Götz Becker
-
Posts
135 -
Joined
-
Last visited
-
Days Won
2
Götz Becker's Achievements
")
Newbie (1/14)
11
Reputation
-
-
 The typecast method will probably always be slower than the direct isNaN check, due to the buffer© of the typecast node. (http://lavag.org/topic/15187-inplace-typecast-possible/page__view__findpost__p__91471)
The typecast method will probably always be slower than the direct isNaN check, due to the buffer© of the typecast node. (http://lavag.org/topic/15187-inplace-typecast-possible/page__view__findpost__p__91471) -
Ah, damn I should have tested it better... thanks!
-
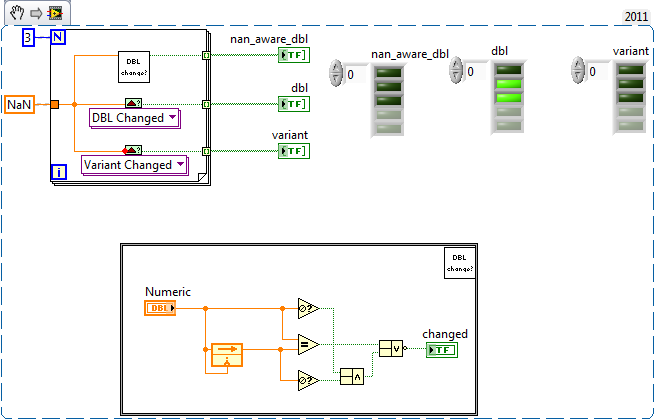
Had to finish some real work... :-) Here my proposal. data_changed_DBL_NaN_aware.vi (Sry about the feedback node... I just don't like the while loop SR any more.)

-
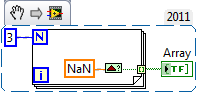
Sure it is... but for me, with my non native english knowledge, the documentation "...that will output a true if the data flowing into it has changed." reads as only a change will output a true. This includes proper NaN checking.
-
The Data Changed OpenG VI doesn't work with NaNs. Basically it lacks isNaN checking. Since it is documented as TRUE if the data changed, it should work for NaNs as well.
-
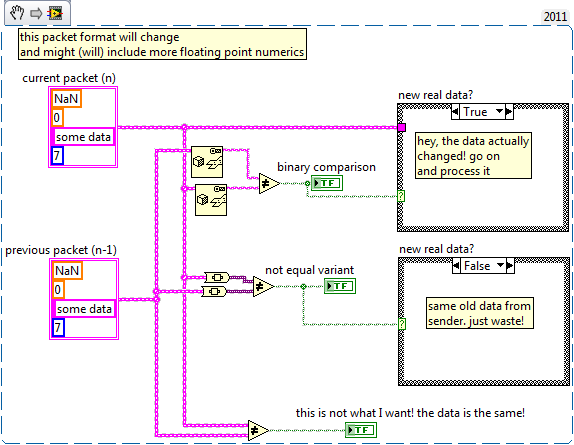
The data comes from a fixed set of subsystems, mostly LabVIEW-based. This code fragment comes from a proxy style application which tries to reduce load to the backend data storage (TCP connected, 400GB ringbuffer) in which itself is a fine grained isNaN check in the floating point transient recorder.
-
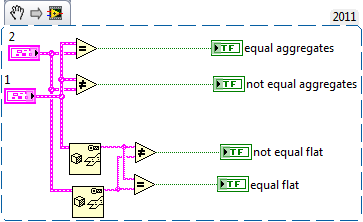
I updated my usecase example to clarify more what I am looking for: Basically I do want to compare the cluster raw contents against each other. The flatten to string works but I hope that it can be made more efficient and elegant. Updating a custom routine for all cluster elements when the cluster changes and implementing the isNaN for both sides is cumbersome and might be forgotten.
-
Hi, is there an easy way for checking a mixed cluster for equality, ignoring the rules for floating point comparison (NaNs)? I just want to check if the data I receive is new or not. My current idea is: Loosing type safety and the buffer allocation is for my current use case ok (slow and non RT), but I wonder if I miss something. Edit: A colleague mentioned that a "to variant" does the some "trick" but might be faster... I guess I'll have to benchmark a little.
-
[CR] Create_UDL_File_LV2010
Götz Becker replied to Prabhakant Patil's topic in Code Repository (Uncertified)
Why are all VIs password protected? -
file transfer using UDP protocol
Götz Becker replied to moralyan's topic in Remote Control, Monitoring and the Internet
The last part I don't understand. What do you mean with "graph" in respect to the TDMS file structure? From my understanding a error rate of >0% _will_ always result in some broken data. TDMS has no integrated consistency checks, as long as the TDMS segment headers survive, the whole file will look correct when opened. Nothing I would want in any form of production quality code/system. -
file transfer using UDP protocol
Götz Becker replied to moralyan's topic in Remote Control, Monitoring and the Internet
I still don't see why you want to build the file transfer on UDP, but I could imagine that if you know your packet loss rates and patterns, you could build a FEC (like RS codes) to counter the losses. At least it would be a fun thing to try -
file transfer using UDP protocol
Götz Becker replied to moralyan's topic in Remote Control, Monitoring and the Internet
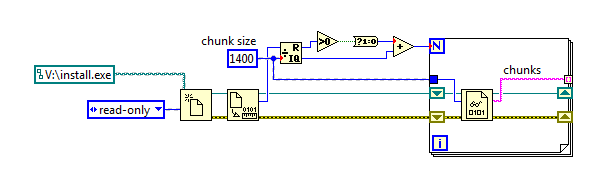
One way of getting the chunks could be:
-
[CR] GPower toolsets package
Götz Becker replied to Steen Schmidt's topic in Code Repository (Uncertified)
The "owner" is still the VI and it gets cleaned up no matter what. This can lead to a race condition which may lead to lost writes. I hacked together a small nutshell (LV2011) to demonstrate the problem. test_vi.vi tcp_server.vi tcp_conn_server.vi As long as you know all variable names in the static part and access them at first there, this is not a problem. But this detail can be easily forgotten and when such an app grows, it could be a nightmare to debug. -
[CR] GPower toolsets package
Götz Becker replied to Steen Schmidt's topic in Code Repository (Uncertified)
The dynamic nature of VIRegister has a drawback when used with dynamic code. Since the obtain refnum is done directly done, the potentially new global refnum has the lifetime of the calling VI references. e.g. use this with a dynamic TCP handler and created a new named register inside the dynamically instanced VIs. This new ref will be invalid when the instanced VI goes idle. This can produce some very hard to find bugs if not all references are obtained in a permanent running VI!