

Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Daklu
-
-
Indeed. In the sense of an ordered list of messages and "how" it is realised (queue primitive or while loop with shift register) is, IMO, irrelevant
I agree, but you can see from the responses there isn't a universal consensus on it.
[Edit - The remainder of my response can be found here.]
-
A queued message handler is a collection of frames that are basically an API of discrete functions driven by an ordered list of incoming messages. There are no inter dependencies between the frames and they can be called in any order at any time.
Have you looked at the 2012 QMH project template? Would you consider the Initialize, Initialize Data, and Initialize Panel messages interdependent? If so, then is that template not, in fact, a QMH?
The module, as a whole, does not have any state.What do you call a module that does have state (behavioral or data,) but does not have interdependencies between the frames? It doesn't fit into your QMH or QSM definition.
For me a QMH would be producer-consumer kind of construct that uses LV queues. A QSM queues states (within the each state/iteration of producer loop, whereas a QMH uses queues originating in one while loop to communicate to, or message, another loop. The difference lies in the communication used as well as there being more than one while loop, each running in parallel.I have talked to a few people who consider the both loops to be part of the QMH/QSM. I don't find that definition very helpful, primarily because of its limited usefulness as a component. I've never seen any examples illustrating how to integrate other concurrent processes into the basic QMH template. (I suspect that's because it would reveal all the glaring problems in the implementation, but... *shrug*.)
A “queue” is different than a specific implementation of a queue, such as the LabVIEW in-built Queue. User Events also involve a queue, as do things like TCP or Network Streams and the like. In contrast, things like Notifiers do not. So, “QMH” does not specify the transport implementation.I'll grant you QMH doesn't necessarily specify the transport implementation, even though in many cases it does. Regardless, QMH *does* specify the transport's behavior. Transports are not defined as having queue-like behavior. It certainly could behave like a queue and present messages in the order they are sent. It could also behave like a stack and present the most recently sent messages before the earlier messages. Or it could behave like a global and overwrite pending messages with newer ones. Or it could randomly choose which message to present from all pending messages.
The point is, a well-written message handler doesn't care about the transport's behavior.** Yes, the transport's behavior could have a significant impact on how you create systems of MHLs, but an MHL is robust against changes in that aspect of the transport's behavior. It doesn't require a specific transport behavior to work correctly.
**That statement defines the difference I see between a MHL and QMH/QSM better than anything else I've been able to come up with. If you can arbitrarily change a transport's message ordering behavior without breaking the receiving loop's expected behavior, then it's a MHL. Otherwise you have a QMH/QSM.
For example, here's a screenshot from the 2012 QSM project template. You probably want to create your own instance from the template--it will probably be easier to follow what I'm saying.
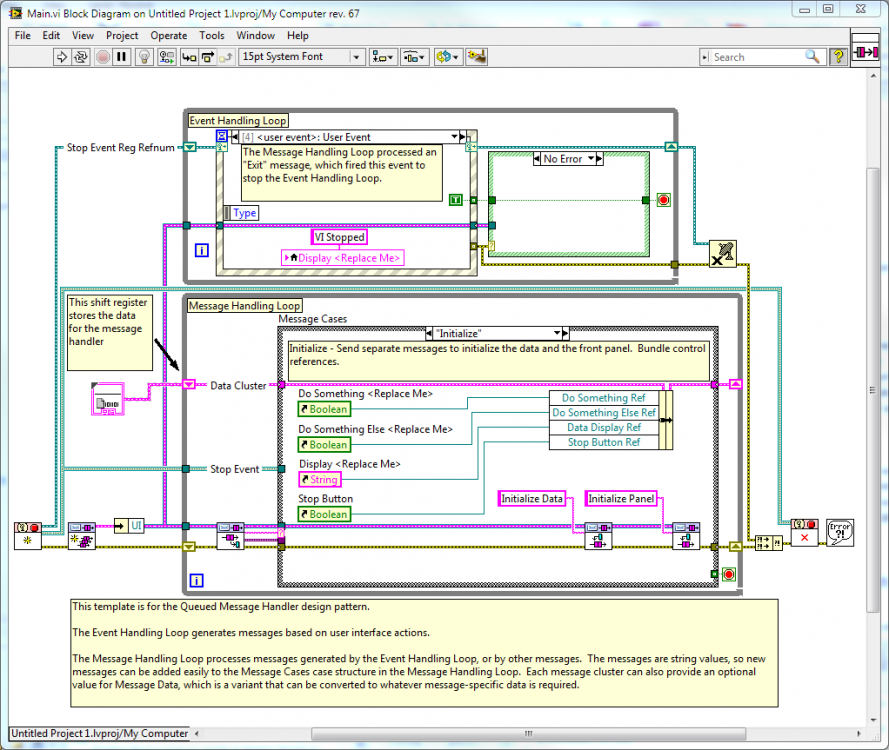
There are four message handling cases we are concerned with--Initialize, Initialize Data, Initialize Panel, and Update Display. The message sequencing is set up like this:
--> Initialize |--> Initialize Data |--> Initialize Panel |--> Update Display
Their responsibilities are:
Update Display - Update the fp indicators with data from the message payload.
Initialize Data - Reset the shift register data to their default values.
Initialize Panel - Self-send all the current shift register data in an Update Display message.
Initialize - High level message that initiates the the initialization process. The implicit guarantee is immediately after this message sequence has been processed the shift register data and front panel indicators have been reset to their initial values.
The "Initialize" message is put on the UI queue in the "Create All Queues" vi (we'll ignore that peculiar design decision this time) so it is the first message processed by the loop. As long as the transport behaves like a queue, it will probably do what you expect. (We'll also ignore the race condition that exists between sending the Initialize Data and Initialize Panel messages.)
What happens if you change the transport's queue behavior to stack behavior? The Initialize Panel and Initialize Data are processed out of order and the Initialize message no longer fulfills its responsibility. It's worse if you change the transport to global behavior--any arriving message can potentially abort the sequence of initialization messages and "break" the Initialization message.
As I see it, the template is very much a QMH/QSM, but is too dependent on the transport behavior to be called a MHL.
-
These statements have convinced me to not ask for code.
I don't think asking for code is bad, or wrong. Code samples are good at showing how to do things. Theory explains why you do things. My presentation focused on the theory, so code samples kind of distract from the message. (FWIW, I'm far less concerned about showing the how than I am about explaining the why.)
I haven't provided anything to the community...Not true. You've participated in discussions and posted about your experiences. And you posted that awesome link to Hewitt's channel 9 video, which did more to help me understand the actor model than anything else I've encountered.
Talking theory is useful, unless I don't know how to turn it into wires.Good point. I remember in college how frustrating is was for me when professors lectured at length about some theory before showing any practical application of the theory. I often wished they would integrate theory and application more tightly. The question then becomes, how can I show practical application of the theory while avoiding implementation fixation? I hoped the abstract animations would be sufficient to reinforce the theory. Maybe they're not?
If I ask NI what is a QMH won't they open the template that comes with LabVIEW?I dunno what they would say (ask 10 people and you'll get 20 different answers), but outside of the JKI-SM I never see a QMH implemented using an array of strings, as shown in the 2012 QMH vi template. Interestingly, the implementation in the 2012 QMH project template is completely different. In your opinion, which implementation correctly defines what a QMH is and how do you justify the claim?
Is this now no longer called a QMH? It feels like it is a QMH but it also feels like it is something more specific but it is still a QMH is it not?Depends on whose definition you're using. According to my definition adding data state and an event structure in one of the cases doesn't change it from a QMH into something else. For me, the main differentiator between QMH/QSM and well-written MHL* is a QMH/QSM uses implementation techniques that are not generally thread safe--they may be okay in a specific application, but the technique cannot be universally applied.
[*I consider a well-written MHL one that conforms to the actor model. In general, when I say MHL I mean a message handling loop that conforms to the actor model. If a loop handles messages and does not conform to the actor model, I call it something else. Usually "QSM" or "QMH," but if I'm feeling cranky I'll call it a blight on the LV developer community.
 In this post I refer to the "template's MHL" a few times. I do that because it is labelled as a "Message Handling Loop" in the template, even though the loop implementation more closely matches a QMH.]
In this post I refer to the "template's MHL" a few times. I do that because it is labelled as a "Message Handling Loop" in the template, even though the loop implementation more closely matches a QMH.]For example, the QMH project template's MHL makes extensive use of enqueuing messages to itself. Self enqueuing doesn't automatically introduce race conditions, but it sure makes it a lot easier to unknowingly add them. Figuring out whether or not any specific implementation has detrimental race conditions requires concentrated code inspection.
The template's MHL also exposes three messages that shouldn't be public: Initialize Data, Initialize Panel, and Update Display. Poor API design makes the template's MHL harder to use than it should be and increases the opportunities for programming errors.
You mentioned adding a "" case with an event structure inside it to process user inputs. I presume you also have a constant wired to the dequeue timeout. Dequeue timeouts are another technique that works only in certain situations. (I noticed the dequeue used in the template doesn't have a timeout. Kudos to whoever wrote the code for recognizing their danger.)
As I've said before there's a lot of gray between a QMH and an MHL. QMHs are often written at the same time as the message sending loop, resulting in two loops that work okay together but are inadequate as independent components. Developers write a QMH based on their knowledge of the message sending loop. A new, arbitrary message sending loop frequently causes unpredictable or unintended responses in the QMH. Conversely, an MHL is written without specific knowledge of the sender. The MHL developer accepts he is unable to control the order or frequency of messages received and writes the MHL code to deal with those situations.
I suspect a QMH could be used as a private helper loop to a MHL, though I wouldn't because correct QMH behavior is harder to verify than other techniques. QMHs are entirely inadequate to use as the public interface to other components in a concurrent application.
-
Thanks James, that helped a lot.
I meant to ask for tips figuring out exactly which add-ons or modules were installed when the application was built, not just which drivers were installed by the installer. Nonetheless, your tip got me going in the right direction and saved me bunches of time.
-
I would take the point that the line is drawn where it is for one reason, so we can express that AE is good and FGV is bad, it is to suit us rather than any actual difference in implementation.
That's funny. I consider FGs an acceptable (though not preferred) way of creating a shared data store or data transport mechanism, while the AE is an ugly hack I always avoid. (If the goal is singleton behavior, there are simpler ways to get the same behavior that are more extensible.)
I wasn't talking about terminology to public methods VIs, I was trying to say that when in a public forum and discussing FGV vs AE all that matters is that the audience understand what we are talking about. And by that I mean a uninitialized shift register.Sure, I understand. My point is it more useful when names refer to a component's observable characteristics, not according to how it has been implemented. When discussing a FG vs AE, you're comparing their observable characteristics. Once you make the AE private and expose its api through wrappers its observable characteristics no longer match what we typically consider an AE; hence, you're no longer comparing a FG and AE. The component may be implemented using an AE, but it's not an action engine itself.
I'll counter with this: If you mean uninitialized shift register and want the audience to understand what you are talking about, then say uninitialized shift register. FGs and AEs use USRs in their implementation, but they are not USRs themselves.
There are two ways to make an LVOOP DVR FGV. One is to create a class with methods that operate on the data and then wrap that class in a DVR. The other is to create a class that has a DVR in its private data and then create methods that create the DVR, access the data in the DVR and destroy the DVR.My question:
Which one is better? Which one do you use?
I agree with James that there is no universal "better" answer. However, I prefer the first solution and believe it is more robust. To expand a bit on what James said, solution 2 presents some difficulty exposing read-modify-write operations through the public api. In addition to the normal data access methods, the class has to expose some sort of mutex (lock/unlock) functionality to prevent other threads from overwriting the data between the read and write operations. The IPE structure is the safest way of mutexing data access; why make it more difficult for users by taking that option away from them?
By default all my classes are as by-value as I can reasonably make them. If I start with a by-val class I can easily create by-ref or singleton behavior by dropping it in a DVR, or global, or whatever. But, if my class starts out as a by-ref class I can't go backwards and use it someplace where I need a by-val class. And if it starts out as a singleton, I can't use it as either a by-ref class or a by-val class. Keeping my core functionality in by-val classes maximizes the ways I can use the functionality the class exposes.
-
Well. There is no real difference between FGV and AE from your definition apart from an arbitrary break point to try and make a differentiation..
Agreed, and I said as much in my post. The transition from FGV to AE is a variation of the paradox of the heap. When does FGV become an AE? When is a heap of sand no longer a heap? If we're going to make a distinction between FGV and AE (and I think we should since the names convey very different ideas) then we need to choose an arbitrary break point. I chose that break point because not coding myself into a corner is one of my primary requirements, and adding methods other than get/set is the beginning of that trap.
So I'm sure others have done this too, but when I get this type of AE I will usually wrap the functions into SubVIs so only the important terminals are being shown for that function and then inline the VI....it just matters that we understand a non-re-entrant VI with uninitialized shift registers is keeping track of some data between calls.
Once you create a public interface for the AE using wrapper VIs, the fact it is implemented with an AE is irrelevant. You don't care (or shouldn't care) that the wrappers use a non-reentrant VI internally or that the data is stored on an uninitialized shift register. You only care that all the public interface VIs refer to the same data and access during read-modify-write operations is controlled correctly.
Do you guys really use FGV or AE much anymore? I would think it's a dying practice now with native classes.I don't (never did, really) but enough people still use them that it makes sense to understand the differences between them. (At the very least the discussion gives me some insight into how other developers think.)
-
 1
1
-
-
Again, thanks for the feedback. I really do appreciate it. Please don't interpret my responses below (or lack of response to your comment) as dismissive. They are just explanations of my thinking.
Dave, I thought you conveyed the core concepts of AOD well, but perhaps your talk could have benefited from more fleshed out examples of how you would actually implement your kind of actor in LabVIEW, including how you manage the state data and how a hierarchy of actors would look (in a single VI and perhaps as multiple VIs).As for improvement, I agree with Neil that examples would do a lot of good for spreading around "proper" AOD.The biggest problem with showing example code is people fixate on the implementation details instead of the principles being taught. I see that happen everywhere--complaints about the examples in LV, questions asked in sessions and on the forums, etc. There are lots of ways to implement actors, transports, and messages, and any example implementation is going to reflect a large number of unspoken design decisions. What I show as being suitable in my example may not work at all in another developer's application or work environment.
While I was talking about helper loops one person asked if instrument communication should go in a MHL or a helper loop. My response was, "it depends." Not a very satisfying response I admit, but it was the truth. There are too many unknown variables for me to answer that question without sitting down and talking to him about details. In retrospect, just having him ask it tells me I'm not communicating the important part of the message adequately.
I'm actually considering removing the code examples and replacing them with abstract animations similar to the one early on showing the address being passed around. I am intending to publish a paper on how I implement AOD in LabVIEW, but that is distinctly different from trying to explain AOD principles in general.
If what you are saying is true then maybe the real reason I have a difficulty knowing the difference is I've never used a QMH the way you describe.I see. You had the advantage of learning LV while working with more experienced developers who could help you avoid the pitfalls. My perception is most people learn LV largely on their own. We relied on trial-and-error and community wisdom to learn. Unfortunately there are significant limits to that model and several standard practices that have developed over the years are not robust.
Part of what makes the QMH so controversial is it has never been well-defined and means something different to everyone. When you say "QMH," what exactly do you mean? The template? The implementation pattern of a dequeue prim and case structure inside a while loop? My argument is using QMH to refer to the implementation pattern isn't useful. Describing a component's private implementation as a QMH tells me nothing of value. Describing a component's public behavior as like a QMH tells me everything I need to know. (Namely to not use it.
)Thoughts on just watching it:1) More pictures; fewer words.
2) I suggest starting with the Message-Handling Loop or QMH (that people will be familiar with) and talk about what restrictions would make this an Actor:
— communicates with other code/actors ONLY via messages to this SINGLE loop. No by-ref data sharing or other communication methods.
— no global addressing (eg. no “named” queues)
3) mention “high cohesion and loose coupling”; an actor is a cohesive unit that is loosely coupled to other actors.
1. Fair point.
2. I'm actually thinking about breaking it down further than that. The actor model views actors as the fundamental unit of concurrent computation. I view the loop as the fundamental unit of concurrent computation. An actor is a higher level abstraction containing one or more fundamental loops.
2a. I did mention (or intended to mention) that. Maybe I didn't emphasize it enough.
2b. That's an implementation detail and actually not a property of the actor model. It's a convention I strictly adhere to and I believe it makes code easier to read, but I can't claim it's a necessary part of AOD.
3. First, any jargon I use needs to be defined, which distracts from my message to some extent. Second, the amount of coupling between actors depends on the implementation. AF actors tend to be fairly tightly coupled to each other, but they are still actors.
I'm a bit oblivious to the job-security aspect of "Never tell everything you know." I'd rather work myself out of a job by doing it well or by teaching someone else to do it.I put that quote in my sig because I thought it was funny. Believe it or not I don't hold back information I think would benefit other developers in the community. I believe "a rising tide lifts all boats" holds true, but to be perfectly honest I do sometimes worry about the consequences of teaching my competitors how to be better programmers.
It's one thing to work yourself out of a job when you are dealing with the same people day in and day out. They can see the value you bring to the business and often will keep you around. It's another thing entirely to work yourself out of a job by teaching the competition how to do what you do so they can undercut your prices.
-
........later....
Nope. I do know the difference between a QMH and Actor and I don't think it's semantics. QMHs don't contain state and the state is driven by the producer. If they do maintain state, then they are QSMs (QSMs and Actors being subsets of QMHs). So an Actor can be the same as a QSM if it does not manage it's state (unusual) but a comparison between Actors and QSMs would have been clearer.
I spun off a new thread to discuss this.
-
(This thread is branched from a comment Shaun made here.)
...I don't see any difference personally between an actor "Do" and QMH as I don't think there is one and it seemed that you were not really convinced there was one either I do however see a huge difference between Actors,QMH and Queued State Machines (and you mentioned the JKI QSM as in reference to QMHs) and in that context I agree with many of the things you often espouse. The usual example I give for QSMs is reading a file, since it is a lot of code and a lot of messages all to do something that can be done in a single simple VI and there is little benefit in splitting out the states. That VI would then be put in a QMH or Actor.........later....
Nope. I do know the difference between a QMH and Actor and I don't think it's semantics. QMHs don't contain state and the state is driven by the producer. If they do maintain state, then they are QSMs (QSMs and Actors being subsets of QMHs). So an Actor can be the same as a QSM if it does not manage it's state (unusual) but a comparison between Actors and QSMs would have been clearer.I've never seen a difference between QMH/QSM and use the terms interchangeably. Seems to me QMH was just rebranding the QSM to avoid confusion with the name "state machine." I'm curious if/how others differentiate between QSM/QMH.
QMHs don't contain state and the state is driven by the producer.This comment confused me. The first reference to state implies state=data, but the second reference to state implies state=one frame in a case structure. Can you explain further?
<Thinking out loud>
Using your definition, if the QMH doesn't maintain data state, I take that to mean it doesn't have any shift registers? In which case the only things it can do when processing a message is exit the loop or send a message somewhere else. Hmm... that does eliminate the meta-stability problem sequentially dependent messages create. Functionally it is exactly the same as what I consider a MHL, except my MHLs can (and usually do) contain data state.
</End thinking
>I still believe QMH is a poor name. It identifies the message transport's implementation--a queue. The transport's implementation is irrelevant to your definition of what a QMH is. Furthermore, I believe the transport's implementation is irrelevant to any well-written message handling loop.
<Thinking out loud again>
The one thing the QSM, QMH, and actor MHL have in common is they receive and handle messages in their own logical thread. So what variations are there of well-written message handling loops? What are the advantages and disadvantages of each of them? Can we come up with more intuitive names for them?
Here are some of the things I believe are essential for any well-written message handling loop:
-No sequential message dependencies(!!)
-Message processing time << Interval between messages
If we accept that as the baseline, the only two important characteristics that come to mind immediately are:
-Data State: Does the MHL retain user data between messages?
-Behavioral State: Does the MHL have more than one handler for any message and choose which handler to use based on its internal data?
Thoughts? (Open to all, not just Shaun.)
-
Agreed. I don't think there is a difference apart from terminology.
I disagree. Here's how I differentiate between them.
Normal Global - A data storage container.
Functional Global - A data storage container with get/set methods, allowing the developer to check data validity prior to getting or setting the value.
Action Engine - A functional global that adds methods--other than get/set--to operate on the data. Essentially when a third method is added to a FG it becomes an AE.
I agree there's a lot of fuzziness between FGs and AEs, and my definition is as arbitrary as anyone else's. I chose that as the defining characteristic because adding methods other than get/set to a FG is taking the first step down a path that easily leads to heavy code debt. The con pane puts a practical limit on the number of methods an AE can support. In theory you can jam every possible input and output into clusters and have an infinite number of methods; in practice it makes the AE much harder to use than other implementations. Restricting the methods to get/set keeps it simple.
-
2
-
-
Thanks for the responses so far.
Another big turn off was the semantics between an Actor and QMH. I realize it is a heated topic...I wouldn't call "the semantics between an Actor and QMH" a heated topic. I can get... energetic... when I'm trying to explain the difference to people, but I don't get angry about it.
The reason I talk about the differences between a QMH and an Actor is to try and show it's not just semantics--there are huge differences in how external entities interact with a QMH compared to how they interact with an Actor. Your comment indicates I didn't do a good enough job communicating that message. Either I didn't explain it well enough or you have a different idea about what a QMH *is* than I do.
The feedback I heard from others was that each of you (David and Staab) could have had your own dedicated sessions.Yep, that's probably true; however, I pitched my presentation for NI Week last year and it was rejected. I don't have any reason to believe it would have been accepted this year either. If Staab hadn't asked me to participate in his session I wouldn't have done anything.
one thing was abundantly clear: viz, it didn't work that well for the two of you to present in the same time slot.Yeah, I got second hand feedback that a few people thought the switch from my presentation to Staab's was a bit jarring. We assumed people knew OOP and were passingly familiar with the AF, but didn't really understand AOD. My part attempted to explain the principles of AOD to help devs design their app correctly, and Staab followed with details to help people implement their app correctly using the AF. Given that we were in the same time slot, I can't think of any way we could have lessened the jolt. Any ideas? (That's an open question to everyone.)
-
Edit - Mark Balla recorded the session and posted the video. Instructions for downloading it are here.
--------------
First of all, Thank you to the Lava community for coming to our NI Week presentation! We had a great turnout and I was shocked at how many people raised their hands when I asked who read the Lava forums. I hope you found the content informative and useful.
For those of you who attended, I'd appreciate it if you could help me improve the presentation by giving me your honest feedback on my part. I'm not fishing for a pat on the back; I really what to know what parts you found most helpful and what parts I need to work on improving (or eliminate altogether.) Everything is fair game--the content, the look of the slides, how I presented, what I was wearing, etc. What I too repetitious? Did I not spend enough time explaining something? Was the message cohesive and coherent? If you thought it, I want to hear it. (Yes, I'm looking at you lurkers...)
My primary goal with this presentation is to help people understand what it means, at an abstract level, to do actor-oriented programming. My secondary goal is to point them in the right direction regarding implementing actors. Some of the areas I think need to be improved:
-I don't think I did a very good job explaining the principles of hierarchical messaging.
-I skipped around on a few of my slides and that may have caused confusion.
-A Venn diagram probably isn't the best way to illustrate the Actor Model.
If I were to expand this into an full hour presentation, what topics should I cover in more depth? My thoughts:
-Topologies. Maybe animating messages between actors would help illustrate the tradeoffs between direct and hierarchical messaging?
-I had a couple requests for more discussion about Command Pattern messaging. Would this be helpful? The command pattern could be an hour long discussion all by itself. How much needs to be covered?
-Do I need to go into more details about the issues with QMH/QSM and show how actors are different?
-I glossed over actor Exit conditions fairly quickly; that might need a bit more explanation.
Thanks,
Dave
-
We all know a poet named Darren
He writes limericks with much love and carin'
We love a good rhyme
And appreciate his time
Here's hoping he never goes barren
-
2
-
-
Platform ISOs? Have they ever done that?
I have some, so I assume they do. I dunno... maybe I created them from media I had?
-
I didn't see Norm's impromptu Leap Motion presentation, but I think that's what he was using with his scheduled presentation... right up until he disconnected it because it wasn't behaving.

-
Have they posted dvd ISOs yet?
(Platform ISOs, not driver ISOs.)
-
(Related post here.)
I have a previously released application (v1.1) built using LV2009. Currently vNext is in development using LV2012 and the most recent drivers. To simplify their testing, I'm trying to allow users to install v1.1 and vNext side-by-side rather than having vNext overwrite v1.1.
I duplicated the v1.1 installer spec, made the appropriate changes (including generating a new upgrade GUID), and built the installer. So far so good.
When I run the vNext installer on a clean system it works as it should. However, when I attempt to install vNext on a system with v1.1 already installed, I have to run the installer twice. The first time it just changes the drivers. The second time it actually installs the vNext software.
Anyone know why this is?
-
I have a previously released application (v1.1) built using LV2009. For v1.2 I have upgraded to LV2012 and am using the most recent drivers. Ultimately I'm trying to allow users to install v1.1 and v1.2 side-by-side, and part of that is recreating the build environment to minimize the impact to the end user's system.
I've saved the information in the notification dialog the NI installer displays. When I install v1.1 on a fresh pc I get this:
Adding or Changing
NI Vision Run-Time Engine 2010 SP1
ActiveX Support
NI-IMAQ 4.6.4
<MyApplicationName> Files
NI-Motion 8.3
Documentation
NI 73xx Controller Support
NI Measurement & Automation Explorer 5.0
NI System Configuration 5.0.0When I install v1.2 on a system with v1.1 already present, I get this:
Upgrading
WARNING: National Instruments system components will no longer be available
NI Vision Run-Time Engine 2012
ActiveX Support
NI-IMAQ 4.7
WARNING: Vision-RIO Support will no longer be available
LabVIEW Real-Time Support
LabVIEW Real-Time 2012 Support will not be available
NI-Motion 8.4
Documentation
NI 73xx Controller Support
NI Measurement & Automation Explorer 5.3.1Adding or Changing
NI Vision Run-Time Engine 2012
.NET Languages Support
NI-Serial 3.8.2 for LabVIEW Real-Time
NI-Serial 3.8.1
NI-Motion 8.4
Microsoft Visual C Support
NI-VISA 5.2
Run Time Support
Configuration Support
Development Support
Real-Time Support
NI I/O Trace 3.0.2
NI System Configuration 5.3.0Removing
National Instruments system componentsDoes anyone have tips for figuring out exactly what drivers are installed with v1.1? You'd think it would be a simple matter of finding the extra drivers and uninstalling them, but it doesn't seem to be that easy. The drivers have a lot of dependencies on each other and I cannot, for example, remove NI-Serial 3.8.1.
-
Maybe my browser isn't rendering correctly but the only thing I could think of was, "uhh... not really."
-
I remember reading about Asteroids in a C´t article.
Ouch. I feel old.
-
So I happened to open my 7th grade daughter's yearbook this morning to a random page and this was the very first picture I saw.

Who knew?
-
I was being facetious
Oh. It's hard to read subtlety in text messages.

-
I'm back looking for the silver bullet, has anyone found it yet?
If the silver bullet you're looking for is the "one implementation pattern to rule them all," then no, to the best of my knowledge nobody has found one. I don't believe one exists. AOD comes the closest for me, though it is much larger in scope than an implementation pattern.
For your customers, you are the silver bullet. If there was an implementation silver bullet, there'd be no need for architects.
-
...to save all the positional/configuration information, you need more notation than any of the textuals generally have.
I agree, dealing with all the position/configuration information would be a pain. When I'm diffing VIs 98% of the time I don't care about block diagram positions; I just want to what functional changes have occurred. I've been idly wondering about ways to get a text-based diff engine to ignore certain elements, like position tags.
It's interesting you mentioned Graphviz. Occasionally I wish I had an editor that allowed me to write certain parts of my applications using text code. Over there (*waves vaguely in the direction of the NI forums*) I suggested opening the compile chain to provide developers with a way to compile code from DFIR instead of from G source. Then the other day I found out you can use Graphviz to view DFIR. Even though it does me no good to write or modify DFIR files directly, perhaps diffing them would be useful? I think I'll have to spend some time looking into that...
Regarding mutli-threading and message-passing Erlang has a good name.Yeah, I've heard good things about Erlang. It's one of the long list of languages I'd like to learn, along with Haskell, F#, XAML, Ruby, Lua, Smalltalk, x86 asm, etc. My next language (other than Python, which I'm learning with my daughter over the summer) will probably be Oz. I find the idea of supporting many different programming paradigms intriguing.
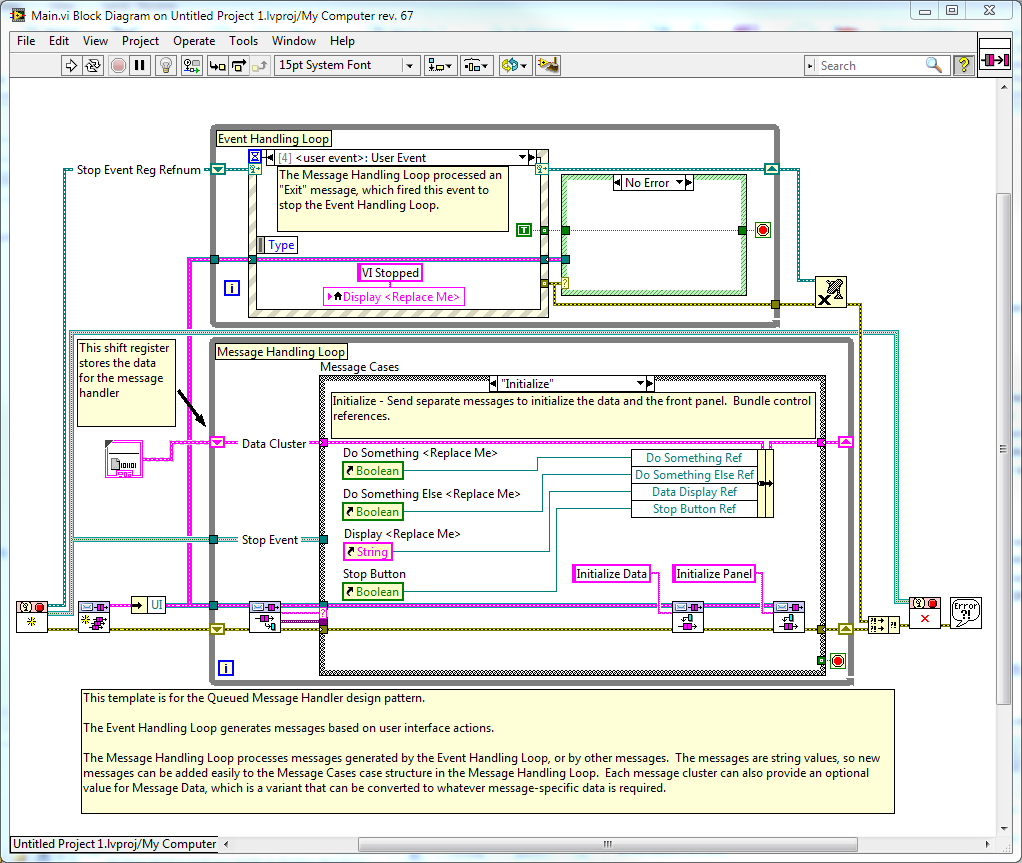
Differences between QSM, QMH, and actor MHL?
in LabVIEW General
Posted
I'm not claiming you're wrong, but I do claim your interpretation is just one of many equally valid interpretations.
I mostly agree, with the added restriction that messages are buffered in a FIFO and presented in a first-in-first-out order. For better or worse the names "QMH" and "QSM" also convey expectations about the techniques used to write it and how users can and should interact with it. Those techniques often create unexpected race conditions.
[Copied from the other thread, it's more appropriate here.]
From an abstract, natural language perspective I agree with you. From a useful programming jargon perspective I don't. Those definitions are far too general--we know there are "good" and "bad" ways to implement a message handler. Good message handling loops conform to a stricter set of rules and offer more guarantees than bad message handling loops. Giving good message handling loops their own name helps users understand what they can and cannot expect from a given message handler.
I'm not particularly tied to MHL as a name exclusive to good message handling loops, but I can't think of a better name. When somebody tells me they have implemented code using a QMH my first thought is, "$%#! Now I get to spend the next two weeks inspecting their code and removing all the race conditions."
As I've tried to explain, even the name "QMH" violates the basic principles of writing a message handler that can be safely used as a component in a concurrent application. I want a name for message handling loops that rejects those techniques that are shown to be potentially thread unsafe. No macros. No self-messaging. No timeouts. No sequential dependencies. Selfish? Maybe. Beneficial to the community as a whole? I think so.
Again, not claiming your definition is wrong, just incomplete.
As I understand your definitions, QMHs do not have any concept of overall loop state--either in terms of data or behavior. However, each frame can persist information between calls but do not share information with each other. In other words, feedback loops can exist inside a frame, but not outside the case structure. QMHs also have the characteristic of no sequential dependencies between message handlers (which I interpret as each message handling frame completes all its responsibilities prior to the execution system exiting the frame) and frames do not self-send new messages.
On the other hand, QSM do have loop state, sequential dependencies, and may self-send new messages.
My question is simply me trying to better understand your definitions. What do you call those implementations that don't fall into either category?
-No loop state, sequential dependencies, self-sends messages.
-Has loop state, no sequential dependencies, no self-sent messages.
-etc.