
JackDunaway
-
Posts
364 -
Joined
-
Last visited
-
Days Won
40
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by JackDunaway
-
-
Join us this week, Wednesday, 23 April 2014, 12noon CST (18:00 GMT) for Episode 005: Acting Up: Panel Discussion on Actors in LabVIEW.
Michael and I are excited to host Dr. James Powell, Allen Smith, and Dave Snyder. Or, as you might more familiarly know them on the LabVIEW-Actor scene, drjdpowell, niACS, and Daklu.
This show, we'll touch on current strategies and frameworks used for actor-oriented design in LabVIEW, share resources and experiences on the topic, and answer live audience questions.
Join us this Wednesday at vishots.com/live, and come prepared with questions about developing actors in LabVIEW!
(Pssst... mark your calendars for a special time next month, Wednesday, 21 May 2014, 4:00pm CST (22:00GMT), where we'll hear a story from a product manager down under and a beloved community advocate within NI)
-
It's helpful to think of a "LabVIEW Web Service" as not a monolith -- but rather, a single web server capable of routing requests to handlers using URL routing rules. There's always just that one web server in your deployment environment, and this server can even bind to multiple ports simultaneously for incoming requests (nominally, 80 for HTTP and/or 443 for HTTPS), which then routes those requests to discrete handlers. The routing rules provide the level of indirection you desire between the web server endpoint and the backend handlers.
-
-
-
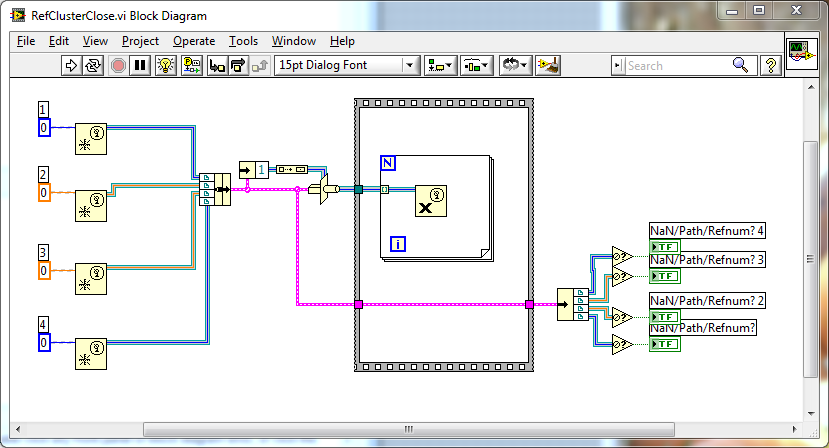
This is simultaneously horrifying and elating.
I love it!
It's a bastardization of the type system, true, but to our advantage -- and seems to be proof that the Destructor is able to dispatch error-free on the ancestor type, regardless of assumed type.
Which begs the request -- I think it makes sense to formalize this rule in the type propper, enabling User Events (and generally, other Refnums which carry/assume a type) to be arrayed, enabling the the more intuitive syntax of auto-indexing through a For Loop.
It's already a by-ref OO API -- like VI Server, this ability would feel and look natural.
-
Greetings, Wireworkers!The previous VI Shots Live shows have been a huge success -- thank you for your continued support and viewership!Join us once more Wednesday, 26 March 2014, 12noon CST (18:00 GMT) for this month's topic - The LabVIEW Nomad: Developing and Debugging LabVIEW Remotely.Whether a true digital nomad, or a team member of a large organization, there's value to knowing how to develop and debug on remote customer machines. Decoupling your person from your deployment target is not always easy, and this month we've got a panel of experienced developers ready to share their experiences and answer audience questions on how to save resources and make the most of getting work done remotely.Michael and I are excited to host Fabiola De la Cueva (Principal at Delacor) and Justin Goeres (Senior Engineer and Marketing Manager at JKI) on this topic.As always, you can join from vishots.com/live -- hop on that link a few minutes early, ready with questions to ask the panel!
Pro-tip -- the Event Page (new event page linked each month, accessible from from vishots.com/live) will add an event to your calendar if you click the "Yes, I'm coming" button (shown below)
(Finally, as a brief logistics note, I'll update this thread monthly rather than creating a new thread in the Lounge)
-
 1
1
-
-
One answer, perhaps unsatisfying (or perhaps even impossible in your scenario) -- attempt to *not* link between PPL's in <LV2013, for practical reasons and heartache of which you are already intimately aware! Consider requesting access to the LabVIEW Beta Program (ni.com/beta) to evaluate new features and give your feedback there.
In the meanwhile, if you have source access to LibC from your original illustration, allow the builds of LibA and LibB to "suck in" dependencies from LibC as private, namespaced members of their respective libraries. This does represent duplication, but is an explicit, legit strategy for two reasons: 1) avoiding linker issues, both during build and run-time, and 2) allowing LibA and LibB to have two separate, decoupled dev cycles w.r.t. LibC, enabling them both to link to separate versions of LibC.
Generally, the same strategy applies to LibA -- decouple it from LibB at runtime if possible, sucking in those dependencies at build time.
Tradeoffs, yes -- but as a best-case scenario, you have source access to all libraries, and your business domain lends itself well to this strategy.
Naive as I am I had a look on the build specs in the project files, and found an node called "Bld_excludedDirectory" but only for source distribution. I copied this entry from there to the spec for the PPL and ..... it worked fine!
...One draw back is, that when resaving the whole project or edit the build spec in the editor it is gone againMy hunch is that your "hacked" settings are preserved with any action other than explicit edits to the Source and Destination settings on the Build Spec, and generally you're fine except when editing these pages, but of course your mileage may vary for such "unsupported" modifications. I've found it useful to run a post-build Unit Test to check for anomalous linkages into areas where I don't expect -- this prevents embarrassing scenarios, of say, shipping a distro that links to something in a "Temp" folder on your user desktop
-
Thanks for the detailed response Jack. I was able to get to step 8.3 before labview hung up on me for 2 hours.
:-(
Perhaps try again, except this time, one at a time, rather than all 20 at once? Else, are you still having problems, or does it seem to be working again?
-
Greetings, wireworkers!
Join us this Wednesday, 26 February 2014, 12noon CST (18:00 GMT) for our next show, VI Shots Live 002: LabVIEW Consulting Panel Discussion.
Michael and I are excited to be hosting David Thomson (Systems Integrator at Original Code Consulting), Steen Schmidt (Founder and Wireman at GPower) and Neil Pate (Director at Premier G Solutions Ltd). Come prepared to ask questions we'll answer live about what it's like to be a LabVIEW consultant, whether you're thinking about it yourself, or looking to hire a consultant.
As always you can join from vishots.com/live.
Pro-tip -- the Event Page (new event page linked each month, accessible from from vishots.com/live) will add an event to your calendar if you click the "Yes, I'm coming" button (shown below)!
-
1
-
-
I am trying to streamline the RTE (using a technique similar to Jack's described here). I will admit I have not made very much progress, I can run a very simple app, but have not yet found the magic sauce for making .NET4 DLLs work, or WebServices.
If you're distributing a Web Service, ship the entire, Full RTE. LV2013 Web service run-time dependencies reticulate throughout a wide smattering of RTE packages, and I've been as-yet unsuccessful to pare to a reasonable subset. (Reference: experience gained through significant efforts over the past year to do this, and far more time in front of ProcMon consoles than what's healthy)
My recommendation is to just ship everything. If you try to be too sneaky with the RTE it can cause you issues if another application installs that loads the same environment. What if you don't install the math libraries but another application needs it? Most installers only check for the registry key added by the core RTE. I don't know how "well" the NI built installers behave with a previously segmented environment, but I expect not well considering if they did their job people like us wouldn't be on this mess.True. A pre-requisite for paring the RTE is the assumption that other LabVIEW applications deployed into the same environment package all their dependencies as part of the deployment. If you're distributing apps that don't ensure all dependencies are within the deployment, instead assuming the deployment environment already contains expected dependencies, even though that's a risky deployment strategy, it's likely to end in some heartache for both dev and end-users.
-
Additionally, is there any way to fix this without having to revert all our source code back to that point and "start over" with all our feature additions? It's over 2 weeks' of coding that we'd basically have to reimplement.
Here's what I would try -- this process anecdotally has helped me, and could help you as well:
- Ensure repo is up to date with all latest developments; ensure that you have no outstanding changesets or modifications to the working copy, and your team working in parallel has no outstanding modifications that could cause a conflict in SCC
- Open project
- From root node in project, right-click to "Properties >> Project page >> Mark Existing Items button >> ensure every item from dialogue is 'marked'"
- Save all
- Restart LabVIEW
- From GSW, Clear Compile Object Cache
- Restart LabVIEW
- These sub-steps are performed as one "transaction" within the context of one IDE session:
- Open project
- Recreate that parent library with the exact same name with your up-to-date repo
- Drag all your ~20 classes back into the library (i.e., the way it used to be)
- Mass compile (and perhaps, see lots of "problems")
- Mass compile once more (and probably, most/all "problems" go away)
- Drag all 20 classes back outside the library (i.e., the way you want it to be)
- Mass compile (and perhaps, see lots of "problems")
- Mass compile once more (and probably, most/all "problems" go away)
- Restart LabVIEW
[*]From GSW, clear compiled object cache
[*]Restart LabVIEW
[*]Open project -- build the EXE -- hopefully, the problem is gone. If so, commit to SCC, with a comment why you just modified 100's or 1000's of VIs
- Ensure repo is up to date with all latest developments; ensure that you have no outstanding changesets or modifications to the working copy, and your team working in parallel has no outstanding modifications that could cause a conflict in SCC
-
Thanks for the feedback. Since you're now able to build, this could mean one of two things: your corruption is resolved, or it's dormant. (Runtime error 102208 would tend to indicate that your Run-Time Engine is not fully installed on the deployment machine you're testing the distro on -- my hunch is this might be unrelated altogether to the original issue)
Errors/corruptions like this are nearly always solvable within a single targeted debug session, with some combination of mass compile, clear object cache, clear mutation histories, inspect linker info for anomalies, procmon or DETT, clues from the crashdump, or at least narrow down to single simple repro and ask for the CAR and refactor to avoid that issue. Inconvenient, but certainly no big deal or more than a half hour. This particular corruption issue (on my side, at least) has had me baffled for over a month, and has manifested itself as several disjoint bad behaviors on end-user's machines, and intermittently. Sometimes, the application runs for weeks, then one day crashes to desktop every time the application is launched. Sometimes, it crashes the first time, but works repeatably each session thereafter for the day. Sometimes, it's crash to desktop, sometimes it's a silent no-op, where a function just doesn't execute. The worst part -- every time I try a new solution, and it appears to be the right solution, but it'll eventually pop up again, but only for a select few customers.
Whack a mole with red herrings -- that's been my MO for some time now, which is why I'm eagerly following this thread.
-
"It was originally LV2012. The build problems first manifested in 2012. I upgraded my machine to 2013 to try to fix the problem, which it didn't." << Aha.
"we only use strict typedefs for a handful of specialized GUI cases. Other cases are standard typedefs" << Not strict typedefs -- do you have any strictly-typed VI references (with an LVOOP object on its conpane) statically linked to any code in your project?
"The sheer number of VIs that returned "Insane Object" errors makes me loathe to try this. I suppose I can try it with one or two VIs on the list and see if they still return an "Insane Object" error on re-compile." << I feel the pain, but give it a go. If this unintuitive workaround of deleting then undoing that deletion "fixes" your root prob, we're almost certainly seeing a related issue.
If the above "workaround" seems to (temporarily) fix your issue, in the context of your other answers that's enough to take this offline to compare notes, then report back here on results.
One final question -- is it possible you may have refactored data structures by changing owning library of a typedef'd cluster?
-
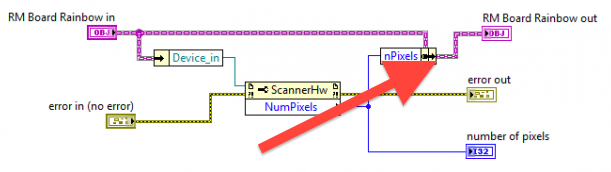
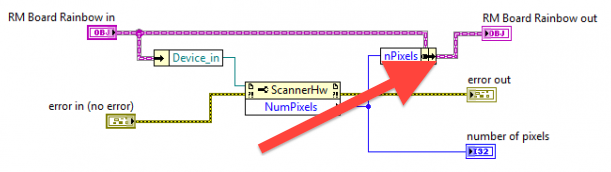
I discovered that subVIs that wrote to specific object elements using bundle-by-name did not have the new value preserved in the calling VI. If I probe the object wire coming out from the bundle-by-name, it has the new value correctly. But if, on the calling VI's diagram, I probe the object wire coming out of the subVI, it does NOT have the new value.
The workaround was to replace the bundle-by-name with a Property Node write
Following onto mje's linked threads, your problem here seems backwards from normal -- replacing a Property Node accessor with a Bundle by Name is more likely to solve problems than cause them.
Is it possible that the wire is not connected as it appears to be connected? On the original diagram, you right click the wire and "Clean Up Wire", is the output terminal connected to the output of the Bundle by Name, or is it a branch of the original wire (with the joint hidden by the node)?
-
A few questions:
- Was the source code originally created in LV2013, or a previous version of LabVIEW?
- Do you have strictly-typed VI references that contain LVOOP objects on the connector pane anywhere in your code?
- Is the crash intermittent?
- Is the crash reproducible in all environments? (e.g., coworker's computers, other versions of LV)
- Are you using .NET callbacks anywhere?
- What additional libraries (NI and third party) do you have installed?
- Is dev environment in a VM or on bare metal?
- If you run some other CPU taxing process in parallel on the same machine (in order to deliberately steal resources from LV), does the crash still occur?
- Have you tried removing mutation histories from all LVClasses?
- If you open all offending VIs, then CTRL+A on the block diagram to select everything, then delete, then CTRL+Z to undo, does the problem still occur?
- Have you tried DETT in the offending context?
- Have you tried Procmon filtering on LabVIEW.exe events?
Your issue sounds eerily similar to an issue that I'm incredibly motivated to put to rest myself, riddled with red herrings.
-
1
-
Two tips -- the TestStand Deployment Utility has a simple command line API for building deployments (and even installers), and I've talked with devs who successfully use TestStand sequences as functional/unit tests not only in the build environment, but also deployment environment (a particularly clever use of TestStand!)
-
2
-
-
I've run into unexplainable CTD's when using Property Node Accessors and LV2012 and LV2013 -- clearing the Compiled Object Cache usually resolves the issues. Does this help for you?
-
Paul, Greg, others reading along -- I have a few meta questions on this topic:
- How often do you find yourselves wanting to invoke a Compare?
- How often for a Merge?
- After using those tools, are you happy with the results, and/or get the job done you set out to accomplish?
-
Thanks, all, for supporting the show! It was lots of fun working with Darren and Chris's Beard and Chris for this pilot episode. We'll soon post details on February's show.
-
1
-
-
- Popular Post
- Popular Post
Greetings, wireworkers!
Michael Aivaliotis and I are teaming to co-host a new monthly web show -- VI Shots Live (http://vishots.com/live/) -- where we invite special guests to talk shop and tell stories about the business of software engineering with LabVIEW.
This show is streamed live, and you can watch using the link above. Episodes are recorded, and the archive will be available also at this link. As a live viewer, you can ask questions that we'll answer on-air.
The Pilot Episode airs this Wednesday, 29 January 2014, 12noon CST (18:00 GMT). We're quite excited to be talking with Christopher G. Relf (Chief Architect at V I Engineering, Inc, a National Instruments Platinum Alliance Partner) and Darren Nattinger (Principal Engineer, CLA, LabVIEW R&D). The topic is on building sustainable careers with LabVIEW.
Hope to see you there! Again, the link: http://vishots.com/live/

-
3
-
I can report back to this thread if we learn anything of interest.
I stumbled upon one resolution to this issue (air quotes, "issue") recently:
- Restart LabVIEW
- From the Getting Started Window, select "Tools >> Advanced >> Clear Compile Object Cache..."
- Clear both User and App Builder cache (my hunch is that the App Builder cache is not necessary; but why not)
- Restart LabVIEW
- Open the guilty lvproj
- Mass compile the project root
- Now, "Find Items Incorrectly Claimed by a Library" -- no more spurious ownership issues
Anecdotally, it's not sufficient to clear the cache while the project is loaded (or, perhaps it might be sufficient with a subsequent reboot). Your mileage may vary.
-
1
- Restart LabVIEW
-
Sooooo.... perhaps let's just short circuit and skip to regexes... how sophisticated exactly is this modification you're wanting to do? (related: attachment)
For the future, here's a convenient link to test XHTML compliance of a document, as a "first-pass" check whether the LabVIEW DOM parser might have a rough go at it: http://validator.w3.org/
-
1
-
-
Thoric, the way I do this is using Actors, where the Actor using scripting methods is running in the LV environment.
Consider an actor as just an API around a shared resource, used to abstract and encapsulate state and resources. Defining an API to the Actor as a TCP/IP messenger with endpoints to handle message types (the native LV2013 Embedded Web Servers work swimmingly for this purpose) provides an API with the subset of functionality that you want to perform with the shared resource.
Following your example above, one message type into the Scripting Actor would be "CreateNewVI", and the payload passed with this message are all the by-value parameters needed to constrain the creation of a new VI. That message from the remote caller is marshaled to the Scripting Actor running in the IDE, which has exposed an API through HTTP endpoints. The new VI could further be manipulated through additional messages, or information about it could be returned to the caller by-val.
Limitations? Unlike .NET Remoting, we don't have native type safety between two remote applications, or "direct access" to the object itself. Additionally, this new level of indirection requires more programming -- you're creating a new by-val wrapper API as a subset of the by-ref shared resource API of Scripting. But this is both good and bad -- from a security standpoint, it's fantastic (since only the desired subset of VI Server is exposed, we have built-in declarations for things like access/error logs, security policies, access policies...). From a debugging standpoint, I'd argue it's far simpler, because all API calls are transactional with no distributed mutable state -- that's just a boon of actor-oriented design for ya.
Whether or not this strategy is suited for your problem domain is sensitive to many factors (more business than technical) -- though, know that what you're wanting to do is possible (at the same time, technically elegant and concise), and i'm glad to talk more on specifics.
-
2
-
-
Jack, can you go into more detail about why you would like to see UE behave more like queues with regards to registration? Is it purely so that communication mechanisms all behave as one would expect or do you see some sort of functional advantage to this? I am assuming the former, but I just wanting to clarify.
It's for both reasons -- to satisfy Principle of Least Astonishment, and to allow handler processes to be subscribed to multiple concurrent messengers. In the case of the Piranha Brigade, you might typically want two registrations per Piranha (worker) -- the Job Queue, and the Abort registration. The poor man's Abort is to simply flush the Job Queue, which causes all the workers to fall into their idle/stopped condition.
Is there an Idea Exchange for this, or campaign thread?Not that I know of -- but it might be helpful to start a discussion to focus on this topic. I'm personally not running into roadblockers that can't currently be solved another way, but the ability would definitely clean up existing syntax.
Your in danger here of becoming an architecture astronought.
Nah, strictly the opposite! Solving existing problems such as load balancing with the absolute minimal syntax possible! Multiple readers consuming from one job queue is about a simple a load balancer as can be developed in LabVIEW. The queue acts as the endpoint from which one-or-many sources queue jobs, and multiple asynchronous workers are gobbling away at those jobs -- the queue acts as a passive load balancer, rather than needing to handle routing and scheduling between workers.
A fairly good approximation for Events in LabVIEW are a queue (lets call it "event queue") to a number of queues (lets call them the "handler_queues") where "event_queue" re-transmits the enqueued element to the other queues before being destroyed. In this approximation, we need a VI that adds a queue reference to the "event queue" and registers a unique ID for a "handler_queue" so that when an element is enqueued to the "event_queue" it copies the element onto each registered handler_queue (iterates through all handler_queue0-N). Each handler_queue (just the usual while loop, dequeue element and a case structure), is waiting and dequeues from its respective queue. So we can create event-like behaviour using queues, but have to do a lot more programming to realise it.To clarify -- it's an improper mental model to consider the User Event publisher a "queue". When a User Event object is created, there is no underlying queue of messages that grows with the "Generate User Event" method, and so there exists nothing to "re-transmit" to the handler queues. A better mental model is to consider the Generate User Event method as a synchronous method that enqueues directly into each of [0,N] subscriber queues. It's not an asynchronous method that enqueues an event into its own queue which is then asynchronously re-transmitted to handler queues. This is why Events semantics are so much more powerful than Queues with regards to decoupling systems in LabVIEW, and why native Queues don't make good mental models for how native Events work -- a Publisher does not create a memory leak in the case of zero subscribers. (This mental model I'm describing is just a mental model -- in reality, the underlying implementation has a more sophisticated memory-saving technique by providing one globally-scoped-to-the-context Subscription queue per Event, where each message exists as only one copy with pointers to which registration queues have not yet handled the message. Consider 100 messages each of size 1 unit. Regardless if there exists 1 subscription or 10 subscriptions, there is still only 100 units of memory necessary to hold all subscriptions, plus the relatively-small overhead of references to each subscriber per message. If there are 0 subscribers, then 0 memory is allocated or queued, and each of the 100 messages fizzled into the ether synchronous to the posting of the message) Said another way, the union of Queues and Events in LabVIEW comprise The Superset Of Semantic Awesomeness, and I wish that all merits could be accessible by one transport mechanism API without having to compromise.
We do exactly this all the time with TCPIP servers where events would be a much better solution but, sadly, lacking.Heartily concur. This can be generalized to say, lots of different APIs in LabVIEW would benefit from providing asynchronous output streams that adhere to these Events pub/sub semantics. Again, this is in the spirit of enabling concurrent systems development in LabVIEW, which converges to Actor design and the current topic of asynchronous dataflow on Expressionflow.
Should an application have File >> Exit?
in LabVIEW General
Posted
If you're thinking about dropping this into the "Resetting VI..." dialog, I'd gladly take a "File >> Exit" ... a [X] button ... a big red [sTOP] button...
In all seriousness, I've not even considered removing this menu option.
(... beyond, using the OS X and more sane standard of placing "Quit/Exit" under the main application menu rather than "File", which I guess causes less theoretical cognitive dissonance, if not actually moving the needle on actual UX for those of us with years of Windows experience. For what it's worth, my #1 UX consultant -- my 2.5yr daughter -- tends to naturally swipe at screens as if shooing away -- to exit applications. This is how iOS works after tap-tapping the Home button. Though having once been a touch screen designer, let's agree arm movements and fat fingers will not and can not displace a mouse from 8:00-5:00 for ergonomic health reasons, and Win8/touch/mobile trends that bank on this will likewise not win out.)