

eberaud
-
Posts
297 -
Joined
-
Last visited
-
Days Won
10
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by eberaud
-
-
I need LVFileRefs as a composite object (instead of that data living inside LVFile) since New starts by instantiating an LVFileRefs object before New can decide which child to instantiate
It looks like you need a Factory pattern. As soon as you know the type, create the proper child, it seems to me that you don't need to store the type as an enum anywhere.
-
Or you can get the fonts using the Windows registry.
Beautiful! Thanks for sharing.
-
Thats not weird; thats a lemon. Send it back and get a new one.
Well if it happens again I'll talk to my IT guy! (that's my work laptop, not my personal one)
-
Wow while troubleshooting some code I noticed that calling the "Generate occurrence" function always returns the same reference if used in a loop or in a SubVI that you call several times. The only way to get different references is to physically place several instances of it on the BD.
Is that the expected behavior? And in a more general way, what do you think of occurrences? I like them because they are so light and simple. I use them when I only have one "sender" and one "consumer" and that I don't need to pass any data...
Edit: A glance at the LabVIEW Help indicated that indeed this is the normal behavior. I'm still interested in knowing what are your thoughts on occurrences...
-
I'm coming to NI Week and LAVA BBQ for the 1st time!
-
 1
1
-
-
I was fortunately able to open the VI in a more recent version of LabVIEW (I think that the corrupted VI was in LV2011 and I opened it with LV2014) and then saving it back to 2011 did the trick and allowed me to recover all of my changes.
Unfortunately LabVIEW 2014 also sees it as corrupted. I guess my VI is even more corrupted than yours

What's weird about the BSOD is that it's on a laptop that is brand new, and I never connected it to any hardware except the usual mouse and keyboard...
-
You're right, Windows does keep previous versions but on my PC it seems it only makes a backup every 8 days. And my VI was more recent than that. However I did restore my LabVIEW.ini after you advised me to do so and that did the trick to restore my environment

-
Thanks ShaunR,
I restarted the coding of the VI from scratch and after 4 hours it's already back to where it was before the BSOD. I had the code printed on my memory... I'll still have a look at your link for my personal knowledge base...
I feel much better now. The new code is also cleaner than the original one...

And yes, it looks like it still happens. I'm running LV2011 on Windows 7.
Edit: My LabVIEW environment really had a kind of reset. I lost all my preferences about palettes and so on...
-
Yesterday I was working on a new VI that I created few days ago, when a Blue Screen Of Death happened. When I restarted the PC and LabVIEW, I was amazed to see that LabVIEW's startup window didn't remember any of my recent projects and recent files. It seems that the BSOD did something pretty bad to my LabVIEW install. So I loaded my project manually, only to find out that LabVIEW can't open my new VI because it's corrupted.
Unfortunately I had not yet performed any commit of this VI to our repository, so I pretty much lost few days of work. I have the auto-save enabled so I had a look in the LVAutoSave folder, but it was almost empty, and my VI was not there.
At this point I'll take any suggestion as to what I can do to recover my VI!! Since it's a binary file, I can't open it in a text editor and see if I can manually fix it...
If you don't have any suggestion, I will also take words of compassion! You can imagine I pretty much want to do that right now:

Thanks!
-
Just tested it within my code. It works! But what made it work is setting the X-position to 0. I removed the update of the Y-scale property of the cursor and it still works. On the other hand, if I leave the Y-scale property and remove the X-position of the cursor, the fix no longer works.
It's strange, I would expect the X-position to be useful in Free mode only, since I use the Index property to specify the point of the plot to snap the cursor to...
Anyway, thanks again Porter, this bug had been bothering us for weeks...
-
Thanks Porter that looks very promising!
I haven't found time to try it inside my code yet but will do very soon and will get back to you.
Cheers
-
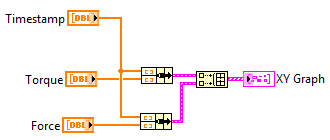
Hi,
My graph is a XY Graph but the X-scale is just the time. I use the XY Graph in order to define the time stamp of each sample. I use cursors that I snap to the plots in order to display the plots' names. Everything works well when all the plots are displayed against Y-scale 0. But when switching a plot to Y-scale 1, the associated cursor keeps moving like if its plot was still on Y-scale 0. Simply dragging the cursor with the mouse a little bit snaps it to its plot properly (value displayed against Y-scale 1).
I tried using the Cursor.YScale property of the cursor but it doesn't seem to help.
Has any of you encounter this issue?
I am using LV 2011.
Thanks!
-
If the time interval between each sample can vary, you definitely want a XY graph, not a waveform. The best way I know is to create a cluster of 2 array with the same number of elements: one for the X values (timestamp in your case), and one for the Y values (force or torque in your case).
You can feed this cluster to a XY graph directly. If you have more than one Y (in your case you have forces and torque), create several of these clusters and combine them in an array. The XY graph will accept this array. See attached picture.
By the way this is not the appropriate location for this kind of post. Could someone please move it? Thanks

-
My pet peeve is the numeric control. I would love to have an "update value while typing" property like for string controls. When the user type a value and then click on a button that triggers a read of the value, we get the old value. We work around this by forcing a the control to lose the key focus first, but that's less than ideal...
-
Dear all,
My company, Greenlight Innovation, is hiring a LabVIEW developer to join the software team. Please find the job description here.
We are located in beautiful Vancouver, British Columbia, Canada!
-
-
At my work we let LabVIEW auto-increment the build number, but we manually reset it to 0 each time we increment another index. For example, if I fix a bug present in version 1.2.3.12, the next build I make is 1.2.4.0. Then in my SVN commit I put "Version 1.2.4.0" as a comment, which allows me to retrieve the SVN version by looking at the SVN log. If I forgot to include something in the build or to modify something that shouldn't involve an update of the first 3 indexes, then only the build number gets incremented, just to make sure each build has a unique build number (1.2.4.1 in my example).
-
Thank you all for your feedback. I believe using strings require one thing at least: being diligent when naming the states correctly at their creation, since renaming them would require modifying several string constants --> bigger effort and error prone.
I'll try to use it in my next state machine!

-
I downloaded the JKI state machine toolkit and it's quite neat. For eons, I have been using state machines following a very similar structure, but always with enums instead of strings. In simple state machine, each state would define the next one (no queue), and in more complex ones, a queue would be used to allow some states to enqueue several ones (and some wouldn't enqueue anything). But always with an enum or a queue of enums, since it seemed this would prevent typos, and allow renaming a state at only one place (the enum typedef).
However I am tempted to make the switch since I see the value in using a tool used by other advanced developer. Where do you stand on this? Is JKI's string-based design the best way for your state machines?
Thanks
Emmanuel
-
Hi Francois,
Yes it did fix it! (I'm using 2014 right now, but still 2011 in general)
I had to restart VPIM to get rid of the conflict icon though. But now everything looks good! Thanks
-
1
-
-
I just installed the control addon v1.3.0.12 (I had never installed any previous version) and I get this conflict:
This Package Conflicts with these other packages:
lava_lib_ui_tools_control_class_addon >= 1.0.0.0Do you know what this means and how to fix it?Thanks -
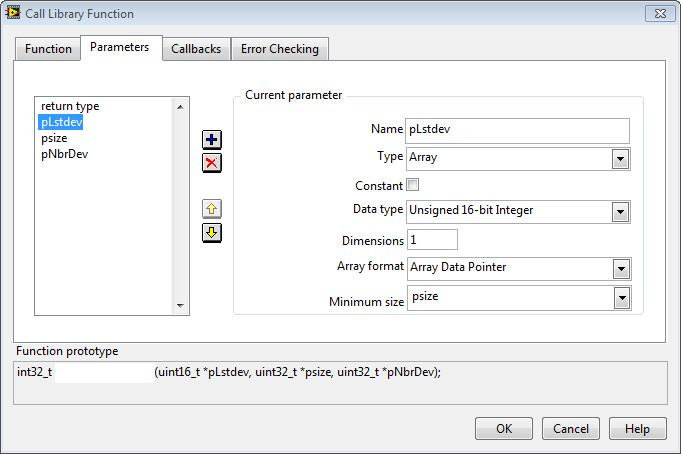
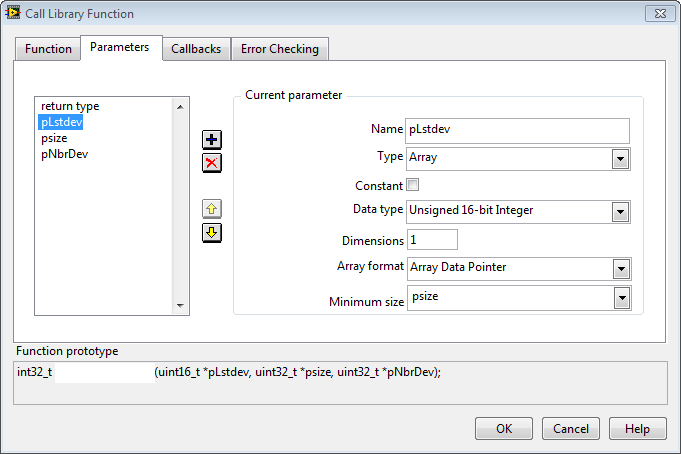
This can't be! The DLL knows nothing about if the caller provides a byte buffer or a uInt16 array buffer and conseqently can't interpret the pSize parameter differently.
Fair enough. I probably misinterpreted my tests. I define the minimum size of the array to be equal to psize in the call declaration, this is probably what influences the results, not the DLL itself. Does that make more sense?
-
I just tried declaring the string parameter as a U16 array instead of a U8. In this case it does treat the psize input as being the number of characters, not the number of bytes. The reason why it seems to be the number of bytes is that the string was defined as an array of U8.
As you said Rolfk I don't need to decimate anymore, I directly feed the U16 array into the convert bytes to string function. I get a coercion dot of course since it needs to be forced into a U8 array first, but that's fine, it's what we want...
OK Shaun, I will then increase the psize to be pretty big (maybe 500 characters). I expect it always to be big enough.
There is really a lot to know to be able to call DLL properly in LabVIEW. I will do some googling of course, but do you know what is the best source to learn this?
Side-note: GPF = General Protection Fault?
-
To be precise, the string is encoded in UTF-16 (or maybe UCS2). There are other Unicode encodings.
You're right, it is likely UTF-16.
If it crashes when you use your Pascal string approach, that's probably because LabVIEW read the first character, interpreted is as a (very long) length, and then tried to read beyond the end of the string (into memory that it's not allowed to read).
It actually crashes in general, not just with Pascal strings, and not just with this function. Even when I open the LabVIEW examples provided by the DLL manufacturer, it regularly works (the dll returns values as expected) and when the VI stops, LabVIEW crashes...
Since your "String" contains embedded 0 bytes, you can not let LabVIEW treat it as a string but instead have to tell it to treat it as binary data. And a binary string is simply an array of bytes (or in this specific case possibly an array of uInt16) and since it is a C pointer you have to pass the array as an Array Data Pointer.
It worked!!!
Array of U8 and Array Data Pointer did the trick. I can't thank you enough for saving me from hours of coffee+headache pills combo!Your DLL programmer is free to require a minimum buffer size on entry and ignore pSize altogether, or treat pSize as number of bytes, or even number of apples if he likes. This information must be documented in the function documentation in prosa text and can not be specified in the header file in any way.
So as it turns out the psize I wire in has to be the number of bytes of the allocated buffer but the psize returned is the number of characters, so half the number of "meaningful" bytes that it returns. That's ok, as long as I know how it works, it's easy to adapt the code to it.
If your array only contains values up to and including 127 you can simply convert them to an U8 byte and then convert the resulting byte array to a LabVIEW string.
Yes all the characters are less than 127 so I just decimated the array to keep all the even indexes (all the odd indexes being null characters) and then converted this array of bytes into a string.
Shaun you have a good point. I could always guarantee that the string will fit by feeding a huge psize, but that's probably a waste of memory allocation in most cases, so what I will do is feed a reasonable psize, and then compare it to the returned psize. If the comparison shows that some characters are missing, I will call the function a second time, this time with the exact number of expected characters since I know it.
Thank you all for your help again!
(I'm pretty sure I'll run into more DLL issues VERY soon)
Feeding composite objects back into parent with a DVR?
in Object-Oriented Programming
Posted
Just an idea: do you really need the LVFileRefs object? I feel like in your situation I would have put all the fields (path, refnum,...) in the LVFile object directly. Then each child object can have both the fields of the child class, and the fields of the parent class (LVFile). Obvisously you have spent much more time thinking of this specific situation than I did so my comments might miss the target, I guess I'm trying to brainstorm some ideas here