

ned
-
Posts
571 -
Joined
-
Last visited
-
Days Won
14
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ned
-
-
Just after posting this I started a different approach: I moved the "Sweep" logic out of the Measure hierarchy and added a "Measure" class input and output to each of the Sweep functions. I'll leave the Sweep Collection object as a child of Measure, and it will still contain an array of Sweep objects. When I need to set a parameter through the one of the Sweep objects, I'll pass in the Sweep Collection object. I think this will be cleaner. Still curious to hear how others have approached a similar situation.
-
I'm working on an application to test a device. There are at the the moment three modes: 1) run the device; 2) run the device and take measurements; 3) run the device, adjust a parameter through a range of values, and take a measurement at each point. This seemed like an ideal case for LVOOP, so I set up a parent class for "Run," a child class for "Measure," and a child of that for "Sweep." The sweep class has common logic for incrementing a value through a range, and has a child class for each parameter that contains the logic for setting that specific value. This all works great and I'm loving LVOOP.
Now the engineer using the tool wants to sweep more than one parameter at a time, taking a measurement at every possible combination, and I'm trying to figure out a way to do this with minimal changes. My "Run" and "Measure" objects store most of the parameters. I started creating a new child of "Sweep" called "Sweep Collection" that contains an array of Sweep objects, but then I realized that each individual Sweep object would contain its own copy of all the data stored in the parent Run and Measure objects, which won't work - all the sweep objects need to share that same data because the parameters that are being changed are part of that data.
One solution is to put the common data into a singleton class or functional global. Anyone have other suggestions?
-
I haven't looked closely at the flattened representation of a variant. One major advantage of a variant over a flattened string is that a variant doesn't need to be flat - it can efficiently wrap standard LabVIEW data without making a full copy. However, as soon as you flatten that variant to a string to send over the network, you lose that advantage. The flattened string representation of LabVIEW data is well-documented and has not changed (except to add new data types) in quite a while, if I'm not mistaken. Have you considered using a flattened string instead?
-
Start with NI's article "How Many Threads Does LabVIEW Allocate?"
Also see the LabVIEW help for "Multitasking, Multithreading, and Multiprocessing."
If you divide your code across execution systems instead of leaving them all at "Same as Caller" you should see the work distributed across more threads, and probably better performance and higher CPU use.
-
I believe the web service import tool still does not support WCF. A search on the NI forums turns up some alternate approaches, for example these threads:
http://forums.ni.com/t5/LabVIEW/LabVIEW-and-WCF-web-service-Why-so-difficult/td-p/1731812
http://forums.ni.com/t5/LabVIEW/WCF-web-services-with-LabVIEW/td-p/1605832
-
But I'm still kind of disappointed that I didn't discover something that hadn't been released.
Off-topic, but... why?
Let's say you do find something that hasn't been released: first, it's not like you're the first to know about it, since some developer explicitly put it there. Second, if I were your customer and found that you used an unreleased feature in code you supplied, I'd ask you to rewrite it using supported features, and then wouldn't hire you again. If you distributed a toolkit based on it I might look, but I wouldn't use it in code for my customers for the same reasons.
I'm not trying to discourage exploration - I've done my share of it even for work reasons when there was no other choice (and the worst part is, it was software from within the same company, we chose to use a machine that another group developed and then their software didn't fully support what we needed) - but keep in mind that unreleased features are not like finding buried treasure.
-
As a preface, I did a minor in CS, so I've taken a reasonable number of Computer Science classes at the undergraduate college level. Not surprisingly, none of them were taught in LabVIEW, and some concepts do not translate easily into LabVIEW, but I do find that the CS background helps me identify situations where there's a standard pattern or algorithm that can solve a problem, and also allows me a basic understanding of what LabVIEW is doing "behind the scenes."
The Algorithms class looks like a very good start. A basic understanding of Statistics is generally useful for anyone dealing with data in a lab, although not specifically for computer science. I'm going to guess that the Automata class is more advanced and you may want to finish the Algorithms first.
For me at least, there's no substitute for writing code - I won't properly understand an algorithm until I've implemented it myself. However, in my opinion (and I welcome other opinions on this), some patterns are difficult to implement in LabVIEW without first doing them in a text-based language, simply because most courses assume that you'll be using a text-based language. In addition, learning at least one traditional text-based language (I'm thinking C or Java here) is worth your time - using multiple languages makes it easier to think about algorithms in a generic sense rather than an implementation in one specific language. The classic C text, "The C Programming Language" by Kernighan and Ritchie, is a good way to get started with C and if you have the NI Developer Suite then you already have access to a C compiler.
-
If you only have one top-level VI, aren't loading VIs dynamically, and have a simple folder structure within your project (for example, virtual folders matching exactly what is on disk), it might be simplest to save the top-level VI to a new location. Choose the option to save the entire hierarchy, then recreate the project.
-
From a message posted by Aristos Queue a month or so ago:
"Replicating VITs was a practice that should have largely stopped in LV 8.0 unless you are scripting new VIs as part of an actual "create me a brand new VI in the editor" tool. There are some edge cases when you're actually scripting new controls, but most UIs don't use that approach because it only works in the full dev environment, not the runtime environment. So for UI work, stick with reentrant clones."
-
My apologies for misleading you, I suggested the standard approach for TCP and missed the note in the documentation that makes it unsuitable for UDP.
If you post your circular buffer approach I'm sure someone will be happy to suggest how it can be made more efficient.
-
Reading first byte to determine the number of bytes to read, then doing a second read of that number of bytes is the correct way to do this. Could you check what error you're receiving, and attach the code that demonstrates it? There's no reason that should return an error, and code 113 does not match your description of it.
-
Am I missing something here or could the number of files in the target directory really be such a performance problem. Any recommendations?
That's likely the problem. Filesystems in general do not deal well with huge numbers of small files. Also, there will be a substantial amount of overhead transferring that number of files over ftp since each file is a separate transaction.
-
I'm not about to try to set this up just to test it, but I'm pretty sure you can send messages between VIs using this DLL. Messages are sent to specific windows; in the image you posted, you can see that it gets the title of the VI window, which in turn is used to retrieve the window handle. The comments in the DLL code suggest that it can handle multiple queues, one for each window. So, it should work.
-
I think it would help if you share your code. It sounds like you have not taken the time to find out where the problem occurs and are instead trying random solutions such as inserting Clear Errors in the hopes that it will work, without knowing why. This is not a good way to go about programming. When you run your program in the development environment, do you ever see this problem? If so, you should be able to determine where the problem is. If your development machine does not have the hardware necessary to test the code, try building an executable with debugging enabled and connect to it with the debugger remotely. Instructions for this are in the LabVIEW help.
-
Why do you have to use ctrl-alt-del to shut down your program? That to me says you have an error in your programming. Perhaps you could be more specific about the failure. Do you have an infinite timeout somewhere? Consider replacing it with a fixed length of time, and if it times out, retry a certain number of times before giving up.
-
You won't need to click twice to change the value if you position the ring on mouse move rather than mouse click. You can track the mouse and re-position the ring only when the cell changes. If the ring appears on a cell on "mouse over", it will give the user a hint that he can click on it to select a value from a list.
Thanks for the idea. I posted my approach to this several months back at http://forums.ni.com/t5/LabVIEW/array-of-cluster/m-p/1822451#M625032. With that code I can simply change the "Mouse Down" event to "Mouse Move" and get the behavior you suggest. I'm not sure I like the visual results of doing that, and I'm no longer working on the project for which I first wrote that code so no need to improve it now, but perhaps I'll take another look at it the next time I need a similar interface.
-
Can you attach a VI that demonstrates what you're doing, and not just the control?
-
Tick Count has always been in milliseconds. Get Date/Time in Seconds returns fractional seconds to greater precision than milliseconds, perhaps you're thinking of that.
-
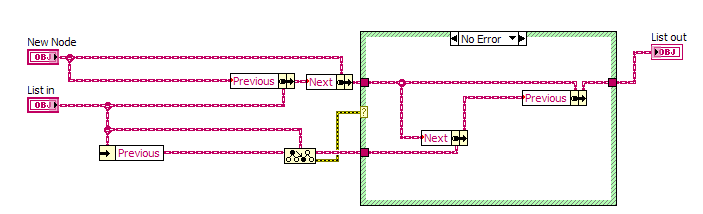
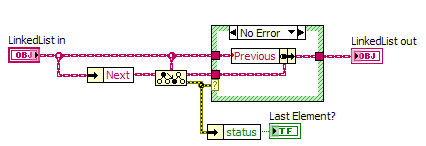
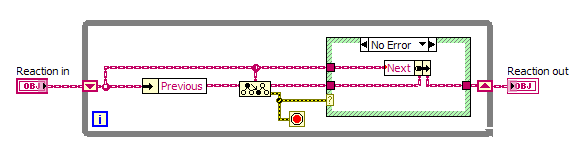
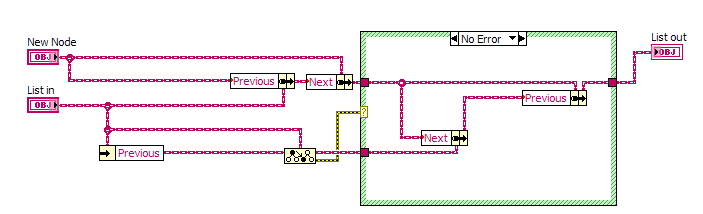
Here you go. I pulled pieces from existing code that used a linked list with limited functionality, expanded it and removed the application-specific data (some items are still marked "Reaction" because I was tracking a list of chemical reactions that needed to be executed in a particular order, defined at run-time by reading from a file). There must be a more efficient way to do some of these operations, because they're incredibly slow. The "Test Linked List" VI generates 10 random numbers and then inserts them into the list in ascending order by iterating through the list until a greater value is found, then inserts the new value at that point. After generating the list, it iterates through the list and appends each number to an array. This is the part that's inexplicably slow - so slow you can see it adding about one number per second on a fast machine with plenty of RAM. I'd love to know how to fix that, just for my curiousity as I don't actually need this functionality in any application I'm working on right now. (LabVIEW 2011)
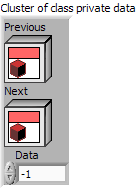
The LinkedList class (Prev and Next are of type LinkedParent from which LinkedList inherits)
Inserting a new node into the list
Advancing through the list
"Rewinding" the list
-
I seem to remember seeing something this in LabVIEW 2009, turned out there was a VI buried in the hierarchy that included a huge constant array of doubles, and for some reason that caused problems when searching for text.
-
If you used the Shared Library Import tool to generate the wrappers, I believe there's an "update" option.
-
Already reported, with workaround, on the NI forums: http://forums.ni.com/t5/LabVIEW/paint-bucket-displayed/m-p/1878283
-
You need a DVR tree when you need to do bidirectional operations. That is pretty common when you are modeling a real-world system like Marie is. Think of a family tree. Family Tree class contains all the family members. Essentially you traverse the Family tree until you find the family member you are interested. Then you can query who that member's parents, uncles, children are very quickly. This rocks if you need efficent code on a system that you understand well.
I understand the data structures, I've done the standard data structures in Java and C. What I don't understand is why you need the DVR. In a linked list you'd have a "previous" and "next" object, in a tree it's a bunch of "child" objects and a "parent" object. What is the advantage to using a DVR instead of embedding the objects directly? I implemented (but don't have the code for right now) a linked list this way and it worked fine, although I found that the only way I could get back to the front of the list was to have a "rewind" method that looped until it reached the start; does the DVR somehow solve this problem?
-
Slightly off the original topic, but is there an advantage to using a DVR to store the child nodes, instead of storing the child nodes directly (using LVObject or some other common parent and then downcasting)?
Command design pattern and composition of functions
in Object-Oriented Programming
Posted
Is there any way you could illustrate this or share some code? After reading it 4 times I still cannot understand what you are doing. You mention an array of commands, a commands class cluster, a queue, and something about VI server. I cannot picture how it all fits together. Are "init," "execute," and "set specific param" the possible commands, or are those actions on commands? What's the OO hierarchy?