Steen Schmidt
-
Posts
156 -
Joined
-
Last visited
-
Days Won
8
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Steen Schmidt
-
I will contact both of you to understand your concerns a bit more, since these toolkits (IO-Link for LabVIEW and TestStand) were developed exactly to accommodate the scenarios you describe. I can clarify a couple of things here as well: - Our runtime licenses are always perpetual, never a subscription that could expire. - For development licenses we offer both subscription (to get going for less) and perpetual (if you know you want to use it for a long time). - We do offer discounts on license bundles. So if someone has "hundreds of systems", they could use that option. - The software in question currently has more than 3,000 hours of development time behind it, with ongoing improvements. I assure you, no matter when you begin it will be a long time before you have something that is close to what you could buy today. And at that point you wouldn't consider giving it away for free 🙂. This toolkit parses the entire IODD XML standard, which is huge. It is not quite the same as picking the 2% you need today, and discovering that the next device you want to connect uses a different part of the standard...
-

Best practices for computing user equations
Steen Schmidt replied to eberaud's topic in LabVIEW General
Oh yes, that's a side effect of VIPM not making sure all dependencies are in order during the installation process. You want to either 1) uninstall and then re-install Expression Parser after its dependencies are in place (making sure mass compile is enabled in VIPM), or 2) manually mass compile the 'C:\Program Files (x86)\National Instruments\LabVIEW 2015\vi.lib\GPower\ExprParser' folder, whichever you prefer. All something VIPM should have done for you. The reason is that since you have updated a dependency (VI Register) after you installed Expression Parser it makes LabVIEW need to compile the Expression Tester when you launch that. For most LabVIEW code compiling on load is merely an annoyance that takes an extra few seconds, but for Expression Parser the matter is different. It's very complex code, which takes around 5 minutes to load an uncompiled Expression Tester for instance. The entire Expression Parser VI package takes around half an hour to build (so it's good only I have to do that). We made some improvements to the code architecture from the last version to this newest one, which improved VIP installation speed from 15 to 4 minutes. Still much too long for comfort. I have a much faster installing version here, but that one takes a 10% runtime performance hit which I'd like to get back before we release it. -
Best practices for computing user equations
Steen Schmidt replied to eberaud's topic in LabVIEW General
You need to upgrade the VI Register toolset to v2016.0.0.31. VIPM should have told you this (since that is a dependency of Expression Parser), but VIPM has been broken for a long while on many details. You can get VI Register v2016.0.0.31 either through VIPM (it's published on the LabVIEW Tools Network) or from our website here: http://www.gpower.as/images/downloads/viregister/gpower_lib_viregister-2016.0.0.31.vipc Cheers, Steen -
Best practices for computing user equations
Steen Schmidt replied to eberaud's topic in LabVIEW General
We have had such a toolset for a couple of years: http://www.gpower.as/downloads/expression-parser-toolset I have worked for almost 15 years writing math software for HP calculators, so I'm also keen on RPN ;-) It's not trivial to do a fully functional toolset like Expression Parser. Probably close to 1000 hours have gone into making it. From our website: Evaluate mathematical expressions, given as text strings, into numeric values: Build and change your math expressions at runtime. More than 260 math functions and constants supported. Very high performance. Supports any number of variables of any name. Supports VI Registers. Reports overflow if that occurs during evaluation. Supports all 14 numeric data types that LabVIEW offers, including complex evaluation. Offers special expression control like conditionals, piecewise defined functions, pulse trains, and defining your own custom periodic functions. Supported on desktop and real-time. Cheers, Steen -
We investigated doing a non-LabVIEW UI for a recent project, due to alle the reasons Shaun lists, but LabVIEW web service support was simply too lacking (crippled web server and non-existent security). So, lot's of good reasons to do it, just not really possible in a comfortable way.
-
Thanks, but having N control P's, one on top of each control T, was what I'd like to avoid. I would much prefer a single control P that resized and moved in place over each control T whenever it was needed. The reasons for this: 1) Being able to drop just a single "Drop Sink" (I call the control P that) control anywhere on the FP is simpler than meticuously placing N of them over each control T (and leaving enough border of the underlying control T to keep its Mouse Over/Mouse Leave events actionable). 2) The hidden control Ps won't scale and move with the FP, unless you jump through all sorts of other hoops (you have to remember to also set those to scale/bind to splitter, and they have a different size than the underlying control). If they could be placed just in time, one control P would suffice and it would always be placed just right.
-
No no, that's perfectly fine. I may come of as too complaintive. At other times I'm a fierce defendant of LabVIEW :-) It might be a question of circumstances for me - I enjoy programming LabVIEW, so if I have the time to do it I don't mind challenging workarounds. If I'm short on time I hate I have to do them. And also, things might get better in the future. So don't put too much weight on my complaining, my bark is much worse than my bite :-) Yes, exactly the workaround I want to implement. But it's not so simple. I don't want the invisible path control (let's call this Control P) to be over my target control (let's call this control T) permanently, as I want control T to behave completely normal, except when I drag something onto it. That is, upon dragging something from the explorer onto the VI FP, and ultimately onto control T, only then do I want control P to place itself over control T to receive the drop (and whisk itself off to the side again after it has passed on the dropped item via Value Change). There are two problems with this: 1) Once I drag something onto the FP all normal control event firing stops. I would have hoped Mouse Enter or Mouse Down would fire on control T, but they don't. So I have no way of detecting when that cursor is over control T. I can't even detect such a drag entering the VI Pane, so I couldn't even poll the cursor by looking at the mouse position with Input Device Control. 2) If I succeed in detecting that drag, and move control P in place, if I then want to abort the drag (by pressing ESC on the keyboard, or by dragging outside control T again and letting go of the mouse button), I have no events firing in this case either. I would have hoped Mouse Leave would fire on control P, but it doesn't. So, I'm contemplating how I can discover that drag from explorer has started, and how I can discover if it is aborted again.
-
I'm interested as well, I think we've come to the end regarding gifs anyway, haven't we? But for future searchability we could start a new thread...
-
Wow, this is frightening to look at from the outside: All I wanted was for LabVIEW to play my animated gif correctly, a feature it's supposed to have built in. That didn't work with my gif (nor Michael's it seems), and no sensible error message comes out of LabVIEW. And now you guys are discussing embedding web browsers in ActiveX containers, and programming a gif decoder and playback feature manually, the latter even as an XControl. And all that with a straight face. We're so used to LabVIEW falling short and us solving simple shortcomings with days of programming, that we can't see the joke here. Over the last 24 hours I've come across two other simple things LabVIEW should be able to do in 10 seconds, but each will end up taking 5-10 hours of programming to get done: 1) Being able to drop a file from the explorer onto a control and get that event in the event structure, and 2) Enabling any control and even the front panel to drag the entire window (as you would be able to do with the title bar). Every small step is really a huge leap with this tool...
-
Not like that. This requirement is: 1. Illustrate busy state on the window. 2. When the window is not busy, the busy indicator must be visible but subdued (to familiarize users with the location of the busy indicator). Just like in VIPM for instance: One simple way to do that was with a toggle-button that has a static subdued image in False state, and a spinner gif in True state. Then activating "busy" is simply programmatically setting the button to True. It's not so the user can push that button.

-
Probably won't get added to LabVIEW: http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Add-drag-and-drop-support-for-OS-files-on-any-control/idi-p/1073586
-
Ok, not going to happen. I try to use http://ezgif.com/maker, which is a great site for making and editing animated images, but LabVIEW just gives me this on the created files:
-
Yes, I want to do some loaders/spinners. I wanted the gif on a button to easily switch between inactive (a static subdued image) and active (the animated gif) states. I started on the route to populate either a ring or a 1D array with the images, and then make a brat VI to automate animation of it. Then I thought better of it; "this is LabVIEW again forcing me to jump through hoops and spend numerous hours on something that should just be a drop-in". I simply won't do any of these work arounds to get a freaking animated gif to roll. But LabVIEW isn't alone here, animated gif support is always riddled with exceptions in browsers and the like. Animated PNGs are even worse for wear in this regard. LabVIEW probably just have an upper limit as to how many frames it will allow a gif to execute per second. Below that rate it'll play at full speed. I'll investigate that assertion and get back shortly.
-
Just ran into this today. Wanted to use the attached animated gif, but it runs really slow on a FP (as state image on a button actually). Oh well, just one of those things. I bet one of those images from 1985 will work just fine. You know, black/white 16x16 px, 4 frames, 1 second in-between frames, no transparency... EDIT: I did try one of those gif speedup services (ezgif.com), and the new gif animates much faster, except in LabVIEW where it continues to crawl along. It must be an issue of LabVIEW throttling resources to run the gif. I can see how such a gif could easily bog down my multi-GHz 8-core CPU. I'm glad those gifs are kept in check, wouldn't want them to animate at anywhere near intended speed... Sarcasm might occur.
-
Yes at runtime. But dynamic dispatch isn't a phenomenon at edit time, only the type resolving (which doesn't have to force load of all VIs in the class). So my question remains; what is the reason behind classes having to load all their member VIs in the editor? Since classes are basically a type, it is probably to avoid edit racing like with typedefs (two people simultaneously editing two members, afterwards both edits need to update the same class lib resulting in a non-resolvable conflict).
-
One reason might be that to read the linker info you'll have to traverse the entire lib tree. Since refnums to all libs in the tree after this are now in memory, they are left in memory. Perhaps under the assumption that stuff within that tree is soon to be called, and thus it's assumed more efficient to leave them in memory than to close them again? The libraries themselves aren't that heavy, but quick access to the linker info will give you a more responsive IDE. The better question is why do classes have to load all their VIs? XControls have to because they execute, but class execution is runtime only.
-
The "Log: Missing Callee" error happens every time you drag a VIM onto a saved VI's BD. As long as the caller isn't saved, you can drag VIMs onto its BD all you want. That's the difference as far as I can tell, and it has been so at least back from LV 2012 (didn't feel like trying further back). It seems like a reference mistake in the VIM builder XNode, but I can't edit that, so I can't attempt to fix it. I know of someone who can though ;-)
-
Nope, didn't help after all. I get a huge number of Log: Missing Callee in 2016. In fact, 2016 seems quite unstable, or perhaps it's just because of VIMs. I'll try porting my code back to 2015, even though that means pulling out my Type Enabled Structures :-/
-
I think I made that error go away by adding "ExternalNodesEnabled=True" to the LabVIEW.ini file, even though that shouldn't be necessary any longer from LabVIEW 2016? /Steen
-
-
Yes, if I were benchmarking the numeric evaluation. I'm not, I'm benchmarking all that comes before that final step, because that is what differs between the two compared solutions. LabVIEW prims handle the numeric evaluation in both cases - for multiplication for instance we're both handing the numeric arguments over to the LV Multiply primitive. That part of the evaluation should perform equally in both our implementations. I'm interested in minimizing the impact of the identical parts, and benchmark where our implementations differ. Both random and exhaustive full-range data would be neccesary if this was a scientific benchmark. Not only for numeric input, but definetely also for the expression content itself. It could turn out that the parsing and traversing the RPN tree is very little of the formula evaluation for most real-world formulas, but in my experience it is not. If you spend most of your time evaluating formulas that take seconds or minutes to evaluate, it might turn out that the parsing algorithm has no real impact on performance - you might spend all your time inside one LV prim perhaps anyway. That is rarely the case, but for special cases it might be. 1) Tell me how to accurately time slices of maybe 10 ns on a Desktop machine? 2) You don't think that building and filling an array with 20 million timing values will impact the benchmark in any way? I also suspect it would take a while to do statistics and display of that data afterwards. But sure, if the world depended on this being very accurate we should do some of that stuff. I can send you the Expression Parser code though, and let's make a dollar bet on the outcome of your exhaustive investigation. My money is on that your results will be within 2% of what I've posted here :-) /Steen Just for clarity I feel it's important to note that I agree both with you Brian and Wouter - my benchmark is skewed somewhat. Doing an accurate benchmark is very very hard at these small time slices. So many factors play a part from run to run. The quick'n'dirty approach I used here does come within touching distance of a much more deterministic approach is my experience (with string to numeric parsing). I've benchmarked exactly these operations for more than 20 years now (making calculator software), so I have a good feeling for when I see a trustworthy trend and when I need to do a more thorough benchmark. Not necessarily the same if I were to benchmark, say, HDMI data transfers. I have no experience with that. You probably know, but NI for instance has 'the grid' they deploy VIs and apps on to benchmark. A network of identical computers and SW images that should run identical benchmarks, but which do not entirely. Enough runtime on the grid will illustrate the general direction of performance; "Did the investigated code change make performance go up or down generally speaking"? /Steen
-
Oh that little thing :-) Yes yes, I know all that. That is on purpose, because that is how I compare it to other solutions as well. Saying it isn't a fair measurement makes assumptions as to what I want to measure - that was the reason for my question. In this case the only parameter I want to illustrate is that Expression Parser is several orders of magnitude faster than the Gold Parser for numeric parsing. There is no way in plain LV to reliably measure the execution time of a single EP Eval as it executes in a few nanoseconds. Thus I need a loop with many iterations of Eval and then divide by N. If I put data IO outside the loop the LV compiler will optimize the loop away since every iteration performs the same operation. The least intrusive way to stop this dead code elimination is with async controls and indicators inside the loop. Yes, we spend a bit of time writing to and from their buffers, and several times per second a thread switch and transfer to the front panel value fields might be happening, maybe even the stray redraw. But I can't come up with a variable data IO solution that skews the timing less. And it suffices to demonstrate the performant characteristics of EP. /Steen
-
In what way is it not fair?
-
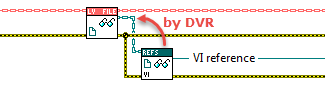
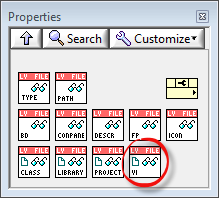
I select the GetVIRefnum method manually (it's a method of LVFile), and it'll throw an error if the child object on the wire isn't one of those that uses a VI refnum (it could be a Project for instance). Note that it doesn't expose the LVFileRefs object anymore: I agree that the parent shouldn't know anything about its children. The instantiation method (factory) is external to the LVFile class, but internal to the lvlib that all the classes is in. It occurs to me that putting LVFileRefs inside that same lvlib ties it together with the other classes, something I'd like to avoid - oh well, still things to tweak. Anyways, outside the LVFile hierarchy exists a polyVI that offers 5 instances: New by path, or by class, library, project, or VI refnum: Each of these 5 instances within the polyVI uses a selection of "New" methods from either a child class or from LVFile to create the new LVFile object. The only "New" method used from LVFile is NewUnsupported, which is output in special cases ("unsupported" types like .zip or folders for instance - meant to facilitate that you can have your app read up an entire folder hierarchy without having to filter errors out yourself, just don't handle any of the Unsupported file objects afterwards). /Steen
-
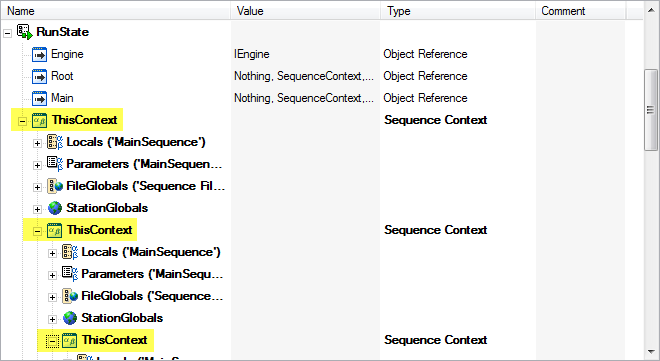
Yes, it's simple to understand the difference between the recursive object and the one that is not. What I mean is: 1) The DVR is a pointer, that pointer does not have to be resolved to any object before it is referred at runtime. Problem shouldn't exist at all at edit time. Type information is only an editor-aid, exactly like in TestStand where every object contains a refnum to itself (ThisContext) - basically an infinite recursive path if parsed (but the object tree is never unfolded to infinity in the editor): 2) Even if some level of parsing was necessary, a circular notation could be used in the object. I had to deal with this often for HP when doing math software for their graphical calculators. Such a specifier would be similar to a recursive function call in code, a symbol that at runtime resolves to my own function pointer in the stack, and at edit time just informs the editor to treat this object in a special way (for instance to open myself if I double-click on my own subVI icon on my BD). In math it's typically about pattern matching, where the circular identifier in symbolic mode throws the parser into a look-up table with predefined results involving special functions, and in numeric mode stops the recursive unfolding when sufficient numeric precision has been achieved. That's what I mean with I don't know why LabVIEW does not allow me to do this - we got recursive VI calls eventually... /Steen