Hello everyone. First, I want to say a long overdue thank you! The resources, eavesdropped advice, and answers I’ve found here over the past 11 years have been immensely helpful. It’s about time for me to stop lurking and join in.
You will be shocked, shocked, to hear that I have had some big problems with the LabVIEW IDE and especially the App Builder for years. I’m about to rewrite a framework I developed originally to facilitate building distributed data-collection and control systems in the cRIO context (which implies that the code must be written and synchronized across FPGA, RT, and PC targets simultaneously.)
I’m facing some architectural decisions and I’d like your thoughts.
I’ll describe the existing architecture, then the kind of problems I consistently contend with, then some proposed approaches for the new framework. Sorry, this is long, but I’ve condensed as much as I’m comfortable. (The post was originally like 3 times this length.) I’m more than happy to provide extra detail on anything you’d like.
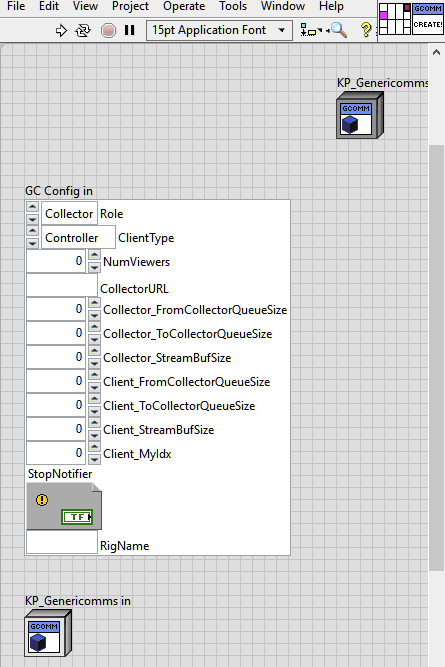
Here’s the (simplified for clarity) architecture and style of the original framework.
With few exceptions, all functionality that needs to exist on multiple platforms is written in a LV language subset that is supported on all the necessary platforms. Practically speaking, this means that for a unit of functionality or definition of static state needed on (for example) FPGA, RT, and PC platforms, I write a VI that can compile on FPGA and use it directly in the RT and PC code as well.
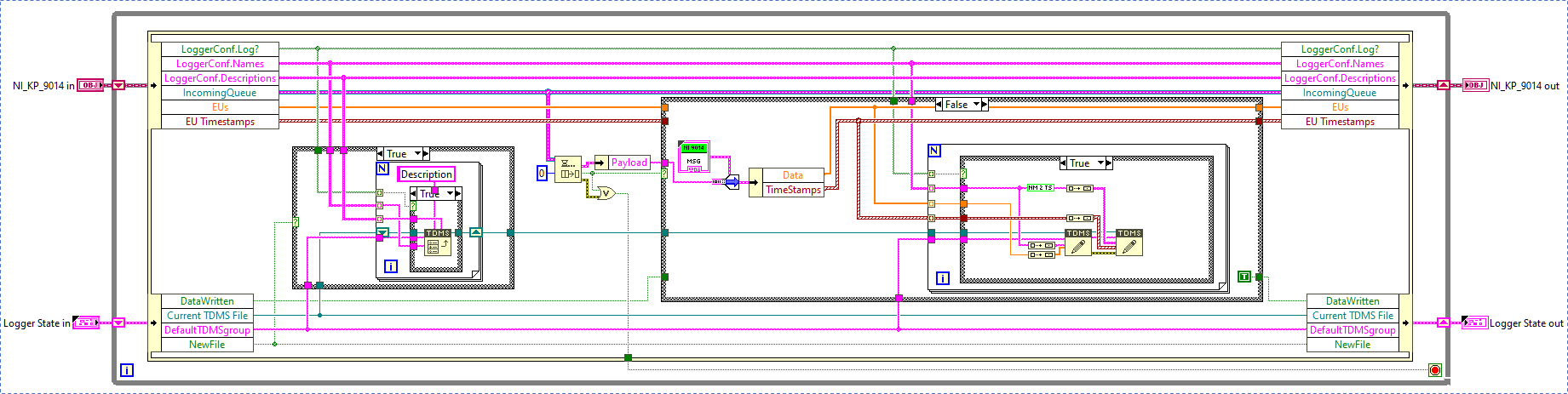
This shared-code approach is used mostly for static system definition and for lower-level communication protocol definitions and implementations. The FPGA code, for instance, instantiates class objects representing physical hardware modules connected to the FPGA and/or software compute modules running on the FPGA. The VI instantiating these module objects can then be run as-is in the RT or PC context, ensuring that static initialization is identical on all platforms. The definition of and serialization code for message formats for these classes is written similarly.
All code is written within a class hierarchy. Inheritance is used sparingly, shallowly, and exclusively (I think) for behavioral—rather than data—inheritance. Composition, on the other hand, is extensively used. My first OO exposure was in a couple of years of Java development, so I was naturally biased towards the notion that “everything is a class.” A system is a “rig” class object which contains “chassis” class objects which contain “module” class objects etc.. “rig”, “chassis”, and “module” classes are written essentially abstract, and are always instantiated as system-specific concrete children. (If interfaces had existed when I first coded this, I would of course have gone that route instead.)
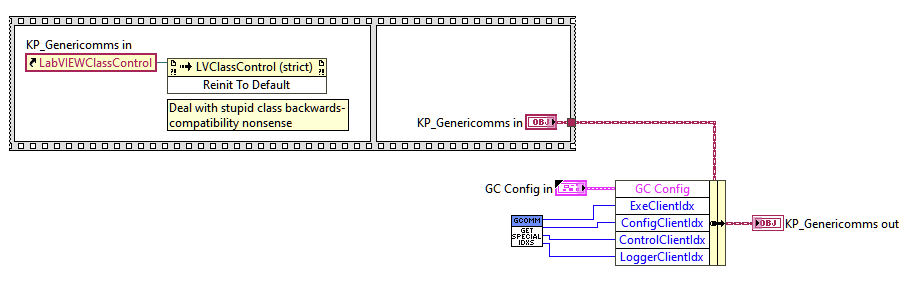
There’s another category of class that functions more as a singleton bucket of generic functionality that gets initialized once and then provides some kind of service. The generic communications infrastructure is written that way. I happily stick identical copies of this kind of object, once initialized, all over the place as a private data member within lots of other objects. That way I can have access to all the functionality and state of the singleton object, almost as if it were a parent class, without the craziness of actually implementing its functionality further up the inheritance tree.
Classes are used across platforms, so they necessarily include code that’s compatible with only one platform. Since class libraries are loaded monolithically, this code gets loaded on all platforms, so I have to guard (or automatically “comment out”) platform-specific code using conditional structures.
I get around the class-locking problem with a bit of source code management trickery. The code lives in SVN in a single filesystem hierarchy. It includes a separate project for each target type with the code loaded only under that target. Locally I check out a separate clone of the source for each target type and program/build apps for that target only in that clone. Therefore if I’m programming for FPGA, RT, and PC then I’ll end up with three separate local copies of the whole codeset, and I use SVN to keep them synchronized. Ah, and of course all code is set to use the compiled object cache, which I generally clear (perhaps out of superstition) when I change target context.
Here are the kinds of random showstopper problems I continue running into:
Random VI corruption, sometimes bad enough to crash LabVIEW at project/class load.
Apparent persistence of previous dependencies, even when no dependencies still exist in the current (visible) code.
Unloading project doesn’t unload project contents (which isn’t a huge problem per se but indicates unaddressed latent corruption)
App builder magically stops building, especially for RT.
App builder successfully builds but compiled app fails to run, either on RT or PC.
Interestingly, I’ve had the least problems with FPGA…that generally just works (meaning that when I have a compile problem, the issue is always a bug in my code that the compiler found.)
I’ve gradually gotten better at troubleshooting and fixing these problems, but until NI squashes more issues I need to adopt an approach that avoids them better.
Over the years it has seemed like these problems have been somehow caused by constantly loading classes and codesets in different target contexts (or in 64-bit vs. 32-bit LabVIEW). I’ve drawn that conclusion partly because if I stay in a single target context, things seem to be quite stable. So my working theory is that there's some fundamental problem with using classes containing cross-target code on multiple targets.
As an aside, for most of the past year I haven’t been doing any FPGA programming, yet just changing back-and-forth from PC to RT is problematic. (In fact my sense is that most of the issues come from the RT tooling in LV, the FPGA stuff has always been quite solid for me. This is only my impression!). When working with just PC and RT I am not using different SVN clones as described before, I’m only using separate projects for the different targets…so the VI paths from the IDE’s perspective remain the same.
But maybe there’s some other issue I haven’t found. I’ve played around with, for example, whether to keep typedefs within classes, and when to use strict vs. non-strict typdefs. I’m also painfully aware of the mutation history in classes, and since I’m not developing reusable libraries for distribution there’s no downside to blowing away the mutation history, so I do that fairly often. But maybe not often enough? In theory none of this should matter…yet apparently it does. I'd appreciate any guidance on anything else that might be "dangerous" given the description of my workflow.
Potential new approaches:
I’m OK with upgrading to the current LabVIEW version. Recently I ran into the “opening a single VI crashes LabVIEW” issue and was able to fix it by opening the VI in LV2022 and saving for LV2021. (I hope this is evidence of increased prioritization of stability in LV development at NI...)
The elephant-gun potential new approach would be to dispense altogether with classes and instead fake some of their functionality with typedefs and auto-populating folders. I hate this idea, but it would limit the number of VIs that get loaded on multiple targets and simplify internal namespace considerations within the LabVIEW IDE (not to mention avoiding all of the logic around class member attributes, protections, etc.)
Another approach that has significant unrelated appeal for me is to rebuild using interfaces instead of inheritance. In fact I just watched AQ’s 2022 NI Connect talk on interfaces where he explicitly suggests replacing abstract classes with interfaces. So I’d like to do that anyway, but I really don’t want to invest in that approach yet still face instability because I’m using classes in different target contexts…assuming that’s actually the root of my problems.
Thanks for listening. Any advice appreciated.
--kej



 Hello everyone. First, I want to say a long overdue thank you! The resources, eavesdropped advice, and answers I’ve found here over the past 11 years have been immensely helpful. It’s about time for me to stop lurking and join in. You will be shocked, shocked, to hear that I have had some big problems with the LabVIEW IDE and especially the App Builder for years. I’m about to rewrite a framework I developed originally to facilitate building distributed data-collection and control systems in the cRIO context (which implies that the code must be written and synchronized across FPGA, RT, and PC targets simultaneously.) I’m facing some architectural decisions and I’d like your thoughts. I’ll describe the existing architecture, then the kind of problems I consistently contend with, then some proposed approaches for the new framework. Sorry, this is long, but I’ve condensed as much as I’m comfortable. (The post was originally like 3 times this length.) I’m more than happy to provide extra detail on anything you’d like. Here’s the (simplified for clarity) architecture and style of the original framework. With few exceptions, all functionality that needs to exist on multiple platforms is written in a LV language subset that is supported on all the necessary platforms. Practically speaking, this means that for a unit of functionality or definition of static state needed on (for example) FPGA, RT, and PC platforms, I write a VI that can compile on FPGA and use it directly in the RT and PC code as well. This shared-code approach is used mostly for static system definition and for lower-level communication protocol definitions and implementations. The FPGA code, for instance, instantiates class objects representing physical hardware modules connected to the FPGA and/or software compute modules running on the FPGA. The VI instantiating these module objects can then be run as-is in the RT or PC context, ensuring that static initialization is identical on all platforms. The definition of and serialization code for message formats for these classes is written similarly. All code is written within a class hierarchy. Inheritance is used sparingly, shallowly, and exclusively (I think) for behavioral—rather than data—inheritance. Composition, on the other hand, is extensively used. My first OO exposure was in a couple of years of Java development, so I was naturally biased towards the notion that “everything is a class.” A system is a “rig” class object which contains “chassis” class objects which contain “module” class objects etc.. “rig”, “chassis”, and “module” classes are written essentially abstract, and are always instantiated as system-specific concrete children. (If interfaces had existed when I first coded this, I would of course have gone that route instead.) There’s another category of class that functions more as a singleton bucket of generic functionality that gets initialized once and then provides some kind of service. The generic communications infrastructure is written that way. I happily stick identical copies of this kind of object, once initialized, all over the place as a private data member within lots of other objects. That way I can have access to all the functionality and state of the singleton object, almost as if it were a parent class, without the craziness of actually implementing its functionality further up the inheritance tree. Classes are used across platforms, so they necessarily include code that’s compatible with only one platform. Since class libraries are loaded monolithically, this code gets loaded on all platforms, so I have to guard (or automatically “comment out”) platform-specific code using conditional structures. I get around the class-locking problem with a bit of source code management trickery. The code lives in SVN in a single filesystem hierarchy. It includes a separate project for each target type with the code loaded only under that target. Locally I check out a separate clone of the source for each target type and program/build apps for that target only in that clone. Therefore if I’m programming for FPGA, RT, and PC then I’ll end up with three separate local copies of the whole codeset, and I use SVN to keep them synchronized. Ah, and of course all code is set to use the compiled object cache, which I generally clear (perhaps out of superstition) when I change target context. Here are the kinds of random showstopper problems I continue running into: Random VI corruption, sometimes bad enough to crash LabVIEW at project/class load. Apparent persistence of previous dependencies, even when no dependencies still exist in the current (visible) code. Unloading project doesn’t unload project contents (which isn’t a huge problem per se but indicates unaddressed latent corruption) App builder magically stops building, especially for RT. App builder successfully builds but compiled app fails to run, either on RT or PC. Interestingly, I’ve had the least problems with FPGA…that generally just works (meaning that when I have a compile problem, the issue is always a bug in my code that the compiler found.) I’ve gradually gotten better at troubleshooting and fixing these problems, but until NI squashes more issues I need to adopt an approach that avoids them better. Over the years it has seemed like these problems have been somehow caused by constantly loading classes and codesets in different target contexts (or in 64-bit vs. 32-bit LabVIEW). I’ve drawn that conclusion partly because if I stay in a single target context, things seem to be quite stable. So my working theory is that there's some fundamental problem with using classes containing cross-target code on multiple targets. As an aside, for most of the past year I haven’t been doing any FPGA programming, yet just changing back-and-forth from PC to RT is problematic. (In fact my sense is that most of the issues come from the RT tooling in LV, the FPGA stuff has always been quite solid for me. This is only my impression!). When working with just PC and RT I am not using different SVN clones as described before, I’m only using separate projects for the different targets…so the VI paths from the IDE’s perspective remain the same. But maybe there’s some other issue I haven’t found. I’ve played around with, for example, whether to keep typedefs within classes, and when to use strict vs. non-strict typdefs. I’m also painfully aware of the mutation history in classes, and since I’m not developing reusable libraries for distribution there’s no downside to blowing away the mutation history, so I do that fairly often. But maybe not often enough? In theory none of this should matter…yet apparently it does. I'd appreciate any guidance on anything else that might be "dangerous" given the description of my workflow. Potential new approaches: I’m OK with upgrading to the current LabVIEW version. Recently I ran into the “opening a single VI crashes LabVIEW” issue and was able to fix it by opening the VI in LV2022 and saving for LV2021. (I hope this is evidence of increased prioritization of stability in LV development at NI...) The elephant-gun potential new approach would be to dispense altogether with classes and instead fake some of their functionality with typedefs and auto-populating folders. I hate this idea, but it would limit the number of VIs that get loaded on multiple targets and simplify internal namespace considerations within the LabVIEW IDE (not to mention avoiding all of the logic around class member attributes, protections, etc.) Another approach that has significant unrelated appeal for me is to rebuild using interfaces instead of inheritance. In fact I just watched AQ’s 2022 NI Connect talk on interfaces where he explicitly suggests replacing abstract classes with interfaces. So I’d like to do that anyway, but I really don’t want to invest in that approach yet still face instability because I’m using classes in different target contexts…assuming that’s actually the root of my problems. Thanks for listening. Any advice appreciated. --kej
Hello everyone. First, I want to say a long overdue thank you! The resources, eavesdropped advice, and answers I’ve found here over the past 11 years have been immensely helpful. It’s about time for me to stop lurking and join in. You will be shocked, shocked, to hear that I have had some big problems with the LabVIEW IDE and especially the App Builder for years. I’m about to rewrite a framework I developed originally to facilitate building distributed data-collection and control systems in the cRIO context (which implies that the code must be written and synchronized across FPGA, RT, and PC targets simultaneously.) I’m facing some architectural decisions and I’d like your thoughts. I’ll describe the existing architecture, then the kind of problems I consistently contend with, then some proposed approaches for the new framework. Sorry, this is long, but I’ve condensed as much as I’m comfortable. (The post was originally like 3 times this length.) I’m more than happy to provide extra detail on anything you’d like. Here’s the (simplified for clarity) architecture and style of the original framework. With few exceptions, all functionality that needs to exist on multiple platforms is written in a LV language subset that is supported on all the necessary platforms. Practically speaking, this means that for a unit of functionality or definition of static state needed on (for example) FPGA, RT, and PC platforms, I write a VI that can compile on FPGA and use it directly in the RT and PC code as well. This shared-code approach is used mostly for static system definition and for lower-level communication protocol definitions and implementations. The FPGA code, for instance, instantiates class objects representing physical hardware modules connected to the FPGA and/or software compute modules running on the FPGA. The VI instantiating these module objects can then be run as-is in the RT or PC context, ensuring that static initialization is identical on all platforms. The definition of and serialization code for message formats for these classes is written similarly. All code is written within a class hierarchy. Inheritance is used sparingly, shallowly, and exclusively (I think) for behavioral—rather than data—inheritance. Composition, on the other hand, is extensively used. My first OO exposure was in a couple of years of Java development, so I was naturally biased towards the notion that “everything is a class.” A system is a “rig” class object which contains “chassis” class objects which contain “module” class objects etc.. “rig”, “chassis”, and “module” classes are written essentially abstract, and are always instantiated as system-specific concrete children. (If interfaces had existed when I first coded this, I would of course have gone that route instead.) There’s another category of class that functions more as a singleton bucket of generic functionality that gets initialized once and then provides some kind of service. The generic communications infrastructure is written that way. I happily stick identical copies of this kind of object, once initialized, all over the place as a private data member within lots of other objects. That way I can have access to all the functionality and state of the singleton object, almost as if it were a parent class, without the craziness of actually implementing its functionality further up the inheritance tree. Classes are used across platforms, so they necessarily include code that’s compatible with only one platform. Since class libraries are loaded monolithically, this code gets loaded on all platforms, so I have to guard (or automatically “comment out”) platform-specific code using conditional structures. I get around the class-locking problem with a bit of source code management trickery. The code lives in SVN in a single filesystem hierarchy. It includes a separate project for each target type with the code loaded only under that target. Locally I check out a separate clone of the source for each target type and program/build apps for that target only in that clone. Therefore if I’m programming for FPGA, RT, and PC then I’ll end up with three separate local copies of the whole codeset, and I use SVN to keep them synchronized. Ah, and of course all code is set to use the compiled object cache, which I generally clear (perhaps out of superstition) when I change target context. Here are the kinds of random showstopper problems I continue running into: Random VI corruption, sometimes bad enough to crash LabVIEW at project/class load. Apparent persistence of previous dependencies, even when no dependencies still exist in the current (visible) code. Unloading project doesn’t unload project contents (which isn’t a huge problem per se but indicates unaddressed latent corruption) App builder magically stops building, especially for RT. App builder successfully builds but compiled app fails to run, either on RT or PC. Interestingly, I’ve had the least problems with FPGA…that generally just works (meaning that when I have a compile problem, the issue is always a bug in my code that the compiler found.) I’ve gradually gotten better at troubleshooting and fixing these problems, but until NI squashes more issues I need to adopt an approach that avoids them better. Over the years it has seemed like these problems have been somehow caused by constantly loading classes and codesets in different target contexts (or in 64-bit vs. 32-bit LabVIEW). I’ve drawn that conclusion partly because if I stay in a single target context, things seem to be quite stable. So my working theory is that there's some fundamental problem with using classes containing cross-target code on multiple targets. As an aside, for most of the past year I haven’t been doing any FPGA programming, yet just changing back-and-forth from PC to RT is problematic. (In fact my sense is that most of the issues come from the RT tooling in LV, the FPGA stuff has always been quite solid for me. This is only my impression!). When working with just PC and RT I am not using different SVN clones as described before, I’m only using separate projects for the different targets…so the VI paths from the IDE’s perspective remain the same. But maybe there’s some other issue I haven’t found. I’ve played around with, for example, whether to keep typedefs within classes, and when to use strict vs. non-strict typdefs. I’m also painfully aware of the mutation history in classes, and since I’m not developing reusable libraries for distribution there’s no downside to blowing away the mutation history, so I do that fairly often. But maybe not often enough? In theory none of this should matter…yet apparently it does. I'd appreciate any guidance on anything else that might be "dangerous" given the description of my workflow. Potential new approaches: I’m OK with upgrading to the current LabVIEW version. Recently I ran into the “opening a single VI crashes LabVIEW” issue and was able to fix it by opening the VI in LV2022 and saving for LV2021. (I hope this is evidence of increased prioritization of stability in LV development at NI...) The elephant-gun potential new approach would be to dispense altogether with classes and instead fake some of their functionality with typedefs and auto-populating folders. I hate this idea, but it would limit the number of VIs that get loaded on multiple targets and simplify internal namespace considerations within the LabVIEW IDE (not to mention avoiding all of the logic around class member attributes, protections, etc.) Another approach that has significant unrelated appeal for me is to rebuild using interfaces instead of inheritance. In fact I just watched AQ’s 2022 NI Connect talk on interfaces where he explicitly suggests replacing abstract classes with interfaces. So I’d like to do that anyway, but I really don’t want to invest in that approach yet still face instability because I’m using classes in different target contexts…assuming that’s actually the root of my problems. Thanks for listening. Any advice appreciated. --kej