Youssef Menjour
-
Posts
83 -
Joined
-
Last visited
-
Days Won
9
Youssef Menjour's Achievements
")





-
 Hello everyone, I’m looking for a precise answer regarding LabVIEW ↔ NI-DAQmx compatibility, because the official documentation is not entirely clear for recent hardware. We need to work with a CompactDAQ cDAQ-9183 chassis. According to NI’s documentation, this device is officially supported starting from NI-DAQmx 2024 Q4. Our current environment is LabVIEW 2020, and the customer may consider upgrading to LabVIEW 2022. However, the issue is that DAQmx 2024 Q4 does not seem to provide “Support for LabVIEW 2020”, and it is unclear whether it still supports LabVIEW 2022. The public DAQmx–LabVIEW compatibility table is not up to date for the newest driver versions, and the installer no longer clearly shows which LabVIEW versions are supported. My main question is therefore the following: 👉 How can we verify which version of LabVIEW is actually compatible with the specific NI-DAQmx version required by the cDAQ-9183? More specifically: The cDAQ-9183 requires NI-DAQmx 2024 Q4 or later. How can we know whether DAQmx 2024 Q4 still includes support for LabVIEW 2020 or LabVIEW 2022? The documentation does not state clearly which LabVIEW versions are supported by the newer DAQmx drivers. In other words: 👉 I want to know whether it is possible to use the cDAQ-9183 with LabVIEW 2020 — and if so, how? 👉 And I want to know the same thing for LabVIEW 2022. If anyone has an official reference, a compatibility matrix, or has already tested this combination in a real project, any insight would be greatly appreciated. Thank you in advance.
Hello everyone, I’m looking for a precise answer regarding LabVIEW ↔ NI-DAQmx compatibility, because the official documentation is not entirely clear for recent hardware. We need to work with a CompactDAQ cDAQ-9183 chassis. According to NI’s documentation, this device is officially supported starting from NI-DAQmx 2024 Q4. Our current environment is LabVIEW 2020, and the customer may consider upgrading to LabVIEW 2022. However, the issue is that DAQmx 2024 Q4 does not seem to provide “Support for LabVIEW 2020”, and it is unclear whether it still supports LabVIEW 2022. The public DAQmx–LabVIEW compatibility table is not up to date for the newest driver versions, and the installer no longer clearly shows which LabVIEW versions are supported. My main question is therefore the following: 👉 How can we verify which version of LabVIEW is actually compatible with the specific NI-DAQmx version required by the cDAQ-9183? More specifically: The cDAQ-9183 requires NI-DAQmx 2024 Q4 or later. How can we know whether DAQmx 2024 Q4 still includes support for LabVIEW 2020 or LabVIEW 2022? The documentation does not state clearly which LabVIEW versions are supported by the newer DAQmx drivers. In other words: 👉 I want to know whether it is possible to use the cDAQ-9183 with LabVIEW 2020 — and if so, how? 👉 And I want to know the same thing for LabVIEW 2022. If anyone has an official reference, a compatibility matrix, or has already tested this combination in a real project, any insight would be greatly appreciated. Thank you in advance. -
Youssef Menjour changed their profile photo
-
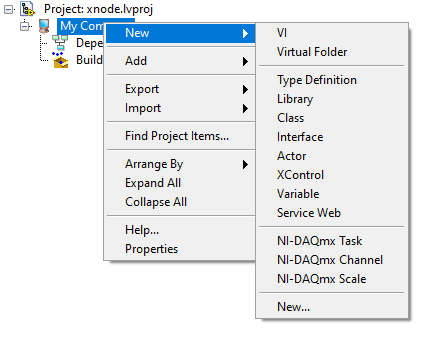
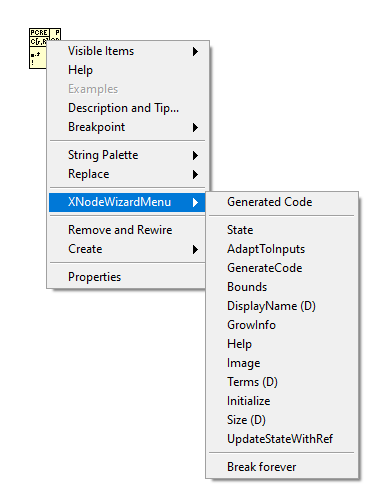
Here’s the message ready to copy-paste into the forum: Title: Enabling XNode development in LabVIEW 2020 – .ini flags Hello everyone, I’m trying to enable XNode development mode in LabVIEW 2020 64-bit. So far, I’ve added the following keys to my LabVIEW.ini file: Xnodewizardmenu=True XnodewizardMode=True XTraceXnode=True XNodeDebugWindow=True SuperSecretPrivateSpecialStuff=True XNodeDevelopment=True XNodeDevelopment_LabVIEWInternalTag=True I’m sure this is the correct .ini file because the XNodeWizardMenu does appear when I right-click on a VI (for example on Match Regular Expression.vi). However, in the Project Explorer the New menu does not show XNode (below XControl), which I was expecting. My questions are: Is there an additional .ini key required in LabVIEW 2020 to make New → XNode appear? Can someone explain what each of these flags actually activates? Has anyone managed to get the Project Explorer “New → XNode” option visible in LabVIEW 2020? Thanks!

-
We are still looking for beta testers to join the ongoing testing phase of SOTA, our unified development environment for deep learning in LabVIEW. Now in its 36th version, SOTA is designed for developers interested in exploring deep learning using graphical programming. If you're passionate about innovation and eager to shape the future of graphical deep learning, we would love to hear from you! 🚀 𝐉𝐨𝐢𝐧 𝐭𝐡𝐞 𝐋𝐚𝐛𝐕𝐈𝐄𝐖 𝐒𝐎𝐓𝐀 𝐁𝐞𝐭𝐚 𝐓𝐞𝐬𝐭𝐞𝐫 𝐏𝐫𝐨𝐠𝐫𝐚𝐦 𝐚𝐧𝐝 𝐒𝐡𝐚𝐩𝐞 𝐭𝐡𝐞 𝐅𝐮𝐭𝐮𝐫𝐞 𝐨𝐟 𝐀𝐈 𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐦𝐞𝐧𝐭! Are you passionate about artificial intelligence? Do you want to be part of a groundbreaking journey to revolutionize AI workflows? SOTA, the unified AI development platform, is looking for beta testers to explore its latest capabilities and provide valuable feedback. 𝐖𝐡𝐲 𝐉𝐨𝐢𝐧 𝐭𝐡𝐞 𝐒𝐎𝐓𝐀 𝐁𝐞𝐭𝐚 𝐏𝐫𝐨𝐠𝐫𝐚𝐦? Be the First to Explore: Get early access to the 64th version of SOTA, featuring powerful tools like the Deep Learning Toolkit and Computer Vision Toolkit. Collaborate and Innovate: Share your insights and ideas to help us refine and improve the platform. Experience Unmatched Simplicity: Discover how SOTA’s graphical programming language, ONNX interoperability, and optimized runtime simplify complex AI workflows. ⭐ 𝐖𝐡𝐚𝐭’𝐬 𝐢𝐧 𝐢𝐭 𝐟𝐨𝐫 𝐘𝐨𝐮? 𝐄𝐱𝐜𝐥𝐮𝐬𝐢𝐯𝐞 𝐀𝐜𝐜𝐞𝐬𝐬: Be part of an exclusive group shaping the next generation of AI tools. 𝐄𝐚𝐫𝐥𝐲 𝐈𝐧𝐧𝐨𝐯𝐚𝐭𝐢𝐨𝐧𝐬: Test cutting-edge features before they’re released to the public. 𝐃𝐢𝐫𝐞𝐜𝐭 𝐈𝐦𝐩𝐚𝐜𝐭: See your feedback implemented as part of SOTA’s evolution. 💡𝐖𝐡𝐨 𝐂𝐚𝐧 𝐀𝐩𝐩𝐥𝐲? Whether you're an engineer, researcher, or AI enthusiast, your voice matters. If you're curious, innovative, and ready to explore, we want you on board! 👉Contact us if you want to join the open beta! https://lnkd.in/dWrckRJV or hello@graiphic.io or PM Stay informed and follow us on our youtube channel ! 👉 https://lnkd.in/dmP49rCa Stay informed on our website ! 👉 https://www.graiphic.io
-
- 1
-

-
- deeplearning
- deep learning
- (and 3 more)
-
National instrument GITHUB repo NI/Linux
Youssef Menjour replied to Youssef Menjour's topic in LabVIEW General
Good morning Ha I hadn't seen this answer! I don't understand the point of putting NI Linux RT online? What's the point ? I just want to simply deploy my code to this target that has a GPU. IN fact what I want is to deploy LabVIEW code on my Jetson target. I don't want to install LabVIEW RT on my target, I just want to deploy my code as if I were on a machine. Is this possible on an Ubuntu Arm target as was done on Rasberry PI. The idea is to use the Jetson GPU for HAIBAL deployments. I asked NI but they didn't answer me. who could be our contact at NI ? -
National instrument GITHUB repo NI/Linux
Youssef Menjour replied to Youssef Menjour's topic in LabVIEW General
As i understood, we can install LabVIEW RT everywhere in case to know how to modify the linux kernel source code (open source) It's possible but it seems it mean to have strong knowledge in OS linux dev. We will start to work on it to deploy LabVIEW RT on jetson. New challenge accepted -
Hi everyone, Can someone explain to me what this repository is for? From the NI linux RT source code, can we consider, after hard development work, gateways to, for example, a LabVIEW deployment of RT code on a Jetson nano ? I would really like to understand what it is, thank you https://github.com/ni/linux?tab=readme-ov-file
-
Hi everyone, I would like modify a project build specification by using input only the path of the Lvproj. Is it possible ? I would like to change with a VI a destination directory of a Build Specification Thank you for your help
-
Actor framework - Substitute actor override
Youssef Menjour replied to Youssef Menjour's topic in LabVIEW General
Good morning I downloaded the famous state actor patern and clearly it explains absolutely nothing. Where can I find an example? What's the point ? Does anyone really know? There are no examples anywhere in the NI examples and this VI shows absolutely nothing How do we launch this switch actor? Where ? I don't understand the point of this VI? When hitchhiking, is the switch actor useful? (obviously no, since nowhere are the FIFO connections cut, the nesteds are not deleted in the actor who is going to be switched)
-
Actor framework - Substitute actor override
Youssef Menjour replied to Youssef Menjour's topic in LabVIEW General
J'ai téléchargé le fameux state actor patern et clairement il n'explique absolument rien. Ou puis je trouver un exemple ? A quoi ça sert ? Est ce que quelqu'un sait vraiment ? Il n'y a aucun exemples null part dans les exemple NI et ce VI ne montre absolument rien clear 274 / 5 000 Résultats de traduction Résultat de traduction Good morning I downloaded the famous state actor patern and clearly it explains absolutely nothing. Where can I find an example? What's the point ? Does anyone really know? There are no examples anywhere in the NI examples and this VI shows absolutely nothing -
Actor framework - Substitute actor override
Youssef Menjour replied to Youssef Menjour's topic in LabVIEW General
OK i'll check thank you -
Actor framework - Substitute actor override
Youssef Menjour replied to Youssef Menjour's topic in LabVIEW General
It's quite frustrating not to have a direct answer to my question and to be forced to dissect a package to understand. The simplest thing would have been to explain this override better. I'll go see but it's really not practical -
Actor framework - Substitute actor override
Youssef Menjour replied to Youssef Menjour's topic in LabVIEW General
I really need to understand how it works. Unfortunatelly there is few information on substitute actor override. Anyone able to help me ? -
Hi everybody, I'm trying to use in actor framework the substitute actor override but there is no example on internet. Is someone can provide me a simple example to understand it ? Thank you
-
Here's some examples of semantic segmentation with 𝐓𝐈𝐆𝐑 𝗟𝗮𝗯𝗩𝗜𝗘𝗪 𝐯𝐢𝐬𝐢𝐨𝐧 𝐭𝐨𝐨𝐥𝐤𝐢𝐭 (Available now for test) This is accomplished by utilizing a UNET architectural model in conjunction with a basic 𝗟𝗮𝗯𝗩𝗜𝗘𝗪 state machine architecture, showcasing how the HAIBAL, the LabVIEW deep learning toolkit by Graiphic toolkit's capabilities enable seamless integration of any model into practical applications with minimal effort. Visit us now --> www.graiphic.io 𝐓𝐈𝐆𝐑 website -->https://tigr.graiphic.io/ Download GIM and try 𝐓𝐈𝐆𝐑 𝗟𝗮𝗯𝗩𝗜𝗘𝗪 𝐯𝐢𝐬𝐢𝐨𝐧 𝐭𝐨𝐨𝐥𝐤𝐢𝐭 --> https://lnkd.in/eUtVumG2 Get started with TIGR --> https://lnkd.in/dssB-MS4
-
This video may not look like it, but for us it represents an enormous amount of effort, difficulty, sacrifice and financial means. It is with special emotion that we proudly unveil the upcoming major update for HAIBAL, the LabVIEW deep learning toolkit by Graiphic. In a few weeks, we will introduce a significant enhancement to our deep learning toolkit for LabVIEW. This update takes our tool to a new dimension by integrating a range of reinforcement learning algorithms: 𝐃𝐐𝐍, 𝐃𝐃𝐐𝐍, 𝐃𝐮𝐚𝐥 𝐃𝐐𝐍, 𝐃𝐮𝐚𝐥 𝐃𝐃𝐐𝐍, 𝐃𝐏𝐆, 𝐏𝐏𝐎, 𝐀𝟐𝐂, 𝐀𝟑𝐂, 𝐒𝐀𝐂, 𝐃𝐃𝐏𝐆 𝐚𝐧𝐝 𝐓𝐃𝟑. Naturally, this update will include practical, easy-to-use examples such as DOOM, MARIO, Ataris games and many more surprises will come along. (starcraft or not starcraft?) 👉🏼 Visit us now www.graiphic.io 👉🏼 Get started with TIGR vision toolkit https://lnkd.in/dssB-MS4 👉🏼 Get started with HAIBAL deep learning toolkit https://lnkd.in/e6cPn4Fq