marcopolo5
-
Posts
5 -
Joined
-
Last visited
-
Days Won
1
marcopolo5's Achievements
")
Newbie (1/14)
1
Reputation
-
Accessing MySQL from a RT VxWorks target?
marcopolo5 replied to 2muchwire's topic in Database and File IO
Go for it! (but only cause ya help me with my GOOP questions! -
Accessing MySQL from a RT VxWorks target?
marcopolo5 replied to 2muchwire's topic in Database and File IO
Glad to hear about the fast inserts - not surprising. Not much code behind sending the query out. Just when parsing return data. For parsing I found that removing the convert to variant and building a 2D string output (vs a 2D variant output) reduces the parsing time by 5x (variants have a lot of overhead). But still 5x+ slower than LV Database Toolkit for parsing for large datasets. I was originally thinking that the variant output would be natural for those already using the LV Toolkit - which uses 2D Variant output on the API - but for the speed, it's not worth it. I played around a little with pre-alocating a byte array and building up a flattened string format then converting to 2D string after parsing is complete and that speed things up just a little more than the 2D string array solution (10%) - but I need to smooth out my code before posting that solution. Not sure if it's worth it. -
Accessing MySQL from a RT VxWorks target?
marcopolo5 replied to 2muchwire's topic in Database and File IO
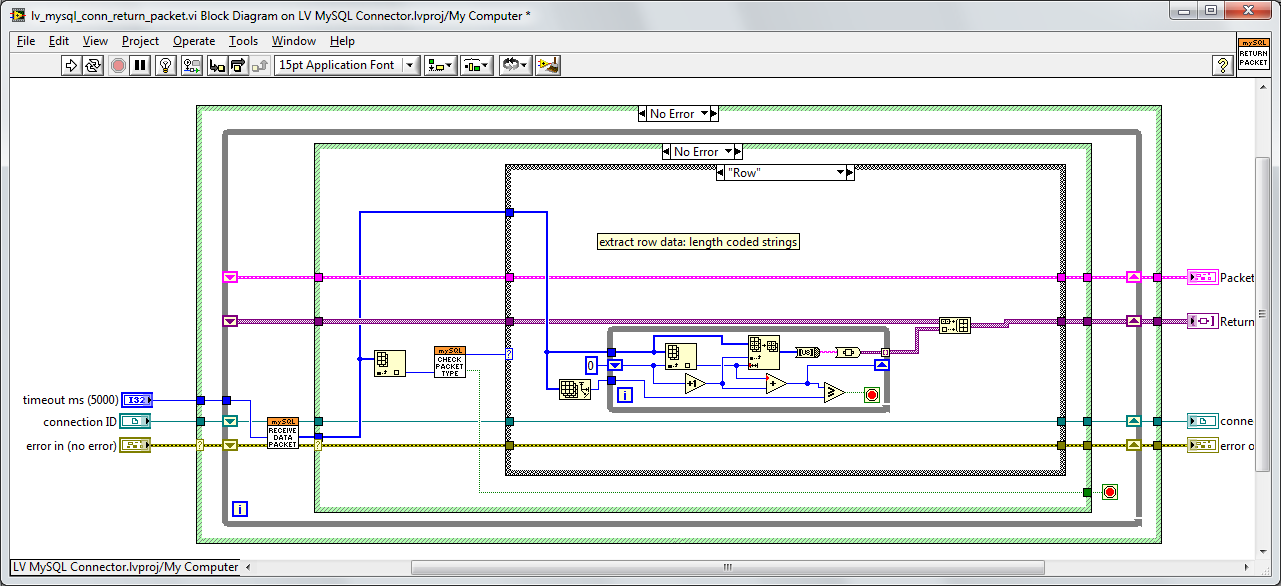
The attached picture shows where the bottleneck is - I'm building an array in a loop (a no-no) . . but I have not found anywhere in the return mySQL header that lets me know how much memory needs to be allocated for the incoming result data. My initial thought is to allocate a "chunk" at a time - perhaps 1000 rows (the header info does give how many columns are in the data) - then return just the portion that was filled. If more is needed continue to allocate "chunks". But then again the data is returned as a string - so I don't know if that will allocate efficiently. I don't have too much time right now to spend on it - just got it working and am pulled onto another project. Any ideas would be great.
-
Accessing MySQL from a RT VxWorks target?
marcopolo5 replied to 2muchwire's topic in Database and File IO
Here's some results from a quick test. I have a mySQL database running on a vmware image (linux) using a bridge virtual port on the same development computer (so ethernet latencies would be greater for a remote server). When selecting 2 rows, 2 columns of data the LV example takes ~0.6mSec (averaged over 10k cycles) to query and return. The LV Database Toolkit takes ~0.7mSec. When selecting 1000 rows, 2 columns; the LV example takes 516mSec (averaged over 10 cycles) where the Database toolkit takes 18mSec. As you can see there's significant room for improvement. On a 9074 controller query of 2 rows and 2 columns takes ~6mSec. -
Accessing MySQL from a RT VxWorks target?
marcopolo5 replied to 2muchwire's topic in Database and File IO
The real answer is "yes" - with the right code. I just posted some code on NI Community that I recently developed to connect to a mySQL database that uses native LabVIEW all the way to the TCP/IP calls. This was specifically meant for RT targets. I have not had time to do much testing (especially on RT targets) and your post made me decide to just put up the code in its current state. So your feedback would be very helpful.