

jaegen
-
Posts
152 -
Joined
-
Last visited
-
Days Won
4
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by jaegen
-
-
My gut says "BAD. Prone to abuse." I'm going with my gut on this one.
What if the required output type changes, and it's way downstream? You won't get an error until you run. This should be a development-time error, not a run-time one.
(Also, anything that AQ calls "magical" scares me
 )
) -
-
I think is due to the subroutine priority setting - the loops must not be able to run in parallel, therefore the VI is as currently as fast as we can make it (it acts the same as if those loops were run serially).
Yeah, I figured the loop iterations were already running as fast as possible (with your standard test string, there are only 8 iterations total anyways right?). I'd forgotten/not noticed that the VI was set to subroutine priority.
Therefore, if memory is an issue, I challenge anyone out there to optimise it but retain speed
My suggestion above about chopping the boolean array saves a huge 224 bytes!

-
 1
1
-
-
Just a quick observation. Does this design trade memory for speed?
If so, would this function ever be used in a memory constrained environment such as RT or FieldPoint?
It appears that two copies of the string data (as U8 arrays, one reversed) are created to iterate over. Is the LabVIEW compiler is smart enough to only use one buffer for the U8 array data? What does LabVIEW Profiler tell us about the buffer allocations?
I don't have 2009 installed, so I can't play with the examples.
If there are two buffer allocations for the U8 array data, would there any difference in performance if the 'end trim' loop were to use the same U8 array and simply index from the end of the array (N-i-1) until a hit was found?
I was curious about buffer allocations for the reversed array too. One of the things I tried was to force sequencing of the two case structures, rather than having them run in parallel, but nothing I did had any effect on the speed, even with a very long test string. However, if you pop up the buffer allocations display tool it does show a dot on the output of the reverse array node. I never looked into profiling memory usage.
I also tried iterating backwards from the end of the array, but this was significantly slower than just reversing the array and autoindexing.
I'd say all of this is probably moot though - RT and FieldPoint applications are very unlikely to be doing a lot of text processing, and if anyone is working with a long enough string to matter they should probably be doing something more customized to keep memory copies down.
Jaegen
-
So the question is - can anyone make it faster?

Well after about an hour of trying the only thing I could come up with that wasn't slower was to delete all but the first 32 elements of the boolean lookup array constant, since every character greater than 0x20 is not whitespace. But given that this didn't seem to speed up things at all, only saves 224 bytes, and further obfuscates the code, it's probably not worth it.
Nice code Darin.
Jaegen
-
I can't add anything to ned's reply, but did want to mention that a common mistake to watch for (I make it all the time, and you even made it near the end of your post) is to type 198 or 162 instead of 192 and 168.
Does anyone know if there's a psychological basis for this error?
 Seriously, what is it about these numbers that makes them so prone to mix-ups?
Seriously, what is it about these numbers that makes them so prone to mix-ups?Jaegen
-
<nitpick>
Something about the upgrade, and perhaps the theme LAVA is using, is causing the text of a post to be indented slightly around the user info/avatar section. It only shows up if there's enough content in the post to reach below the div, like dannyt's post above:
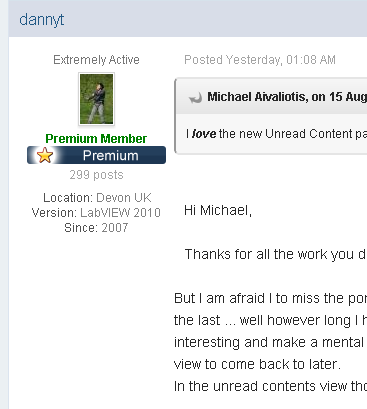
Here's what it looks like if I click and drag to select content in Chrome:
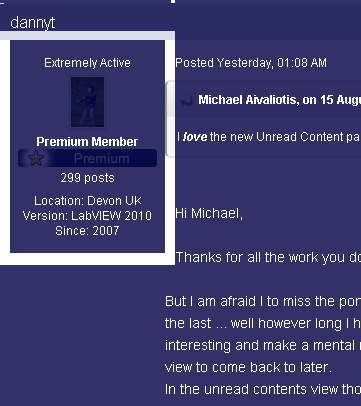
You can clearly see that the border around the "author-info" div is forcing the post content to the right.
Obviously not a major issue, but it's a bit distracting.
Otherwise, I love the upgrade.
</nitpick>
EDIT: My pictures didn't show up first try...
-
I know NI's answer to #2. My answer would have been a CSV file...
We use CSV files a ton (too much) here too, but be warned: CSVs don't like Europe (or Europe doesn't like CSVs) - any country that uses commas as a decimal separator can't use commas as a column separator. After being bitten by this years ago all my text logging code allows for a re-configurable separator and file extension.
Jaegen
-
2
-
-
- Popular Post
- Popular Post
Well, since this is kind of the "Don't use classes in your CLA exam solution"
 thread, I figured I'd chime in with my $0.02 CDN now that I've passed...
thread, I figured I'd chime in with my $0.02 CDN now that I've passed...I spent a long time thinking about whether I'd use classes going in to the exam. I received strong advice from a few people not to, but also bought into Steven's statements above about his experience. In the end, I decided to go with classes for 2 reasons: Firstly, because I'm now way more comfortable using them than not using them (and I hate the sample exam solution's use of "action engine"-type VIs, with tons of non-required inputs), and secondly on principle - Architects should use classes, and if the examination mechanism can't handle that then it needs to be challenged.
My use of classes was quite straightforward, and seemed obvious (to me at least). All of my VIs and controls belonged to a class except my top level VI. The only issues the markers took with my architecture were to note the areas where it wasn't complete or properly documented, which was completely fair (since it wasn't - I ran out of time). I'd say my biggest mistake was getting sucked into too much "implementation", at the expense of completing the architecture. I am certainly grateful for this thread though, since it raised the level of discourse about this issue before I wrote my exam, and Zaki spent a lot of time addressing this in the exam prep session I attended.
I would say, however, that using classes probably takes more time. There's a lot of "background" work to creating a good class hierarchy, with icons, documentation, data member access VIs, access scope, etc. If you're confident in your ability to create a non-OOP solution, you might consider this. Time was a huge factor for me, and four hours of hard-core, non-stop LabVIEWery is exhausting.
And here's a tip I struck upon the night before my exam: Create a quick-drop plugin to prompt you for a requirement ID and automatically create a "[Covers: XX]" free label. This only took me about a minute (I memorized the steps before the exam), and probably saved me 20. Make sure you turn on scripting in Tools-Options, then copy "C:\Program Files\National Instruments\LabVIEW 2010\resource\dialog\QuickDrop\QuickDrop Plugin Template.vi" into the "plugins" folder, rename it, and edit it to create a Text decoration with the appropriate text. You can even use the "Prompt User for Input" Express VI
 . Then assign an unused key (hit Ctrl-Space, click on "Shortcuts...", then the "Ctrl-Key Shortcuts" tab, and your VI should show up in the list). For me, adding a "Covers:" free label was only a few key-clicks.
. Then assign an unused key (hit Ctrl-Space, click on "Shortcuts...", then the "Ctrl-Key Shortcuts" tab, and your VI should show up in the list). For me, adding a "Covers:" free label was only a few key-clicks.Jaegen
-
8
-
P.S. I'm also periodically stressing about whether I passed the CLA whenever I think about it. Fingers crossed...
And I passed! Woo hoo! I suddenly feel like a member of an elite cadre of hard-core developers.
 That or a loosely defined herd of NI-brainwashed nerds. Same difference...
That or a loosely defined herd of NI-brainwashed nerds. Same difference... 
Now to convince management to send me to the CLA summit ...
Jaegen
-
I'll bite:
I'm going through the rather tedious process of porting our test stand code over to yet another version of test stand. Essentially, this means I'm re-creating low-level I/O code to feed into the underside of our hardware abstraction layer, but since the I/O list looks mostly the same as an existing one (but of course never exactly the same), it means a lot of copying, pasting, and typing until things look right. This is particularly painful when I'm keen to start testing out LV 2011 and all the new and interesting things I saw at NI Week. Oh well, maybe next week ...
Jaegen
P.S. I'm also periodically stressing about whether I passed the CLA whenever I think about it. Fingers crossed...
-
Are we supposed to have an actual ticket? I paid via PayPal but I dont have a ticket - what do we use for proof?
According to Justin there are no actual tickets. I think the list of attendees is stored in his brain somewhere.
Jaegen
-
This sounds like it might be the Mac version of the problem discussed on the JKI forums here.
You should make sure that you disable all anti-virus type services before trying to install VIPM.
Jaegen
-
I've tried hard, but I could not find how to register for sessions this year. I had no problems with that last year. Could you point me where to click?
Looks like they just released the scheduler.
Here's the direct link: https://sine.ni.com/...tmp2=niweek2011
Here's the link to the community discussion in case the direct link doesn't work for you: https://decibel.ni.com/content/message/24924#24924
-
1
-
-
Thanks for the insight AQ.
I wasn't implying type defs should change - just asking whether the "don't add type defs as data members of a class" rule changes if the type def belongs to the class. If I open the class and modify the type def, doesn't a new version get saved to the class mutation history (since its data type has changed)?
-
Is the class mutation issue the only reason to avoid using type defs as data members? And does the mutation issue exist if the type def belongs to the class? (In this case, the class is guaranteed to be in memory when you edit the type def.) I've never had issues with type defs in class data, but I haven't really used the mutation history feature, and I don't think I've ever used a type def as a data member that didn't belong to the class (other than simple, unchanging things like enums).
Jaegen
-
"about 1.2 miles" ... sure you can't get any more accurate?
You're right though, according to Google, it's only "about" 1.0 miles from the north-west corner of the convention centre.
If survival isn't guaranteed, what is?
-
In the spirit of "pay first, ask questions later", now that I have my ticket ... Is transportation provided, or do we have to get ourselves to the restaurant?
Can't wait to meet everyone there.
Jaegen
-
Sorry, but kludging is the only solution I've ever found for this problem (edit the control and use an appropriately-coloured rectangle decoration over the 118).
Jaegen
-
Don't forget - if all you want to do is use "Get" and "Set" instead of "Read" and "Write", you can just modify the default values for the appropriate controls on "...\LabVIEW 2009\resource\Framework\Providers\LVClassLibrary\NewAccessors\CLSUIP_LocalizedStrings.vi".
That being said - this is a great addition that will make automatic updating of the icon possible.
Thanks,
Jaegen
-
2
-
-
It appears that the RSS feed is having trouble handling rapid replies to a thread. I've seen a few times now where I get the answer before I've read the question (I'm using Google Reader). This thread was the most recent.
Jaegen
-
Thanks for the hard work to everyone involved in restoring LAVA - we couldn't do without it.
Jaegen
-
Dude, slap on some dorky glasses and that would be me as a kid. Almost the exact same setup (though I never had the disk drive melt a table cloth).
Jaegen
-
I have to agree with AQ. I would support changing the sequence structure to have a (much) thinner border, but I think the null wire concept just opens up a whole bucket of confusion.
You could always create a null class, with a thin light-grey wire. (I realize that still means you have to create actual connector pane terminals for it).
Jaegen
LabVIEW Built Windows Applications - Preventing the "Not Responding" Label
in LabVIEW General
Posted
You need to feed it a snack every now and then - it gets hungry on long journeys...