

styrum
-
Posts
39 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by styrum
-
-
Well, you are missing some important details in "The story of how this came about". So maybe indeed "it is worth a post of its own". It was LabVIEW 7.0 where they forgot to put a password on one of the VIs shipped with LabVIEW. And that VI had some node(s) on its block diagram including, I think, the BD reference property for the VI class. The community indeed got excited. But what did NI do? They tried to hide everything again in LabVIEW 7.1! I made a joke then that "our mother" NI must had had a PMS so she put the most interesting toys on a top shelf. So I made a"ladder" for us, kids, to get to them again and called it
hviewlabs was me then, because that was a name of my company I used to sell my LabHSM Toolkit, an actor framework with actors controlled by hierarchical state machines (statecharts), long before the Statechart toolkit by NI, "THE Actor Framework", DQMH, and even before LVOOP.
After PJM_Labview has published his private class generator http://forums.lavag.org/index.php?showtopic=307&hl=# and class hierarchies http://forums.lavag.org/index.php?showtopic=2161# and http://forums.lavag.org/index.php?showtopic=314&hl=hierarchy# (neither topic is available anymore) it became clear how to get access to private classes, properties and methods. However, it wasn't convenient enough. My PMS Assistant made it really easy. It gave back the access to those features to a much wider community of LabVIEW enthusiasts
As you can see from the PMS topic discussion, by that time brian175 already had made his DataAct Class Browser. And he got really excited about the possibility not only browse but also to actually create objects, property and method nodes with the properties and method NI didn't want the users to see.
By April of the same 2006 he figured out object creation too and incorporated the capabilities of PMS Assistant into DataAct Class Browser.
At that point, I guess, NI decided that "the cat is out of the bag" and there is no point to resist. Nevertheless even after VI Scripting was made released by NI some classes, and even some properties and methods of public classes remain hidden even in LabVIEW 2024.I wonder why DataAct Class Browser is no longer available (as of January 2025) as well as original findings by PJM_Labview even here, on LavaG. Did NI "politely asked" admins to remove all that and just forgot about my PMS Assistant?
-
 2
2
-
-
I reported the expression node too to the NI tech support guy who's dealing with this bug report.
-
 1
1
-
-
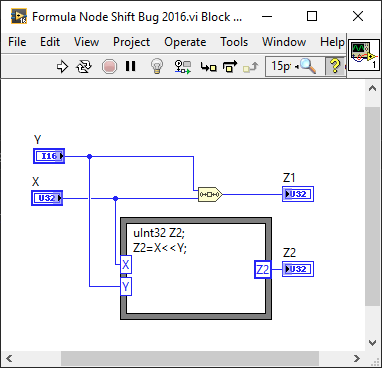
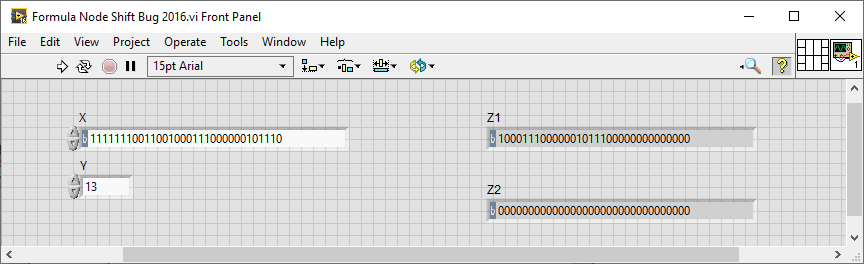
Was there at least in LV2016.

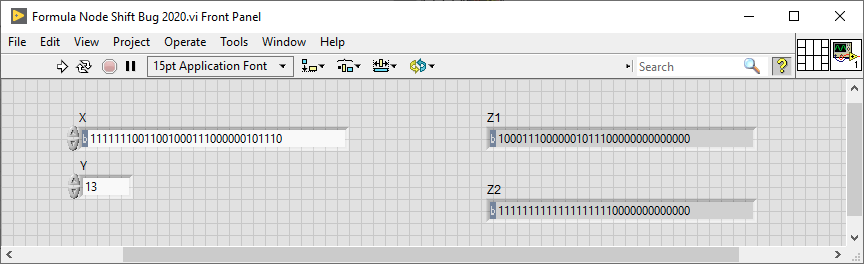
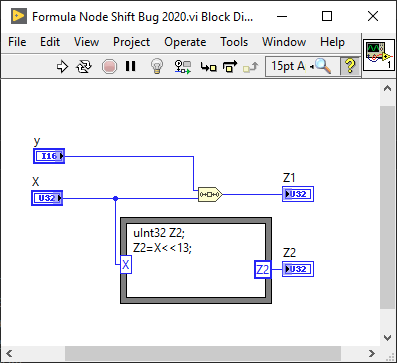
Still there in LV2020
The corresponding VIs are attached.
Formula Node Shift Bug 2016.vi Formula Node Shift Bug 2020.vi
-
A nasty caveat with "Preserve disk hierarchy" is that you can end up with too long of a resulting path string for some files in the build which is still not too long in the source. There is an apparent limit on the path length (in terms of total number of characters including the file name, not number of folders levels) after which LabVIEW (Windows) refuses to open a file with such a "too long" path (this can happen with unzipping a deeply nested archive into a too deep folder of too by the way). The limit can manifest itself even at a build stage (Error 6). But it is worse when it happens while running an exe. So keep your folder and file names short and keep the source code folders as close to the root of the drive as possible. The chances to run into the "too long a path" issue become higher when your source located on one drive references libraries from another drive, say, from user.lib or vi.lib which are obviously within LabVIEW folder which in turn is most likely on drive C while you may want to keep your source code on, say, drive D. Then you can end up with a folder structure MUCH deeper in the build than it is in your source and run into the problem with much higher probability.
-
As I suspected, the short answer is: no, we can't. This was confirmed to me by a known expert in LabVIEW application building and deployment Matthias Baudot from Studiobods. Merci beaucoup, Matthias! Here is his answer:
Unfortunately, it is not possible to embed custom files inside the executable when building a LabVIEW application. Only “code” files in the point of view of the LabVIEW Run-Time Engine can go inside the executable. Other “support” files must go in a separate location on disk. Therefore, it is not possible to do what you want.
However, you could configure your exe build specifications to store your classes outside the executable and so maintain the file hierarchy with your custom files residing next to your lvclass file.
For instance, let’s say you have the following LabVIEW Project:
By default, the resulting files when building your executable will be:
Instead you could have something like this:
Here you can see that your Application.exe will now load the classes from the “Classes” folder. Each class resides in his own “Class 1”, “Class 2” or “Parent Class” folder with all the files including your Custom file.
To achieve this, you simply have to create a new Destination (named “Classes” in this example) and make sure to check the “Preserve disk hierarchy”:
Then, configure each class to go to this new destination (“Classes”):
Note that even if the the VIs of your class are not embedded inside the executable, you can still protect your code from being pirated by making sure the “Remove block diagram” checkbox is ticked (which is the default behavior). In this case, your code will be machine compiled the same way as if it goes inside the executable and the block diagram will be removed so nobody can see your code when distributed this way:
I hope this helps… Good luck with the Project Provider Framework 😉!
Regards,
Matthias Baudot
Tel : +1 (418) 780 4443
matthias.baudot@studiobods.com
-
I have an additional (custom) project item(file) type defined and a primary project provider for it, complete with its own icon/glyph and a dedicated editor for editing such files. Such files contain just some additional info about the class as a plain XML/JSON text but have a custom file name extension. I manage to store such files within class libraries in the project (.lvclass files are just XML text too) as yet another type of class files (in addition to .lvclass,.ctl,.vi). Just like in the case with class method VIs in classes inheriting from one another, there can exist this new type of files with the same names associated with those related classes (and stored in the same folders with the .lvclass files in the source). The logic of selecting particular ones at runtime is the same as with overriding method VIs: the one in the calling class itself or (if no such file there) the one in/from the nearest ancestor is used.The project providers is a "rusty nails" topic, as we know. For example, for some reason I can't drag those custom items/files between folders/classes. As anyone can see, it is the case for the published examples too, by the way. https://forums.ni.com/t5/LabVIEW-Project-Providers/bd-p/bymqyodmkc?profile.language=enHowever the project provider issues for my type themselves are not my main concern right now. The question I have for this forum is: can we make the app builder to store such additional items/files with the the other class items (.lvclass, .vi, .ctl) when building an EXE, i.e. inside the EXE itself, in the corresponding class folders, right where they were in the source? By default the app builder throws all of them into the same "data" subfolder. That can create filename conflicts, so the app builder makes additional "data" folders with unpredictable names. I can kind of work around this by having only the top level VI in the EXE and creating source distribution with directory structure preservation for the bulk of the code or use the app builder API to programmatically create/update build specs with known (separate for each class) target folders for storing these files but all that looks too clumsy.
-
Much longer "nail to the coffin" 😜 of THAT KIND of OOP (written 5 years earlier than the subject rant/"opinion"). Or an entire box of nails rather. And even interfaces introduced in 2020 don't help LVOOP considering all those "nails".
Even if you don't read the whole thing, notice the same conclusions (recommendations of alternatives) in the end regarding the paradigms and languages to use instead: actor model (Erlang) and/or functional programming (Haskel, Closure). Again, it was written in 2014.
Also notice that some comments above are too similar to "No True Scotsman..."😜
-
7 hours ago, jacobson said:
I would say here you are just describing what an Actor does and nothing specific to OOP. An Actor can be an object but doesn't have to be from my experience. I personally think that this use of inheritance can be the most difficult to actually understand/maintain as well. If you've ever used an NI's Actor Framework where the inheritance reaches depths of 5+, trying to understand what the Actor does can be quite difficult (though someone might claim this is because they violated SRP).
Perhaps I'm missing some historical context though and should read some older papers.
Exactly! To implement an actor in LabVIEW one doesn't need LVOOP! Quite a few "asynchronously communicating modules" producer-consumer design patterns, developed by different people independently from each other including my LabHSM and EDQSM show that very clearly. After all, LVOOP didn't even exist when mine were developed. One can get away with just a cluster in a shift register to access any the data from any action case, but, OK, lets instead make an instance of a "regular" (LVOOP) class and make each action case just call a corresponding method of that class. It will look a little cleaner. The main point of creating an actor is to make an object more than just a bunch of data and methods, to give it a "process", "life", to encapsulate its state and enable it to exchange messages with other objects while having that own "life", i.e. the original Alan Kay's idea about what an(y) object is(should be). If your objects are like that (actors), and you build your application with (out of) them instead of the "regular" (data plus methods) objects, then you don't need all those complex "Gang of Four" design patterns which you indeed better use if you stick with "regular" objects.
IMHO the main harm from "THE" Actor Framework is that it scares LabVIEW developers away from the actor model.
-
-
I think it is important what exactly we call "OO code". If objects are not simply "dead" combinations of data and methods, but rather have their own "life"/"process", exchange messages with the user, "environment", and other objects the way actors do, react to events, I am all for such "OO code". The "regular/"passive"/"C++/Java/C# style" objects indeed have a very limited use and I agree that the attempts to build large applications using only them by constructing and utilizing complicated inheritance hierarchies and design patterns can lead to a disaster.
-
😂He knew what was coming:
" I expect some sort of reaction from the defenders of OOP. They will say that this article is full of inaccuracies. Some might even start calling names. They might even call me a “junior” developer with no real-world OOP experience. Some might say that my assumptions are erroneous, and examples are useless. Whatever. "
I think we all still can benefit from a more substantive discussion of his particular points rather than from accusations of "not understanding", let alone "calling names" and insults.
A "straw man" demagogic trick is no good either. The author opposes not OOP in general or as coined in by Alan Kay, but rather the C++/Java "kind" of OOP, especially inheritance hierarchies and "promiscuous sharing" of state. Neither he advocates "unstructured coding". And the C++/Java/C# style of OOP is not and never has been the only (let alone "best") alternative to "unstructured coding". Actor model is circa 1973. Smalltalk is even older.
Statefulness, messaging and concurrent code organization have everything to do with OOP if/when they need to be present in the same program in which you use OOP. Just because you really have to figure out how to implement them in your OOP code then. And, very softly speaking, they are not easily implementable with "regular"/"passive" objects consisting of only data and methods that need to be called from "outside" of the objects themselves.
-
Some food for thought:
Note that LVOOP is indeed the "C++, Java and C# variety of OOP" too, and is taught the same way, complete with "cats and dogs", all the same "Gang of Four" design patterns, S.O.L.I.D (https://scotch.io/bar-talk/s-o-l-i-d-the-first-five-principles-of-object-oriented-design), etc.
" The bitter truth is that OOP fails at the only task it was intended to address. It looks good on paper — we have clean hierarchies of animals, dogs, humans, etc. However, it falls flat once the complexity of the application starts increasing. Instead of reducing complexity, it encourages promiscuous sharing of mutable state and introduces additional complexity with its numerous design patterns. OOP makes common development practices, like refactoring and testing, needlessly hard."
I don't agree with everything he says, in particular with a definition of state. A variable is a state variable in a reactive (the vast majority of systems/applications and their components built with LabVIEW are indeed reactive and, hence, best modeled as such https://www.reactivemanifesto.org/) module/system/object in my opinion only if the reaction to some event/message (transition, actions that are run in response to the event, and/or target state) can be different depending on the value of that variable. And each object has its own state. The states of all the objects in the program combined constitute the state of the entire program itself, of course. But the very purpose of breaking a program into objects with their own ("isolated") states is to not have to deal with that combined state. The state of each object can and should be "mutable" in a sense, because real life objects indeed change their state with time and that indeed can have an effect not only on themselves but on their interaction with others. It should not be shared explicitly with other objects though, of course. I totally agree with him on that.
Personally, I came to developing my LabVIEW applications as collections of asynchronous modules/active objects/actors which are backed by (hierarchical if needed) state machines and communicate with each other only via queued messages long before LVOOP was created, let alone "THE Actor Framework", DQMH, JKI's "State Machine Objects", etc. showed up. Search for "LabHSM" and "EDQSM", they are both circa 2004-2006. Those two templates/toolkits/design/patterns/frameworks of mine, just like some other similar "asynchronously communicating modules" frameworks, have no explicit sharing of state and are closer to the Alan Kay's/Smalltalk idea of objects, where messaging between objects is "The big idea" and where the state of the receiver object (and, hence, the actual code/action/method that will be run as the reaction to a particular message from the sender) is of no business of the sender (now recall Do method in AF's message class and what it takes to decouple actors exchanging such messages)! "Active" objects and actors are not just data and methods, which need to be called externally, by some other methods of some other objects and ultimately by the "God" main loop (well, technically, for active objects as opposed to actors, it is still their methods that are called but those "method calls" are actually just message sending to its process). The main idea is that in contrast to the "regular" OOP, each of "active" objects (actors, modules) has its own "life", in which it reacts to various events, both internal (resulting from its own actions) and external (messages it receives from environment/other objects). It can and often does react to the same event differently, depending on its current state. The reaction consists of running some other actions (which may include sending messages to other objects) and changing its state (transitions). Ideally, it is a true parallelism, not just concurrency, i.e. while communicating with others (within the same physical machine or over the network), it runs in its own thread, process, container, virtual machine or even its own CPU core or an entire real physical machine, because each such object is a "microservice". It is like a complete computer in a sense, just like Alan Kay imagined it.
I counted at least three more similar idea "actor frameworks" presented at the latest NI Week and GDevCon. Some of them even use LVOOP :-)
Maybe it is time for many other LabVIEW developers to look at the LVOOP and "regular", "passive", single loop/thread (C++, Java, C# style) OOP more critically too.
Some more on the topic:
https://medium.com/@richardeng/the-object-oriented-schism-9dedbbc3496b
-
The NI definitions of tag, stream and message/command are given, for example, in this cRIO guide (p. 29):
http://www.ni.com/pdf/products/us/fullcriodevguide.pdf
-
It is indeed amazing and sad how attractive and popular "straw man argument" is. I won't even say anything else.
-
The matching discussion on NI forums:
-
9 hours ago, crossrulz said:
There also appears to be A LOT of interaction between things. If I disable the Value Property Node, the User Event gets into the same realm as the Notifier and Queue. Removing the channels makes it even more the similar. Maybe the Queue Status in every single VI is doing something?
Yes, checking the watchdog queue takes a lot of time (if not most of) in each sender iteration. Please check out a "sequential version" in the latest posts or try putting a Disable structure around those Preview Queue Element nodes in the sender VIs (you will have to stop everything with the stop button on the toolbar of the Main then).
-
06-18-2019 04:17 PM
Set Control By Index added. Wow, it is fast!
"Speed" calculation in the "sequential" version corrected to count the iterations of the receiver loops.
-
Ok, OK, my bad, I left Debugging enabled. This is not a commercial app. This is is just some "food for thought", and something to play with, which you would otherwise not have the time to put together yourself. But now you can find some time (much less) to play with it. The goal was to get people to play with it, find flaws, "unfairness", etc. So I am glad that happened so quickly. Here is a version that has debugging disabled plus a "sequential" flavor of the whole thing.
Some disclaimers right away:
1. Yes, I deliberately do not count the iterations completed by sender loops but not completed by the corresponding receivers by the time the senders are done, because I do want to count only fully completed "transactions" in evaluating "performance"
2. No, I don't say that lossy and non-lossy methods are comparable "1 to 1" in general context. But for the declared purpose of this particular experiment, updating an indicator in a UI VI, where the user is interested only in the latest value, it is fair to put them "together".
-
Sorry, I only have LV.2016.
-
1 hour ago, jacobson said:
Would you be able to summarize your findings in a table?
I'm also interested in what frameworks/methods you were thinking of.
Well, the very point of putting together this code is for people to see the numbers for themselves and that I didn't "cheat" on any of the tested methods to make some look better than others. Their significantly different performance numbers are real.
In summary, the main findings are:
1. (Widely known) Passing a control reference to a subVI or a VI running in parallel to the VI where the control(indicator) is located with the purpose of using that reference to update that control/indicator is the worst you can do.
2. (Not so well known) Using "user events" in event structures for the same purpose mentioned and moreover, for implementing asynchronous communications in messaging architectures between "modules", "actors", parallel loops, etc. instead of regular queues and notifiers and now channels is (softly speaking) not a very good idea either from the performance point of view.
3. Even the fastest "channels" are not better than the "good old" notifiers and queues. At least channels give more features and allow to do things impossible before. Which hardly can be said about user events.
DQMH is one of the frameworks which rely heavily on such use of event structures one can recall right away. There are others, I bet.
-
Yes, I know, you wanted to do this some day too. So I did it for you. Just run (and then stop) the Main VI from the attached set (Saved in LabVIEW 2016 32-bit). I suspect (and hope
) the numbers will be quite a surprise and even a shock, especially for the fans of one particular method and some very aggressively promoted frameworks which use that method.
-
1
-
-
Maybe that will work too (again with a control, not with a constant). But there is no explanation there regarding the type expected as the Conpane (variant) parameter of that Set Conpane method. How do we get that Conpane from a VI we want to take it from before we can feed it to that method?
-
OK. So OCD is "obcessive compulsive disorder" I figured. Sorry,
sickospatients, my native language is not English, but I still know what past participle is and even, for example, when to use past perfect tense in English (How many Americans do?).😋 "Cast Operator: () (programming) A type cast provides a method for explicit conversion of the type of an object in a specific situation. v. cast, casted" (https://english.stackexchange.com/questions/94565/can-casted-be-the-past-tense-of-cast) -
For whoever is looking to do anything like this or anything else as far as programmatically changing code in a VI goes, I think I should remind that the best way to find and get a reference to any object you want to mess with on the FP or BD of the target VI is one of "hidden gems", <LabVIEW 20XX>\vi.lib\Utility\traverseref.llb\TRef Find Object By Label.vi

Scripting and Rusty Nails History
in VI Scripting
Posted · Edited by styrum
Oh, so is It now JKI who "forced NI's hand to release scripting"?! Isn't that too much of a credit for him/them considering when he released his framework relative to the previous community efforts mentioned above? Maybe it became "the last nail into the coffin" of the "VI Scripting is for NI use only", but definitely not the only and not the "thickest and longest" one.