

Jim Kring
-
Posts
3,905 -
Joined
-
Last visited
-
Days Won
34
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Jim Kring
-
-
Should we call in vugie?

I don't see anything wrong with having well-designed icons for OpenG VIs, as long as they all look consistent -- right now I think that the font of "MD5" doesn't really fit with the icon designs of other OpenG VIs.
-
1. Are you happy with the current VI icons (they are do exist in the released package they are just not shown)?
I'm not in love with the current icon, but there really isn't any sexy way of saying "MD5 DIGEST"

2. Do you want the poly selector on by default still (personally, I don't see the point anymore if we do the above)?
Yes, I think we should keep the Poly Selector, because the poly instances change between string encoding, not data type. This means:
1) You can't change between implementations by wiring up different input data types.
2) there's really no other good way (besides the Poly Selector) to convey to users that it's a poly VI with other implementations and let them choose between the different implementations.
-
I know it's only been about 5 minutes since the OpenG MD5 Library version 4.1.0.8 was released, but I was so excited that I had to try it out and wanted to make a couple suggestions to continue this wave of improvement
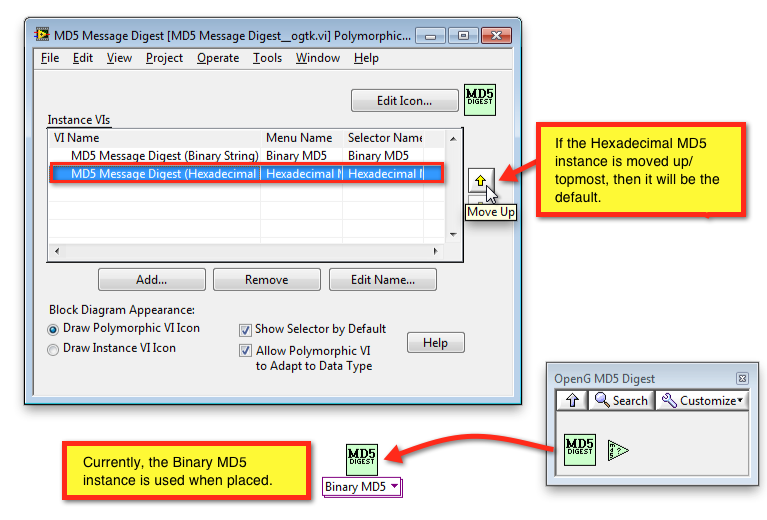
Place Hexadecimal MD5 instance by default
When the MD5 Message Digest is dropped from the palette, the Binary MD5 instance is placed, since this is the top-most instance of the Poly VI. I'm not sure if this is by design. I expected that Hexadecimal MD5 is more commonly used and that this should be the default instance when dropped.
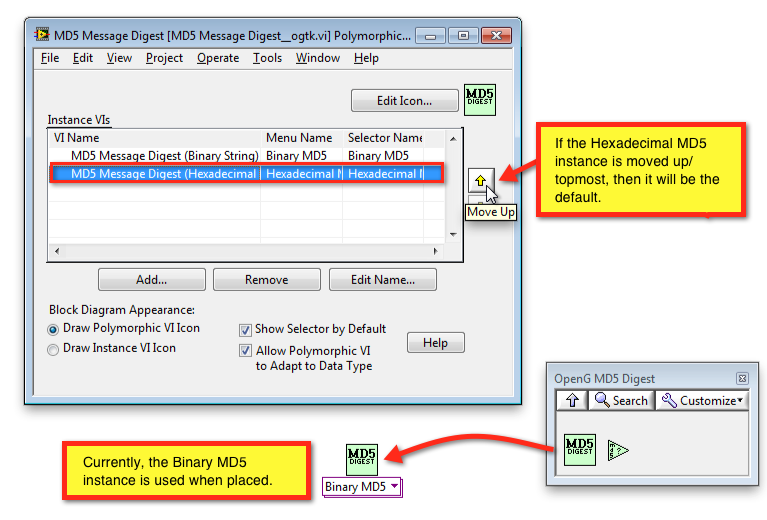
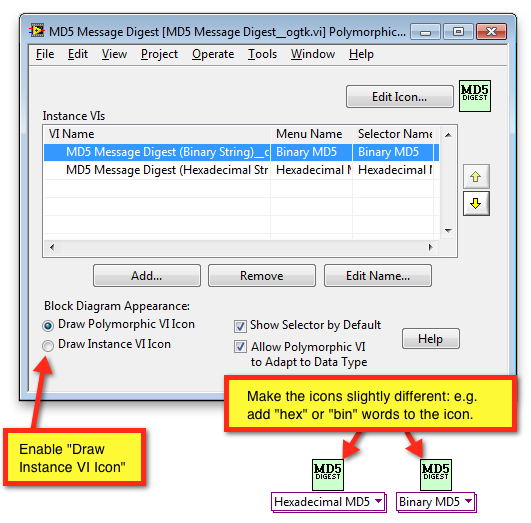
Use Instance VI Icons to distinguish instances
There is currently no difference between the Hexadecimal MD5 and Binary MD5 instance VIs. One can only tell the difference if the Polymorphic VI Selector is visible and many people like to hide that, since it takes up a lot of space. If the Use Instance VI Icons option were enabled and the two instances' icons were different (to reflect the output MD5 encoding), then it would be really helpful.
-
It e.g. allows you to check for an error from a specific task, handle it (e.g. clear it) whilst persisting error information from previous code (upstream).
Normally I would merge this external to the VI, but I like the fact that the merge is included in the VI (one less thing to do).
That's right. It's a real space saver to not have to merge errors as a separate function call. And, this is a standard that I hope can be adopted, if others agree that it makes sense.
Note: I think we should add this "upstream error" to the "Clear All Errors" function, too.
-
 1
1
-
-
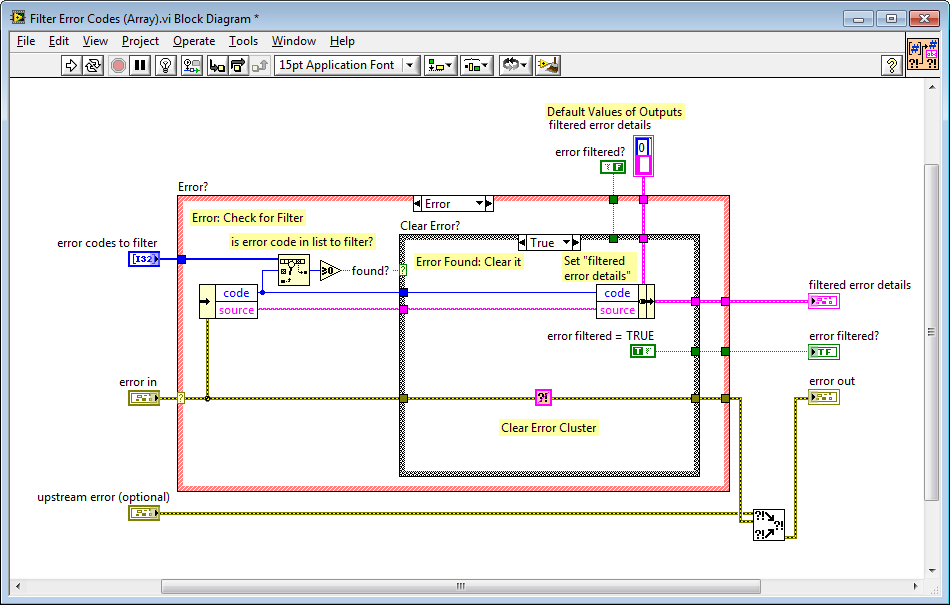
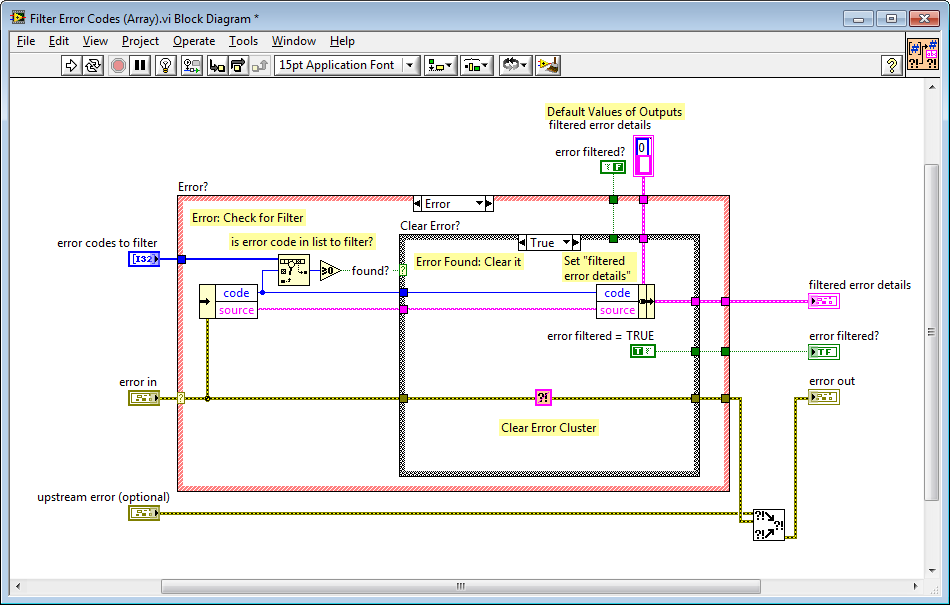
Quick design question - why pass out and maintain a new data-type (which is a subset of Error cluster) when an Error cluster could just be passed out?
Great question! We actually had a long debate about this at JKI, back when this function was designed.
If I recall correctly, here is the thinking behind it:
- it avoids the possibility of accidentally confusing (miss-wiring) the filtered error details with error out
- most of the time (e.g. the scalar error code to filter use case) you only care about the Boolean output error filtered? (e.g. wiring it up to a Case Structure's case selector or similar) so we decided to make that raw Boolean an output of the VI, rather than requiring the user to unbundle it from the filtered error details.
- in the case where you want more information about the filtered error (like if you passed in an array of error codes to filter and need to know which one occurred), then you can unbundle the code or source string from the filtered error details cluster.
- We didn't include the Boolean error filtered? in the filtered error details cluster since that would be redundant (the Boolean is already an output of the VI). And, if we did actually add the Boolean error filtered? to the filtered error details cluster, then it would look a lot like an error cluster and we would then probably want to name the Boolean status (since that's what it's called in a normal error cluster), which does not convey the intent nearly as well as calling it error filtered?.
- We didn't include the Boolean error filtered? in the filtered error details cluster since that would be redundant (the Boolean is already an output of the VI). And, if we did actually add the Boolean error filtered? to the filtered error details cluster, then it would look a lot like an error cluster and we would then probably want to name the Boolean status (since that's what it's called in a normal error cluster), which does not convey the intent nearly as well as calling it error filtered?.
And, after years of using this VI, I don't have any complaints about the design of the VI (and haven't heard any complains from others at JKI)
- it avoids the possibility of accidentally confusing (miss-wiring) the filtered error details with error out
-
Hi All,
This is a great discussion!
In an effort to support this, JKI has decided to donate (to the community via BSD license) a couple relevant VIs into the mix, in the hope that they might contribute some design inspiration to this discussion:
JKI - Clear All Errors and Filter Error Codes.zip
The first VI is called Filter Error Codes and filters either a scalar or array of integer error codes. It also returns the information about the error that was filtered, which is useful for handling that error.
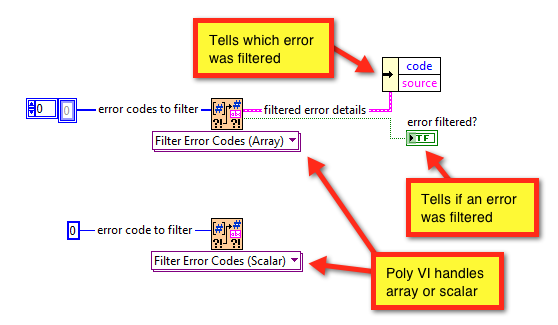
This is what the array implementation looks like:
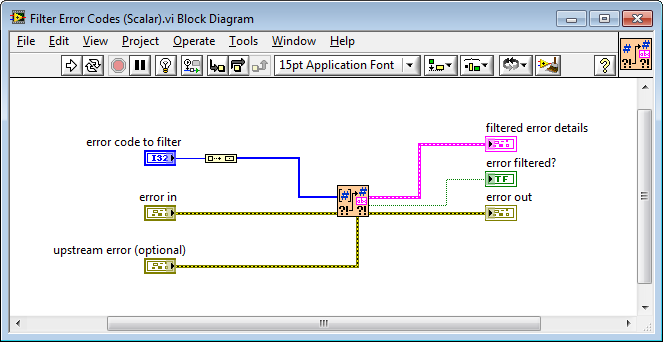
And, here's what the scalar implementation looks like -- you can see it just calls the array implementation.
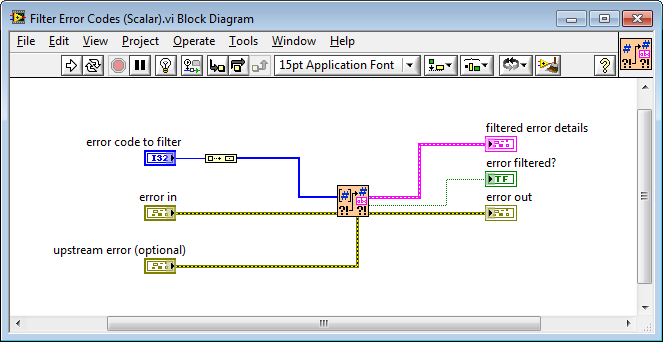
The second VI is called Clear All Errors, which is just like NI's Clear Errors, but a lot more compact, which is nice
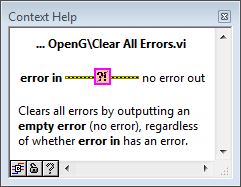
Cheers!
-
2
-
-
-
I'm wondering if there's anything like the LabVIEW add-on for Lego Mindstorms NXT, but for Lego Wedo, that lets you directly control the WeDo motors and sensors with LabVIEW. If so, that would be super cool.
Our Lego WeDo Robots Construction Set arrived and my daughter and I are having a blast building stuff. But, I forgot to order the WeDo Robotics Software that's used to write programs and control the robots, so we're not having nearly as much fun as we could be
[update: I found a thread on ni.com that lead me to a Tufts University Center for Engineering Education and Outreach page with a link to a downloadable WeDo LabVIEW Module zip file containing the required VIs and DLLs. I was able to make them work on Windows
 , but not on Mac yet (the .framework wouldn't load)]
, but not on Mac yet (the .framework wouldn't load)]-
1
-
-
- Popular Post
- Popular Post
My preference would be to start simple and only address the most basic, and widely useful, functionality of splitting the input string into an array of single characters. If it's determined that people would benefit from additional functionality, it can always be added later. But, we don't want to risk adding features that people won't need, since every feature must be designed, documented, tested, and maintained, which takes development resources away from other high-value features/activities.
-
3
-
Is there a list of Pros/Cons anywhere? Perhaps a list could be maintained in the original post of this thread?
-
1
-
-
.
'If' this VI is in the string palette and only accepts string (as is) then this can be implied - much like Trim Whitespace (from string)?
I am open to this change.
That's true, that it's implied by virtue of it being in the string palette, but it's name is not scoped to "OpenG String.lvlib" so there's the possibility of a name collision with some other OpenG VI. Also, if someone is using QuickDrop (Darren Rocks!!!) then they won't know that "to Character Array" takes a String as an input.
-
1
-
-
Should this VI be called "to Character Array" or "String to Character Array"?
If there is any interest in making the VI polymorphic, to accept other input data types, then "to Character Array" is preferable (I think). However, if it will only work on strings, it seems that it might make sense to make the name specific and go with "String to Character Array".
That said, are there any other input data types that we might want to support? I don't want to over-engineer this, but it's a question worth asking.
-
Ah, got it.
I've got a calibration object with name, physical channel, scaling, etc... The object has methods to save to and load from XML file. I've coded the serialization into the object. (Hope I'm using the terms right.) Wouldn't this be the appropriate place?
Tim
Ya, that's a good place to do it yourself.
-
Tim: Basically it's a fancy way of saying "flatten" (and "unflatten"). Here's a Wikipedia link to a more formal definition. For example, you could convert an object into a cluster and then write all its data to an INI file using the OpenG Variant Configuration File IO VIs.
-
It would be nice if there were some VIs for dealing with LVOOP Objects, at run time. One VI that I would love is one that could convert an LVOOP Object to a cluster (and vice versa). Ya, I know that this would violate encapsulation (shhh... don't tell AQ), but it would allow us to do stuff like create flexible object serialization tools.
-
Roger.
Unfortunately that spot is already taken

I will have to drop it down a row.
There is also a VVariant palette (which is what the output is)?
Hi Jon,
As long as it's somewhere on the root palette, I'll be a happy camper
But, I don't think it should go on the VVariant palette, since that is for VIs that deal with variant data (at run time) inside of the variant inputs/outputs (at edit time). It makes sense if you think about it really hard, but is guaranteed to make your head hurt.
For example, in the snippet, below, you end up with a VVariant (a Variant containing a Variant containing a String).
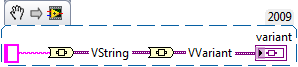
-
Hey Jon,
I'm not sure if putting it in the Type Descriptor subpalette is the best place (since this palette is for VIs that take Type Descriptors as inputs). I think that it probably makes sense to put it on the main, top-level palette.
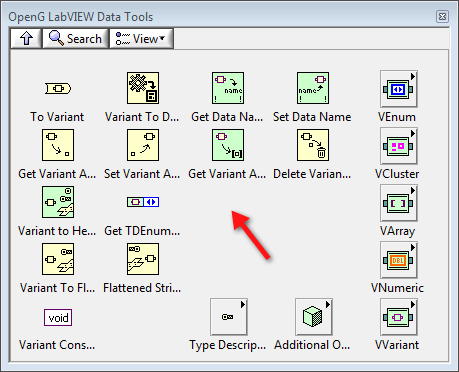
-
1
-
-
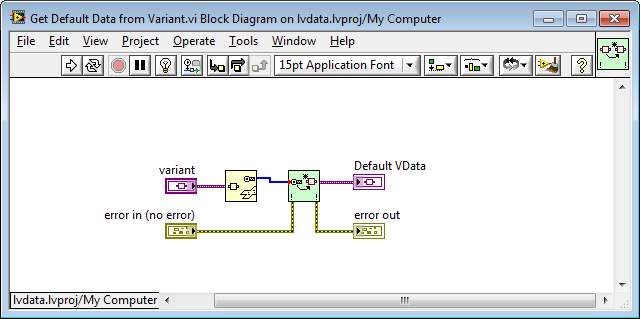
There's a VI in the lvdata package called Get Default Data from TD (that accepts a type descriptor input), but there's no equivalent (wrapper) for variant data input. I suggest that a Get Default Data from Variant VI be added to the library, for symmetry (and the fact that it would be useful -- I've needed such a function recently).
Get Default Data from Variant.vi
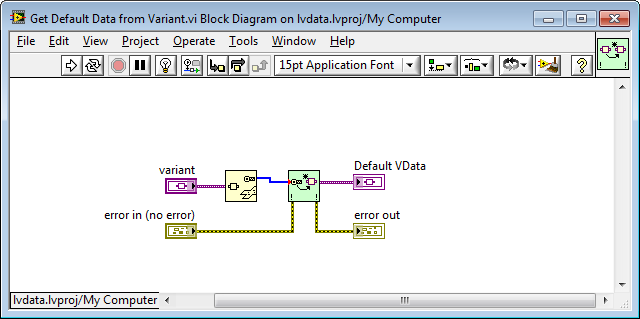
-
1
-
-
Does anybody have a good name for such a functionset?
OpenG Cryptography Library
-
1
-
-
-
Another "major change" that may be worth considering at the same time is whether to put the OpenG packages into .lvlib libraries. Pros and cons?
I created a new topic, here, for this discussion -- it's going to be a hot one and should be separated from the discussion about whether to move OpenG into vi.lib.
-
I quickly wrote a tool using Traverse Refs (thanks D!) to scan the OpenG Library to discover CallBeRef node and if Re-entrant.
Here are the results:
Please comment if you think tool may have missed any VIs etc...
I can add these to DB to be fixed based on outcomes of this performance benefits discussion.
Code in LabVIEW 2009.
Great! That's probably all of them.
(Also, Darren Rocks!!!)
-
For a long time now, me and a couple other guys here have dreamed of being able to drop a "black terminal" which will literally take any type without coercion. I saw AQ's post when he first wrote it and I was excited to see that we're getting closer to having that feature. I wish I knew more about how it was written.
There must be a LabVIEW.ini key that let's you create these.
-
1
-
-
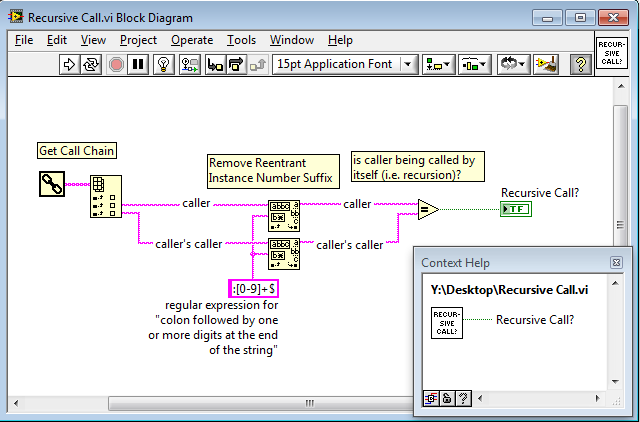
I'm not sure but what is call stack of a recursive VI? Wouldn't that show the same VI name (except for the instance number)?
So we can autodetect it's in a recursive call.
Ton
I think that "call stack" means the "call chain" -- if the caller's name is the same as the current VI's name, then it's recursion.
I threw a small VI together that does this:
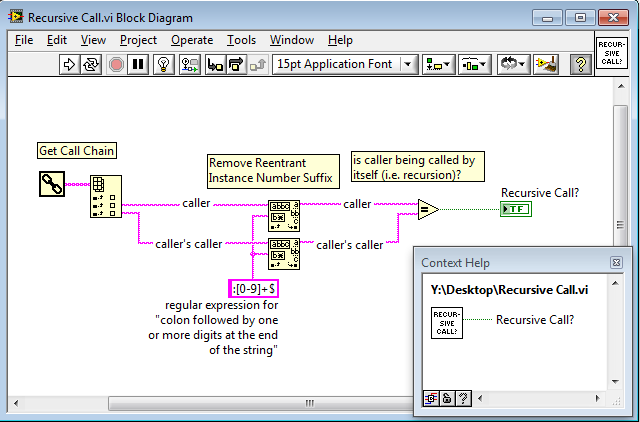
Perhaps this could be a useful OpenG VI. Note that it should probably be improved to test for A >> B >> [C >> [..]] A recursion (by checking for the callers name in any location in the call chain), rather than just A >> A recursion (by only comparing the caller with the caller's caller).
My guess is that passing in a parameter indicating that it's a recursive call is probably a bit faster than programmatically inspecting the call chain.
Feedback on OpenG MD5 Library 4.1.0.8 Release
in OpenG General Discussions
Posted
Ya, I wasn't blaming you