

Steen Schmidt
-
Posts
156 -
Joined
-
Last visited
-
Days Won
8
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Steen Schmidt
-
-
I've been on vacation and I haven't looked at the VIRegister library at all, but I did want to share how our team stops loops.
All of our code has something like the following architecture, and all loops are stopped by destroying a reference to a queue or notifier, which is a pattern we call "scuttling". It doesn't matter whether the wait functions have timeouts or not, it works immediately and all you have to do is filter out the error (error 1 or error 1122) that it throws. Usually the code is split into many VIs, but as long as you make sure that any queue or notifier reference is eventually destroyed (we try always to do that at in the same VI as the creation), then all the loops will stop.
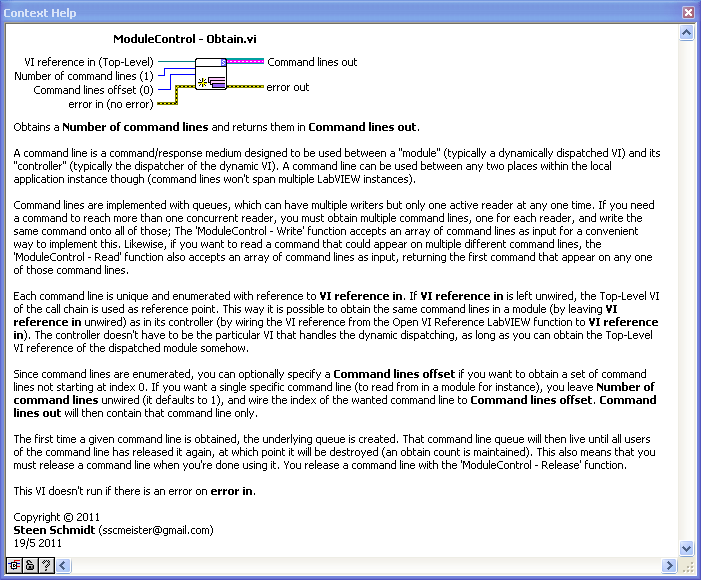
That's a very robust way of sharing data, I use that alot too. In fact I have a toolset for stuff like this, called ModuleControl:
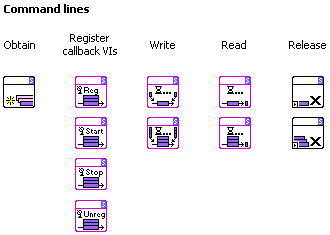
I call these queues "command lines", since they convey commands (which can bring data with them, are timestamped and so on). The read-function provide a Command line destroyed? output that basically wraps the queue destroyed event as you use. This part is actually quite tricky when handling more than one queue at a time, it involves many of the issues Stephen mentions in his Alpha->Beta prioritized communication posts. A bit of the VI documentation for ModuleControl:
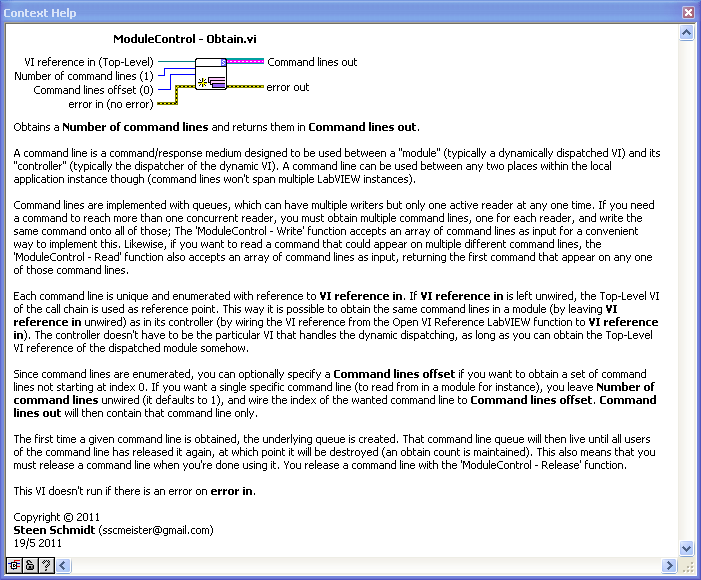
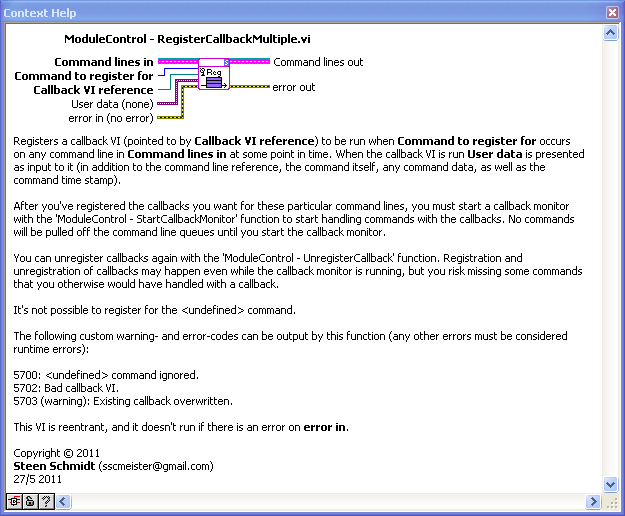

Cheers,
Steen
-
Ok, alot of discussion went on before I got back to this - super
 .
.(On named queues):
NI may not discourange their use, but there are many of us (admittedly a minority) who believe they are a quick solution instead of a good solution. Here's a quote taken from Stephen's excellent article, The Decisions Behind the Design:
(Quote from Stephen: It is hard to guarantee data consistency when you cannot limit changes to the data):
As is usually the case when I disagree with Stephen, over time I began to see the why until eventually I understood he was right. The guarantee of data consistency pays off in spades in my ability to understand and debug systems. Any kind of globally available data--named queues, functional globals, globals, DVRs, etc.--breaks that guarantee to some extent.
When I'm digging through someone else's code and run into those constructs, I know the amount of work I need to do to understand the system as a whole has just increased--probably significantly. There's no longer a queue acting as a "single point of entry" for commands to the loop. Instead, I've got this data that is being magically changed somewhere else (possibly in many places) in the application. It is usually much harder to figure out how that component interacts with the other components in the system. Named queues are especially bad. We have some control over the scope of the other constructs and can limit where they're used, but once we create a named queue there's no way to limit who interacts with it.
I agree in principle with what you're stating, and have had my share of apps suffering from entanglement - but I don't think it's all as black and white as you make it sound.
There is a duality in "hiding" and "encapsulating" functionality. A subVI does both, as does a LabVIEW class.
LabVIEW is evolving into a language more and more devoid of wires; First you bundled stuff together, then we magically wafted data off into the FP terminals of dynamically dispatched VIs, then we got events, and now we have all sorts of wire-less variables like Shared Variables. Everytime we use a shift register or feedback node we have the potential for enheriting data that others have changed - this didn't get any better with the introduction of shared reentrancy. My point is that I wouldn't dispense with any of this. What other people can or can't comprehend and what they might make a mess of, isn't my concern. As long as I ensure my application or toolset works as intended, I will happily use 5 references when the alternative is a gazillion wires. And when I need to make sure some data stays verbatim, I'll of course make sure it's transferred by value.
Therefore, the difference in my mind between a named and an unnamed queue is convenience. Queues are very flexible, as we agree on, but unnamed queues have the built-in limitation that you have to wire the refnum to all your users. And getting a refnum to a dynamically dispatched VI can't be done by wire. All a named queue does differently is to link its refnum to another static refnum (the name). When I keep that name secret, no one else is going to change my data, but I as developer know the name and can pull my shared data from Hammer space when I want to.
Inside my application it's my responsibility to maintain modularization to ensure maintainability and testability. I do that by having several hierarchies of communication - it looks a bit like your "mediator" tree. From the top there is typically a single command channel going out to each module. Then each module might have one or more internal communication channels for each sub-component. The need for more than one channel is typically tied to prioritization as Stephen highlights (so I'm thinking in parallel about a good architecture for that). Down at the lowest level I might use flags (or now VIRegisters) to signal to the individual structures that they must do something simple, like stopping (just as Shaun favorizes). But these "flags" don't span an entire application, they are created, used, and destroyed inside an isolated module. There isn't any replacement for sharing data (by reference) when you want to share data (a common signal). I can't use by-value for this.
So regarding references; the issue seems to boil down to if the reference is public or private. Isn't that it? If you keep the scope small enough, you can guarentee even the most complex tool will work.
Regarding your (very good) Data logger/Data collection analogy I couldn't agree more. But application development is always about compromise. It seems to be a rule that whenever you improve encapsulation you also add weight (system load, latency etc.) to your application. 99 out of a 100 times I tend to favor encapsulation and abstraction though, as computers get faster, and I trust I can always optimize my way out of any performance deficiency
 . But if every operation gets absolutely abstract the code would be very heavy to run, not to mention extremely hard to understand. The magic happens when you get the abstractions just right, so your application runs on air, it takes a wizard to shoot your integrity out of the water, while a freshman still understands what happens. And one case needs some tools while another case needs other tools to achieve that. There are many ways to do it wrong, but I still believe there are also many ways do it right.
. But if every operation gets absolutely abstract the code would be very heavy to run, not to mention extremely hard to understand. The magic happens when you get the abstractions just right, so your application runs on air, it takes a wizard to shoot your integrity out of the water, while a freshman still understands what happens. And one case needs some tools while another case needs other tools to achieve that. There are many ways to do it wrong, but I still believe there are also many ways do it right.Cheers,
Steen
-
Or my favorite of each "module" has a queue linked to the VI instance name. To close all dependents, you only need to list all VI names and poke...[snip]
That is basically what VIRegisters are. And exactly the use case that initiated me making AutoQueues, and wrapping a couple of those in a polyVI --> VIRegister. But it's not good style, as you're spawning queues by reference this way, Shaun
 . But you must admit it's convenient...
. But you must admit it's convenient...Cheers,
Steen
-
Thanks for the update
 . One first comment:
. One first comment: Calling the same node with varying register names works now, but it is very slow.
If you use a variant to store and look up the index of requested queue (instead of using the standard search function) the use of the cache will be much quicker.
VIRegister was never intended as a lookup-table, it will always be much slower to look for the correct queue instead of using the same one every time. Even supporting multiple register access through the same node has lowered best case performance from almost 2,000,000 reads/s (on my laptop) to 700,000 reads/s. Accessing 10 registers in a loop lowers performance to around 400,000 reads/s.
That aside, how many different registers are you reading with the same node? 1000 lowers performance to a crawling 9,000 reads/s on my machine, but I'd consider that seriously beyond the intent of the toolset. But anyways, you are doing something you can't do with a local variable.
I assume you mean variant attributes, taking advantage of the binary search instead of the linear search of Search 1D Array? That will only be beneficial if we're talking about a serious number of different registers. The major bottleneck is typecasting the Scope VI refnum anyway, so I wouldn't dare to guess at which number of registers break-even is, and I wouldn't want to sacrifice static register name performance to get better dynamic name performance.
What I have definetely learned though is that LabVIEW sucks majorly when implementing polymorphism. I don't think I'll ever want to change anything in VIRegister again, I'm fed up with making the same VIs over and over again. I have to copy and change icons too, but have opted to have the same VI Description for all instances, or else I wouldn't have finished v1.1 yet. In other languages it's so easy to make function overrides, but in LabVIEW each and every instance has be be implemented 100%. It takes 5-10 minutes to get to an improved version of a VIRegister instance, and then literally days of programming instead of a couple more minutes before all the instances are done. It's way beyond pathetic.
Cheers,
Steen
-
Hi.
Version 1.1 of VIRegister is now ready for download:
Version changes from v1.0:
- Removed the write- and read-functions without error terminals.
- Removed type-dependency from VIRegisters, so it's no longer possible to have two different VIRegister types with the same name.
- Added support for using the same VIRegister function with varying names and/or scope VI refnums (in a loop for instance).
- Improved read performance when no write has yet been performed.
- Added array of path to supported data types.
- Updated the polymorphic 'VIRegister - Write.vi' to adapt to input.
- Added 'VIRegister - Release.vi'.
Cheers,
Steen
-
 1
1
-
-
Hi Steen,
I totally agree with you about the limitations of Shared Variables and about the disappointing support from NI regarding SVs. However, I haven't given up on them quite yet. Actually, the majority of our systems are still designed with SVs as the main tool for intra-process (and extra-process) signalling, and I must say they work really well.
I design data acquisition and control systems for thermal vacuum chambers that are used to perform space simulation. Tests can be up to one month long (24/7) but everything happens relatively slowly. The acquisition rate of our CompactRIOs is 1Hz and losing a reading once in a while is not an issue. Also, the outputs can take a couple seconds to react without causing problems. Finally, data loggers that record hundreds of temperature readings are queried only once every 10 seconds. In this environment, Shared Variables with the DSC module and a Citadel database can be an excellent solution, especially because they benefit from the power of the Distributed System Manager. When we consider other designs, like VIRegister, the DSM is the factor that tips the scale in favour of using Shared Variables.
Having said that, I don't see anything wrong with VIRegister and I will consider it next time I design a high throughput application (yes, we do have some of those as well
).Regards,
LP.
Hi LP.
It's not my intention to turn this into a flamewar against SVs. I sincerely hope the kinks will get ironed out. NI is putting a lot of effort into making SVs better at least, so I'm certain we'll see big improvements also in the next several LabVIEW releases. SVs, especially network enabled ones, are very powerful when they work. My concern isn't performance as any technology has a performance envelope - I'm disappointed that NI didn't disclose the full monty about the expected performance envelope when we struggled so hard to make SVs work in streaming applications (our typical Real-Time application will need to stream 15-30 Mbytes/s, often distributed on several RT-targets). CIM Industrial Systems is one of the biggest NI integrators out there, so I'd expected more honesty. Now I believe we have a good idea about that performance envelope, we have afterall probably field tested SVs for 5-10,000 hours
. No, my real concern is the SVs tendency to undeploy themselves when we're pushing their limits. And it's not possible to recover from that mode of failure without human interaction, simply because we cannot redeploy an SV-lib from the Real-Time system itself. LabVIEW for Desktop can, but not RT. That's a risk I can't present with a straight face to our customers. And I agree, the DSM is a great tool!Regarding VIRegisters please note that this is a lossy register. More like a global variable than a buffered Shared Variable. I'm looking into making a buffered VIRegister, where all updates are receieved by all readers, but it's quite complicated if I do not want to have a central storage like the SVE. It'd be very simple to enable buffering in the CVT toolset, since you here have the central storage (an FG), but I don't want to go that way. That'd be too straightforward, and we know straightforwardness in implementation is inverse proportional to performance
.A replacement for network enabled SVs could be TCPIP-Link (minus the control binding feature and the integration with DSM, at least for now), but that's a different story.
Cheers,
Steen
-
Almost there with v1.1 (only need to update the documentation):

And now I'm sick and tired of polymorphic VIs. I must've edited a thousand almost identical VIs the last two weeks
 .
.Cheers,
Steen
-
- Popular Post
In the past I have bought into the whole NI DSC/NSV technology for my cRIO based SCADA applications. I really like the SVE Publish Subscribe Protocol and the all the built-in features like NSV-NSV and NSV-LV control binding as well as the Distributed System Manager and DSC Citadel data logging. The problem is that it is a closed system, for example even though the SVE supports SV events, in LabVIEW this functionality is not exposed and you have to buy the DSC just to get such a basic capability. Also NSV's are cpu intensive, if you wanted to use them to emulate a CVT then you will hit the cpu% ceiling rapidly. I think, at least on the read side, the SVE could offer a more efficient interface for getting current NSV data. I think in the future I will consider an open tcpip based architecture.
It's quite a shame really, because Shared Variables held such a promise, but we use them as little as we can get away with now. We've been burned repeatedly by their shortcomings, and I feel we've been let down by NI Support when we've tried to get issues resolved. Issues that still carry several CARs around, like how every Shared Variable in an SV-lib inherits the error message from any of the member-SVs to have experienced a buffer overflow for instance - such an error will emerge from all the SV-nodes when any single node experiences the error. NI have known about that for years now, but won't fix it. And the update rate performance specifications aren't transferable to real life. SVs are quite limited in regards to dynamic IPs - we use DataSocket to connect to SVs on a target with dynamic IP, but DataSocket holds its own bag of problems (needing root loop to execute), and it's not truely flexible enough anyway. A Real-Time application can't deploy SVs on its own programmatically etc.
I also once saw needing the DSC module for SV event-support as a cheap shot at first, but there will always be differentiation in features between product package levels. Coupling SVs with events yourself isn't that hard, and even if you need the DSC module (the tag-engine for instance), it's not that expensive. Many of our projects carry multi-million dollar budgets anyway, so a few bucks for the DSC-module won't kill anybody. But losing data will.
We've for instance battled heavily with SVs undeploying themselves on our PXI targets under heavy load, without anyone being able to come up with an explanation. We've had NI application engineers look at it over the course of about 2 years - no ideas. And then at this year's CLA Summit an NI guy (don't remember who) spoke out loud that Shared Variables never were designed for streaming, they don't work reliably for that. Use Network Streams instead. Well, thanks for that, except that message comes 3 years too late. And Network Streams use the SVE as well, so I can't trust them either.
I started TCPIP-Link because we no longer can live with SVs, but we need the functionality. Now TCPIP-Link will be used for all our network communication. If the distribution of TCPIP-Link follow the rest of CIMs toolset-policy (with a select few exceptions), it will be available with full source code included. But I'm not sure that'll be the case.
Even if NI don't adopt TCPIP-Link, and even if CIM never release it for external use (I can't see both not happening, but you never know), I can always publish a video on Youtube where I pit SVs and Network Streams against TCPIP-Link - who'll finish first when the task is to deploy the network data transfer functionality to a cRIO, and get 10 Gigs of data streamed of it without error
 .
.But there isn't much debate coming off VIRegisters in this thread, is there? Did everybody go on holliday?
Cheers,
Steen
-
4
-
Hi Steen,
Curious to know... what is tcpip-link? Sounds like some cool inter process messaging architecture.
It is
 . It's basically a TCP/IP based messaging toolset that I've spent the last 1½ years developing. I'm the architect and only developer on it, but my employer owns (most of) it. I spoke with Eli Kerry about it at the CLA Summit, and it might be presented to NI at NI Week if we manage to get our heads around what we want to do with it. But as it's not in the public domain I unfortunately can't share any code really. But this is what TCPIP-Link is (I'm probably forgetting some features):
. It's basically a TCP/IP based messaging toolset that I've spent the last 1½ years developing. I'm the architect and only developer on it, but my employer owns (most of) it. I spoke with Eli Kerry about it at the CLA Summit, and it might be presented to NI at NI Week if we manage to get our heads around what we want to do with it. But as it's not in the public domain I unfortunately can't share any code really. But this is what TCPIP-Link is (I'm probably forgetting some features):- A multi-connect server and single-connect client that maintains persistent connections with each other. That means they connect, and if the connection breaks they stay up and attempt to reconnect until the world ends (or until you stop one of the end-points ).
- You can have any number of TCPIP-Link servers and clients running in your LabVIEW instance at a time.
- Both server and client support TCP/IP connection with other TCPIP-Link parties (LabVIEW), as well as non-TCPIP-Link parties (LabVIEW or anything else, HW or SW). So you have a toolset for persistent connections with anything speaking TCP/IP basically.
- Outgoing messages can be transmitted using one of four schemes: confirmation-of-transmission (no acknowledge, just ack that the message went into the transmit-buffer without error), confirmation-of-arrival (TCPIP-Link at the other end acknowledges the reception; happens automatically), confirmation-of-delivery (you in the receiving application acknowledges reception; is done with the TCPIP-Link API, the message tells you if it needs COD-ack), and a buffered streaming mode.
- The streaming mode works a bit like Shared Variables, but without the weight of the SVE. The user can set up the following parameters per connection: Buffer expiration time (if the buffer doesn't fill, it'll be transmitted anyway after this period of time), Buffer size (the buffer will be transmitted when it reaches this size), Minimum packet gap (specifies minimum idle time on the transmission line, especially useful if you send large packets and don't want to hog the line), Maximum packet size (packets are split into this size if they exceed it), and Purge timeout (how long time will the buffer be maintained if the connection is lost, before it's purged).
- You transmit data through write-nodes, and receive data by subscribing to events.
- Subscribable system-events are available to tell you about connects/disconnects etc.
- A log is maintained for each connection, you can read the log when you want or you can subscribe to log-events. The log holds the last 500 system eventsfor each connection (Connection, ConnectionAttempt, Disconnection, LinkLifeBegin, LinkLifeEnd, LinkStateChange, ModuleLifeBegin, ModuleLifeEnd, ModuleStateChange etc.) as well as the last 500 errors and warnings.
- The underlying protocol, besides persistence, utilizes framing and byte-stuffing to ensure data integrity. 12 different telegram types are used, among which is a KeepAlive telegram that discover congestion or disconnects that otherwise wouldn't propagate into LabVIEW. If an active network device exist between you and your peer, LabVIEW won't tell you if the peer disconnected by mistake. If you and your peer have a switch between you for instance, your TCP/IP-connection in LabVIEW stays valid even if the network cable is disconnected from your peer's NIC - but no messages will get through. TCPIP-Link will discover this scenario and notify you, close the sockets down, and go into reconnect-mode.
- TCPIP-Link of course works on localhost as well, but it's clever enough to skip TCP/IP if you communicate within the same LV-instance, in which case the events are generated directly (you can force TCPIP-Link to use the TCP/IP-stack anyway in this case though, if you want to).
- Something like 20 or 30 networking and application related LabVIEW errors are handled transparently inside all components of TCPIP-Link, so it won't wimp out on all the small wrenches that TCP-connections throw into your gears. You can read about most of what happens in the warning log if you care though (error 42 anyone? Oh, we're hitting the driver too hard. Error 62? Wait, I thought it should be 66? No, not on Real-Time etc.).
- The API will let you discover running TCPIP-Link parties on the network (UDP multicast to an InformationServer on each LV-instance, configurable subnet time-to-live and timeout). Servers and clients can be configured individually as Hidden to remain from discovery in this way though.
- Traffic data is available for each connection, mostly stuff like line-load, payload ratio and such.
It's about 400 VIs, but when you get your connections up and running (which isn't harder than dropping a StartServer or StartClient node and wire an IP-address to it) the performance is 90-95% of the best you (I) can get through the most raw TCP/IP-implementation in LabVIEW. And such a basic implementation (TCP Write and TCP Read) leaves a bit to be desired, if the above feature list is what you need
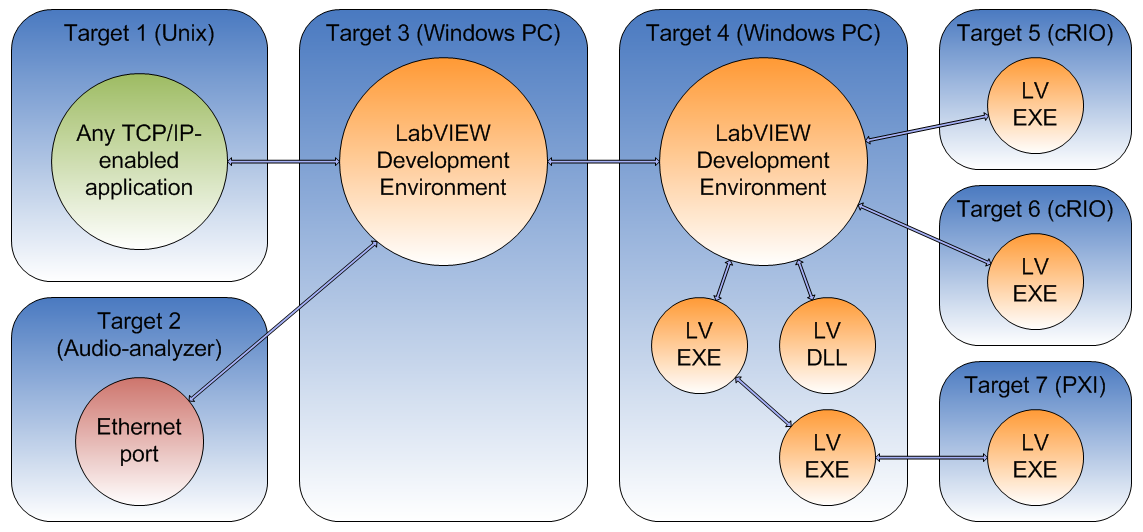
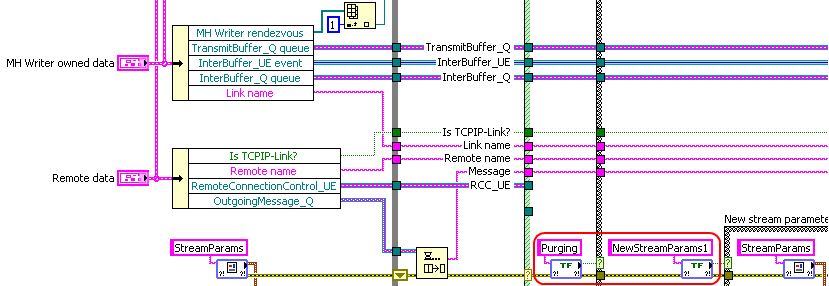
.We (CIM Industrial Systems) use TCPIP-Link in measurement networks to enable cRIOs to persistently stay connected to their host 24/7 for instance. I'm currently pondering implementing stuff like adapter-teaming (bundling several NICs into one virtual connection for redundancy and higher bandwidth) as well as data encryption. Here's a connection diagram example from the user guide (arrows are TCPIP-Link connections):
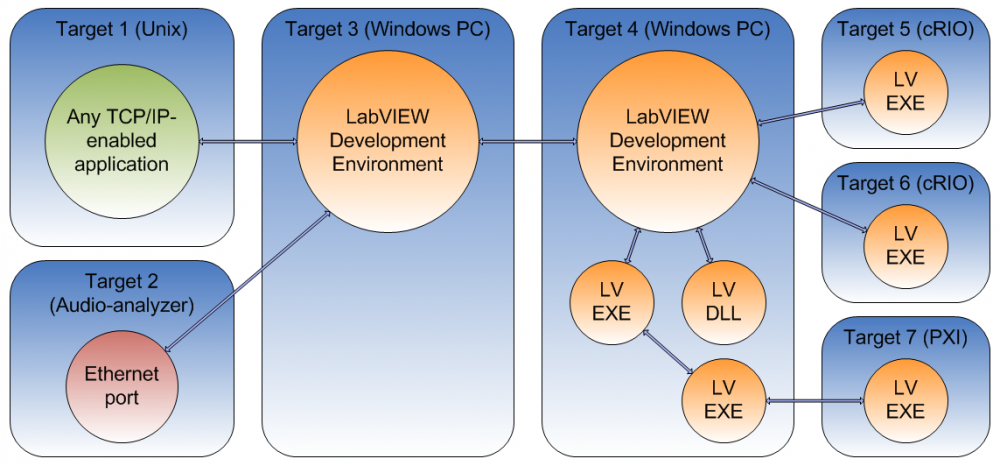
Cheers,
Steen
-
1
- A multi-connect server and single-connect client that maintains persistent connections with each other. That means they connect, and if the connection breaks they stay up and attempt to reconnect until the world ends (or until you stop one of the end-points
-
I have started a new topic in the Application Design & Architecture group where we might be able to discuss this in more general terms:
http://lavag.org/topic/14494-intra-process-signalling-was-viregister/
Cheers,
Steen
-
Hi.
This discussion is carried over from the Code-In-Development topic "VIRegister" since it developed into a more general discussion of the sanity of using by reference value-sharing (globals by lookup-table in different forms). I'll start this off by describing a few use cases that drove me to implement AutoQueues in general and the special case of the VIRegister toolset;
Consider a Top-Level VI with several subVIs. I call that a module in this post. A module could in itself be the entire application, or it could be a dynamically dispatched module from a logically higher level application.
Use case 1: The global stopping of parallel loops
We face this all the time: we have multiple parallel while-type loops running, maybe in the same VI, maybe in different (sub)VIs of a module. Something happens that should make the module stop - this "something" could happen externally (e.g. user quits main application) or internally (e.g. watchdog). Anyways, we need a way to signal a parallel structure to stop. If the parallel loop is throttled by an event-type mechanism (event, queue, TCP-read etc.) already, we could use that medium to transfer our stop signal on. But if the loop is more or less free-running, possibly just throttled by some timer, then we usually poll a local variable in each iteration for the stop condition. Locals work fine for such signalling inside a single VI. There are some drawbacks with locals, like you need to tie them to an FP object, you need to take special precautions regarding use of the terminal versus the local on Real-Time and so on.
If you cross VI boundaries locals won't cut it anymore. Globals could work, but they are tied to a file. Other types of "globals" exist, like Single-Process Shared Variables (they are rigidly defined in the LV project). So to be good architects we deploy another construct that'll allow sharing of our signal inside the module - typically an event or a queue (most often depending on 1:1 or 1:N topology). It's more work to create a user event, or to obtain a queue, for this, since we need somewhere to store the reference so everybody can get to it (FGs are often used for this), we must be careful for data (the signal) not to be invalidated due to the context moving out of scope, and we might have to handle the destruction or release of the reference when we're done using it.
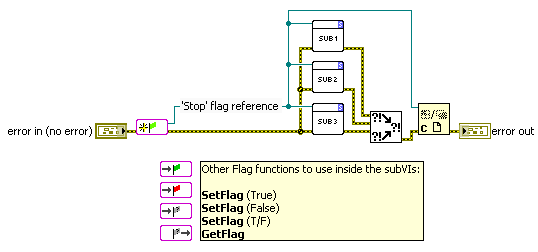
A while back I made a toolset I called "Flags" to solve both cases above. Flags are dynamically dispatched FGs that each contain a single boolean, just nicely wrapped up passing the FG-VI reference from Flag function to Flag function:
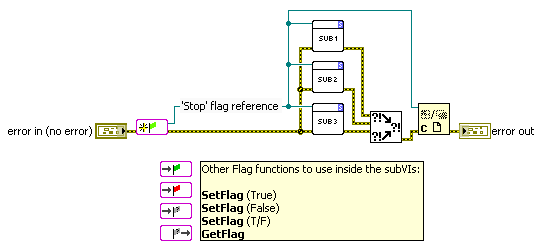
This works ok, but not perfect. The signal can only be boolean in this case (95% of my uses are for booleans anyway, so this isn't that bad), but it gets unwieldy when I have many Flags (most of my modules use 3-6 different Flags) which again usually mean not all Flag references need to be wired to all subVIs:
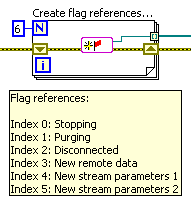 ...
... 
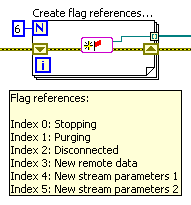
To improve my intra-process signalling toolbox I made the VIRegisters. The same example as above, but with VIRegisters; No initialization necessary, and no references to pass around:
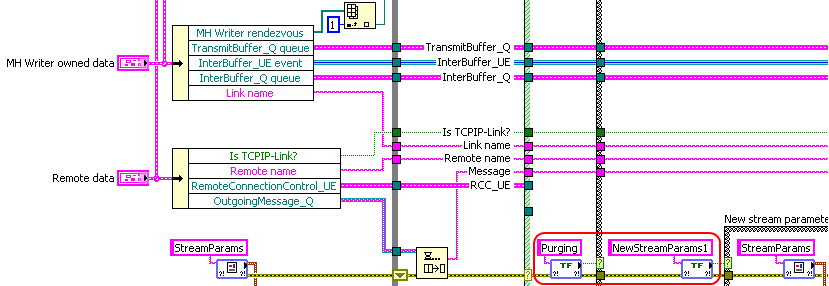
Use case 2: Module-wide available data
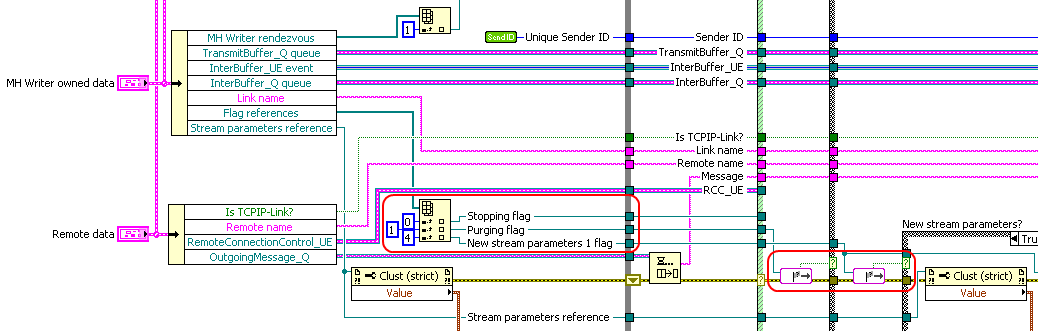
In the TCPIP-Link code snippet above there is also another data set replaced with a VIRegister: Stream Parameters. This is a cluster of parameters that are used by a buffering subsystem of TCPIP-Link. The data is set with an external user event, but various parts of the Stream Parameters are used in different places (subVIs) of this module. Therefore it makes more sense to store this data in a VIRegister than it does to store it in a control on the Top-Level VI of the module and get to it by control reference.
Use case 3: Application/Instance-wide available data
There is an additional set of data in TCPIP-Link that must be "globally" accessible so a user API function can read it, namely a set of traffic information for each connection (payload ratio etc.). This data is stored inside a VI of a module in TCPIP-Link, but to make it available to the entire LV instance, that module was required to support generating an event to any party asking for this continuosly updating information. Replacing this mechanism with a VIRegister I disposed of all the event generation code, including the need for the API to fetch the event refnum to register from another global storage. Now I just drop in a VIRegister read function wherever I want to read the traffic information. It's leaps and bounds simpler to code, and I can't see it's any more fragile than the previous setup.
Remember I'm talking about lossy "signal" type data here (aka. latest-value or current-value single-element registers). Similar to Locals, but much better (in my view). I have other toolsets for lossless data transmission, but we can discuss those at another time.
Are VIRegisters (or any similar architecture) bad? Stephen has some grief regarding the reference-nature of VIRegisters, but I don't think they are worse than named queues. Queues can be accessed from anywhere in the LV instance by name, using an internal lookup-table. I don't see NI discourage the use of named queues? So, the discussion commences. I'm looking forward to learning something from this
.Cheers,
Steen
-
1
-
-
Hi Stephen.
I just realized that people are looking at these VIs and planning to use them for something entirely different from what I had assumed. What I saw as a useful tool for good I realized could be turned to darkness in the wrong hands.
If you haven't heard my position on by-reference data in LV before, it is this: References sometimes necessary -- rarely, and only in well-defined situations with extreme limitations on their use. I do not claim that references are always bad; I do claim that they are overused by today's LV programmers and generally references create many more problems than they solve. And, no, I don't think users are stupid. I think most references are dangerous in the most experienced hands, mine included. Now back to the topic at hand....
For sure references are harder to get right than by value/dataflow, but references enable us to do much more complete encapsulation and thereby code reuse. And belonging in the hard departement of programming is alot of other very useful stuff like inheritance, reentrancy, events, dynamic dispatching, polymorphism, recursion etc. I must say that I use all these techniques leisurely, and wouldn't want to go back to when they didn't exist (in LabVIEW nor in any other programming language). I also think I understand these techniques well enough to not be afraid of them, on the contrary I constantly find new uses for them.
I'm not sure how VIRegister classifies as a by reference component. What I need is an easy way to transfer signals (not data, since VIRegisters are lossy) between code segments that can't be connected by dataflow, e.g. parallel structures or even (sub)VIs. I most often use queues or events for this type of signalling. Named queues are convenient, since I then can skip the step of fetching an event refnum from some global storage. Since I don't want the restriction of purely hardcoded names, I combined the user supplied queue name with the VI instance name. Nothing new here, just fancy dressing for what NI (and common sense) recommends as signal transfer medium between the structure types I outlined above.
As I said, I have built for my personal use VIs that are fairly similar to these. And mine have a string input for "queue name", just like these do. But when I use my VIs, the name is ALWAYS wired with a constant. ALWAYS. They're full reentrant and store the underlying refnum. If I ever released the VIs, I'd probably add an assert that the name passed on each successive call was exactly the same name as the previous call and return an error if that wasn't true. In fact, if I ever got ambitious enough, I'd probably make "name" something to configure on the node, not an input.
That was my expected use case too, which is the reason for the 'release queue' bug in v1.0 of the VIRegister toolset - I didn't expect anyone to run through a list of register names in a loop, using the same VIRegister instance. That was also why I suggested a couple of posts ago to enter the register name into the node itself, but the official LV IDE does not allow me to create such a node - only stuff that fits within 32x32 pixels with a static icon (with a few exceptions). But why not allow the reuse of the node, with the name as input? It's not any different from the way we create hundreds, or even thousands, of queues or events.
I never really considered that someone would look at these as an API for creating a misbegotten by-reference lookup-table. I always forget that various people keep trying to strip LabVIEW of its major assets by turning it into a mush of procedural, by-reference code. Wired with a constant, VIs like this can become a great addition to LabVIEW. Debug tools can be built to track the start and end points of these "off diagram wires". And there a number of code correctness proofs you can apply. Wired with a non-constant, they introduce code maintenance problems that are very hard to debug.
Once you've tried to debug reentrant VIs on a Real-Time system you stop complaining about things-hard-to-debug
. No, seriously, sure they are harder to debug. One of the biggest advantages of dataflow programming, and therefore one of the major reasons for the popularity of LabVIEW when people get introduced to it, is how easy it is to follow the data around ("debug" it). It's also the Achille's heel of LabVIEW. I can't keep track of how many times I've been called in to rake experienced programmer's b*lls out of the fire because they've painted themselves into a corner with LabVIEW. "LabVIEW is so easy" they were told by the NI sales guy. BUT, any of the features I mentioned at the top of my post, well basically anything non-dataflow, is hard like that. And again, I don't see how VIRegister differ from ordinary named queues in this regard?I know I'm not a full-time G programmer. I do theory more than practice when it comes to G. Those of you who actually have to produce working G code for your jobs are right to be suspicious of my opinions on topics like this. Most of the time, when someone who works G full time tells me they really need XYZ, I pay attention and try to see how LV could provide for that need. But when I read things like this idea -- Globals that can be created during run-time and accessed by name (i.e. native Current-Value-Table/VIRegisters) -- I just can't in good conscience help. That sort of architecture just should not be necessary. It might work. It might even work well sometimes. But my theory is that it will never work as well as building software that solves the problem in a more dataflow-like manner, and when it doesn't work, it will be much harder to figure out why than the comparable dataflow architecture. I really wish that all the time poured into tools to support references over the years could be poured into really nailing down dataflow-like architectures that scale. I know they exist.
I don't think you have to put hide your light under a bushel when it comes to G
 . I usually tell people that LabVIEW is just syntax. Implementation may differ in the detail, but so does sunlight and shade, or the good idea, from day to day. Inside my head I don't see anything else but when I program in C++ for instance. I just have to do something different with the mouse and keyboard to make an application out of it. I agree that people with less experience sometimes take the sharpest tools and get hurt, but that doesn't mean the sharpest tools shouldn't be available - but maybe they should be licensed in some way? . So, no, references are king (ever try TestStand?), but that aside I still don't see VIRegister as anything but a mighty fancy wrapper of named queues (did I mention that?).
. I usually tell people that LabVIEW is just syntax. Implementation may differ in the detail, but so does sunlight and shade, or the good idea, from day to day. Inside my head I don't see anything else but when I program in C++ for instance. I just have to do something different with the mouse and keyboard to make an application out of it. I agree that people with less experience sometimes take the sharpest tools and get hurt, but that doesn't mean the sharpest tools shouldn't be available - but maybe they should be licensed in some way? . So, no, references are king (ever try TestStand?), but that aside I still don't see VIRegister as anything but a mighty fancy wrapper of named queues (did I mention that?).I'd like NI to put this into LabVIEW, but with the ability to enter the name directly into the node. This just to get rid of the unnecessary input to make it even cleaner, alas you then lose the ability to create the name programmatically (you will probably then be able to set the name with a property node, even though I'd expect such a feature to cost extra because it'd only be available through a module like the DSC-module). I'm not too fond of the blocking-FG limitation of CVT, VIRegister is simply without these limitations; Shared Variables (which I still need to spot a decent use case for) needs the project for configuration and drags the SVE around, Locals are tied to the FP, Globals are tied to a file... I hate that. Well, VIRegister is tied to the queue name lookup table, but at least that's transparent to the programmer, and lives in the same code space as your VI, and it has worked fine over the years.
But of course, in the spirit of the main topic of this year's CLA Summit, we shouldn't headlessly create new communication APIs. So, implement VIRegister and TCPIP-Link, keep queues, events and locals - ditch the rest
(notifiers can stay too, but they are more like the evil cousin to VIRegister anyway).Cheers,
Steen
-
1
-
-
Steen,
This is a very nice set of VIs. Thank you for posting. I'm one of the developers and current owner of the CVT library, so this is of special interest to me.
I really like the ability to dynamically create new registers by simply writing to them, which is a feature we've been planning on adding to CVT for some while. I also like how you handle dynamic and static names in the VI registers using two feedback nodes. I would like to borrow this idea for CVT to eliminate the need for dual dynamic and static name access VIs.
Thanks
. And of course you may grab any ideas in VIRegister you find useful.One big difference I see is the low level read-write performance. One of our main use cases for CVT is LabVIEW RT on cRIO, which is a much slower processor than most LV programmers are used to from Windows. Doing a very quick comparison between VIRegister and the static access CVT VIs I see a 10x faster access speed for CVT. This is not surprising as when we designed CVT several years ago we benchmarked all the different possible implementations on cRIO and picked the fastest one we could find.
When benchmarking VIRegister reads, have you made sure to have performed at least one write before the read? Reading an empty queue (even with 0 ms timeout) is very slow - on (my arbitrary) Desktop read performance falls from 1,600,000 reads/sec to about 1,000 reads/sec when the queue is empty. This will also be fixed in v1.1 of VIRegister, in which I'll see if I can prime the queue if it's empty (I must avoid the racing condition of a parallel write to the same queue - I have a few ideas how to solve that).
I mainly program LV Real-Time these days actually. I'm the architect behind a couple of large Real-Time applications, for instance this one: http://sine.ni.com/c...c/p/id/cs-12344, and a couple of these (sorry, some is in Danish, and others are without much description yet due to NDAs): http://digital.ni.co...62576C60034F338. I was actually not considering using VIRegister in deterministic code on Real-Time - here I'm contemplating an RT FIFO version of this toolset (RTRegister). Queues are often faster on Real-Time though, but exhibit alot more jitter of course as well as uncanny behaviour on low-memory systems (never deallocating once used memory for instance). If you are careful tuning the RT FIFO you can get slightly better performance than with queues too, while maintaining the very low jitter, but it takes some consideration before it gets perfect (as with everything Real-Time
).Currently the name lookup in CVT is very slow (linear search) as Mads has indicated and we plan on fixing that by using variant attributes to store the tag data and using its built in binary search.
Yes, variant attributes are quite fast when doing lookups like this (here's finally a good use case for that feature
). But isn't the (next) biggest drawback the blocking nature of the FGs?One thing I noticed is that you cannot use one write node to write to multiple registers without risking that the previous registers are lost.
As long as no read is opened on the given register the write is the only place the queue ref is open, therefore the queue is destroyed when the write node runs a release when it switches to another register. The release node does not have the force flag set, but the queue is still destroyed because no other reference to the queue exists (necessarily). If this is the case then I think it would be more useful if you the destruction had to be done explicitly.
The test scenario that made me see this behaviour (which I did not expect, but perhaps it is intentional?) was that I planned to do a double write to 10 000 registers and then a double read of the same registers, and time the 4 operations. The reads turned out not to return an error, but they would return all but one register with default values (i.e. a DBL would return with the value 0 instead of the value I had previously written to it).
Now I only ran through this quickly so I may have overlooked something and gotten it all wrong...However perhaps you can correct me before I come to that conclusion myself :-)
You're absolutely right, and this'll be fixed in v1.1 too. I included that explicit Release Queue to take care of the use case where you'd change the VIRegister name on consecutive calls to the same instance of a VIRegister write or read, since I considered the earlier register no longer used then. But I missed the next-door use case of using a loop to access more than one VIRegister with the same instance of the read or write function, by just cycling through names. using VIRegisters this way yields very sub-par performance (since you'll take the obtain queue hit on each and every call to the write or read function), but In this case the old queues may of course not be released between calls
 .
.The explicit release function has been in the todo-list from the start, so that'll probably also make it to v1.1 (I just grew tired of making all these similar instance VIs for the polyVIs
).Cheers,
Steen
-
I'll try an XNode implementation once you've posted v1.1 - though like you, I also have limited time for this! However, I think trying to use XNodes is valuable if it shows NI that there are benefits to officially supporting them, or something similar. I haven't had any real issues in using them across several machines and versions of LabVIEW.
Cool, I'm curious to see the XNode implementation eventually
 . I'll get back with v1.1 soon hopefully.
. I'll get back with v1.1 soon hopefully.Cheers,
Steen
-
I'm not sure I agree with your decision to put a verison in the palettes that doesn't have the error terminals. For one thing, even the Obtain could fail on a low memory system. For another, asynch behavior like queue writing often requires serialization with other operations.
The "often" (contrary to "always") in your second argument was the reason I included a version without error terminals, but I agree that your first argument trumps that. Alone for the sake of the Obtain (or the Enqueue) possibly failing on a low memory system only the version with error terminals should exist. That version could still be running in parallel with other code, either without wiring the error terminals (the programmer bearing the fallout for that), or wiring the error terminals and then merging error wires later.
I'm one of those people who frowns on local variables not having error terminals, for similar reasons. If you always had the error terminals available, then you could allow the name to be the only identifier and successfully return the queue error when the types and names mismatch, thus allowing the polymorphism. For my money, the ease-of-wiring of the nodes trumps the compile-time-tpype-checking, which is a very odd thing for me to say considering my position on other similar LV features. I'm not sure what makes this one feel different, but, well, for some reason it does.
The extra point of failure by enabling automatic type adaption to the write function isn't catastrophic, and might easily be found less significant than the added comfort of that setting. There are many other possible failure scenarios not nullified by not enabling adapt to type; for instance wrong type selection on VIRegisters reads and writes from the start, or diverging type selections in a main application and the same-named VIRegisters in a dynamic VI.
So I'm also leaning towards it being better to enable automatic type adaption on the write function, and only to offer the VIRegister functions with error terminals. I'll update the toolset and post it here as v1.1.
But I won't touch XNodes for now (due to their unsupported nature and my limited time). I'd rather assist NI in any possible way in making a supported functionality of that sort.
Regards,
Steen
-
One alternative is to require a type wired into the Read function - given that you need that for a Variant-to-Data conversion, that's not so bad, but it may make things a little more unwieldy for the standard datatypes.
I need the data type to obtain the correct type queue, but I think it'd make these variables more unwieldy than the other offerings (locals, SVs and such) if we needed to wire a data type to every read function. The data type comes for free on the write function, but I would only consider automatic type-selection on the read function lightweight enough if the data type could be taken from the wire on the output. As we've discussed at other times, this is probably not realistic to implement (due to type selection stability in the compiler).
So I'd rather keep the polyVI and manually select the data type on the read function, ideally with an additional "Other type" selection, which would (as the only instance in the polyVI) expose a data type input. Alternatively all the instances could instead expose a "Default value" input to prime the queue with (if no value already existed in the queue) - this input would then be configured as 'recommended', except for the "Other type" instance where that input would be 'required'.
But XNodes don't work in polyVIs, right? So in a polyVI we'd need a supported "anything" input to implement the "Other type" instance. I have a couple of ideas how the interface to specifying such an input could go. I might drop a note in the LV Ideas Exchange regarding an alternative polyVI form which could also implement an antýthing input, without maybe making such a terminal globally available in LV. I don't know if that would make it simpler/safer to release such an "anything" terminal (if they only live inside the configuration dialog to a polyVI).
Cheers,
Steen
-
Steen,
Looks like a really neat toolkit that scores highly in the "ease of use" stakes.
Going to give it a real test over the next few days and will feedback on my experience.
Hope you're well. Are you attending NI Week this year ?
Regards
Chris
I'm great Chris, thanks
. Hope you're too?I won't be attending NI Week unfortunately, would've been cool to run into some of you from the CLA Summit again. Are you going? Two of my colleagues will go this year - Morten Pedersen and Henrik Molsen. Henrik will do a presentation at NI Week (Flexstand, a LV plug-in based TestStand OI).
Take care,
Steen
-
Regarding NI's CVT toolset (I just took a look at it - thanks for pointing it out);
Which functionality of CVT do you suggest VIRegister should implement? VIRegisters should be much faster and more lightweight on memory (queues vs. FG-VI), and each variable has its own non-blocking queue vs. a blocking FG per data type in CVT.
Also the ability to setup scope per variable in VIRegister isn't present in the CVT toolset. And the interface to VIRegister is 4 VIs, where your API in the CVT toolset is around 34 VIs (much more complex).
But I'm open for specific suggestion of course - that's the reason for my post here
.Cheers,
Steen
-
The reason I didn't enable "Allow Polymorhpic VI to Adapt to Data Type" is that it could potentially lead to the wrong VIRegister being shared.
The VIRegister is unique by its name and type, so a DBL named "Data" is a different VIRegister from an SGL named "Data". Only the write function will have the possibility to adapt to its input (since Value in this case is an input, on the read function Value is an output, and again; we have no upstream type propagation in LabVIEW).
If you drop a write and a read, both named "Data", and configure those as DBL, you'd be able to write and read the values without problem of course. If you then change your data source to SGL type, the write node would automatically change the VIRegister type to SGL, if the polyVI is allowed to adapt to type automatically. But since there'd be no way to propagate this change to the associated read function, you'd no longer be passing data between the VIRegister nodes. And you'll have no warning of this at edit-time, since nothing is broken.
When the polyVIs do not adapt their type automatically you'd instead just get type coercion which I think is the better option.
If I remove type from the uniqueness constraint, I could enable automatic type selection on VIRegister write. You'd still have to manually select the proper type on the VIRegister read function, and if you selected the wrong type on the read, you'd get a queue type error internally in the VIRegister, which I'd have to somehow propagate to the user. Is this a better compromise? Could be...
Cheers,
Steen
-
Thanks.
You're right about XNodes, but I'm loath of using them since they are unsupported. I like to be able to move my code forward through LabVIEW versions without it breaking too much.
Another issue is that an XNode probably wouldn't be the fix all for VIRegisters - I might've been too quick there. For sure an anything-type XNode would enable me to make a generic write function instead of the polyVI, but since we have no upstream type propagation, I can't use the same trick for the read function (and there are good arguments for not implementing upstream type propagation in LabVIEW). The Value output of the read function needs to know its type at edit-time, and since there isn't even a requirement for a VIRegister write being present in the same edit session as we're using the read, I would have no way of knowing what the data type of the output should be before runtime. The programmer using the VIRegister read will know this data type of course, so some form of dialog could be used to select the output data type - but that wouldn't be any better than using a variant VIRegister and convert the variant to data after reading it.
And a data type dialog (like when setting up the data type for a single process shared variable) isn't as lightweight as I'd like with VIRegisters. They should just be drop-in-and-use. It'd be great if you could type the name into the node through, instead of inputting it by string:

So the best compromise is probably to live with the variant type when sharing clusters.
Cheers,
Steen
-
Hi.
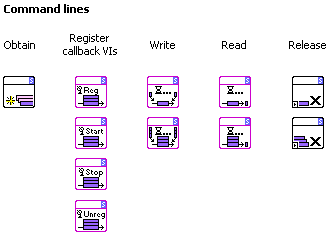
I'm working alot with a concept I call AutoQueues - basically named queues that name themselves in clever ways to allow for "automatically" connecting data paths across the LabVIEW instance. The naming logic depends on the context, and the queue scope might be much narrower than the entire LV instance, sometimes all the way down to within a single VI. I can explain a bit more about AutoQueues later, but as an experiment I'd like to share one of my toolsets that builds upon that concept, namely the VIRegister toolset.
VIRegisters:
The VIRegister LabVIEW toolset is an intra-process communications media. A VIRegister combines the performance and simplicity in use of a local variable with the scope of a global variable – without any binding to front panels or files. You simply drop in these VIRegisters wherever you'd normally drop a local variable to write to or read from, or rather wherever you'd wish you could just drop a local variable
. Even though the toolset consists of more than 160 VIs underneath, these four polymorphic VIs are the ones you drop in your code: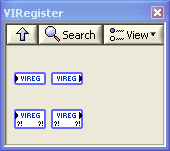
VIRegister features:
- VIRegisters are independent of controls, indicators, projects and files – they exist in the block diagram(s) only.
- The scope of a VIRegister is user configurable, from encompassing the entire LabVIEW instance all the way down to covering a single VI only. So you can use VIRegisters to share data between parallel structures within a single VI, to share data between subVIs, or to share data between entirely independent VI hierarchies for instance. The included documentation explains how the scope is defined - it's all very easy, and has to do with VI references and the call chain.
- VIRegisters come with and without error terminals to support both parallel and dataflow bound execution.
-
VIRegisters are implemented as single-element named queues, using lossy enqueue for writing and preview queue element for reading. Don’t worry, the queue names are quite esoteric (and dynamic), so there’s extremely low risk of namespace collision with your own named queues (you wouldn’t normally use “eXatvx‚ƒt/</Rtpƒt`„t„t]p|t=…xnatvn_t_tƒt_tst@SXBA” for instance to name your own queue, would you? And no, it's not just random characters ).
- VIRegister performance is normally in the millions of operations per second. They typically update 2-3 times slower than local and global variables, but since we’re dealing with lossy transactions absolute performance is seldom a bottleneck. Sub-microsecond latency is still pretty useful for most signaling applications.
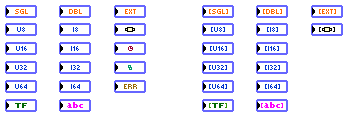
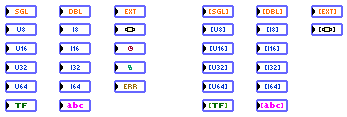
31 data types are currently supported (very easy to expand, but I unfortunately need an "anything" type input to be able to support generic clusters and such - this has been suggested ad nauseam in NI LabVIEW Idea Exchange
):
The code is compiled with LabVIEW 2009 SP1, but should be quite easy to port back and forth. The toolset is released under a BSD license, see the included license.txt file. Any comments are welcome!
Cheers,
Steen
-
2
-
I was the one who brought this to Justins attention at the CLA Summit, and I was a bit surprised at how many didn't know this, but even more so at how many saw this as a bug. Let me explain;
I have many times run into unexpected behaviour (not just in programming
), and often times these experiences just add weight to the "experience-belt". It wasn't more than about a year ago I myself ran into the mentioned issue with unhandled events resetting the timeout counter. At the exact time of discovery of course a huge bubble of "WTF?" appeared above our heads. But it really wasn't much different to the first time I experinced how sharing a registered event refnum between two event structures leads to (at the time) unexpected behaviour, or when I experienced the weirdness when two timed structures have the same name, or the unclarity of it all when I discovered that some FP parts of reentrant VIs can't be unique, while they can when spawned from a vit. All cases with perfectly reasonable explanations, and all cases that made me a better and more precise programmer.I know how this works now, and it makes sense for me - I just take it into consideration when I use an event case structure. Maybe it's because I do not use the timeout case that much? I see the timeout case of an event structure as something of a "lazy way out" of a task that really was asking for something more deliberate. We all know that we shouldn't count on the timeout being deterministic in any way, why are we surprised when this fact stretches to "it may never fire"? Even though the cause for it not firing is another one but imprecision or low priority. I only use the timeout case for doing a check that needs to be done if none of the other event cases does it - a check for an error condition for instance, so I can end my code snippet and inform someone about it. But in reality this probably should be taken care of by a watchdog using a deliberate and specific user event for this task - it's just easy to use the timeout case. I merely know that if I register more events than I handle in a given event structure, then I can't rely on this fallback mechanism - and in those cases I do something else (i.e. the proper thing instead).
So I'm in the group that accept this as nominal albeit opaque behaviour. Maybe the solution is a "Default" case when not handling all registered user events? That could coexist with the Timeout case, make the feature obvious, and allign it a bit with the ordinary case structure/enum scenario (the latter presents a huge pitfall when configuring a case to handle a range of values that truncate to value_m...value_n by the way, but that's another and much more hazardous topic than this).
I think it's probably because most people only use the event case for the UI (and generally wire -1 to it). And only a few are brave enough to base a whole inter-process messaging system purely on events.So if anyone is going to find it....it's you

I'm with Michael A. here. I love events, and use them all the time for messaging. A favourite use case of mine is having a number of dynamically dispatched modules draw their own input and output events from a master pool, and then just start generating data to, and receiving data from, all the other running modules. One exemplary case is this customer project; about 4,000 VIs, Real-Time system + Host, 50 modules divided between the two, about 1200 unique events and thousands of connections criss-crossing the deck. The modules load up, they draw their events and the event handler subsystem just takes it from there. Practically indistinguishable from magic
.Cheers,
Steen
-
Hi.
On a desktop PC I can get the file version or build number of a DLL or EXE by using the Win32 API in LabVIEW for instance. Has anybody got a clue to how I can do this on LabVIEW RT? I'm using LabVIEW RT on both PharLab and VxWorks targets, so additional applause is given for solutions that work in both cases. And I'm not talking about getting a built VI's revision number through its history node - these are general non-LabVIEW DLL and EXE-files (a Simulink model built into a DLL with Realtime Workshop for instance).
Cheers,
Steen
-
QUOTE (Aristos Queue @ Mar 21 2009, 11:04 PM)
Ah, but we can, and have, randomly changed things between versions, just on the off chance that something is working that shouldn't be. :-)I haven't checked since 8.5.1, but I hope NI is abandoning the current PW scheme, since it's fairly shot through with the newly exposed MD5 vulnerabilities.
Cheers,
Steen



Is background priority in VI Properties ignored?
in LabVIEW General
Posted
I ran across this page which basically states that when setting a VI to background priority (lowest) it is deferred to running in normal priority:
http://digital.ni.com/public.nsf/allkb/D6F5480F7F3E9CAD8625778F00652246
It states this as "known behaviour"? I must say I didn't know that, especially not since several other pages recommending priority level setup explains about background priority without mentioning this "fact". For instance;
http://digital.ni.com/public.nsf/allkb/84081F249CEF7AB7862569450074168C
http://zone.ni.com/reference/en-XX/help/370622E-01/lvrtconcepts/deterministic_apps_vi_priorities/
Does any of you know for a fact that setting a VI to background priority have the same effect as setting it to normal priority? On all targets including Real-Time?
Cheers,
Steen