

Zyl
-
Posts
47 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Zyl
-
-
Hi Neil,
It seems that no it doesn't.
Is this discord server different from the LV Discord server ?

-
Hi @drjdpowell!
Thank you very much for your powerful lib !
We actually encounter a small problem with it. We do a lot of TestStand development, and therefore we create PPL for our code modules.
The fact is JSONText lvlib contains lots of VIs where there is code in Disable Structures. When a Disable Structure contains a VI (like Treatment of NaN and Inf.vi) and you build a PPL, the PPL list the VI as a dependency but doesn't embed it (whatever the flags we use).The only way to make the PPL sucessful when it calls JSONText lvlib files is to completely remove the Condition Structures.
Do you think it would be possible to release a version without 'dead code' into it?
Cyril Gambini (aka CyGa, LV Champion, CLA, CTA).
-
Hi,
Possible to get a new invite link ?
-
Hi Francois,
I was seeing the DVR more like a 'pointer' (the address in memory) on the class, not a representation of the class itself. To me, if it is really a pointer, and the variable containing the pointer is public, I should be able to access the pointer everywhere. But of course, I wouldn't be able to use what's pointed (because it is private).
This is the way I was seing this, I am maybe far away from the truth 🙂
Anyway, I wonder if it is the same behavior in C++ (or other OO language using pointers)....
For the 'interface' part of the problem, yes the lvclass is a lib. But I guess that originally, the code was designed to allow building a PPL. So I guess that's why the interface is in a LVLIB and it contains the lvclass.
-
Hi!
The class itself is private (set a s private in the lvlib), so nobody with the DVR can use what's in the class outside the functions in the LVLIB.
The control containing the reference is public. IMO, I should be able to create the control outside the lvlib.
-
Hi everybody,
I'm running into something I don't really understand. Maybe you can help me here !
I've got a LVLIB that is used as an 'Interface': it exposes public VIs which wrap around public functions of a private class (see code attached) . The class is private because I want to force the users to use the 'interface' functions.
In one of my interface VI, I create a DVR on the private class (Interface_init). The DVR is stored into a typedef (FClass_DVR.ctl) and this typedef is the 'reference' that link all the interface public functions.
In TestCode.vi (which is not part of the lvlib and illustrates the standard code that a user can create to use my driver), I can call my public interface functions and link them without any problem.
But as soon as I create an indicator on that reference (to create a state-machine-context-cluster for example), my TestCode VI breaks !
The error returned is : This VI cannot use the LabVIEW class control because of library access scope. The LabVIEW class is a private library item and can only be accessed from inside the same library or libraries contained in that library.
I understand that the class is private. But the DVR is contained into a public control. Using an In Place structure on that DVR into TestCode would not work, since the class is private. So why is the DVR control problematic at that point ? Creating it do not breaks any access protection...
Am I missing something ?
-
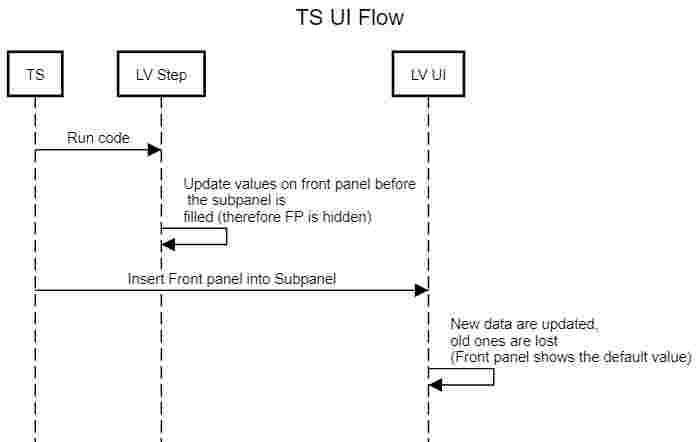
Hi !
I'm developping a TestStand UI in LabVIEW. Within this UI, I want to display the front panel of VIs that are played in a TS sequence into a subpanel.
It works fine ... except for values that were set into the 'sequence' VI (LV Step) before the front panel was loaded into the UI subpanel. If I want to 'redraw' them I have to read a property on the front panel controls into my LV step...
I want my code to be as more generic as a possible, so I dont' want to add extra code into my LV step just to ensure that it will be displayed correctly into the subpanel.
Do you have any idea how to force a front panel to redraw ENTIRELY (or at least all control/indicators visible) ? Note : I must be able to do it through VI server fron the 'outside' of the VI.
-
On 10/10/2017 at 3:39 PM, Stagg54 said:
Just curious how you manage that without committing broken code?
We do commit broken code !
And we think it is important : the trunk is the 'ongoing' state of the developement. So it is normal that the code is broken if prototype or wrong code is delivered. If we cannot build and make tests with the code, there is no chance that a stable release will be tagged.
For the rest it only relies on team management and communication. But at least wit heth locking system and identified commit, we have a chance to know what is going on or at least who did it.
-
Thank you for your advices!
I'll go with Mercurial and my Synology !
-
Hi!
Thank you for all these answers.
Hooovah: Thank you for the precision on separating compiled code / source. however for some of our customers, we still use old LV versions (2010..2013). So I guess the issues can still be a problem for these projects.
Smithd : Locking on SVN helps a lot when working on big projects (I had once more than 10 developpers working on the same project) and it prevents headackes due to the merging process in LV. Since a locked file is read-only, and with LV well set, you don't get 'modified' VIs just because you opened them. Our rule is to unlock one by one the files to modify and to commit right after any modification is made, so that it unlocks the file rapidly. Locking issues with developpers is really rare.
Neil : I plan to host the server on our Synology NAS, so everything stays 'in house'. For some of our customers it is (still) comforting to 'know' that the sources are not in the cloud. But I plan to use TortoiseHg as our client. Do you have any specific settings that you apply to your client ? To LV because you use Mercurial ?
Antoine: I've seen that too on Twitter. And it let me think that Mercurial would be a better choice than Git (mainly for the non-mergeable files and Trunk-base dev rate). But so many people rely on Git (even NI lately) instead of Mercurial. So I was thinking that there is a particular reason about it.
-
Hi !
I know that there are numerous threads about SCC, but none really helped me to answer clearly this question : I want to move from SVN to a DSCC to be able to commit even if I cannot connect to my server, which DSCC should I use between Git and Mercurial AND how should I set it ?
I use SVN for years now, and I always apply the same rules to be able to work with several developpers on the same projects :
- Files are all locked, a developper MUST unlock them to work on them
- Locked files are read-only
- LabVIEW is set to treat read-only files as locked and not to save automatic changes (old habit to avoid LV to recompile and ask to a VI for non-functionnal 'modifications')
These settings work perfectly fine for us.
Can I replicate such settings with Git / Mercurial ? Is there a point to do it ?
I have a video from Fabiola explaining how she uses Mercurial with LV. One of her LV setting is to separate compile code from source code (I guess to avoid unnecessary changes made by the compiler when opening a VI for example to be taken into account by the DSCC). I've heard that this setting is sometimes buggy and generate more problems than really helping. Is it still true with new LV versions ?
Reading some comparisons between Git and Mercurial, I would tend to use Mercurial (seems easier to use, more particularly by SVN users). But Git seems to be more popular even in the LV community. Is there any specific reason (related to LV or not) to that ?
Thank you for your help and opinions !
Cyril
-
Hi!
Maybe you can take a look to the advanced plotting API : http://advancedplotting.github.io/
-
12 minutes ago, hooovahh said:
I didn't see it linked here but I found your Idea Exchange, and luckily I already kudo'ed it. Too bad the RT Idea Exchange, along with several others, get very little attention from NI. A little while ago I was looking for a feature in RT and noticed an idea was posted for it so I kudo'ed it and talked to NI. Turns out NI already had implemented it internally and just had never released it. The feature could be documented and released 8 years ago but NI didn't know there was that much of a need for it. I pointed them to the Idea Exchange where at least one employee (close to RT support) seemed unaware that the idea was even posted, let alone that it was gaining traction.
This idea is mine and I posted back in 2014... Since then it is maked as 'In dev'.... In 2014 I was mainly developping my own RT apps, with my own framework (that is why I built a web console based on WebSocket). But now I mainly work with VeriStand. Even if my console is still usefull, it is even less easy to use it with VS. Looking at the number of Kudos on thsi idea I tought that NI would have put more eforts into it, it such a basic option...
-
4 minutes ago, smithd said:
If I'm understanding you, the console you describe is only available on pharlap systems with video hardware. cRIOs have always had to debug through something like syslog or through the serial port, and in my experience I've only ever used the serial port to monitor NI's failures, not my own.
I do agree that NI should build the syslog stuff into the product and it would be nice if there was a clear and obvious way to say 'write this output string to any connected ssh session'...but its not like the current level of functionality is a change for most cRIO users so I can't imagine this is a priority.
The 'console' is there on VxWorks and PharLaps system since ... a long time (I would say since the first release of LV RT, but I'm not 100% sure). You can see it indeed with video-hardware equipped targets but also on the configuration web page. So the video hardware is not necessary. Publishing string is done calling 'RT Debug String' VI.
Works fine on VxWorks and PharLap cRIOs, and has absolutely no effect on Linux RT cRIOs (no error, no effect, seems to be no op when 'Write to monitor' is selected). When you are migrating code from 1 platform to another, you expect keeping the same behaviour (tracing access in this case).
-
17 hours ago, rolfk said:
Well as far as the Syslog functionality itself is concerned, we simply make use of the NI System Engineering provided library that you can download through VIPM. It is a pure LabVIEW VI library using the UDP functions and that should work on all systems.
As to having a system console on Linux there are many ways for that which Linux comes actually with, so I'm not sure why it couldn't be done. The problem under Linux is not that there are none, but rather that there are so many different solutions that NI maybe decided to not use any specific one, as Unix users can be pretty particular what they want to use and easily find everything else simply useless.
I perfectly understand that there are many options to trace that comes with Linux. But I don't think that NI not picking one solution is a good idea. When you use for years the RT targets and get use to use the console to debug, when you switch to Linux RT you've got nothing anymore... or at least nothing immediately operational... All previous code routing messages to the console work without error, but actually do nothing, and you keep searching for the 'console'. When you do that in conjonction with 'linux' keyword, you just fall onto posts saying that the console is now on ... the serial port !
So I agree with you that Linux RT provides a lot of possibilities but most of the people using RT targets are not Unix-fan-professionnals... A clear position from NI saying that 'RT console' VIs should be changed to 'Syslog' VIs or even better, directly provide the syslog functionnality onto Linux RT targets when you use this VI would have been clever... (my 2 cents...)
-
Hi Rolf,
I definitely should look deeper at Syslog. I don't like the 'file' option because it doesn't tell me 'immediately' what is going on in the target. And most of the targets I have are equipped with a tiny HDD (mostly 9063) so the file size monitoring would be 'critical'.
I'm pretty sure it can work with VeriStand, but I must ensure that this solution can work on other supported targets (I've got PharLap and Windows targets as well). And again, I've got to design a specific (but reusable) monitoring thread in each custom device that may be played on the targets. Compared to the console (very simple and enough for fast debug) that was native on the other targets, IMO the lack of this tool on Linux RT targets complicates things.
Do you have a syslog viewer app to recommend ? Also a specific syslog LV lib that can be used ?
Thanks !
-
Syslog is good point! I'll try that in future devs.
But I guess that it will again a 'pain' to have this working with VeriStand...
-
Thank you for your answer. Yes indeed, the debug is difficult in the case you're using VeriStand : you have no way to get the RT VI FP when it runs on the target. File is an idea but you can only read it when th execution is done, not 'live'.
In MAX you have the console option, yes. But it only enables sending strings on the serial port.
-
 1
1
-
-
Hi everybody,
Currently working on VeriStand custom devices, I'm facing a 'huge' problem when debugging the code I make for the Linux RT Target. The console is not availbale on such targets, and I do not want to fall back to the serial port and Hyperterminal-like programs (damn we are in the 21st century !!
 )...
)...
Several years ago (2014 if I remember well) I posted an request on the Idea Exchange forum on NI's website to get back the console on Linux targets. NI agreed with the idea and it is 'in development' since then. Seems to be so hard to do that it takes years to have this simple feature back to life.
On my side I developped a web-based console : HTML page displaying strings received through a WebSocket link. Pretty easy and fast, but the integration effort (start server, close server, handle push requests, ...)must be done for each single code I create for such targets.
Do you have any good tricks to debug your code running on a Linux target ?
-
Hi InfiniteNothing,
I think Taylorh140 pointed the right tool. Correlation is exactly what you need since it returns the a 'resemblance' ration between X and Y. You may have to slide X array onto Y and remeber where is the highest value from the correlation function. It should give you the index on where to align your arrays.
Using waveforms can also help, because you'll be able to modify the t0 value of one waveform to get the traces aligned on a graph.
-
Exactly, shoneill is right. The main purpose is it to give breath to the reading loop and keep some synchronisation between server and client.
-
Hi everybody,
Thank you all for advices ! I'll try to answer each questions.
Why not UDP ? Because even if I don't care missing a message because my reader is not fast enough, if I send it I expect receiving it and without any error in the bit stream.
TCP read mode I'm using is Standard (I didn't modify the STM lib). From what I see there is no chance that i'm reading 0 byte, bcause my bit stream is then unflatten to a LV type. With 0 byte read, my unflatten function would return en error.
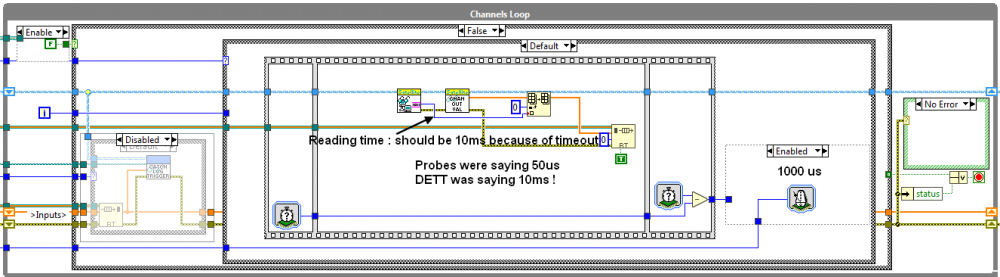
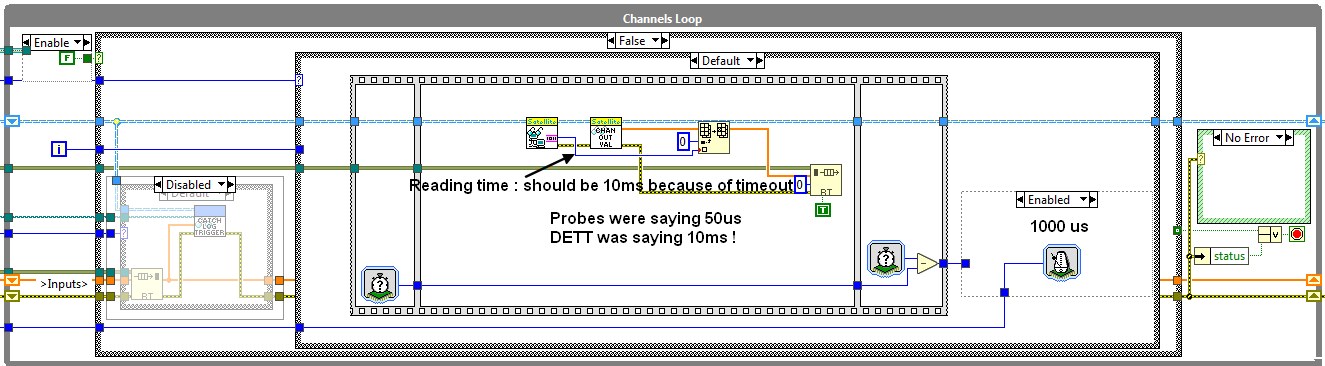
Now that I answered the main question, here is what happened ! I was using the function Ticks (us) to measure the time elapsed between 2 parts of code. It appears that when you probe the code, this function doesn't behave as it should at all !!! I moved my cRIO code from RT target to Windows host, and ran DETT to see what was going on. DETT found out that my reading was running at ... 10ms !! With probes only, probed values were saying that my loop ran at 1ms, reading took 50us. Probe + DETT : DETT was saying 10ms, probes 6000 us ; stopping DETT trace, probes were saying #50 us !
I changed the Ticks (us) to Ticks (ms) : probes were displaying 10ms !!
As may notice from the reader code, the developpement is actually a custom device used in VeriStand. It appears that if I use the same technique to measure time elapsed between 2 parts of my code and put the result in a channel, the same thing happens if everything is based on us (ticks and wait next mutiple). If one of these 2 functions is in ms then the monitoring returns the expected value.
I dont't know exactly what happens under the hood with us ticks, but it seems that there is an interaction with my code which makes them misbehave when you monitor their value in some way... Maybe a quantum effet ? :-P
-
Hi Ned,
Indeed I didn't know about the behavior of the TCP write. timeout of 0 was to ensure that I couldn't write data if the reader didn't get the previous message. I'll change that.
However on the settings I have, TCP writer runs 10x slowly than the client.
In fact the client doesn't run faster than the server because the timeout of the TCP read is quite 'big' (100ms) compared to the writing rate. 1ms is the value given to the Wait Next multiple function inside the reading loop. It just ensure that the loop doesn't run faster than 1ms. Most of the time it just should wait for the timeout or the data t be received.
So in my case the server writes every 10ms, the client should loop every 10ms also, right ? But this is not what I see! In my case the client runs at 1ms... Just like if the pause granted by the timeout was not respected, which would mean that I always data in the receiving buffer. But my server writes it 10x slower than the max read time...
-
Hi,
I already tried replacing the loop, it doesn't help at all.
From what I see, it is like the server was writing as fast as possible (but the loop monitoring says that it is really looping at 10ms) and that the read buffer was always filled with something... So the read loop is never respecting the timeout because it always have somthing to read... Is there a way to see the nb of elements in the buffer s ?


LabVIEW Discord server
in LAVA Lounge
Posted
OK so there is no 'LAVA specific' Discord server, right ?
The invitation on top is the LV Discord, which is already in my list of Discord servers.