GeorgeG
-
Posts
25 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by GeorgeG
-
Actor Framework - Too much coupling?
GeorgeG replied to GeorgeG's topic in Object-Oriented Programming
The distinction between an actor and a service is somewhat lost on me. -
Actor Framework - Too much coupling?
GeorgeG replied to GeorgeG's topic in Object-Oriented Programming
Thanks for pointing out that white paper. I hadn’t read it and it was enlightening about why the Actor Framework is the way it is. The coupling section is interesting, but it seems really quite difficult to get the zero coupling case. I am wondering if I have been using the Framework in an efficient way. Suppose we have a brain. The brain has eyes, feet, and a mouth, which itself has a tongue. The eyes report position and the feet can walk. The brain starts the feet walking until it is happy with the position reported by eyes. Maybe the brain wants to do something else while walking: chew gum, perhaps. So now the brain is walking and chewing gum until it is happy with the position and until the gum doesn’t taste good anymore (as reported by tongue). When thinking about such a system, the actors seem obvious to me: they are the nouns... but the relationships (callers and callees) and the messages and routing are not very obvious and seem to impact the flexibility and ease of expansion quite a lot. It seems like the Actor Framework should really handle this kind of poorly specified, feature creeping situation well, but in practice the experience is frustrating. Actors can’t talk to each other the way I need. I end up making messages that just route messages. I cheat and expose a queue. The software is really devolving now. For example, I might make the mouth actor, which has a nested tongue actor. Tongue is periodically reporting what it tastes. Brain needs to give this information to the chewing task to decide if the gum is still good. I end up sending a message to mouth that just repackages the information and sends it on to brain. But this is too much work and doesn’t add anything to clarity (for me anyway). It gets worse when brain is just repackaging the information to send back down an actor hierarchy to one (or more) subordinate tasks. It makes me want a “Tastes Like†message that tongue can send out to “registered recipientsâ€. Other actors can route the message through the tree to the destination without knowing anything about the contents (like the post office). But that white paper claimed that such a messaging philosophy is fraught with perilous race conditions and deadlock. What are the “good†ways to get the “Tastes Like†message to the “chewing†task? Or have I set the problem up poorly such that the previous question is ill posed? -
I've used the AF three times now in delivered applications and I am finding it is "just okay". I really like the concepts that it embodies, but its implementation of the details is very frustrating. My biggest gripe is in the coupling between actors. If I am actor A and want to send actor B a message, I have to call a method on actor B. Which is fine until I want to send the same message to unrelated actor C. It seems like actor A needs to “know†too much about the destination to be able to send messages. Next on my list would be how incredibly easy it is to write an unreadable application with AF. Coming back to code from 6 months ago, I find I am totally lost and have to rely heavily on external documentation to follow even simple operations. Now I admit it could be my AF programming style is the problem… or maybe it’s the AF. I’m not sure. And then trying to follow the flow of events and information through a program built on AF… I don’t have much fun doing that. Which leads into my next gripe: it is quite a complicated process to launch nested actors, generally requiring me to modify the private class data of something to store a message queue refnum. And then routing messages between actors seems really fussy, requiring me to pass around these queue refnums, usually through modifying more private data to include more queue refnums or adding more messages to ever more actors that just route messages. Finally, I wish it was easier to monitor. Which actors are running? Which are sending what messages when? The AF concept seems so well suited to address all of these problems (reduced coupling, simple message routing, built-in debug/monitor) that I don’t understand why they aren’t present. These are my thoughts on the AF that I have been stewing and chewing on a while. And now I am really wondering if others have had similar experiences with LabVIEW’s AF or if it’s just me using it “wrong†or having unrealistic expectations. Feedback, please! And thanks!
-
I've been looking for information on the details of what LabVIEW really does with these two different parameters specs. There doesn't seem to be much Google knows about the difference between the two (besides the obvious, one is handle and one is a pointer to a handle), or why you would use one vs another. I am working in the context of returning data to LabVIEW from external code, where I want to allocate memory in the external code. I understand about LabVIEW's handles, and what a pointer to a handle means. Why would you chose one of these paramter specs over another? From testing it seems that if you say "Handles by Value", LabVIEW will ALWAYS allocate a handle for you. However if you say "Pointers to Handles", you might end up with a NULL handle (but NEVER a NULL pointer). It seems straightfoward to allocate or resize handles thought, so I don't see the advantage to one spec over the other. Where does one find more information on these low-level details and questions about the Call Library Node? George
-
Thanks Rolf! I thought I'd written code quite similar to yours, but it didn't work. Following along with your suggestions I did get something working... go figure. Pointers and handles are tricky beasts... not so impossible to understand, but very devil-in-the-details. I wasn't able to use the DSSetHandleSize function though... anytime I executed that branch of code an exception would get thrown (somewhere else). So for now I am just deallocating the whole thing, disposing the handle, and starting over (instead of trying to "resize"). Thanks again for your help!
-
I'm not exactly sure what you're trying to do, but I took a stab at it anyway. Does this VI do what you want? Crude on-off event.vi
-
I am trying to use the LabVIEW memory manager functions (DS/AZNewHandle,DS/AZSetHandleSize,DS/AZDisposeHandle,others) to populate the array of clusters shown below. The number of elements and the string lengths will not be known before the DLL call, so I am really trying to make it work as shown. I've tried quite a few combinations of Type/Data Format/Manager Function calls, but I consistently crash LabVIEW or create severe memory leaks. It isn't even 100% clear to me whether this is in Data Space or Application Zone. Google has been decidedly unhelpful. Can anyone help me /* insert code here */ (see below)? DLL Code generated by LabVIEW (right click on node and "Create C File": /* Call Library source file */#include "extcode.h"/* lv_prolog.h and lv_epilog.h set up the correct alignment for LabVIEW data. */#include "lv_prolog.h"/* Typedefs */typedef struct { int32_t Numeric; LStrHandle String; } TD2;typedef struct { int32_t dimSize; TD2 Cluster[1]; } TD1;typedef TD1 **TD1Hdl;#include "lv_epilog.h"int32_t funcName(TD1Hdl *data);int32_t funcName(TD1Hdl *data){ /* Insert code here */}
-
Do close primitives that return errors cause memory leaks?
GeorgeG replied to GeorgeG's topic in LabVIEW General
I think this is what I am trying to wrap my head around. To do any local error handling I need to know what happened and what didn't happen right? If I tried to enqueue an element into a queue and I get an error from the enqueue function, I need to know what happened to the element before I try to do local error handling... local error handling shouldn't enqueue the element again if the operation was successful notwithstanding the error. Is it possible for that to happen? I'm not talking about specific error codes here. I just want to know for sure whether the element got into (or out of) the queue. Is the presence of any error enough to definitively say nothing was enqueued or dequeued? -
Do close primitives that return errors cause memory leaks?
GeorgeG replied to GeorgeG's topic in LabVIEW General
So you could follow an Open with a Close-if-Error and that way you could make the open either fully succeed or fully fail. What about Enqueue or TCP write (or any of the others)? Is there a way to know whether the fuction failed completely? -
Do close primitives that return errors cause memory leaks?
GeorgeG replied to GeorgeG's topic in LabVIEW General
Whew, that really helps me constrain my thinking about how to deal with Close and its errors. Along similar lines I have been trying to understand what happens with the non-close primitives. Let's start with Open... if it returns an error, does that mean I am guaranteed that the open failed completely? That is, might I be left in an ambiguous partial state where some resources were allocated, but the open still failed? And is that behavior consistent? Obtain Queue, Open TCP Connection, Open VI Reference, etc And then the VI's that do work (like enqueue, TCP write, Start Async Call, Generate User Event) return errors, does that mean that they failed completely? Is it possible the function was actually successful, but still returned some kind of error? In a more general sense, I am trying to work out how I think about error handling down at this level. I have started to ask myself, well, if such-or-such VI returned an error, I can assume it failed, and if it failed, what should I do next. But then I started to wonder how safe the assumtion of failure (or complete failure) was, and I am not really sure how to go about testing the primitives under different error conditions. I guess this is a pretty low level question and based in paranoia, but just because I am paranoid doesn't mean the bugs aren't out to get me... -
Do close primitives that return errors cause memory leaks?
GeorgeG posted a topic in LabVIEW General
The close/release primitives for things like files, queues, notifiers, VISA references, TCP sessions, Application/VI/Control refnums, etc have an error out terminal. Many return error 1 if the input refnum is invalid (like a constant) or has already been closed. Close reference for VI server seems to return 1026 under the same conditions. What other conditions could cause a close function to fail besides having an invalid or previously closed input reference? Assuming there are other conditions, if a close function does fail, does it create a memory or resource leak? If by chance there are different answers, I am working in three contexts: IDE, runtime, realtime. (All 2012) -
I have some projects on the horizon that have to be more reliable than anything I have done in the past. And this new requirement has me thinking about how I deal with errors in LabVIEW more and more. Simultaneously I have been looking into the Actor Framework. The sample project in LabVIEW 2012 for the Evaporative Cooler does a great job of showing how many of the pieces of a full application fit together. However, as I have studied the example, I have noticed that in many places error handling has simply been ignored. An example of this is in the water level control... specifically, I take issue with the word "guarantee". Documentation states: "Water Level is a concrete implementation of a Level Controller. We will use it to guarantee that the water in our evaporative cooler’s reservoir never falls below a minimum safe level." What if the building loses water pressure? Or the piping fails? Or the valve doesn't actually respond? Or any of a million scenarios that result in the program being unable to really guarantee anything. I'd like to open a discussion of how the Evaporative Cooler example could improve on its error handling so that it was robust enough to safely deal with all the "what ifs" of the world. This question is covering everything from "what if writing to the value property of a UI indicator fails?" to "what if the building water supply fails and the water level doesn't respond when I command the valve?" And those seem like two great places to start! In the context of the Evaporative Cooler example project, I found three VIs whose error handling I would like to discuss: 1. Timed Loop Actor.lvlib:Timed Loop Actor.lvclass:Read Controller Name.vi 2. Live User Controller.lvclass:Update Current Temperature.vi 3. Level Controller.lvlib:Level Controller.lvclass:Update Core.vi In the case of #1, the VI does not have error in/out terminals, but some of the VI's it calls does. This is a situation I have encountered before: how do you add error handling to a very low level VI that does not (and for the sake of discussion cannot) have error terminals? In the case of #2, the VI writes to a property node and ignores the error terminals. In a big application there are soooo many property nodes! What are the implications of ignoring the errors? When is it safe to ignore them? This is probably very common, and has some overlap with #1... In general, in LabVIEW, when can you ignore error terminals? #3 is the logic VI that determines whether to open or close a valve based on water level. But it doesn't keep track of time and whether things are "working". And certainly if you put a human operator in place of the VI, the human would after some time decide that opening the valve hadn't helped the water level. Can the VI mimic this? For all of this error handling business, I think I am really asking four questions: A) What should the software do on its own to respond to the error? B) What should the software tell the operator (who might have never heard of LabVIEW or college) about the error? C) What should the software tell the operator's supervisor about the error? D) What should the software tell the software developer about the error? It is pretty easy to write an application when everything works the way it should! But when things might go haywire, how do you write application then?
-
I am looking for a list of errors that could be returned by the things in vi.lib. I've tried searching, but the search terms are pretty generic and I get lots of links to the list of ALL error codes. But I want to know the (exhaustive?) list of errors that could be returned by each VI (like Enqueue Element, or Release Notifier, or Property Node). Does such a thing exist? It seems hard to do really good error handling without it... And hard to know what kinds of things will give the code trouble.
-
Well I played around with some other apps on windows to see if there was a "standard" behavior. And it's true that nothing else really behaves the way LabVIEW did. That being said, LabVIEW still doesn't behave the same was as other Windows apps (at least on Win7). Both explorer and google chrome require you to release the right mouse button before displaying the context menu. *shrug* It isn't exactly the apocalypse... just one of those little things that irritates. In fact, the change was so subtle I first thought my mouse button was starting to break.
-
Argh! I lose again. First it was the great palette shuffle caper. Now it is the right click menu! It is funny how something so tiny gets ingrained into such a strong habit. In 2011 and before you could right click a thing, hold the right button down, navigate to your choice and release. Now when you let go, LabVIEW just stares dumbly back at you. But hey, conditional tunnels! Yay.
-
Unflatten LabVIEW class works until built in application
GeorgeG replied to GeorgeG's topic in Object-Oriented Programming
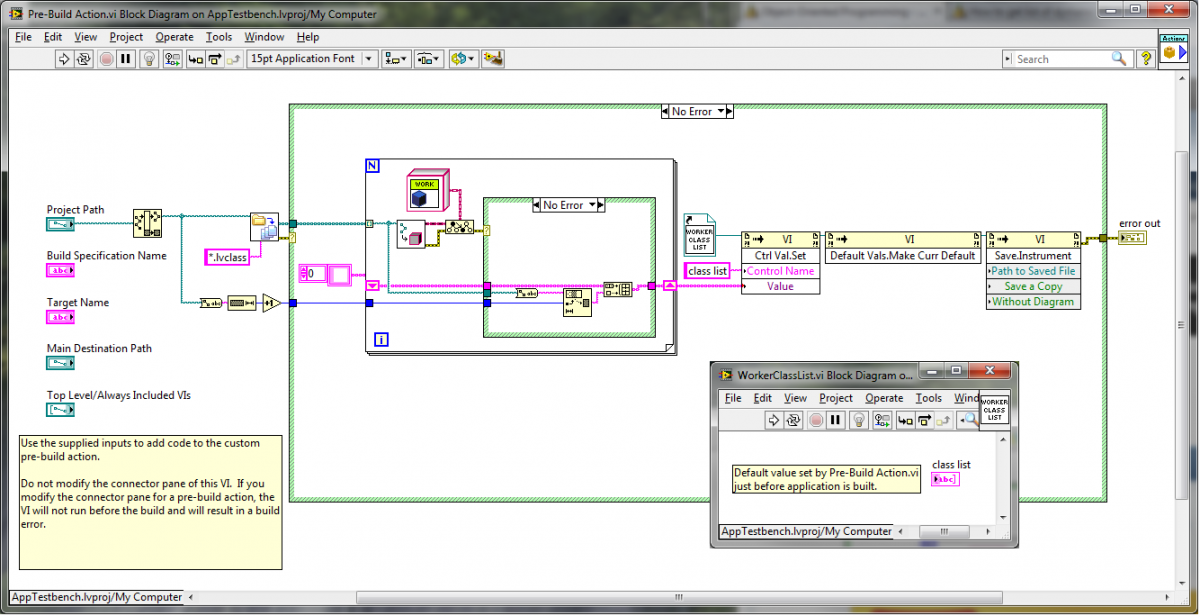
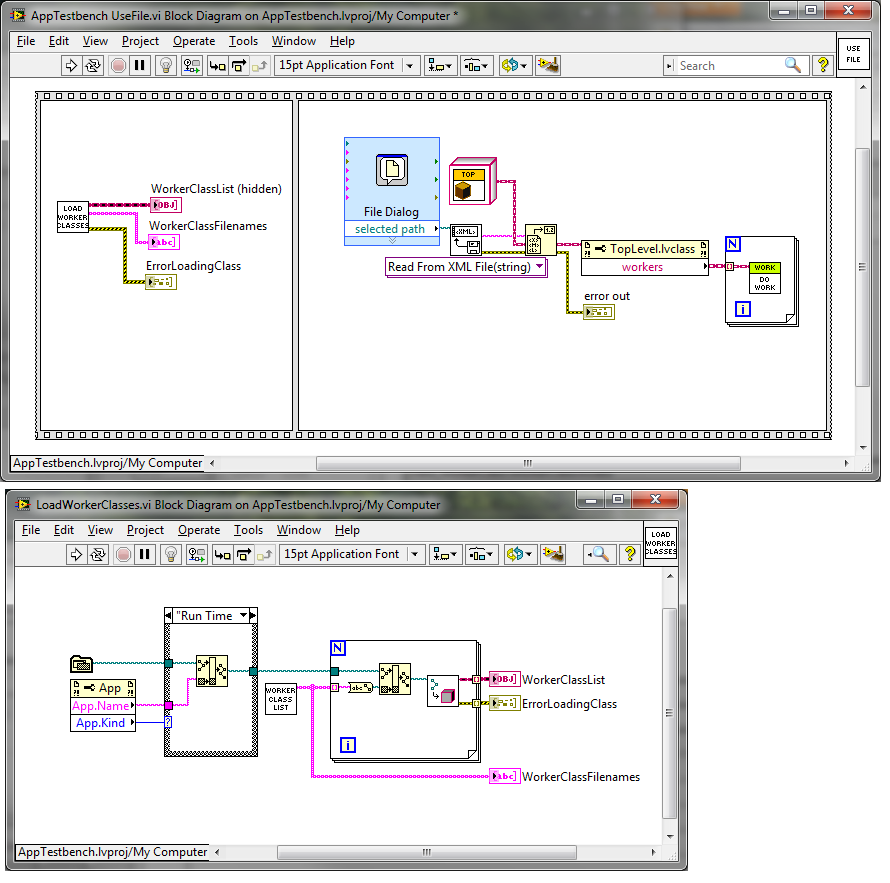
Well, I am pretty sure it is a simple class not in memory problem. Pity LabVIEW didn't offer that in the error message in the first place. Anyway, getting the classes loaded seemed trickier than I thought it would be. So maybe there is a better way? My solution was to add a pre-build action to store the relative paths to the worker classes. Then the application can use that information to dynamically load all of the worker classes before it does anything else. Pre-Build Action: Changes to top level vi:
-
Unflatten LabVIEW class works until built in application
GeorgeG replied to GeorgeG's topic in Object-Oriented Programming
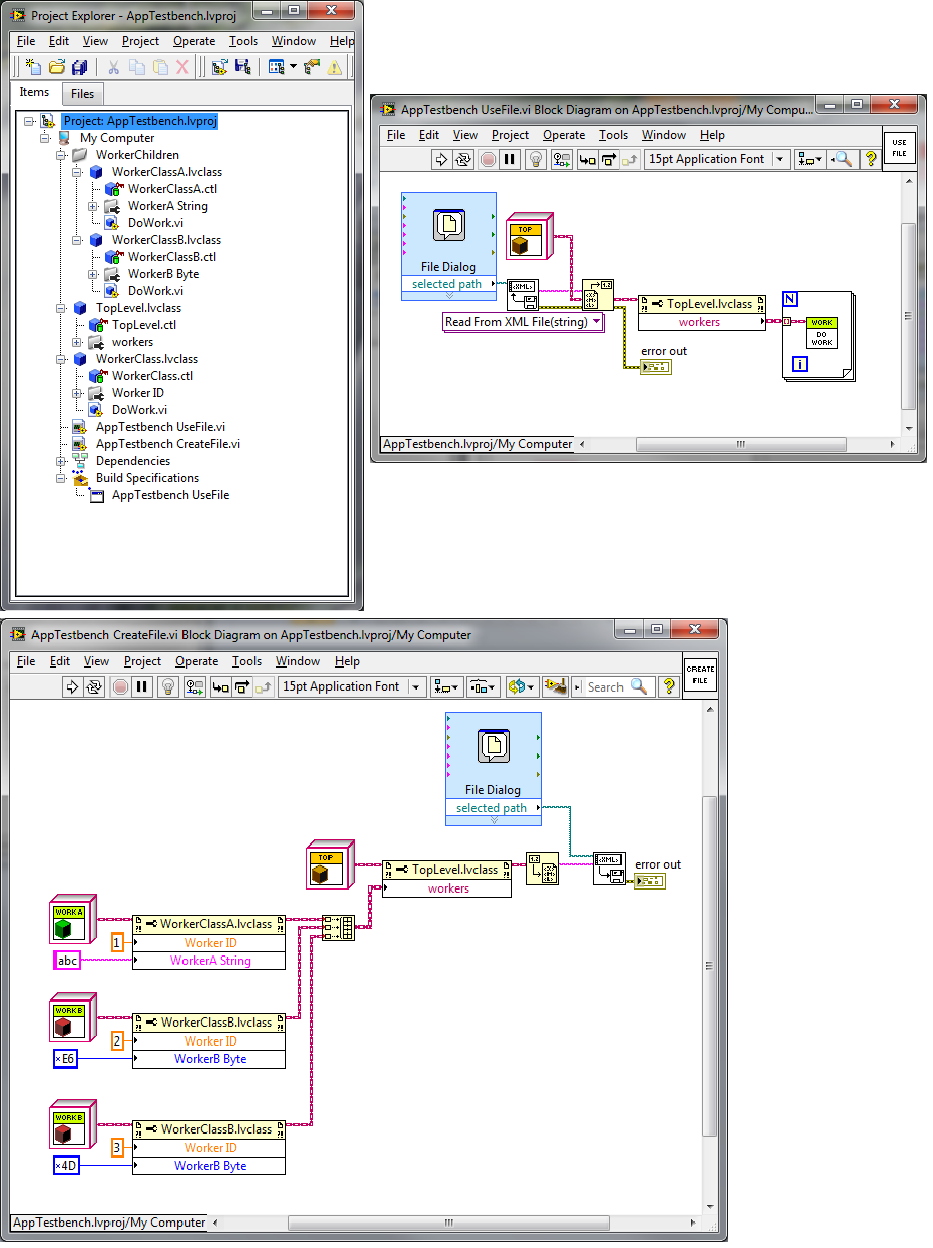
This works in the development environment, but fails with error 1403 after it is build into an application. Add class constants for WorkerA and WorkerB to the diagram of "UseFile" and the application will run without errors. So it does seem to be a class not in memory problem, but putting constants on the actual block diagram is not a solution I like, since there are lots of worker classes, and I will add new ones regularly.
-
Unflatten LabVIEW class works until built in application
GeorgeG replied to GeorgeG's topic in Object-Oriented Programming
That is a good question. No, I don't think they are. The specific worker-class children don't have any constants or controls/indicators anywhere in the application. The files are generated by a different application (but part of the same project). What is a good way to load them all into memory before reading the file? -
I have a class hierarchy something like top-level-class, which has no children, but contains an array of worker-class objects. There are about ten specific types of worker-class, all children of parent-class. The array usually only has a few types in it at any given time. Now I want to save top-level-class to a file. I have tried flattening to xml and saving as well as just using the write binary primitive. In both cases I get the same result. Everything is fine and dandy in the Dev environment, but fails in the build application when I try to read the file from disk. I get: Error 1403 occurred at Read from Binary File LabVIEW: Attempted to read flattened data of a LabVIEW class. The data is corrupt. LabVIEW could not interpret the data as any valid flattened LabVIEW class. In my build spec, I have everything in the project (except top-level.vi) in Always Included (under Source Files). top-level.vi is the startup file. I am at a bit of a loss how to proceed. Has anyone encountered this or have an idea where I might have gone wrong? George
-
Problem solved! Aristos stated the problem exactly, and to fix it and keep the original functionality unchanged, I replaced the Refnum with a string in the private data, and in the accessors I added code to flatten and unflatted from string. Thus the refnum is still stored in the class, and no code outside the class had to change, and I was able to hide from LabVIEW that ugly strict refnum it seems to hate so much. I would still like to hear why this is a problem, and, more importantly, why it is not stated more clearly by the compiler or the application builder. I want my two days back! George
-
Found this post from a thread in February: And I do indeed have such a strict VI refnum in the private data of a class. This is a "bug"? Why does this compile in the development environment, but not build in the application builder? Is there a work around? And taking that out of the private data and turning the corresponding accessor VIs into stubs fixed the build problem. Is there a reason the compiler doesn't complain about this situation or a reason the compiler and the application builder treat it differently?
-
All VIs are definitely closed when I try to build the application. I think I have, however, narrowed the problem down to something about the XControl or its underlying classes. I have created a new, empty project and added the XControl and the associated class. I then created a top level VI with just the XControl on its front panel. This will not build. Unfortunately there are still some 200 VI's involved, so I still don't have a clear idea of what is causing the problem.
-
Moved the whole project to C:\project\ and tried to build it, but got the same error message. Thanks for the idea though! I fear the problem is something obscure like this Since I made my original post, I have been playing around with a nearly empty top level VI trying to find the simplest VI that wouldn't build. Right now I have a class object constant wired to a default indicator of that class, and won't build.
-
1. All of those VIs in the error message are NIs. I assume they are the code of the application builder. 2. That is what I am doing right now, and still haven't isolated the "broken" VI. When making a top level VI from scratch and just adding tiny subsets of the functionality, I can get it to build sometimes, and not others, but I still haven't discerned the pattern. I can have the exact same sequence of VI's, and just change which class object is at the front of the chain, and that is the difference between building and failing. I didn't mention in my original post, but I also make extensive use of dynamic dispatch with the classes.
-
I am in the middle of code development for a big application (500 VIs currently) on Windows XP with LabVIEW 2009 SP1. The application currently has 24 classes, 3 levels of OO inheritance, one XControl whose data type is one of the classes and uses the friend scope, lots of VI server calls (dynamic VIs, reentrant dynamic VIs, property and invoke nodes, etc), and a couple of external DLLs. In the development environment everything runs wonderfully. Mass compiling the project shows no bad VIs, but an attempt to build the top level VI into an application fails immediately with Error 1003 (shown below). I have googled and googled, and this seems to be a common enough problem, but none of the solutions I have found have gotten me any closer to an executable. I have tried disabling blocks of the diagram to try to find the offending VI or VIs, but no luck there either. If I disable the entire diagram it will build, but I have not been able to disable anything less than the entire top level diagram and get it to build. I have also tried many build configurations, including keeping all of the front panels and block diagrams, disconnecting type definitions, telling the application builder to include all of the VIs in the build. I am running low on ideas of how to even start narrowing down the problem to a specific class or VI. The single, unhelpful, error message is below. Any ideas? George The VI is broken. Open the VI in LabVIEW and fix the errors. Visit the Request Support page at ni.com/ask to learn more about resolving this problem. Use the following information as a reference: Error 1003 occurred at AB_Application.lvclass:Open_Top_Level_VIs.vi -> AB_Build.lvclass:Build.vi -> AB_Application.lvclass:Build.vi -> AB_EXE.lvclass:Build.vi -> AB_Engine_Build.vi -> AB_Build_Invoke.vi -> AB_Build_Invoke.vi.ProxyCaller Possible reason(s): LabVIEW: The VI is not executable. Most likely the VI is broken or one of its subVIs cannot be located. Select File>>Open to open the VI and then verify that you are able to run it.