

jdunham
-
Posts
625 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by jdunham
-
-
Today I tried to add a new message to a topic where I had also posted the most recent message (sometimes I just can't shut up). The forum put my new text into the previous message and removed all of the whitespace from everything. This is similar to what Yen is reporting but there is also the inability to post as a separate message.
-
QUOTE(Tomi Maila @ Nov 9 2007, 02:21 PM)
I haven't done any profiling, and I think I exceeded my time budget by a few hundred percent on this topic. It would be very interesting to see some performance results. I would imagine that if you had a complicated data type, then the variant attribute approach might get expensive since the attributes are also stored as variants and so you would be flattening and unflattening the data on every access.
Also, I have to say thanks to you, Tomi, for adding the custom probe to this project. I couldn't have developed or debugged any of my code without it.
Another note (I can't seem to make this a separate message).
During development, I invented some graphical conventions to help me understand the recursion and inheritance, but I started a new thread for discussing them.
Jason
-
When I was trying to figure out the object-oriented and recursive implementation of the Map Class, I found it very difficult to get a handle on what was going on. My eyes are accustomed to traditional LabVIEW development and I couldn't get my head around how the inheritance and the dynamic dispatching were working to make AQ's design functional.
What I found most confusing was that it was very difficult to see which VIs, controls and wires were 'normal' as oppposed to those which used special features of the language like recursion. Once I gained some understanding, I modified the wires and icons to help remind me what was going on with the design.
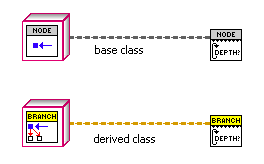
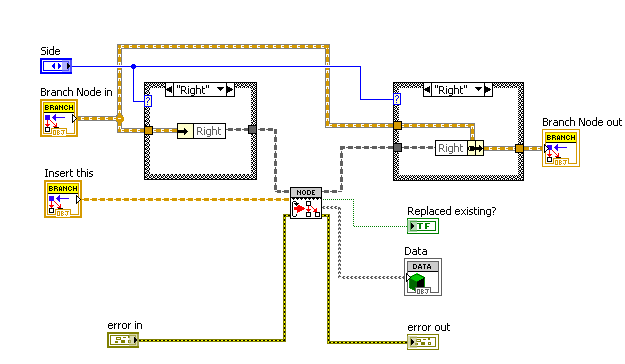
1. Dynamic Dispatching VIs are marked with a "serrated edge" between the template part of the icon and the lower part.

In the future, LabVIEW should change the way VIs look if they are dynamic dispatch, and if they are reentrant, with some kind of simple border or overlay. Until that time, I plan to use a consistent marking on my own VIs.
2. VIs used recursively have a cyclic arrow at the left side. (they are all dynamic dispatch too). "Recursive" should be in the VI name. Since LabVIEW can tell that your VIs are used recursively, they should also have a built-in marking.

3. Base classes, which generally have no private data and empty methods designed for dynamic dispatch, are colored gray in the icon template. The object's wire is also dark gray. The class name contains "Base". I wouldn't use this convention if the parent class was something that could exist on its own; this is for situations where no parent class objects should exist, and all objects on that wire are supposed to be an inherited class at runtime.
4. Child Classes have a color in the icon template, and a matching wire color, and the same wire pattern as the base class. The name should start the same way the base class name starts with a modifier at the end.
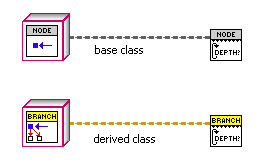
5. Remember that unbundle text uses the wire color, so only use wire colors with reasonable white contrast.
6. Use old-style BD terminals for built-in data types (including the built-in generic object), and newer icon terminals for lvclass terminals.
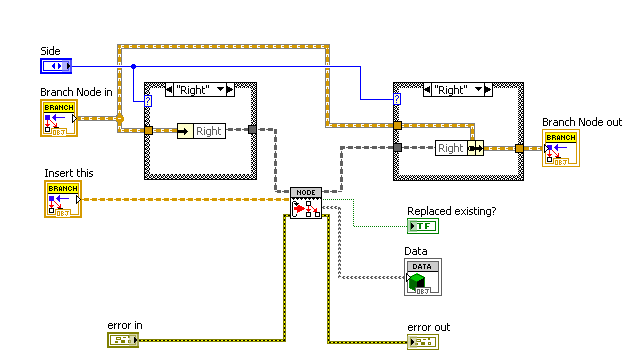
I would be curious to see whether these ideas help anyone else understand the Map Class code better, and whether you have more suggestions for conventions we can adopt or ideas to suggest to LabVIEW R&D.
Jason
-
QUOTE(Norm Kirchner @ Nov 9 2007, 12:29 PM)
Norm, you are right, but in the current version, CompareKey is a dynamic dispatch VI. If you make a key with a different data type, you have the opportunity to redefine the CompareKey function. Then you can sort your clusters however you like, with the built-in compare aggregates comparison or else with an application-specific comparison. For example, some of the cluster's fields could be ignored when performing the comparison.AQ, What I was asking regarding not the use of just a class, but something more complex, like a cluster. So my comment about needing compare aggregate is still valid. -
QUOTE(Jan Klasson @ Sep 14 2007, 12:09 PM)
Actually Endevos GOOP 3 class architecture provides protected data which is what you want. It is based on the lvclass and adds the by-reference model....
Sorry for the plug, but I thougth it was informative since you clearly want protected data.
Hi Jan: Thanks for the tip. I will check out the Endevo toolkit. I have heard so much about it and I am glad to hear it could solve some problems. I think the by-reference objects will help with some other constructs I am working on. Does the toolkit also help with by-value classes?
However, I do still wonder whether NI will move toward access of protected data. It seems to me that there are many cases where inheritance doesn't help much if the inherited parent data is not availaible to the children without accessor methods. It's not that you can't get the data (via methods) but standard LabVIEW clusters make access to the data so easy, that it's hard to see how the native object-oriented implementation will be worth the trouble of implementing it.
-
QUOTE(Jan Klasson @ Sep 14 2007, 03:04 AM)
QUOTE(Jan Klasson @ Sep 14 2007, 03:04 AM)
About the session data field in the Vehicle parent class. I don't know what kind of code you need to handle the session but let's assume you put it in a separate class to use containment. Then you let Vehicle contain this class in one data field. This may be good from a design perspective (I couldn't tell without knowing more about what you do) but it doesn't solve the issue that you find annoying, i.e. child classes has to use a get method from the parent class to read out the object... back to square one:-).Yes, I tried it just after posting and realized it doesn't work. The child can't use the private data from a class it contains. That makes plenty of sense, but I have to find a different solution. Maybe I am just allergic to lots of accessor methods and I should get over it, but I see the need for many of tham as an impediment to productivity.
QUOTE(Jan Klasson @ Sep 14 2007, 03:04 AM)
Here is one way of solving the case with scenarios repeating in child class methods.For each dynamic dispath VI in the parent class create a static "mirror" method. The static method should be public and work like a "macro", in this case GetSession-call the DynamicDispath VI to do the job-CloseSession....This scenarion will double the number of methods in the parent class but you will not have to repeat scenarios in child class methods. If it is worth it only you can tell.I think you are right. Your method is probably a sensible way to go. It sure doesn't make a LabVOOP design any easier to implement when protected data would give you this for free.
I actually solved my DLL problem by sticking to one class, and making similar methods for the two types of 'children' which I didn't bother to implement with objects.
Thanks for your response. I would love to keep the discussion going because I feel like this situation will keep recurring.
-
I saw a comment by Aristos Queue a different thread (see Post #11 in http://forums.lavag.org/I-want-polymorphic...lass-t8853.html) which I want to discuss further
QUOTE
Neither C++ nor Java allows you to cast a value of the parent class as a child class. ...Let me go one step further and say that in the vast majority of cases where you might think you want this ability, you've actually got the wrong relationship between the classes. Instead of inheritance, you should have containment. The "child" class should actually contain as a private data member an instance of "parent" instead of one inheriting from the other. Thus the parent data gets constructed at time N and at time N+1 the child data gets constructed with that parent data as a data member.
I am trying to make some objects which have some shared properties with some different behaviors. For example I have parent class 'vehicle', and child classes 'car' and 'truck'. I don't want to strain the analogy too far, so I'll get real and say that I have DLL code which needs to open a session, common to all vehicles, and then I have different methods for car and truck which could be dynamically dispatched depending on the object on the wire.
On opening the session, I get a handle, which needs to be used by all other methods in the child classes. In my first attempt, the session was in the parent private data, so I would need a parent accessor subvi call in every child call just to get the handle value. I guess that's not a deal-breaker, but it just seems like an unwieldy pattern. It would be easier to just include the handle in each of the private data clusters for the children, but that chips away at the whole point of an object-oriented design, which is to avoid duplicating common code and data structures.
So on re-reading the quoted text, it seems like I could make the parent data structure include the handle, and then stuff the parent private data into the child class so that it is available where the code needs it.
Does that make sense? Should the child class still inherit from the parent class? Maybe my parent class is really gasoline, used by car and truck, rather than vehicle, the generic type of car and truck. I'm not sure how I can really tell the difference.
-
I think most, if not all, NI DAQ cards can do simultaneous input and output. But the DAQmx API was not designed to handle this as a single task. The main trick you want to use is to make both tasks share the same sample clock and starting signal when you are configuring them.
There is an example VI at <labview>\examples\DAQmx\Synchronization\Multi-Function.llb\Multi-Function-Synch AI-AO.vi, however that VI only has common start signal rather than forcing the sample clock to be shared as well. That should be good enough, but it is also pretty easy to share the sample clock with the same type of DAQmx property nodes.
-
QUOTE(Aristos Queue @ Sep 5 2007, 07:14 AM)
GOOP or LVOOP?If you're wanting to transmit the object from one LV to another LV:
...
Helpful?
I think Harish was talking about treating his instruments as objects, and how you would create an instrument driver using an object-oriented approach.
I'm still pretty new to LabVOOP and OOP in general, but it seems like you want to think of all the stuff the instrument driver knows, but which the rest of the program shouldn't care about, and make that your class's private data. Then you would think about all the actions you perform on the instrument and make them into methods, along with other methods to do any necessary manipulation on the private data.
I think it can be pretty easy to make that disctinction between public and private, because you could say "If I changed to a different instrument from another vendor, what items would change and what would stay the same?". Anything which is likely to change should be private to your object.
The open question is how much benefit can you get from inheritance. It's plain that you could make a class for a generic instrument and then a generic oscilloscope which inherits from it, and then have children for different scope vendors, but if you just have one scope on your bench, it probably isn't worth the trouble to create that model and implement the hierarchy.
Of course if someone reading this knows it is worth the trouble, you should use all of the time you saved to tell the rest of us the story! :worship:
Jason
-
QUOTE(yen @ Sep 3 2007, 12:06 PM)
I'm sorry, but I don't see how this can be used. As mentioned in the original post, you can get hundreds of Value Change events from a simple move of the slide. In your example, if you get a hundred events, it would take 5 seconds before the code finishes executing for all the values which are mid-way, when usually only the last value is needed. That was the point demonstrated in my two methods.Well I built it before posting and ran it and it worked great, so I just don't know what to tell you.
I looked in the LabVIEW manuals and didn't see any direct information on why this works, but I have to assume that the NI developers either knew in advance that it would be useless to stack up events for a slider control, or else they did it wrong the first time and it was fixed in an early LabVIEW 6 beta. The slider control would probably be unusable if moving its slider generated thousands of events and they were allowed to accumulate.
I was a little surprised that orko's last suggestion also worked. I thought it would miss the last update, but it never does. That means that the sequence frame is not needed at all.
What you can't really do is know that the slider is still in motion and only run the event case one time when the mouse up has occurred. I don't think that's possible, since there is no safe way to trap the mouse up event.
Jason
-
Here is a simple solution. The main issue is that the GUI goes dead during the waits, so the slider is not even repainted as you move the mouse. If you set the wait time above 250 you can see that the behavior is really unacceptable, but for values of 50-100, it's totally fine.
The subtletly is that you can't use the NewVal from the Event Structure because that will usually be stale by the time your wait finishes.
http://forums.lavag.org/index.php?act=attach&type=post&id=6834
I generally shy away from handling mouse up/ mouse leave events because there are many cases in which they don't really behave the way you would like, as orko found out with his example.
Jason
-
QUOTE(Aristos Queue @ Aug 17 2007, 01:29 PM)
AQ's general thoughts on project, library and VI relationships:The post above said "that lvlib is a namespace and has a one-to-one pairing with VIs". The Library actually has a one to many relationship with VIs. Each lib contains multiple VIs. You should package together VIs that are related, to the extent that feels reasonable to you. Some libs are very small. The Analysis library that ships from NI has 600+ VIs in it. In the words of Yoda, "Size matters not." It is a question of how related the functionality is and whether the VIs are intended to be distributed/used together. You can use sublibraries to give further breakdown if that is useful.
The point I was attempting to make is that a given VI can only be a member of one library. If two different pieces of code need to call the same function, I guess that requires it to be made into a separate object with its own lvlib (or preferably an lvclass), which can then be shared.
QUOTE
My personal goal is that all VIs should be owned by either an XControl library or an LVClass library. Plain libraries should only own other libraries for packaging and distribution purposes. This is in accord with the maxim "All bits of data may be thought of as part of some object; all functions may be thought of as actions taken by some object." Do I actually keep to this goal? No. LabVOOP still has inefficiencies in some places, and sometimes I get lazy. But I'm working toward that goal and do believe it is viable.Not knowing any better, I would suggest that most lvclasses should be contained in either an lvlib or lvproj to hold the class and its test harness and any examples.
QUOTE
All the VIs for a single project go in a single directory unless they are components intended to be shared among many projects. Within that single directory, I recommend creating subdirectories for each library. I do not recommend that you have any further disk hierarchy. If you create folders within your libraries, so be it, but don't make directories on disk that reflect those folders. Why? Because folders are the organization of your library for presentation as a palette and for providing scope for VIs. It is really annoying to want to change the scope of a VI and have to save it to a new location to keep your disk organization consistent. And it serves no purpose. If the library is a coherent distribution unit, then when you're on disk you're supposed to be moving the entire library as a chunk. Some people complain that that makes it hard to use the "Select a VI..." item in the palette. But I suggest that is what drag-n-drop from the project is for. Use the project window as a pinned palette during development. When you deploy, deploy the library with a .mnu file that is part of the regular palette hierarchy.One thing that has always been helfpul to me in the non-oo world is to have the top-level folder only contain top-level vis. That's been a self-documenting way to communicate where someone should start when attempting to take over the code. I suppose the key here is to make sure the top level folder only contains the main project, and then within the project, that only main VIs are shown outside of folders.
QUOTE
PS: If your clusters are already typedefs, put the typedef into the project window, popup on it and choose "Convert Contents of Control to Class." This will help you on your way to converting your project over.Great! Thanks for the help.
Jason Dunham
-
I am testing the waters for converting my large application into LabVOOP. We have a lot of clusters (typedefs of course) so the end goal is to hew to AQs advice that "all clusters should be classes". I would also like to supply more unit testing as I go along.
However I feel a bit confused by one basic thing: How do I map my existing code into lvclass, lvlib, and lvproj? I get it that lvclass is the cluster and the functions which muck with its private data, and that lvlib is a namespace and has a one-to-one pairing with VIs. I am also thinking that each functional grouping should be an lvproj which includes some test VIs, or should they be in the lvlib too?
If I can take similar clusters and convert them into inherited objects from a base class, then how much of that goes into lvlib?
I realize there are no strict answers, but I'm having trouble getting started. Any advice would be appreciated.
-
QUOTE(Jim Kring @ Aug 13 2007, 03:57 PM)
Jason,Thanks for the advice. I'm sure I can get it working. It's just pretty odd that my use case isn't addressed under the hood. I've seen this error several times in trivial scenarios and I can't understand why it should be the user's problem to avoid the "resource busy" error when a timeout is specified.
I opened a support request with NI at the same time (2 hours ago) that I started this thread on LAVA. So far I've only gotten automated responses from NI stating that someone will respond to me within 6 hours. The fact that I've already gotten about 5 responses on LAVA is a testament to what an awesome resource and community we have here

Cheers,
-Jim
In my app, I needed long term timed acquisition on some of the channels, so I suspect you may be able to get it working with your retries (how annoying!) whereas I could not.
I presume DAQmx Read is the VI throwing the error. The read process has a property called auto-start. which basically runs DAQmx Start Task if you didn't bother to. You can turn this off, but the default is on. Since the timeout function is really for the reading of the channel not for the autostarting, it sort of makes sense that the driver does not contain code to loop on starting the task, when you are really doing a read and it is starting (and then stopping) the task as an extra favor to you.
You could run your loop on DAQmx Start rather than DAQmx Read, but I guess that doesn't buy you anything except code clarity. You are still at the mercy of the shared timing subsystem. If you can get this logged as a bug against the API, then more power to you!
-
QUOTE(Jim Kring @ Aug 13 2007, 03:09 PM)
I am using a http://sine.ni.com/nips/cds/view/p/lang/en/nid/201614' target="_blank">PXI-6225, which is an M Series device. I have not configured any additional timing -- I'm simply calling DAQmx Create Channel several times at startup to create all of my channels and then calling DAQmx Read (Analog DBL 1 Chan 1 Samp) to read any given channel on demand.I suspect that the timers are integral to the operation of the M-series. When I did something like this, I did try to use separate tasks and never got it to work. I ended up using one task, and reading the channels independently. Architecturally it was annoying because I had to know about all possible tasks in one VI and configure them all before doing any of the reads. If you find a different way, it would be great to hear about it, but I gave up.
To access the channels independently (after the global task start), just set DAQmxRead.ChannelsToRead immediately before calling DAQmx read. I was using sample timing so I also set the property node to read the last N samples which I wanted.
Note that if you set DAQmxRead.RelativeTo = Most Recent Sample, and Offset = 0, it will actually wait until the next sample arrives (Traditional NI-DAQ did this too). You generally want Offset = -1 if you really want the currently available sample with no waiting.
I don't know what happens if you don't request any sample timing at all, but I would read the timing from the property nodes and find out what you are getting.
Good luck, and don't spend too much time without calling NI for more help.
-
Only time for a quick note. LabVIEW only stores timestamps in UTC. In older versions of LabVIEW this was great EXCEPT that there was no easy way to get UTC out of the timestamp; it would always convert it back to your local PC time zone before showing it to you. As far as I remember, if your machine had changed itself between daylight and standard, there was a lot of potential for an hour of error in your timestamps.
Newer versions of LabVIEW (for sure in 8.2) have mostly fixed this, subject to limitations of the OS. You can choose to convert the timestamps to either local or UTC representations, which is extremely helpful (if a bit late in coming).
If you have discrepancies in your files, I would recommend trying to use the LV Timestamp as much as possible. You may be able to do some tricks like check the first or last times recorded as timestamps versus ascii date/times and see if there is an approximate 1-hour difference. You can also check the OS file timestamp and see whether it matches the last timestamps you recorded in the file.
Good luck, and try to use the timestamps as much as possible.
-
QUOTE(Jim Kring @ Aug 13 2007, 02:05 PM)
I have a large system where we are using DAQmx to acquire several analog voltages. Due to architectural considerations, we have decided to use separate DAQmx tasks for reading each channel.Here's the problem. We occasionally get error -50103 which states that "The Specified Resource is Reserved". I was able to find an NI knowledge base entry, http://digital.ni.com/public.nsf/allkb/04BEDD9E9E91ED3486256D180048116D' target="_blank">Causes of NI-DAQmx Error 50103 "The Specified Resource is Reserved", which addresses this issue. Basically, the problem is that DAQmx Read is reentrant and I'm trying to read two channels (using separate DAQmx tasks) on the same board at the same time.
Why would this cause an error? The DAQmx Read VI has a "timeout" input that defaults to 10 seconds! Why can't DAQmx Read simply wait until the resource is no longer "reserved" and then read the channel. If the resource does not become free before the timeout occurs, then I am fine with getting a timeout error or even error -50103.
IMO, this is either a bug or a very poor design of the DAQmx API/behavior.
My solution is to create a wrapper VI around DAQmx Read which implements a retry (in a While Loop) when error -50103 occurs, until the timeout expires.
I believe that the reserved resource is actually the analog sample clock subsystem, which can't be shared. The API doesn't assume this because it could be different for other hardware, but with E series and M series I think this is true; hence the runtime error. You would think that with all of the timers, they could run tasks in parallel, but then the signal routing definitions of those timing signals would become ambiguous.
In general I would agree that the DAQmx API is not the greatest. Just try to take two slaved DAQ boards and make one task which includes all of the channels on both boards. We were kind of bummed to learn that this is totally not possible even with all of the virtual channel stuff.
If there were a call which could return an immediate (non-timed) value from an analog channel, then that might work (assuming you don't care about sampling and timing, but I suspect there is no such call in the API.
Last time I had to do somthing similar, I made the DAQmx task global, and then accessed the specific channels independently, which is pretty easy to do.
Good luck, and thanks for all the coolness at NI Week.
Jason
-
I'm having trouble figuring out how to dynamically clone VIs in LabVIEW 8. In LabVIEW 7, we just made copies of the VI on disk with different names, and loaded them dynamically. We also used the libraryn.llb library from NI to copy the template VI out of the built executable to start making the clones, but that doesn't seem to be working with my LV 8.2.1 built executable.
It seems like LV8 fixed this, with better support for reentrant VIs with separate panels, but I couldn't find good documentation or examples (or the right lavag.org thread) of how to generate an unlimited number of copies at run time. I'd rather do this the right way than fix my old code, because I'll bet it's much easier now.
Thanks
Jason Dunham
-
I'm not sure if the topic title fits exactly, but it sounded kind of impressive. I'm just looking for a general idea here of a direction to take. Any thoughts are welcome.
I have 4 channels of data that I want to sample for 15 msecs. When I start sampling each of the channels depends on a corresponding independant trigger that the code will initiate. For instance, trigger 1 happens so sample channel 1 for 15 msecs. Trigger 2 happens so sample channel 1 for 15 msecs. The triggers can happen any time in relation to one another so for instance trigger 2 could happen during the sampling of channel 1. Part of the problem might be that I have existing DAQ boards I need to use that don't have parallel DAQ inputs.
I was thinking that I have to do a continuous acquisition of all channels and then somehow pick out the data of interest based on a timestamp of when the trigger happened. Does that seem reasonable or is there a better approach?
Thanks,
George
Hi George: I have done plenty of applications with complex access to the DAQ buffer. The normal DAQ read mode keeps track of an internal read mark, but if you bounce around in the buffer you will need ot use a different mode and keep track yourself. Just set your DAQmx Read.Relative To property to "First Sample" and specifiy DAQmx Read.Offset and you will get the data you want. You will probably want to request a larger DAQ buffer size than the default to make sure the data is still available by the time your code gets around to requesting it.
You may also want to set the DAQmx Read.Channels to Read property if you don't want all of the channels. You can also query the DAQmxRead.Status.TotalSampPerChanAcquired property to see which samples are currently available so you don't have to wait for DAQmx Read to return or risk a timeout error.
Jason Dunham
-
Some typedef'ed clusters can get really big when dropped on the block diagram. It can cause a big problem in a crowded case structure. It would be great to be able to replace the typedef with its icon.
-
I think you would need to limit it to enums. I'd hate to see what labview would try to do with the case
1..1000000
Rather than being an option, maybe it could limit itself to 8 items or as many characters as fit, whichever is larger.
- Jason


Icon style conventions
in Application Design & Architecture
Posted
I am planning to start marking reentrant VIs with a colored border (blue?) or maybe an "R" somewhere. I also add a comment on the block diagram "This VI is Reentrant", and sometimes I add it to the VI description.
But on reflection I realize that you should always be able to tell at a glance whether a VI is reentrant. Conventions are fine, but sometimes you inherit old code or change teams, and this is something that shouldn't remain a mystery. It would be best if a future version of LabVIEW will display reentrant VIs with a different marking.
I filed a product suggestion on this at ni.com