red box below? You may also need one in the green box, not sure. I don't have the CD&Sim toolkit, but my gut tells me this would at least fix the "Wire is a member of a cycle" errors.
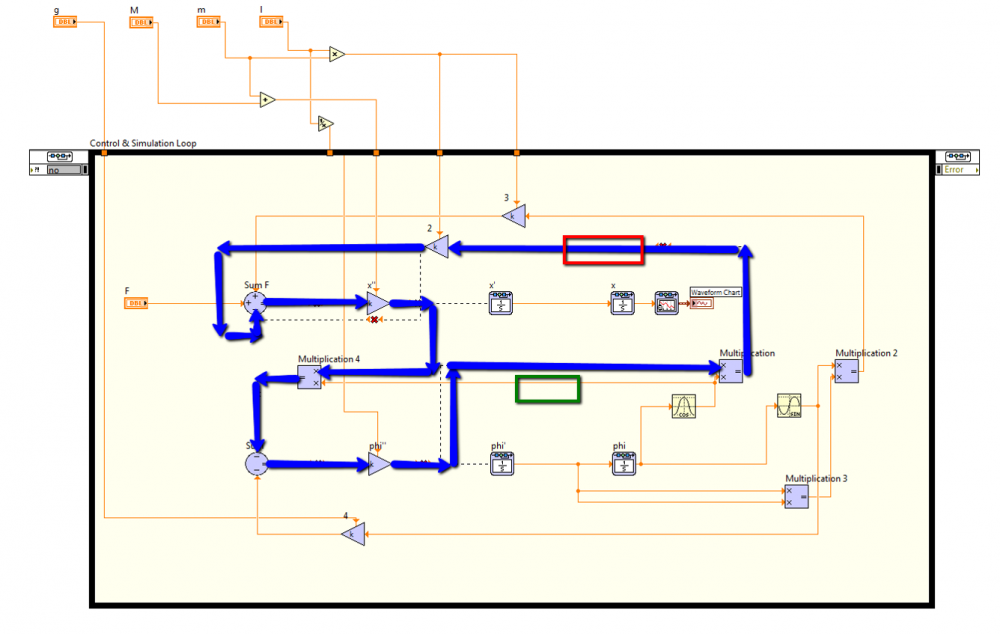
P.S. Feedback nodes are in the Structures palette.
-
1
-
-
On 1/27/2017 at 8:30 PM, smithd said:
Well in this case (or at least for me) the data is whats important. If someone has to come along and re-write every UI and sql query I make it could still be cheaper than losing the data because influx's view of reliability is different from mine.
I guess I just assumed the data could be reliably backed up, but that's probably a generous assumption.
On 1/27/2017 at 8:30 PM, smithd said:it looks like the folks who maintain the windows builds of cassandra are having some sort of fight with apache, and I had trouble finding the appropriate download.
that sucks!
-
On 1/27/2017 at 8:58 PM, smithd said:
What we've got on my current project is nothing too special, its just if your original table is columns (a, b, c) you ad (t0, tF) to the end. t0 would default to current_timestamp. A trigger would be run on every insert that says
update table set tF=current_timestamp where tF=null and a=NEW.a and b=NEW.b and c=NEW.c.
Another trigger would run if you want to update a row which replaces the update with an insert.
Another trigger would replace a delete with a call to update tF on a row.Then your query would be either:
- (for most recent) select a,b,c from table where (filter a,b,c) and tF=null
-
(for selected time) select a,b,c from table where (filter a,b,c) and tF > selectedTime and t0 <= selectedTime
- for both, you can add "order by t0 desc limit 1" but from my recent experience this leads to sloppy table maintenance -- for example we have tons of configurations with tF=null, but we just pick the one with the most recent t0. It works, but its annoying to read and make queries for, and plus it makes me feel dirty.
Ah good point on the triggers. Basically, prevent a user from ever doing an update or delete, and then add an action to update the old record's tF.
One question regarding the INSERT trigger. Your where statement looks for an identical record with a null tF. Would that just be a record with the same identifier instead? Like you said, the gist is there, just curious about that line.
Thanks!
-
On 1/27/2017 at 8:21 PM, ShaunR said:
Depends how much of a match the example will be to your real system. I could just copy and paste the same INI file and pretend that they are different devices But it wouldn't be much of am example as opposed to, say, a DVM and a spectrum analyser and a Power Supply - you'd be letting me off lightly
.
Alright, lets try this. I included two DAQ config files, another CALC file with different calcs/values, a CRACT (actuator) file, a CRSTEER (steer profile), and a limits file (CRSAFE). That enough variety?

-
Ah good point, I just stripped one down to show several types of Calculations. Are you asking for more than one file, or more channels of each type?
-
WOW! Great post, glad I asked! You've done significantly more research than I have.
13 hours ago, smithd said:Basic DBs, requiring significant client dev work. The advantage being that they are all old, heavily used, and backed by large organizations.
- mysql can provide this, but it doesn't seem to be great at it. What we've tried is that each row is (ID, value, timestamp) where (id, timestamp) is the unique primary key. What I've found is that complex queries basically take forever, so any analysis requires yanking out data in small chunks.
- Postgres seems to handle this structure (way, way, way) better based on a quick benchmark but I need to evaluate more.
-
Cassandra seemed like it would be a better fit, but I had a lot of trouble inserting data quickly. With an identical structure to mysql/postgres, cassandra's out of box insert performance was the slowest of the three. Supposedly it should be able to go faster. The slow speed could also be due to the driver, which was a tcp package off the tools network of less then ideal quality.
- There is an alternative called Scylla which i believe aims to be many times faster with the same query language/interface, but I havent tried it.
Agree with the idea that proven technology is safer. But the amount of work to get something like this working (and working efficiently) seems to negate the advantage of older tech. I hadn't looked into Cassandra or Scylla yet, but they seem promising (as long as write performance can be managed).
13 hours ago, smithd said:More complete solutions:
- Kairos DB seems cool, its a layer on top of cassandra, where they've presumably done the hard work of optimizing for speed. It has a lot of nice functions built-in including a basic web UI for looking at queries. I ran this in a VM since I don't have a linux machine but it was still quite fast. I need to do a proper benchmark vs the above options.
- InfluxDB seemed like a good platform (they claim to be very fast, although others claim they are full of crap), but their longetivity scares me. Their 1.0 release is recent, and it sounds like they rebuilt half their codebase from scratch for it. I read various things on the series of tubes which make me wonder how long the company will survive. Could very well just be doom and gloom though.
- Prometheus.io only supports floats, which is mostly OK, and allows for tagging values with strings. They use levelDB which is a google key-value pair storage format thats been around a few years. However its designed as a polling process which monitors the health of your servers and periodically fetching data from them. You can push data to it through a 'push gateway' but as far as the overall product goes, it doesn't seem designed for me.
- Graphite, from what I read, is limited to a fixed size database (like you want to keep the last 10M samples in a rolling buffer) and expects data to be timestamped in a fixed interval. This is partially described here.
- opentsdb: InfluxDB's benchmarks show it as slower then cassandra. It has to be deployed on top of hbase or hadoop and reading through the set-up process intimidated me, so I didn't investigate further, but I think the longetivity checkmark is hit with hadoop given how much of the world uses it.
- Heroic, same as above except it requires cassandra, elasticsearch, and kafka, so I never got around to trying to set it up.
Great additions to the list! I'll have to dive in and do some more research based on these.
One thought I had when performance or LabVIEW driver compatibility is concerned is potentially using .NET or C libraries to access the databases. My guess is that since those are MUCH more popular, they might have had more resources/development time/optimization than a LabVIEW driver (as you mentioned for Cassandra). Have you tried this?
How did you find that spreadsheet by the way? I feel like my google-fu is lacking.
-
Just wanted to point out the excellent NI KB on this subject here. It covers channel wires, locals, queues, notifiers and more. I personally use notifiers (unless I have an event structure) and have never had an issue with them.
-
First off, THANK YOU all for contributing to the discussion! This is very helpful! Please see my responses and thoughts below.
13 hours ago, ShaunR said:Do you have any INI files you can post? We can do an import to a DB and I'll knock up a quick example to get you started..You can then figure out a better schema to match your use case once you are more familiar with DBs.
I attached a truncated INI file below (file extension is .calc, but its a text file in INI format). I'm interested to see what you mean by import to DB. I have some ideas for a basic schema which I'll outline below.
11 hours ago, smithd said:I would say the easiest way to think about sql databases is as an excel workbook. If you can represent it in a workbook you are very likely to be able to represent it, similarly, in a db. This is a nice intro along the same theme: http://schoolofdata.org/2013/11/07/sql-databases-vs-excel/
If you're looking to try things out, you'll likely go along one of three free routes:
postgres/mysql: server-oriented databases, everything is stored on a central server (or network of servers) and you ask it questions as the single source of truth.
sqlite: file database, still uses sql but the engine is implemented as a library that runs on your local machine. To share the db across computers you must share the file.
I can't say this with certainty, but if you need to use a vxworks cRIO and don't like suffering, mysql is the only option.One recommendation I have is to use a schema that allows for history. A nice writeup of the concept is here: https://martinfowler.com/eaaDev/timeNarrative.html
The implementation should be pretty simple...basically add a "valid from" and "valid to" field to any table that needs history. If "valid to" is empty, the row is still valid. You can use triggers to create the timestamps so you never have to even think about it. You can also skip a step if you always have a valid field, as then you just have a "valid from" field, and select the newest row in your query. An alternative but more complex implementation would be to have a table which only represents the current state, and use a trigger to copy the previous value into an append-only log. The first option is more valid if you regularly need to ask "what was the value last week" or specify "the new value will be Y starting on monday" while the log is more appropriate just for tracking -- something got fat fingered and you want to see the previous value.
I'm pretty familiar with SQL databases, so I have that going for me! Using them for configuration/calibration data will be a new one though. I'll probably opt for mysql since I have the server already. Luckily we use a Linux based cRIO (and the config is currently loaded on a PC before deployment, though this could change in the future).
I like the history based schema! Great idea! Do you have any examples of queries you have used to pull current/previous data?
7 hours ago, CraigC said:Either way, if you are using SQL or files for configuration there is usually some sort of trigger chain. By this I mean that there is an order in which the files (or SQL tables) must be re-loaded if any file in the chain is changed. Thus if your config dependency is sort of hierarchical as you suggest then my usual approach to this problem is to brute force all of the loading. For example if you have files (or tables) A->B->C->D then no matter where in the chain a file is changed the whole chain is refreshed. So for example if file C is changed and it has no impact on A, I dont really care I just re-load everything (A,B,C and D).
An advantage with databases is that these triggers can be attributed to fields within tables. This can often require some careful thinking and is worth doing with larger databases. However if it takes a minimal amount of time to reload everything then at least you know all of your tables / config data has been refreshed and you're not using old fields.
On the other hand if you are constantly changing values within your files (which I dont think you will be for configuration) then you may well want a finer amount of control as to which properties / fields you want to refresh within your application. If this is the case I would argue that these changes should not really be held in configuration files and a database or memory structure which is written periodically back to file should be used instead.
Great things to keep in mind! My current operation is that a config file is loaded on the PC and deployed to the target on startup (target runs a simple EXE which receives and loads the config at runtime). I'm thinking this means I can just rely on pulling the whole configuration at launch. I'm lucky in that the configs take very little time to read in, so I don't think that will be an issue. Also, the values change often now, as we are still in buildout/validation, but should slow down in a month or two.
-------------------------------------------------------------------------------------------------------
Overall, my first guess at a database structure would be something like this:
But this presents the question how to handle different sets of parameters. Perhaps you just have n number of Parameter columns and interpret the data once loaded? If you ever need more parameters, add another column? Or would you consider something like below? To me the schema below seems hard to maintain since you have a different table each time you need a different type of calc. Is there such a thing as OO Database Design? Haha
Other questions that come to mind:
- To pull these data, you would still need a config file which says "I need Channel ID X", correct?
- Some of my configs are fairly lengthy. Do you have a typical limit on the number of columns in your tables?
Drew
-
I'm certainly open to that as an option. I really wouldn't know where to start, do you have any recommendations or resources to look into?
-
Hello all!
I've recently been looking for a better way to store time series data. The traditional solutions I've seen for this are either "SQL DB with BLOBs" or "SQL DB with file paths and TDMS or other binary file type on disk somewhere".
I did discover a few interesting time series (as opposed to hierarchical) databases in my googling. The main ones I come up with are:
- daq.io - Cloud based, developed explicitly for LabVIEW
- InfluxDB - Open source, runs locally on Linux. Basic LV Interface on Github
- openTSDB
- graphite
I haven't delved too much into any of them, especially openTSDB and graphite, but was wondering if anyone had any insights or experience with them.
Thanks!
Drew
-
Late to the game here, but I stumbled on this post looking for something else, and had a relevant experience.
Working with the OpenG Variant INI files, I found the floating number format %#g to be very useful. It stores the number as either f (floating point) or e (scientific) depending on the magnitude, and removes trailing zeros. This (in my experience) prevents loss of data when working with very small numbers, and keeps the user from having to specify how many digits.
My 2 cents.
-
Hello again LAVAG,
I'm currently feeling the pain of propagating changes to multiple, slightly different configuration files, and am searching for a way to make things a bit more palatable.
To give some background, my application is configuration driven in that it exists to control a machine which has many subsystems, each of which can be configured in different ways to produce different results. Some of these subsystems include: DAQ, Actuator Control, Safety Limit Monitoring, CAN communication, and Calculation/Calibration. The current configuration scheme is that I have one main configuration file, and several sub-system configuration files. The main file is essentially an array of classes flattened to binary, while the sub-system files are human readable (INI) files that can be loaded/saved from the main file editor UI. It is important to note that this scheme is not dynamic; or to put it another way, the main file does not update automatically from the sub-files, so any changes to sub-files must be manually reloaded in the main file editor UI.
The problem in this comes from the fact that we periodically update calibration values in one sub-config file, and we maintain safety limits for each DUT (device under test) in another sub-file. This means that we have many configurations, all of which must me updated when a calibration changes.
I am currently brainstorming ways to ease this burden, while making sure that the latest calibration values get propagated to each configuration, and was hoping that someone on LAVAG had experience with this type of calibration management. My current idea has several steps:
- Rework the main configuration file to be human readable.
- Store file paths to sub-files in the main file instead of storing the sub-file data. Load the sub-file data when the main file is loaded.
- Develop a set of default sub-files which contain basic configurations and calibration data.
- Set up the main file loading routine to pull from the default sub-files unless a unique sub-file is not specified.
-
Store only the parameters that differ from the default values in the unique subfile. Load the default values first, then overwrite only the unique values. This would work similarly to the way that LabVIEW.ini works. If you do not specify a key, LabVIEW uses its internal default. This has two advantages:
- Allows calibration and other base configuration changes to easily propagate through to other configs.
- Allows the user to quickly identify configuration differences.
Steps 4 and 5 are really the crux of making life easier, since they allow global changes to all configurations. One thing to note here is that these configurations are stored in an SVN repository to allow versioning and recovery if something breaks.
So my questions to LAVAG are:
- Has anyone ever encountered a need to propagate configuration changes like this?
- How did you handle it?
- Does the proposal above seem feasible?
- What gotchas have I missed that will make my life miserable in the future?
Thanks in advance everyone!
Drew
-
Well, not sure how to mark this as answered with the new layout, but I tried shoneill's suggestion, and it works great. Thanks for everyones contributions to the thread!!
-
1
-
-
I like that thought as well, more flexibility. Probably looking at iceboxing that one for future investigation tho, gotta keep a schedule!

Advice on OPC
in LabVIEW General
Posted
Good point! I suppose the benchmarks would then be more along the lines of "how fast can the server turn it around". I like the idea of event/change based updates as opposed to polling, but you are right that it will be very driver dependent. Honestly, I wish I could just get the data directly in LV. That way I can use the data as I need it now, and build my own data server when I have time!
Any reason to go with the NI OPC Server over the Kepserver?
Don't think I knew that ... wonder if it is true of RT as well. Not that I'm looking to dive into the SVE right now, but good knowledge to have anyways.
Cool on the .net driver, if I go this route, I'll have to check it out. I'm assuming Linux RT == no .NET unless NI has worked out something fancy. Thanks for the other links, I'll check them out!