

GregFreeman
-
Posts
323 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by GregFreeman
-
-
We pretty much use the VI from that thread. I've attached our copy (LV2012 onwards). I can't say much about Bamboo, but when we use TeamCity it is looking for tokens in the stream that indicate specific messages. That's how we transmit status messages (progress) as well as unit test results etc.
I do recall having issues executing a batch file and then receiving messages though - currently we execute scripts manually in TeamCity (ie. it opens a command window and then feeds each line as StdIn). Perhaps this is related to your issue?
Thanks, that direction should get me started.
Ssssshhh, Don't tell Rolf. But there is a superb library that no-one is supposed to use.

-
We built a basic utility we inventively called "GBuild" that is run via command-line when starting LabVIEW. GBuild parses LabVIEW command line arguments (ignoring itself) to determine what project to open, whether to mass compile or clear the compiled object cache, what number to version a build (e.g.with reference to source control version), what unit tests to run (by unit test framework provider, we occasionally use more than one), what VI Analyzer configuration file to use (if required) and then what build specification to execute. We use the command output stream to feed information back to the CI runner (progress, unit test results etc.), which in our case happens to be TeamCity.
The actual TeamCity build agent in our case is a virtual machine with the development environment elsewhere on the network. As part of the pre-build process TeamCity automatically checks the source out of source control prior to starting GBuild.
This works quite well, even in some scenarios where we "chain" builds (one build is dependent on the previous).
The only issue we have had is where we use .NET assemblies as part of a project that is being built - if the .NET assembly version has changed then we have had to add a programmatic "Save All" to avoid LabVIEW hanging at exit with a prompt to save changes (since there is no actual user).
How did you go about writing to the output stream? I used the VI found here and it writes to the console, but it isn't captured by Bamboo (although my echod commands in my batch file are, so I know bamboo does get this stuff). I may just write to a file and have my batch script read from the file and echo its contents after the fact as James mentions but it would be nice if I could get it to update in real time and let the tool stick everything in its native log file. In the meantime, I will confirm Bamboo will get StdOut so I'm not chasing something that's impossible
-
A VI template is not intended to be placed inside a VI, therefore you cannot put it on the palette. If you try to put a template into a VI it is like trying to call the template from the VI if that makes sense.
There is one case, however, where I have used this successfully. Functional globals inside a VIT seem to get their own "namespace" of sorts. This allowed me to launch multiple VITs but use a functional global independent to each one. (Ever wanted to reference the same timer in multiple cases in your code...now you can).
I know this is unrelated to the original post, but maybe someone will find this convenient.
-
extracting information form the output stream
I probably do. I'll look into this.
-
We do the same thing - since the command output stream is already hooked back to TeamCity we don't need any content in the result log file - it's presence (or not) indicates whether the LabVIEW process finished successfully or not.
I thought about this route but if it fails I wanted to be able to add errors to the file. I suppose I could do if finished and file doesn't exist, success, if finished and file exists, failed.
-
Before we had a dedicated build agent PC (well virtual machine, but you get the gist) I actually used my development machine as a build server and scheduled the hours the the agent was available for (typically break times, outside work hours, times I knew it didn't need LabVIEW etc.). Not quite as useful as a dedicated machine but it was able to take advantage of the same license. I could enable or disable the agent when I needed control of LabVIEW back to get some actual work done, and then relinquish it back to the build agent when I was done. Build agents are independent of the build server with TeamCity so if my development machine was unavailable the build server would try and locate another available agent.
The biggest issue we faced was the automation of the LabVIEW IDE. We went through several hoops to make sure that we could shut-down the IDE normally when a "build" was finished. If only LabVIEW, ironically, had a command-line version

What I am doing is launching LabVIEW from the command line, via a batch script that is called from bamboo. I have an input variable that is the path of the VI which does the build using the build API that ships with LabVIEW. Bamboo relies on the response from the application that was launched to determine a passed/failed build. I am now taking the approach my batch file waits for the call to LabVIEW to return, my build VI dumps a log file which holds success/failure inside, and my batch script looks at the file to determine a pass fail. Then, the batch script can return exit(0) or exit(1) itself, which bamboo captures. To get out of LabVIEW, I am fine with just putting an exit LabVIEW function in my VI that does the build, since this VM will be dedicated to builds. Whew.
Edit: I did try launching LabVIEW directly from Bamboo. While this did launch LabVIEW, calling exit (0) or exit(1) from LabVIEW using the CLFN crashed LabVIEW. So, there was no way to tell Bamboo that the build failed or succeeded, as it would always fail. This is why I wrapped it in a batch script and let the script return 0 or 1.
Edit #2: I am open to more robust ideas here
-
I was thinking about it and I wonder if when LabVIEW first introduced event structures, if people had one event structure for each control. Certainly not knowing the intended way to work with a tool is a common way to use it improperly, and generally speaking having multiple event structures is a red flag for this. But when advanced users know what they are doing, powerful things can be done with these tools.
I know this is old but I couldn't resist. The answer is yes. The person that did it: me, even when the ES was no longer new (although I was new at this time). I had no knowledge of right clicking and adding event case.
-
Thanks guy, good responses. This is the feedback I have been looking for. AK_NZ this is pretty much the route I have been beginning to take so that at least confirms I am on the right path. Danny, I don't have the same licensing issue luckily. But, I really appreciate those links. I hadn't come across them and they seem pretty valuable.
-
We've set up Jenkins once and used it for a brief moment, but it was just experiment to see how it works and we've left this after several weeks. The real show-stoppers were some nasty bugs in compiler in the project that was our guinea pig. Those errors were unrelated to the CI server, but the result was that none of the compilations could be finished. The application builder is very moody - it can break without apparent reason in the first run, just to succeed in second. That is for sure one of the things to considerate when setting up CI.
Anyway, I still see many advantages of CI, so I'll follow this thread with interest and maybe come back to the idea.
Yes, the build can be finicky for sure. I'll see how this works out. Anyways, I am making some headway and when I have something that's at least somewhat substantial I'll post back with my findings.
-
You should it is awesome and I'm not biased at all...okay well I just wanted to explore more XNode stuff, and I think it could be useful.
Right now the read returns the whole buffer, I can see that reading a subset could be useful especially if a rotate is not always needed.
Also I'm getting the idea that if a rotate was required, that we could then write the newly rotated data back and set the pointer back to 0. I think this would mean that you can no longer have a write and read happening in parallel, but right now I think you could, not that I would want to. The benefit of this is that if you did two reads in a row before a write, the second read would never need a rotate.
All sound improvements team, I'll implement these changes soon.
You're a week late. I just implemented one of these for a project (only for one data type). Would have preferred to use yours. The xnodes make this about a factor of 10 better than mine
 . If it's any consolation, I rotate the array as well.
. If it's any consolation, I rotate the array as well. -
Has anyone here set up CI with Bamboo (or Jenkins?). I am working on this now (with Git) but starting with a blank slate with something you hardly know anything about is tough, especially with LabVIEW that doesn't have really any plugins available for it on this front. I would like to first start with just automating a build, then I can start adding in the more complex stuff like kicking back merges etc if the build fails. But, those things are a task I will tackle later.
-
Implicit FTW.
-
Revive a 5 year old thread? Why not. Turns out there is a easier way to concatenate a 2D array of numerics horizontally using the matrix math build matrix function. There is a right click option for append columns, or append rows.
http://forums.ni.com/t5/LabVIEW/Concatenate-2d-arrays/m-p/2959175#M853118
Believe it only works for numerics though.
-
It works, but it involves a lot of data copying and reflection analysis. Does it scale sufficient for your needs?
For now, yes. Won't be a deep directory structure. If I build something that is to be more than a one-off subVI, I can consider other routes.
-
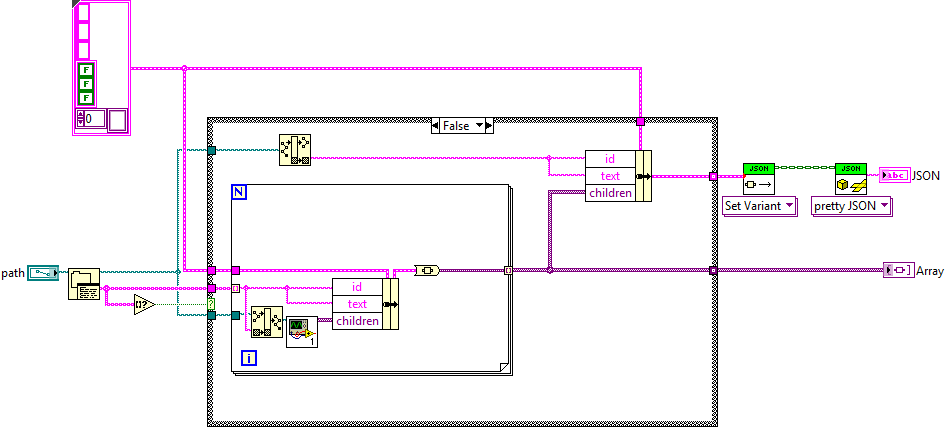
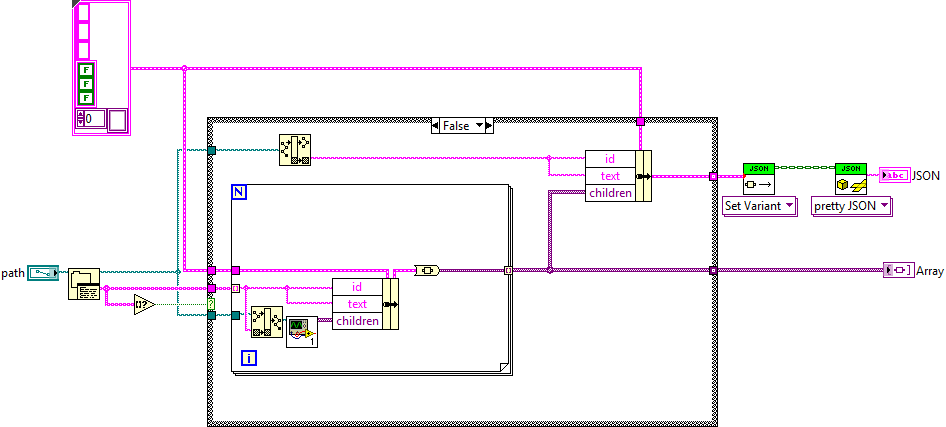
Have you tried using the JSON API? That allows nested clusters of arbitrary types, unlike the native LabVIEW one.
Well that became trivial. Done in 10 minutes.
-
Have you tried using the JSON API? That allows nested clusters of arbitrary types, unlike the native LabVIEW one.
I haven't. I'll give it a whirl. Was hoping to roll my own "real simple one" because I thought making it for a specific use case wouldn't be too big a deal. But it's proving to be more time consuming than I thought.
-
I had another thought, since yes, I just need the JSON. Rather than make the children an array of by value nodes (which I can't because I'd have a recursive node cluster), I can make them an array of strings. I can go through recursive call, formatting all children nodes to an array of JSON strings and flatten that array to a single string to be passed up the stack. Then, I just have a bunch of nested JSON strings already formatted, and when I get to the top level, I can just do flatten to JSON string...I think... We'll see if it works.
Won't work because of string vs object formatting in JSON.
-
I had another thought, since yes, I just need the JSON. Rather than make the children an array of by value nodes (which I can't because I'd have a recursive node cluster), I can make them an array of strings. I can go through recursive call, formatting all children nodes to an array of JSON strings and flatten that array to a single string to be passed up the stack. Then, I just have a bunch of nested JSON strings already formatted, and when I get to the top level, I can just do flatten to JSON string...I think... We'll see if it works.
-
So, I'm just trying to recursively go through a directory list and build up a jsTree structure in JSON to send from a web service to a browser. But, I am having a heck of a time doing it. I was hoping I could just build this up into a cluster and pass it to the flatten to JSON function but for obvious recursive loading reasons that won't work because my structure will have an array of itself inside it as the children variable. When going the references route like you normally would a tree, I now am having a hard time going back up the call stack to build up the JSON structure. I could post what I have tried but I assume it won't be much help. I figured I'd just see if someone here wants to take a crack at it for me so I don't keep spinning my wheels. Feel free to scrap the li/a attributes for now.
// Expected format of the node (there are no required fields) { id : "string" // will be autogenerated if omitted text : "string" // node text icon : "string" // string for custom state : { opened : boolean // is the node open disabled : boolean // is the node disabled selected : boolean // is the node selected }, children : [] // array of strings or objects li_attr : {} // attributes for the generated LI node a_attr : {} // attributes for the generated A node } -
It is possible to get around that by using event callbacks. It is intended for activeX and .net support but seems to work with internal LabVIEW events without issue. I used it to be able to set up dynamic binding for an MVC framework - http://www.wiresmithtech.com/mvc-in-labview-library/
In my case I'm not using OO to change the response but you could make the callback method a static parent method and then have a dynamic dispatch core VI inside (I don't think you could use dynamic dispatch directly).
Nice, I never even thought to try this. Ironically, I have often said to people, "I wish LabVIEW had callbacks support" (other than .NET and ActiveX like you noted). Well, whaddaya know...
-
We're working on parsing sets of data. As part of this process, I go from a TDMS file on-disk to an array of objects. Each object contains data from a single sub-test and provides access to several methods that help in analyzing and displaying the results.
The size of this array could potentially be large, with perhaps a few thousand elements.
We're concerned that this may cause memory management problems in LabVIEW. We'll be running tests to try it out, but we're curious if anyone else has done something similar, and what barriers or issues they may have run into.
We're considering alternatives, such as performing read/writes directly from the TDMS file at all times. But regardless, we may have to plot large sets of data, which would require the data to be in memory anyway.
Does LabVIEW have any problems automatically deallocating memory for large arrays, especially large arrays of objects? Some of my colleagues are concerned about this.
My instinct is that it's no different than any other array. I think that once a class is loaded into memory, all the metadata about the class is locked in and can't be removed (the info about the private class and methods). But I don't think that particular caveat applies to specific instances of the class, which can be created or destroyed like instances of any other datatype (I think).
I'll be looking through the Managing Large Data Sets in LabVIEW white paper. Any other references would be appreciated.
Thanks.
We have conquered this using DVRs, but unfortunately I didn't work on any of the projects that have done this, so I don't have a lot of familiarity with it. I'll see if I can get a chance to look at the work that was done and provide some feedback. As for the plots, just make sure you decimate the data.
-
I do a lot of this, but oddly enough often shy away from it for UI interactions.
Architecturally my frameworks are often designed around this. BaseClass is designed to receive SomeMessage which invokes a dynamic dispatch BaseClass:OnSomeMessage for which child classes may override as desired. In the end the underlying transport layer disappears and largely becomes irrelevant to the component designer-- all that matters is picking off the right level in the hierarchy and implementing the right overrides to hook into the larger application. The framework could be event based, home-baked queues, actors, or voodoo, it doesn't matter much at the component level.
I don't find myself using this type of framework for handling too much of the controls in a UI though. Dynamic registration is very powerful, but at the end of the day your dynamic event registration is not extensible. What do I mean by this? If your register for events node is set up to work with ten different events, that's all it will ever do. The next level in the hierarchy can't add another set of events, it needs its own registration.
Add to that the venerable front panel is filled with statically defined interface elements means I don't see too much use for objects in this context. Yes, my frameworks may have some level of inheritable functionality that implements an OnCancel method or the like, but at the end of the day they're method calls that are made from a single event structure in a single loop, in a single VI.
Don't get me wrong, I use a ton of dynamic events, just not in the inheritable OOP context.
This is fairly inline with what I have been doing, and your third paragraph with regards to extensibility is what I have found as well. In fact, just yesterday, I tried seeing if a cluster of event registration refnum clusters would wire into the terminals on an event structure. Alas, I got a broken run arrow. Too bad those terminals can't recursively register through clusters of clusters of event registration refnums, or an array of them, or something so I can have a "get events" method that I override in the children, which calls the parent "get events" method and appends events then returns them all. Maybe this is unnecessary but I can think of a couple of places in my code it may prove useful.
-
This thought crossed my mind the other day and I pinged AQ on it offline and got a good response. I just thought I'd open it up to the community as well.
In more complex UI frameworks, they enhance UI reusability. For instance, with my limited text based experience I realize most frameworks allow you to create a dialog class that inherits from some parent dialog. You then, by default, get the onOK and onCancel methods. If you just have a simple dialog you don't have to do anything for these methods the parent method will just be called. And if you need something more complex, you can override them.
After talking to AQ he pointed out that is because of dynamic event registration. I already knew we had the ability to dynamically register with controls but I never put two and two together. He also mentions this "for most UI deisgns, it is more work to pass around refnums and dynamically register than to just statically register. It is only when you start designing and inheriting UI frameworks that the balance of effort shifts in favor of dynamic registration."
So, I guess I am just curious if anyone has gone the route of implementing things this way and found it beneficial? This is pretty much just an open ended question; just curious on people's responses. I just have found myself rewriting almost identical event cases in most of my dialogs, and was trying to mitigate the need for having to do this. That is what prompted this whole discussion.
-
For the VI that is going idle, why not just use the VI Invoke Node with the Front Panel:Close in its ChangeView event handler.
Then for the VI that is going visible, use SubPanel Invoke Node with Remove VI followed by Insert VI in its ChangeView event handler. I would add a Clear Errors in between in case there is nothing in the subpanel. You might also add a Front Panel:Close in front of all of this in case the VI is already being displayed somewhere along with a Clear Errors in the event it is not currently visible.
I like this solution. Also, if as mentioned above, I check the current VI reference in the subpanel against the VI reference I'm about to load, I can have some logic built in determining if I need to remove the current panel or not, or even load a new one (if the references are already equal, no need to remove or load).
{kind=link}
Continuous Integration
in Source Code Control
Posted · Edited by GregFreeman
To follow up, when I launched with "start /b /wait" I was then able to redirect my stdout from LabVIEW to a file. Before it would print to the console but it was like that stdout stream wasn't seen as the one that the start command was referencing because the redirect just left me with an empty file.
Haven't checked if Bamboo captures this yet, that is my next step. But, the fact that i can now redirect an output from the start command to a file gives me hope. If nothing else, I should be able to execute a loop on the stdout from LabVIEW and echo the response which I know Bamboo can get.
FOR /F ["options"] %%parameter IN ('command to process') DO commandJust in case it helps anyone else...
Edit: Just confirmed, the /b option allowed bamboo to capture what I wrote to stdout