

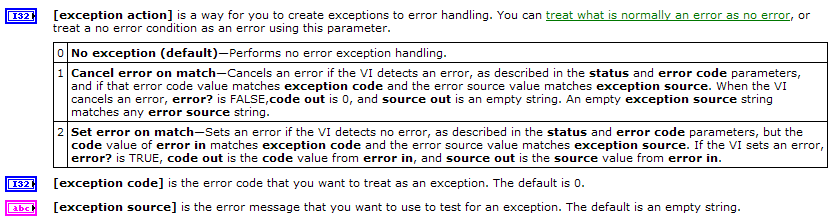
syrus
-
Posts
28 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by syrus
-
-
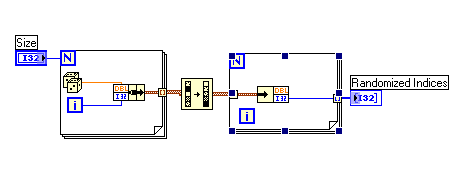
File Name: Random permutation
File Submitter: LAVA 1.0 Content
File Submitted: 02 Jul 2009
File Updated: 02 Jul 2009
File Category: General
LabVIEW Version: 8.2
File Version: 2.0.0
License Type: Creative Commons Attribution 3.0
Potentially make this file available on the VI Package Network?: Undecided
Copyright © 2006, 2007, Syrus Nemat-Nasser
All rights reserved.
Author:
Syrus Nemat-Nasser
**see readme text for email address**
Description::
This SubVI takes a positive I32 integer n as input and generates a uniformly random array of the integers from 0 to n-1 as output. It is equivalent in function to the ‘randperm’ command in MATLAB. If a non-positive value is provided, an error is raised to alert the caller.
Version History:
1.0.0:
Initial release of the code.
1.1.0:
Added input validation, error handling, and the option to use "MATLAB mode" and generate a permutation of the integers from 1 to n instead of 0 to n-1, where n is the value wired to the size input. Added a "convert to I32" before feeding the random index to the array functions to eliminate two coercion dots. Updated description to reflect these changes. Changed wiring pattern to 4-2-2-4 and changed icon to accomodate additional terminals.
2.0.0:
Added a random seed input to allow the user to optionally seed the random number generator to produce a specific random permutation. The VI now uses the Uniform White Noise PtByPt function which is not available in the LabVIEW Base package. Users who have the Base package may need to use version 1.1.0 which is still included in the distribution.
-
Another option is to go to VI Properties->Execution and select the "Clear indicators when called" option. This will set all indicators to their default values each time you run your VI.
-
Take a look at this article about Comparing Floating Point Numbers.
-
QUOTE(torekp @ Mar 27 2007, 04:34 AM)
This is a pattern classification problem of the statistical machine learning variety. If you have the ability to collect a large amount of labeled examples, and the data source is stationary, then you can apply standard regression techniques to find an optimal parametric solution (e.g. if you assume normal distributions) or an optimal non-parametric solution (e.g. using a neural network approach).
Your goal is to approximate p("good"|x) where x is an n-dimensional data vector and p("good"|x) is the probability that the data example is in class "good" given that x. In your diagram, x is a 2-dimensional vector. [in the two-class case, p("bad"|x) = 1 - p("good"|x), so it is not necessary to explicitly approximate both quantities.]
Because you have an uneven cost function, you will add an additional weighting parameter to account for the different, i.e. greater, cost of labeling "bads" as "goods". If the cost was the same in each case, you would get the Bayes optimal classification accuracy by choosing the class with the maximum posterior probability, i.e. choose "good" if p("good"|x)>p("bad"|x).
Reference: Neural Networks for Pattern Recognition by Chris Bishop (http://research.microsoft.com/%7Ecmbishop/nnpr.htm''>http://research.microsoft.com/%7Ecmbishop/nnpr.htm' target="_blank">http://research.microsoft.com/%7Ecmbishop/nnpr.htm)
-
I like Tomi's list. I do something else too--I use a different mouse and keyboard at work and at home. At work, I use a Microsoft 5-button optical mouse, and at home I use an earlier version of the Logitech 5-button optical mouse. I use a Dell quietkey at work, but use a Microsoft Natural Keyboard (the original MS ergonomic keyboard--not the "elite" which sucks). I find that drinking tea and water while working helps with the hourly breaks. I go to the restroom every hour by afternoon if I'm drinking enough fluids.
QUOTE(Tomi Maila @ Mar 15 2007, 09:34 AM)
This is my top 10 list in the order of importance- Excercise enough (sports, walking, ...)
- Avoid stress :thumbup:
- If you feel too much pain, stop working, it will only get worse
- Think more, you need to code less (or at least you get more results)
- Study more, you learn to code more effectively
- Choose an ergonomic office chair that fits to you well
- Keep short breaks at least every hour
- Adjust the table height so that you don't have to keep your hands at tension
- Get a docking station, external keyboard and external monitor if you are using a laptop
- Use a good laser mouse, I prefer Logitech MX Revolution
- Excercise enough (sports, walking, ...)
-
I started using 8.0.x sometime after it was available but before the 8.0.1 bugfix release. I have found 8.2 to be superior to 8.0.1. It starts up much faster for one thing, and I think a few annoyances were fixed. Two new features in 8.2 are LVOOP, which I have not yet used, and an import shared library wizard which I have used successfully (with some pain) to call functions from a proprietary C++ library under development at my company.
-
Assuming you are using the Windows version of LabVIEW:
Starting in LabVIEW 8.0, executables are built from a LabVIEW project. One must create a LabVIEW project that contains the top-level VI for the executable. Additional data files may be added to the project (even if they are not LabVIEW files). At the bottom of the Project->My Computer tree is a "Build Specifications" branch. Right click on "Build Specifications" and select New->Application (EXE) or New->Installer.
As stated previously, you must have one of the Pro versions of LabVIEW to build executables. If you build an Installer, it will include the LabVIEW runtime engine.
-
Many thanks for the reply. Indeed my 1D array elements are all of the same length but I understand your point. I need to read more than one element in the queue without removing them. Is there a simple way to do it apart unqueue and queue these elements back again.
In Jim's recent book, LabVIEW for Everyone (http://labviewforeveryone.com/), he provides an example of how to build your own queue using a functional global SubVI. This might be the best way to do what you want, but it's not necessarily simple unless you have experience with functional, i.e. LV2, globals. As I recall, the example is given in the appendix on graphical object-oriented programming (GOOP).
-
Pop-up on your control and choose Customize.
Use the drop down to change change the control from a control to a typdef.
Save it.
replace all of the old occurnces with the typdef.
HINT:
After you create and save the edit it and add a new field. Save it.
This will break yur code every where the typdef is wired to a non-typdef'd control. Fix all the broken wires by replace the non-typedef with the typedef.
When you are done you will have found all of the places that need to be fixed (well maybe not all).

Ben
In addition to this, if you only bundle and unbundle "by name" in your VIs, you will not break them unless you remove something from the cluster in the typedef.
-
Take a look at the General Error Handler.vi. In and among its inputs is the ability to filter the wire value but still output the formatted string of the error so you can dump it to a log file.
Yep. I have to agree that using the built-in exception handling of the General Error Handler.vi is the way to go. My little VI is not needed.
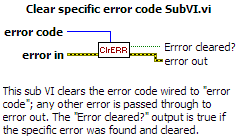
-
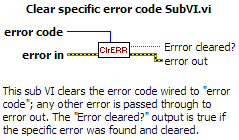
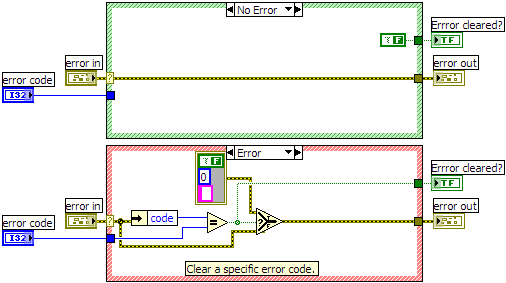
I have a small utility VI that allows me to trap a particular error and handle it silently. Here's a screenshot and the VI compiled for LabVIEW 8.0:
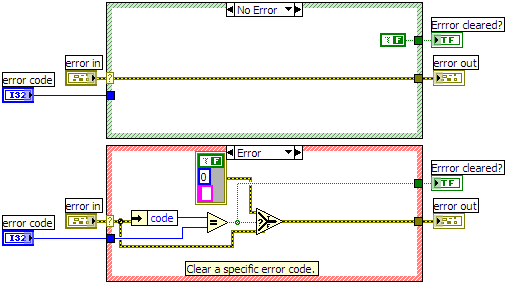
-
In LabVIEW 8.20 on Windows, file pointers are 64-bit integers and files can be larger than 2GB. However, datalog files are limited to 2GB according to the release notes. Funny thing though: when I accidentally write a datalog file past the 2GB limit, no error is raised. The error occurs only when I try to read the file. If I read sequentially and reach the 2GB limit, an EOF error occurs. (I'm not going to post an example file for the obvious reason that posts over 2GB are not supported on LAVA. :laugh: ) I've been informed that R&D is aware of this issue, but that it is a low priority because not many people create large datalog files.
-
I see...
You must have a lot of memory on that computer...

Yep. I've got 4GB on my workstation and have access to a server with 24GB of RAM. Unfortunately, LabVIEW is limited to just under 2GB per instance so I play some games with ramdisks and file I/O when dealing with large data sets. I'm really looking forward to the 64-bit version of LabVIEW.

-
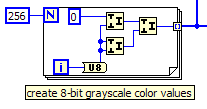
Now I'm curious. In my 10 years or so of technical computing, I'm having trouble thinking of many times where I've come across a need for randomizing an array. A LabVIEW implementation of Boggle that I did on a long flight, and a card shuffling exercise in college come to mind, and obviously those don't need to be really fast.
So, just out of curiosity, what type of real applications require such fast and efficient randomization?
I have implemented a number of artificial neural network models in LabVIEW. While performing stochastic optimization, i.e. "training the neural networks", I will often process the "training set" many times. This data set consists of thousands to hundreds of thousands of input output pairs in which both the input and the output are vectors of floating point numbers. I include the option to process the training set in a random order each time it is used. To do this random processing, I implemented the random permutation in LabVIEW.
-
I wish I could find that App Note...
My understanding was that Labview will evaluate both paths. It just happens that for simple things like incrementing vs. not incrementing, performing an unecessary addition is faster than the overhead associated with using a case structure to not performing the operation.
In our VI, LabVIEW is modifying the whole array, not performing an addition on a scalar. And, since both branches must be preserved, LabVIEW will produce an extra copy of the array.
-
Syrus,
There are a couple ways that it seems that you can squeeze out a few more microseconds. I ran some benchmarks for size=1000, and on my 2.4GHz P4, I was able to trim the execution time from ~0.76ms to ~0.70ms.
First, get rid of the coercion dots by converting those two coerced wires to dbl.
Second, I read somewhere (probably one of the Labview App notes, which I can no longer find), that case structures have a fair amount of overhead associated with them, so for simple things like your Matlab switch, it's better to use a Selector node.
Gary
Hi Gary,
When I decided to add the MATLAB switch, I was no longer woried about a few microseconds--users who are that pressed for performance can extract the portion of the diagram they need and remove all case structures. Regarding coercion dots, I don't believe replacing the automatic coercion with an explicit coercion should make a difference in performance (although I'm not disputing that it does in your version of LabVIEW).
Regarding the selector instead of case structure, I would like to know whether the selector computes all inputs before evaluation or if it smartly evaluates the condition first. It may indeed be smart, but it is not obvious from a dataflow point-of-view. I therefore would err on the side of code clarity to use the case structure instead of the selector.
When I decided to add error handling and input validation, it was because I realized that I had performed premature optimization.
-
Admin Note: For the next release, perhaps you can include the older labview versions in the zip file. Another option is to develop in LV7.0 or 7.1 and release it in that version only. People can then upconvert. Just some suggestions to streamline the process.
Thanks Michael. I'll improve my process as you suggest for the 1.0.1 release. --Syrus
Edit: I have uploaded a 1.1.0 release in response to the discussion today. I updated the minor version number because this is not a bugfix release. The following changes were made:
1.1.0:
Added input validation, error handling, and the option to use "MATLAB mode" and generate a permutation of the integers from 1 to n instead of 0 to n-1, where n is the value wired to the size input. Added a "convert to I32" before feeding the random index to the array functions to eliminate two coercion dots. Updated description to reflect these changes. Changed wiring pattern to 4-2-2-4 and changed icon to accomodate additional terminals.
-
Hmmm... Any chance you could post your VI saved as 7.1?
Thanks,
Gary
Hi again Gary,
I can save as far back as 7.0 using "Save for previous..." under 7.1.1. I'm attaching all three versions of the 1.0.0 release to this message.
Download File:post-3106-1161639025.zipDownload File:post-3106-1161639046.zipDownload File:post-3106-1161639058.zip
-
Hmmm... Any chance you could post your VI saved as 7.1?
Thanks,
Gary
I'll try. I do still have 8.0.1 and 7.1 running on my primary workstation. I'll have to get back to this later--I've got a few errands and meetings coming up this afternoon. --Syrus
-
Forgive me if I'm being dense here, but how is that different from doing this?
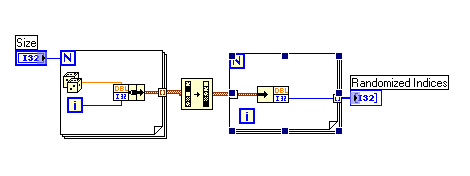
Your solution requires at least three times as much allocated memory. It might also be slower (which one might or might not care about). I've learned to optimize for memory allocation in LabVIEW to get maximum performance out of my applications.
-
Instead of "assumed to be positive I32", why not use an unsigned 32-bit? Then you don't have to worry about someone passing a negative.
In my applications, this function is used to generate an array of indices that, in turn, are used to randomize the order in which data is processed from another array. I believe that LabVIEW coerces array indices to I32, so I want to use I32 for the output array. A question then is whether to use U32 for the input which could theoretically cause a problem if the user decides to input a size larger than 2147483647. The answer to that question is no because a value of 2147483647 generates a "Memory Full" error in LabVIEW, so this issue is irrelevant until the 64-bit version of LabVIEW is released.
 I think that the randperm function in MATLAB generates numbers between 1 and N.
I think that the randperm function in MATLAB generates numbers between 1 and N.Maybe add an option to select if the sequence is zero indexed or not?
/J
Yep. MATLAB does generate numbers between 1 and N because MATLAB indexes arrays starting with 1 instead of 0. I can add a recommended boolean input to switch the indexing to 1...N.
Another non-trivial improvement could be to make the VI polymorphic allowing any compatible integer type to be used for both input and output (I32, I64, U32, U64, I8, U16, etc.), but this VI is simple enough that the end user can modify the types and the range to match their application.
In my opinion, this VI is most useful to demonstrate an efficient way to randomize an array in-place in LabVIEW, a pattern that comes up once in a while.
I'm going to wait a while to allow further discussion before I incorporate changes.
-
-
Thanks! I agree about the "\" before the file name. I added that, but I won't post another version here quite yet so as not to clutter the site with too many revisions.
Another note: Although the internal code should all be platform independent, the logic assumes a Windows path syntax...
Regards,
Dave
Hi David,
This VI will be very useful to me. I added the backslash and also added simple error in and error out terminals. Edited version is attached. --Syrus
Download File:post-3106-1160086183.vi Edit: Requires LV 8.2
-
Hi folks. I solved this problem a few days ago, forgetting to search here first for the answer. I used the builtin function "Join numbers".
[Discuss] SAPI TTS(Text To Speach) Library
in Code Repository (Certified)
Posted
Name: SAPI TTS(Text To Speach) Library
Submitter: LAVA 1.0 Content
Submitted: 04 Jul 2009
Category: General
LabVIEW Version: 8.2
Version: 1.1.0
License Type: Creative Commons Attribution 3.0
Potentially make this available on the VI Package Network?: Undecided
Copyright © 2007, Syrus Nemat-Nasser
All rights reserved.
Author:
Syrus Nemat-Nasser
--see readme file for contact information
Description::
A simple set of Sub-VIs to efficiently implement text-to-speech in LabVIEW applications on Windows using the Microsoft Speech API (SAPI).
Version History:
1.1.0:
Updated SAPI Speak SubVI: SAPI Speak is now polymorphic, accepting either a text string or a file path (which should point to a text file containing text to speak). In addition, SAPI Speak now handles speech flags correctly thanks to code contributed by LAVA user 'jdunham' included in this release.
1.0.0:
Initial release.
Click here to download this file