

Mark Yedinak
-
Posts
429 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Mark Yedinak
-
-
Congrats! Welcome to the club.
-
Did you volunteer to Mentor a team or are you going to work during the competition.
Thanks for reminding me to get signed up for the comming year.
I am very interested in getting involved this year and my team from last year has disbanded.
Mark,
At this time I will be working on the one day challenge. I will be attending both the practice day and the actual event itself. At this point it is unclear whethe rI will be working with a single team or if I will be working as a floating mentor. I had indicated that I would like to mentor a team for the FRC but I am still waiting to hear if there are specific teams in my general area that I can work with. There are some teams way down on the simply be impractical for me to be able to mentor them from a travel and time perspective.
There was one high school that was on the fence whether they would participate or not again. I guess they had trouble getting people to help them. I would be ideal for this team since the school is about a mile from my house.
-
Well I decided to take the plunge and volunteer for the FIRST competition here in Chicago. The local organizer is pretty happy to have me volunteer since she generally has problems finding people in the actual city to help out and I live in the city. Anyway I was wondering if anyone who has done this before has any good advice or suggestions for a newbie volunteer.
Thanks
-
I wanted to express my thanks to everyone on this board who assisted me with preparing for my CLD exam. It helped me a great deal to have advice from experts like you guys.
Now that I have my CLD certification, my next goal is to find paid employment, preferably in the Raleigh-Durham area. I have ten years of experience as a test engineer, and extensive experience building test solutions for electronics. I am open to contract work. My resume and work history is available on LinkedIn at http://www.linkedin....orne/6/102/301.
Josh
Congrats! Good luck on the job search.
-
A bit excessive dont ya think?
It depends on his application as both you and Scott discussed. The thought that came to mind though when I read the original post was that he was trying to do polling using an event structure. Like Scott, I try to avoid using the timeout event in an event structure. I also prefer to use events rather than polling. As for a producer consumer architecture being excessive I don't really think it is. At least not for anything that will be an application and interact with a user. It isn't that challenging of an architecture to understand and it provides lots of flexibility and extensibility for an application. It is the architecture of first choice for any application I write. No I'm saying that it is the greatest thing since sliced bread but it is a proven architecture for applications where user interaction will be involved.
-
It sounds like your application could benefit from using a producer consumer architecture. Use a single event structure in one while loop that will detect the value change and have the event notify the consumer of the new value. A state machine in the consumer could process the data as required and if necessary repeat over the action until a new value is detected.
-
I think this is the intended behavior of a class static member - all objects instantiated from the class share the same data space for the static member. This is useful in some design patterns like keeping track of the number of instances which might be useful if you're trying to manage a limited number of physical resources. The constructor increments the static counter and the destructor decrements it.
Also, I use a single element named queue for this type of behavior. The data is in a cluster and the queue name is the class name. If any member of the class needs to read or write the static member they get a queue ref (using the name) and then read or write as required. The SEQ forces mutex-like behavior since the one must intentionally flush the queue before a write so any VI that gets a ref at this point is blocked until the writer is finished and vice versa - once a read operation pops the element everyone else waits until the queue is repopulated. The only problem with this is that VIs outside the scope of the class can "steal" the data by using the class name and getting a reference so protecting the data as private is problematic but unless a developer really wants to "break the rules" this works.
Mark
You could combine this technique with a class global that defines the name of the SEQ. If would be written to by the very first instantiation of the class. the name could be in the form of the class name with a random number appended to the name. All other methods would access your global data using the SEQ and the randomly generated name to obtain your queue reference. Using this method it would be very difficult for someone outside the class to get a reference to the queue.
-
I just realized this, again, when we brought Lilah (newborn) home and saw how big Sydney (our 20 month-old) is compared to her. It seems like just yesterday Sydney was a little baby

You should see how shocking it is when it is the same child. My 13 year old really shot up this past year. He grew close to 6 inches in less than a year. Last week I saw some pictures of him from February and he looks like a completely different kid. He went from looking like a kid to looking like a young man virtually over night.
-
Congrats Jim. Enjoy them while they are young. They grow up VERY fast.
-
You could still use an OO approach although it would not be native LVOOP. You could use the Endeavo toolkit or dqGOOP for example. We have several classes which were implemented in dqGOOP since they were created back in the days of LV 7.1. We still use them today and they work well. It would be nice to convert them to native LVOOP but we don't have the luxury of the spare time to do that.
One of the classes that we have is a generic connection class very similar to what you describe.
-
I'm not sure why you say it would more complicated to send the references. Just right click on the cluster to create a reference and send that. It seemed a little cleaner.
I wasn't sure which way would be faster, create fewer data copies, etc.
George
The primary benefit of passing the data directly as opposed to using references is that you avoid race conditions. Once you pass the data via a reference you introduce the possibility of race conditions in your application. They can be very difficult to track down and debug.
-
There is no silver bullet answer for your question. It really will depend on what application you will be opening the document in as to what you will need to include in the actual text of the document.
-
I would highly recommend that you consider using VIPM. My group has been using source code control (CVS) for our reuse and it doesn't fully meet our needs. As crelf stated SCC doesn't truly manage your reuse libraries. The nice thing about VIPM is that once you build and deploy your packages your reuse libraries are easily integrated into the LabVIEW environment. You certainly don't want your SCC repository to sit in the users directory of LabVIEW however that is where you want you reuse libraries to exist. If you use SCC only you need to manually integrate your libraries into the user directories under the LabVIEW and this can be a pain not to mention error prone process.
-
If the auto recovery didn't catch it then the answer is no. The ever valuable lesson of computers: save early and save often. Sorry you lost your work.
-
I don't think that's enough of a difference, personally - what about a strike or a slash through the "!?" instead of a color difference?
That would work too. I was basically suggesting the color to remain consistent with the current "Ignore Errors inside Node".
-
There are plenty of nodes in LV that execute even if there's an error in -- Close Reference, for example -- and the behavior there is well defined. I would assume the property node would follow suit. I think the bigger question is how would we change the block diagram to indicate "executes even if there's an error in" and whether this setting would change the behavior *between* properties... currently if you have 3 properties on a single node, if an early one triggers an error, the later ones don't execute at all.
The way I would envision this to work would be if you select to ignore incoming errors the error input would change from black to red. This would be similar to how the current ignore errors on the inside works. I would also envision this option only affecting the input errors. Internally generated errors would be control by the state of the "Ignore Errors inside Node". If the "Ignore Input Errors" (new feature) is enabled and an error is input then that error would be passed through. If an error occurs on the inside then just like today in most VIs the internal error would overwrite the input error.
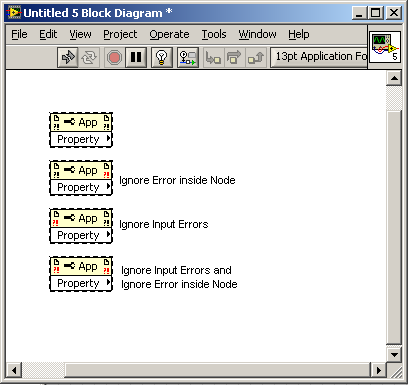
-
Update: idea added to the NI Idea Exchange here.
Thanks for posting the suggestion on the Idea Exchange.
-
I agree, and if I wasn't outputing this to a graph, I would be reading in chunks.
This really all started because my users have been getting "out of memory" errors when running one of my analysis programs. I went in to it to see if I could make it more efficient, and kept running into copies of code where I didn't think I was making any.
I'm going to have to break the files up anyway, in a macro sense. These files can get quite large and impossible to read on a generic laptop. However, I would like to break it up as little as possible for better usability.
Why can't you read the file in chunks and simply build up the data to pass to the graph? You could preallocate the array used for the graph data and replace it as you read from the file. Once all the data has been read pass the entire data set to the graph for display.
-
I totally *don't* want that - that'd obsfucate to much IMHO. Use the "Clear Errors" vilib vi. I think that, rather than adding this functionality specifically to the property node node, I'd rather see the exection sequence container we talked about here.
However this implementation would be much more explicit than a subVI which simply passes an error through it. At least here the glyph could be changed just like it is when you ignore errors inside the property node. If someone writes a subVI that ignores the errors other than looking at the code you have no idea that the error will be ignored.
And yes, if I had to choose between this feature or the sequence container I would opt for the sequence container.
-
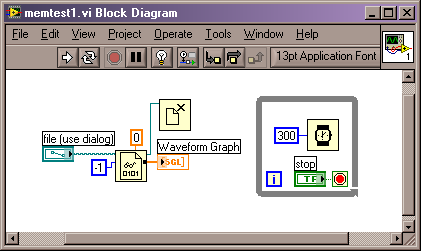
5 copies. Yeesh.
I'm attaching a pic of an example BD. All it does is read a file (~150MBytes) and send it to a waveform graph. The loop is there to keep the vi "alive". The default of all controls/indicators is "empty". There have been no edits done since the last save (in fact, I've been editing, saving, exiting LV, and starting the vi clean, just to make sure there are no residual memory or undo issues).
When the vi is opened, LabVIEW is showing 81MB of memory usage. After it runs and is in steady state, LabVIEW shows ~537MB of memory usage. This would be, I assume, three copies of the data. Where are they all coming from? I've got "Show Buffer Allocations" turned on for arrays in the pic, and there's only 1 little black box showing.
I'm running 8.6.1, if that makes a difference.
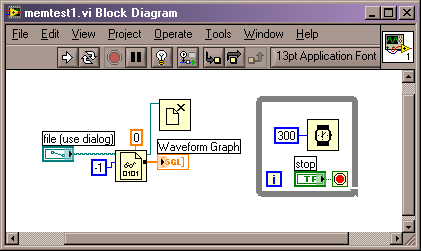
When working with large files like this I generally try to read the file in chunks. If you can do that you may find that you significantly decrease your memory usage as well as see an increase in the performance. Reading large files in a single read is extremely inefficient, at least based on my experience so far.
-
I'm not short - I'm vertically challenged.
That's what I usually say too.
-
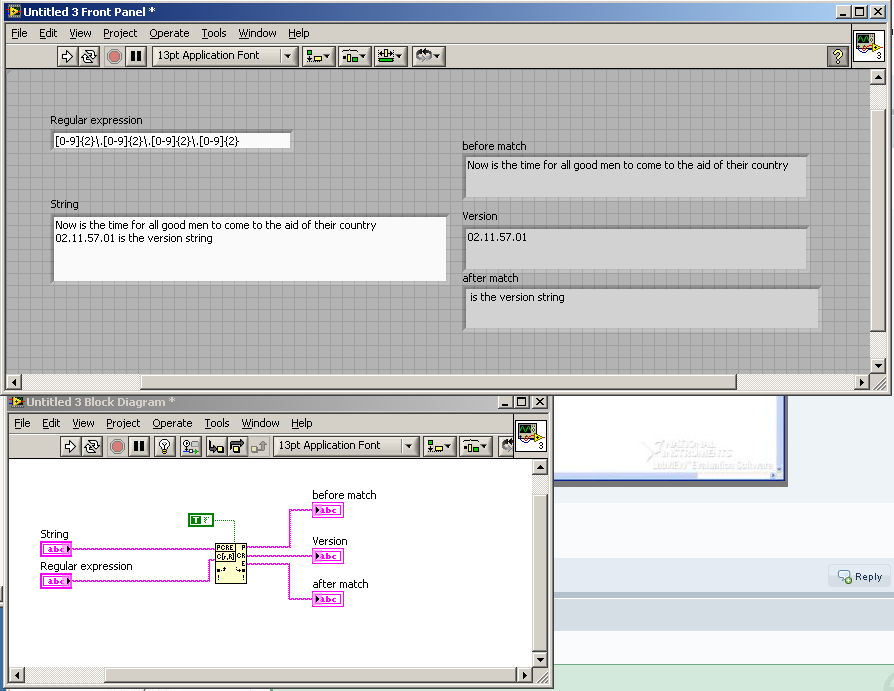
The following regular expression will extract a version string from the text: [0-9]{2}\.[0-9]{2}\.[0-9]{2}\.[0-9]{2}
Here is a condensed version of the regular expression: ([0-9]{2}\.){3}[0-9]{2}
It is not clear from your code exactly what you are trying to accomplish though.
Screen shot of the code.
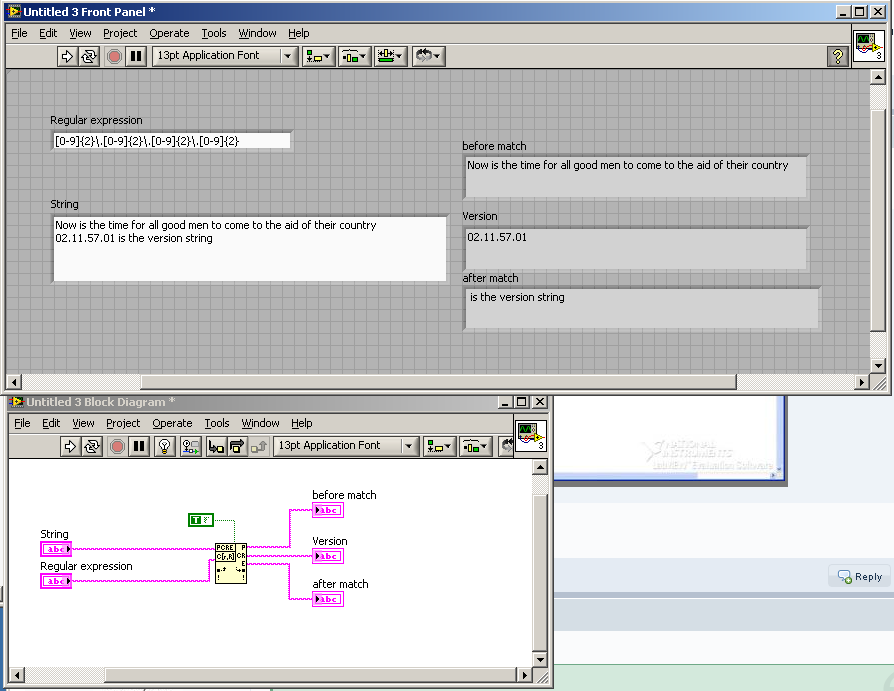
-
Hello,
I'm trying to parse a version number of format 00.00.00.00 from some telnet traffic.
I get several lines of output from telnet when I send it a "version" command.
I'm using the match pattern function on the returned lines and among the regex-es I used are:
\d\d\.d\d\.d\d\.d\d\
m/[0-9].{3}[0-9]/
and variants of these, as well as other regex-es.
I always get the version string plus the several lines afterward. as though the regex is being ignored.
Is there anything about how LV implements regex that quirky , or some issue I should know about?
Thanks!
J
Can you post more of the surrounding data? Also, are you simply trying to extract the version string out of the data?
-
I always figured that you should use locals over property nodes (for reasons already mentioned) - unless you were already using a property node anyway (to set some other property). Also, when speed really isn't an issue, I like that I can use the error clusters of the proprty nodes to both force execution order and decisions based on those errors (note: you can right click on a property node and select "ignore errors inside this node" or something like that).
The ignore errors inside only pertains to errors generated inside the property node, not the error passed in. I wish it did allow you to ignore input errors. this would be handy when using the error cluster to force data flow.

help for useing SNMP in labview
in Remote Control, Monitoring and the Internet
Posted
Could you please post you code saved for version 8.6.1? I don't currently have LabVIEW 9.0 installed. Also, have you tried using a LAN analuzer to capture the communication between the devices? This would be useful in determining what is happening. These VI's were written to strictly enforce the SNMP protocol and I have seen at times that some devices don't always format the response in full compliance with the SNMP spec. This can result in a error. I have discovered a few areas where the error reporting in these VI's can be improved. However, it would be most helpful if I could see you code (saved for LabVIEW 8.6.1) to see what is happening.