

Stobber
-
Posts
213 -
Joined
-
Last visited
-
Days Won
5
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Stobber
-
-
I have a cRIO-9064 with the desktop stand accessory to sell. Where do people sell these things to one another?
-
djpowell, could you add support for extended error codes to this API? I'm struggling with a SQLITE_CANTOPEN error on a cRIO that never used to appear, and I don't have enough context to know what the heck is wrong.
Also, could you modify SQLite.lvlib:Format Error.vi to yield the full call chain? Figuring out where an error came from without it is sometimes really hard. If you don't want to stringify the call chain all the time, maybe make it an option I can toggle on Open?
-
2 hours ago, ShaunR said:
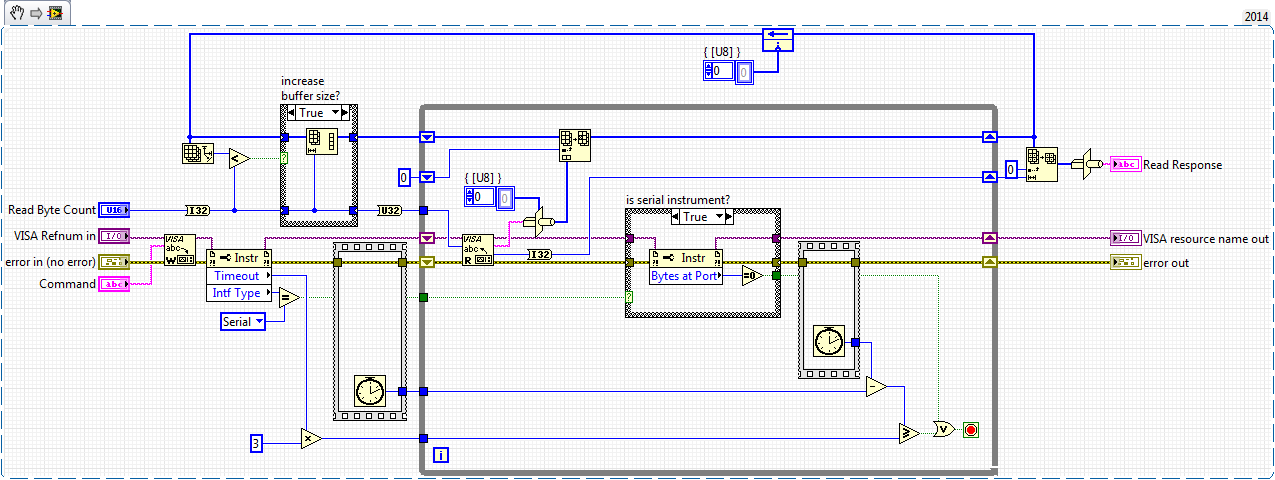
Hmm. Isn't the string terminated? It may be that the read byte count is a red herring and doesn't behave as you would expect. It depends if the port was configured to use term chars in the serial init.
Had to swim far upstream to find the instrument config for this app. Yes, it's terminated by 0xA, as usual. Their query function is definitely looking for a byte count, though. I don't want to have to understand the design goal of the entire API, so I think I'll stick to the edit I have as long as it doesn't cause any regressions or new bugs.
-
Thanks, guys. The instrument's data width is fixed all over the API, probably a fixed memory width baked into the hardware design. So there's no apparent need to code the 64-bit case.
Here's an attempt to make the serial query VI a little less moronic. I'm pulling into a fixed-size buffer while reading, and then doing a single copy afterward to get the string I need. The buffer grows only when a bigger string is called for and never shrinks. This should limit the number of allocations caused by serial queries.
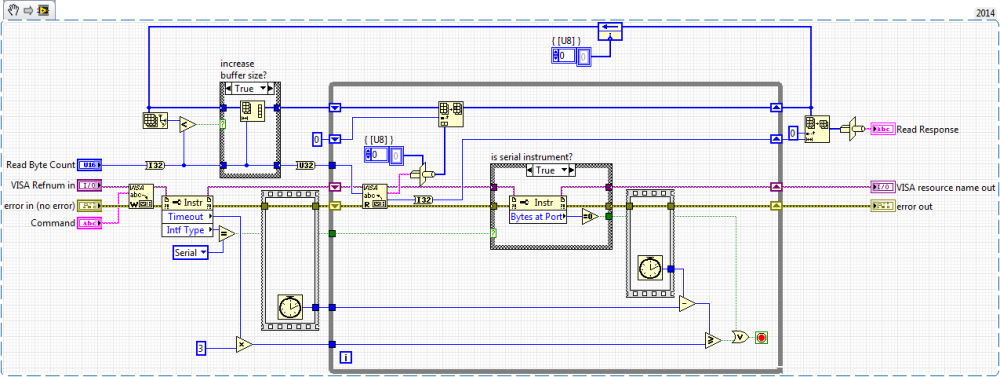
-
I'm using a Keithley instrument driver that works over RS-232 on a cRIO. Our app is leaking memory somewhere, and the component that uses this library is highly suspect. I've been refactoring a bunch of it to use shift registers and IPE structures, and I just found these two doozies (attached, LV 14.1). Together, they build a string byte-by-byte when read from VISA and then convert it to an array of DBL element-by-element. Here's a screenshot of one of them:
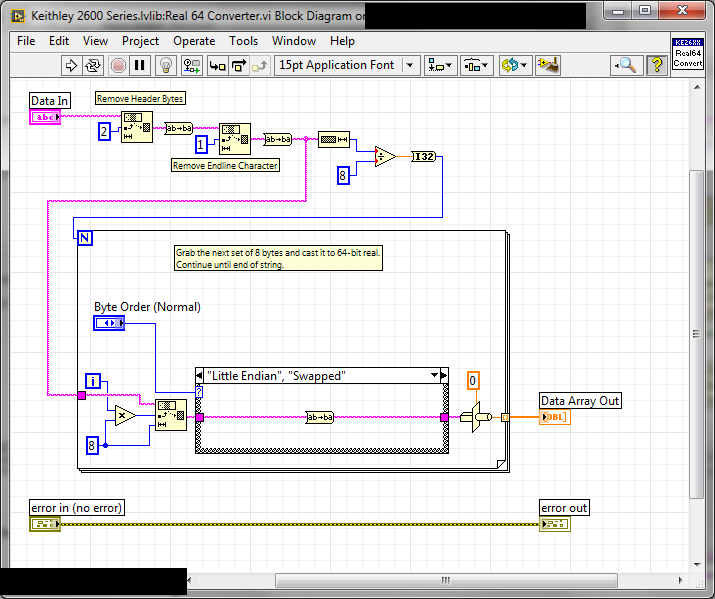
What's the best way to modify these two so they're better citizens of LVRT (i.e. no memory copies, or as few as absolutely possible)?
-
I'm using it in 2014.1. I would wait for a major upgrade to break compatibility. Shaun's suggestion of back-saving makes sense to me. I've done that with concat tunnels, and the code generator replaced them with old constructs appropriately as I recall. If you don't wait for an upgrade, then I'd bump the revision by a major number anyway. You even might consider setting the major rev to the version of LV it's developed in.
-
I wrote all the articles and APIs you linked when I worked for NI. Those APIs only work for the HS-DIO line of products, which are digital vector generator boards. You're looking for LVFPGA code, but I can't find any for a JTAG controller. You'll probably have to develop your own or use the IP Integration Node to import a pre-built JTAG core (if one exists).
-
Test it with a cluster full of big arrays. You should see an allocation when you unbundle/bundle without the magic pattern.
-
1 minute ago, Neil Pate said:
Interesting, do you have any official documentation to back this up? Not that I don't believe you, I am just super curious about optimizations the compiler can make, and things that can be done to help.
No, I don't have documentation. I learned about it when I worked at NI as a Systems Engineer and had access to unpublished documents about LV, as well as people who had developed the language. I verified it with an NI R&D engineer while developing a project in March of this year.
IPE does add logic for other nodes, like the DVR node that adds a mutex when popping the value from the pointer.
-
1 hour ago, Manudelavega said:
Come on!

Trivial examples have trivial impact. Anyway, this is still a derailing of the thread's topic, so let's agree to disagree.

Edit: Found this on an article linked below and just had to post it as a counter-point: https://i1.wp.com/www.notatamelion.com/wp-content/uploads/2015/07/Read-and-Decimate-Big-Data.png
-
1 minute ago, Manudelavega said:
Quick off-topic comment: in AddError.vi you unbundle then rebundle the 'status' and 'source' elements of the error cluster. I strongly suggest using In-Place-Element structures when you have this kind of situation, it optimizes the performances and also makes the code more readable
I haven't looked at his code, but I want to clarify this: for unbundle/bundle, the IPE structure just enforces the "magic pattern". It doesn't add any logic behind the scenes at all. As for diagram legibility, that's subject to preference.
")
(The magic pattern is when you use unbundle by name on the same items, in the exact same order, in a path of unconditional logic (i.e. bundle node not in a case structure). If you change the order, or fail to bundle an item, or bundle an extra item, or put the bundle in a case structure the compiler will duplicate the entire cluster in order to finish the operation. If you follow the pattern, it'll update the items in-place.)
-
 1
1
-
-
No thanks. I simply changed the pattern, and it works fine without having to introduce new dependencies to the app.
-
Thanks, Rolf. That email thread is 6 years old, so I sent a message to Ed Scherer to see if he ever found a solution. Who knows, he might be able to help.
-
19 minutes ago, ShaunR said:
SQLite doesn't support UPSERT.
I know; I'm using that as a succinct way to say "when a row in a table changes in an interesting way". Are you being pedantic and ignoring my actual points for fun?
-
1 hour ago, ShaunR said:
It won't work cross process because it is not a system-wide hook. It works great in LabVIEW on all platforms but won't tell you when another application has changed it.
I don't see anything in the documentation that says it only invokes the hook when changes are made on the same Connection...so how do you know this is true? Why wouldn't an UPSERT made from my Python app's connection invoke the hook that was registered on my LV app's connection?
-
46 minutes ago, rolfk said:
...every supported platform will require the creation of its own shared library (Windows 32 and 64 bit, Linux 32 and 64 bit, and MacOSX 32 and 64 bit makes already 6 different shared libraries not to mention the extra at least 4 cRIO flavours).
Yeah, that's what I expected. Sounds like something I'd have to create for our use. I could post it as a bolt-on to the existing API. Might be able to inherit from JDPowell's class to extend it with this feature...
-
20 minutes ago, ShaunR said:
That's not the function you are looking for. This is.
No it isn't; I use this library exclusively on Linux devices. Also, I think a change notification on the entire db file will be useless if I only want to be notified when a certain table changes.
-
How hard might it be to add support for this feature? https://sqlite.org/c3ref/update_hook.html
I'm really, really interested in using it to avoid polling for changes to a db that gets written by other processes.
-
1 hour ago, drjdpowell said:
Why are you not just (plain-old synchronously) calling the subVI?
Oh, you know. "Reasons."

-
Thanks, but "ugh"
 . Guess I'll have to pass a DVR in.
. Guess I'll have to pass a DVR in.
-
If I create a DVR in a dynamically launched VI, the DVR ref goes stale when it's passed back to the caller. Anybody know why? See the attached code (LV15) for an example.
I don't want to use the ACBR node right now because I want to set some control values of the VI ref on a different diagram than the one that will run it. (I just want to pass the VI ref between calling diagrams, not all the values that'll be passed into it.)
-
OpenG has a similar function in its String library for formatting a Variant into a String, though not for splitting up a multi-variable format. Like you, they've chosen to implement a subset of the possible formatting commands.
...(assuming your data is in a cluster)...
Insofar as I'm using Format Into String to do the actual formatting, I don't have to implement any of the formatting commands. I just have to scrape the variable's data type so I can cast it from the Variant.
If my data were a cluster, the consumer would have to know its structure (data types, data names, shape of memory structure) at compile time. That would completely undo the objective of decoupling consumer from producer.

OK, so here's a very quick-and-dirty XNode to do what I think you're wanting. Don't use in any code you care lots about, though it should be ok if you always wire it up properly - i.e. errors are ignored, not handled
(Thanks, but if I can't use it in code I care about, what good is it?
 ) While this, when completely fleshed out, allows me to easily write a consumer that's correctly coupled to a particular producer at edit time, it still establishes coupling. My data producer won't always be a LV app, or even an app written by my team. I want to completely abstract the type and arrangement of the inbound data set from the consumer. It should just receive a "collection" and see that turned into a formatted string.
) While this, when completely fleshed out, allows me to easily write a consumer that's correctly coupled to a particular producer at edit time, it still establishes coupling. My data producer won't always be a LV app, or even an app written by my team. I want to completely abstract the type and arrangement of the inbound data set from the consumer. It should just receive a "collection" and see that turned into a formatted string.Fast producer, extremely flexible consumer?
Object queue (yeah LVOOP is a good choice here).
Good point: By embedding the "format this data" algorithm into the data itself (via a method on the abstract type and data in the concrete type), I can hand abstract data to the consumer and let the data format itself. In a high-level sense, that's what I've done with my Variant implementation: The abstract data set is an array of Variants (which itself could be structure as a Variant if I wanted to get even more abstract about the structure), and the formatting algorithm is abstracted into a string provided with the data and a function (Format Into String) that processes the data.
The queue is just a transport mechanism for getting the data and algorithm over to the consumer. Assuming the producer is always LV code, the queue is one of many good choices. On that note, since my producer isn't always LV code, a LV Object might limit my implementation, too. (I'd have to convert the data from another type into a LV Object, requiring knowledge of the concrete data type in the consumer.) But for LV-to-LV implementation, a queue of objects is a great way to go.
-
I didn't want bother implementing it for all simple data types, since my data's not in a Variant, but here's a first-pass example of how I got it done.
-
You're both onto what I've been working on since I posted. It's not as bad as I feared. I'll have to enforce ordered parameters, at least in the first pass, to minimize string mangling. Let me hammer on it a little more, and I'll try to upload a version that uses an array of variants for your review.
{kind=link}
Where do I sell a cRIO?
in Hardware
Posted
The standard warranty is 1 year. People expect NI's hardware to break down that fast, huh? Seems like a poor choice for an OEM, or even a process controller, if that's the case.