HugoChrist
-
Posts
5 -
Joined
-
Last visited
HugoChrist's Achievements
")





-
We looked into both and will definitely use multiple cores or the GPU in the future but the computation is not what slows us now. I could create my own Array object (maybe using using DSNewAlignedHandle) but I not familiar enough with LabVIEW memory manager. I think this would require me to write external code for every array operations, essentially building a complete array librairy (like numpy), I don't have time to do this now but it would be great because any time I need some sort of subarray of an array more than 2D, I'm facing the same problem. For now, I wrote a simple DLL to handle the windowing and it is about 8x faster than the naive implementation. Thank you for the suggestion, we will look into it in the future.
-
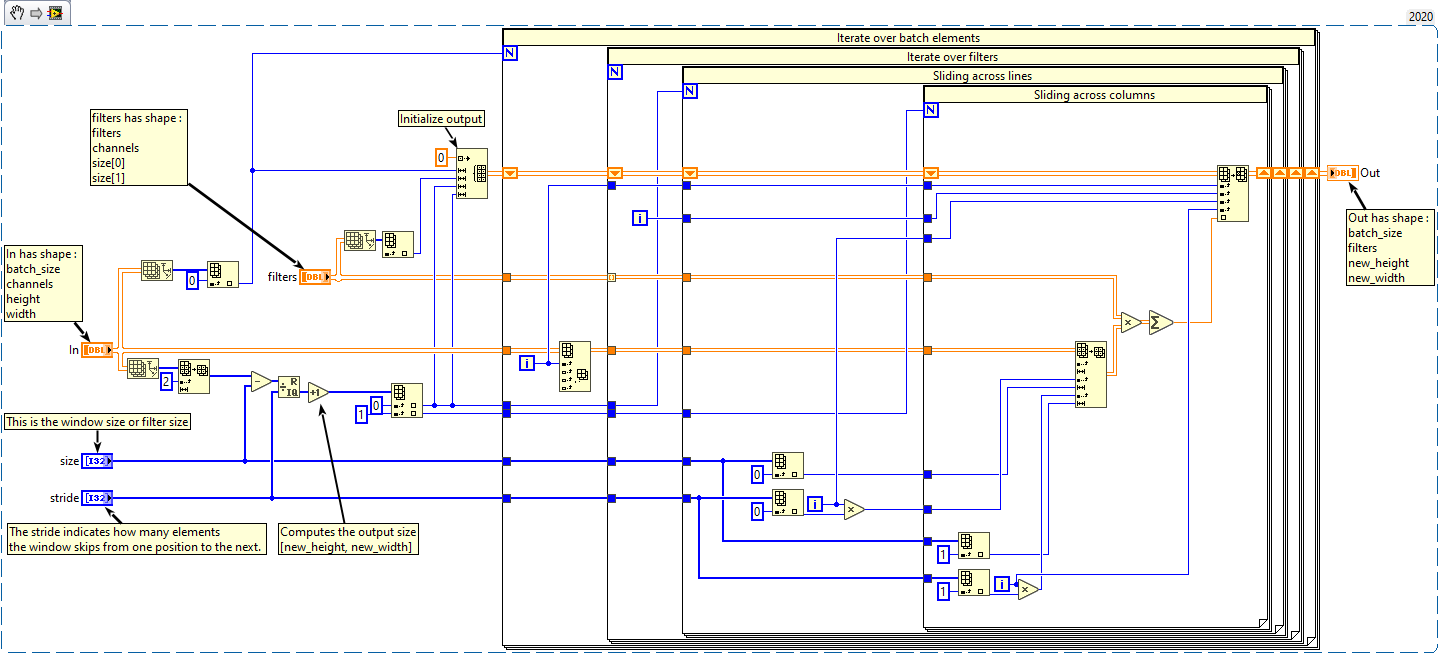
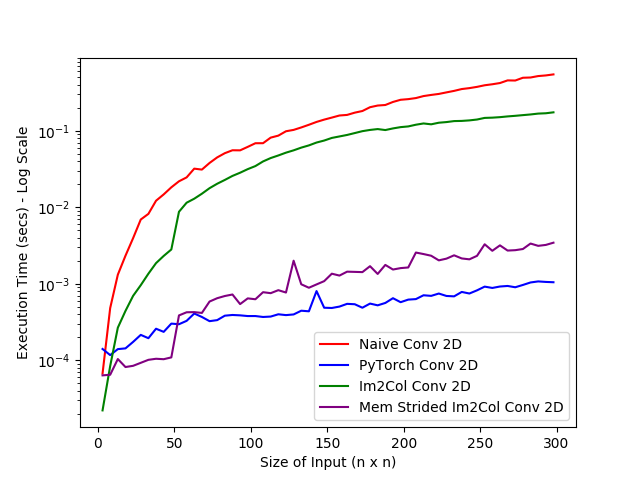
The cost I am worried about is speed. I realize I did not give you enough information. I am implementing convolution layers of neural networks. These layers multiply each window with a filter and sums the result. Here is a naive implementation of a convolution. This is really slow. One way to make it faster is to move the multiplication and summation out of the loop and do it later. Instead, you flatten each window into a 1D array and get a big matrix with "batch_size*new_height*new_width" lines and "channels" columns. Then you flatten the filters into a matrix of "channels" lines and "filters" columns and you do a matrix multiplication. BLAS (Basic Linear Algebra Subprograms) is so well optimized that having so much redundant information is worth it. The function that flattens the windows is called im2col (or im2row in my case) and makes convolutions around 4 times faster. Now there is still room for improvement. You can compute a new shape and new strides to do that. By changing the shape and strides, you only change how the data is viewed as the array is in one contiguous block of memory. The adress of the element at index i,j is pointer + i*strides[0] + j*strides[1]. So this is how it is done in Numpy, PyTorch and other librairies. Arrays (or Tensors) also have a shape and strides like in LabVIEW and there is a function to change them to create a "view" of the same array without any data being copied. This is why my original question was about creating custom subarrays. You can find more details here To illustrate the gain in time, here is a plot from the linked article. Obviously there is still a copy of data when you call BLAS but I thought that given the new shape and strides, LabVIEW would be faster than my im2row function. From Rolf's answers, I get that there is no way to do that, so I am writing external code to do it. I did configure one loop for parallelism but it is not significantly faster. I also tried the convolution vi in LabVIEW but it only works with 2D array and filters and my code is actually faster with BLAS. Thank you for your help.

-
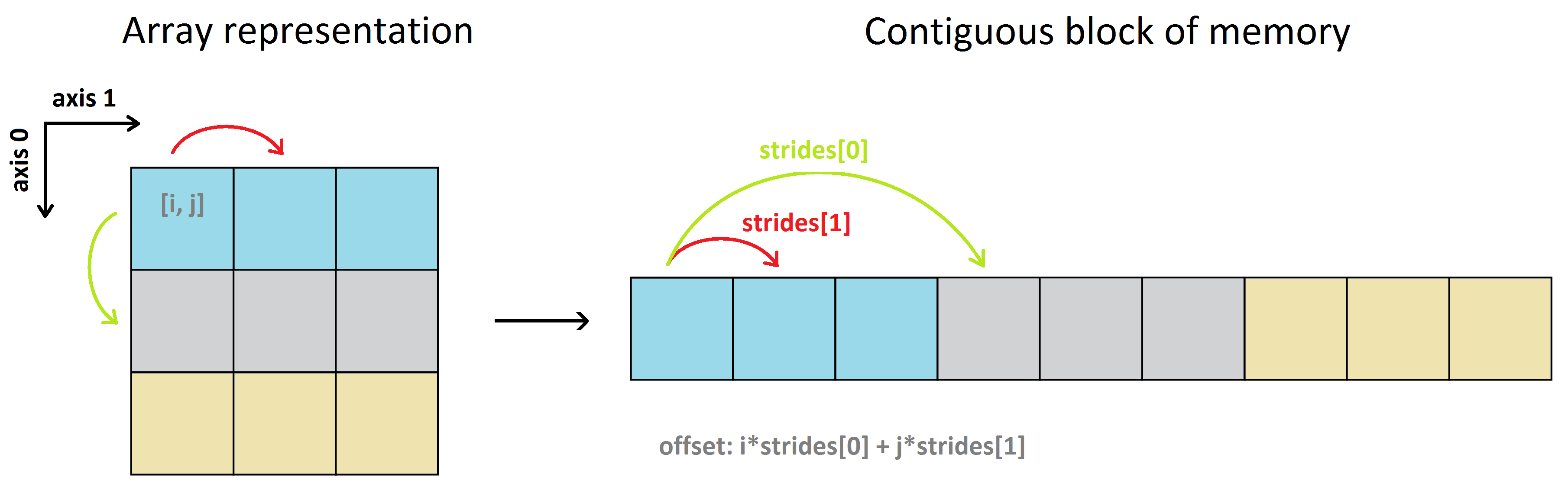
Thanks Rolf, I would be okay with LabVIEW converting the array because I think it would still be faster than doing the two for loops I do. Do you have any information or idea on how I could change the sizes and strides ?
-
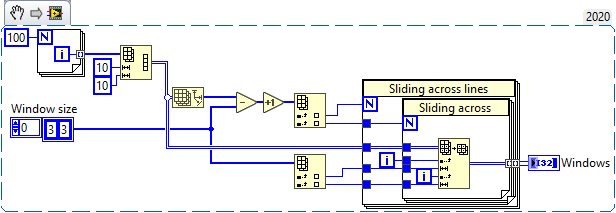
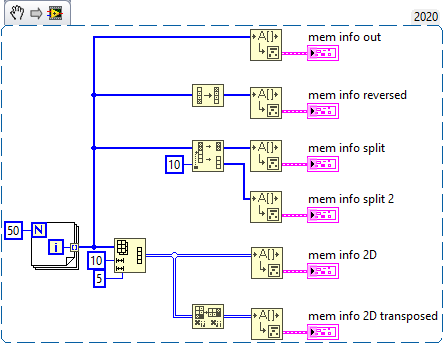
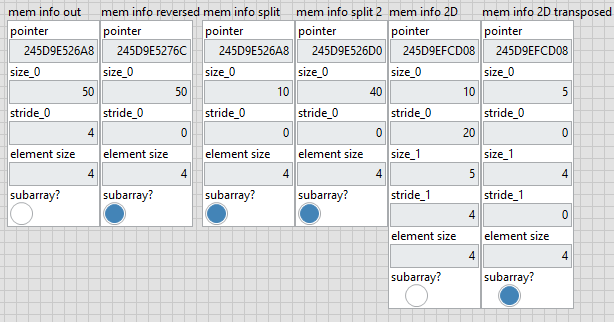
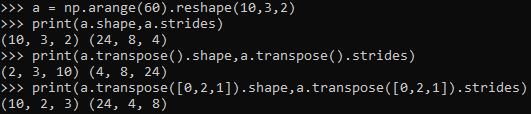
Hi, I need to do windowing on big arrays (4-D with millions of elements) which is very expensive. Just to illustrate what I mean by windowing. From what I've read here and on the internet, LabVIEW stores arrays as a structure with the dimension sizes and a pointer to the first element. In the example 2-D Array Handle in the "External Code (DLL) Execution" vi, we can find a definition: typedef struct { int32 dimSizes[2]; double elt[1]; } TD1; When we do simple operations on 1D or 2D arrays such as reverse or transpose, LabVIEW doesn't copy any data, instead it creates a structure with the information needed to read or reconstruct the array. Rolf Kalbermatter said that this information is stored in the wire Type description. We can read this information with the vi ArrayMemInfo. It gives the pointer to the first element, the size and stride of each dimension and the element size. The stride is the number of bytes to skip to get the next element in a given dimension. Numpy has a similar approach and this is what it gives for sizes and strides. We can modify it with the function "numpy.lib.stride_tricks.as_strided", and do really fast windowing thanks to it. The information given by ArrayMemInfo seems incorrect but assuming it's just a reading error, modifying this information would allow me to do efficient windowing and much more, like transposing or permuting N-D arrays. I have no idea if this is possible and even if I could change this information, I don't know if LabVIEW would have no problem interpreting it. What do you think ?