

JamesMc86
-
Posts
289 -
Joined
-
Last visited
-
Days Won
12
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by JamesMc86
-
-
Hi All,
I was hoping to crowdsource some of your experience today on a common application architecture that is bugging me slightly, but I can't decide whether it is genuinly bad or if it is just me. In the spirit of Steve Watts talk at the European CLA summit, something stinks!
The problem statement it solves is, I have multiple data sources, let's say they are the same rate but I have seen different rates as well, that I want to log to disk as a single file. I have seen the same solution several times involving FGVs, this is what makes me nervous!
What they do is have a seperate DAQ process per source of data and a single write to file process. Then either a)They have an FGV per DAQ process or b)A single FGV that different process write into different points in an array. Then in the log to file they either a)read from all FGVs or b)read from the FGV. I don't like this because:
- There is no buffering, the only thing that guarantees getting the data is that the various loops stay in phase.
- FGVs make the code pretty hard to read.
But it is hard to rip it to shreds when fundamentally people are succeeding with this. What I am interested in is what you guys have found to be a good solution to this problem. Ideally the data should be buffered which points to using queues, but another smell to me is waiting on multiple queues in one loop. One thought I have had is to have a data collator process, this would have to wait on multiple queues but then outputs the single set of data, or is this just b) from above again? I think this could be done in the actor framework as well where the collator then spawns the various DAQ actors.
So what are your thoughts, is there a deodorant to this or is this problem always going to smell!

Cheers,
James
- There is no buffering, the only thing that guarantees getting the data is that the various loops stay in phase.
-
On first glances there are two sections of the code I would want to double check the logic of, not sure if its wrong, but looks like a potential source of data loss.
One is where you and output valid of the FFT with less than 512. I am not sure exactly what this is doing yet but if those two disagree then data would be lost.
I am also trying to work out your logic for writing to the Frequency Spectrum FIFO. It looks like you are enabling everything off ready for output rather than output valid. Typically I would check first for Number of Elements to Write for the queue and use that as the ready for output flag.
EDIT: I think I see what you are doing now and it looks like it should work but the counts will tell you.
I guess your Valid FFT Out vs Elements loaded vs Valid outputs counts should suggest which of those is the problem.
-
The PXI trigger lines are great for this as is TCLK for really tight synchronisation.
If you search the respective help files for state diagram there are a series of diagrams that show the states of the hardwares and most importantly the different trigger signals that are generated so you can see what can synchronise the right parts.
T-Clock is a technology on PXI for very tight synchronisation of most modular instrument boards from NI (The have to be based on the SMC architecture). I am pretty sure that all of these boards meet that (The 653x doesn't but I think the 654x are) and this gives typical skew of 200-500ps. Check this and see if it is what you need: http://zone.ni.com/devzone/cda/tut/p/id/3675 but you may get by with just the correct trigger signals.
Cheers,
James
-
Hi Austin,
If you are doing high speed control the RT/FPGA are much better for this. Doing control ideally should be done on single point data, no queues as the introduce latency to the system but everything we do on windows tends to use buffers of some form to get the performance required for DAQ.
Perhaps if you post a little more information on your FPGA issues we can suggest some improvements to make it fit.
Cheers,
James
(null)
-
Hi Mike,
There used to be some standard functions that supported different data types in the HIgh Performance Analysis Library (HPAL). Not sure about extended but I know they went the other way and implemented some in SGL. I went to the NI labs page but it looks like it has been pulled but there is a beta program where the functionality has been moved to. The page is at https://decibel.ni.com/content/docs/DOC-12086 with the address for the beta program if you were interested.
Cheers,
James
Scratch that. Remembered I still had the HPAL library installed to LV 2010 and check, it has SGL support but not EXT, sorry for the confusion.
Cheers,
James
-
Just be aware that the spreadsheet to array functions will work if you save to a csv or tab delimted file from excel, but the XLS or XLSX files are harder to get into LabVIEW because they have to come in through automation of office rather than acting on them directly (unless there are some third party tools out there for it now).
Cheers,
James
-
Hey Nitin,
Do check out the guide as well. Both of those are good techniques but it depends on the type of data you are transferring that will decide for the best on a case by case basis. For example if you need to stream continuous data the RT FIFO is the best inter-process but then over the network then network streams are much better than shared variables. There is rarely a catch all technique.
Cheers,
James
-
Hi Alex,
With the multiply I think you should be OK. As you said it returns within one cycle and this means it will return its output in the same cycle when it is called in the single cycle timed loop. I wouldn't go as far as to say all as there may be other elements which can't return in one cycle (e.g. is there reciprocal in high throughput? EDIT: I guess not as this is what you are doing!). I think the overhead is minimal if you enable the handshaking when available.
The one problem with the code above is what happens if the output FIFO is full? To truely complete the four wire handshaking on the divide you should handle the time out case there which involves latching the divide output until you know it has been succesfully read, I think there is an example of this in the FFT shipping example.
Cheers,
James
...or to avoid latching I think you could do it just with checking the queue status has a space (available elements to right). If this is greater than 0 then set ready for output on the divide.
-
 1
1
-
-
Check out the cRIO developers guide at www.ni.com/compactriodevguide. It has a whole chapter on this, even if you are using a different RT target the same should apply.
Cheers,
James
-
2
-
-
Hey Wim,
Definitely using the digital input as a clock is easiest. Don't think it will do rising and falling edge natively though but I remember seeing schematics for a basic circuit which can take care of this.
Cheers,
James
(null)
-
Hi,
This was actually released with LabVIEW 2010. The product page is at http://sine.ni.com/nips/cds/view/p/lang/en/nid/209015
Cheers,
James
(null)
-
Now I have managed to look at the video properly on my laptop it appears he is not referring to that board but a Xilinx board called the Spartan 3E XUP (Xilinx University Program). There is an old thread discussing this at http://lavag.org/topic/10838-spartan-3e-fpga-board/ but the long and short is that it is a board from Xilinx for academics and we have written a driver for it, but you have to agree to be using it for academic purposes.
The page describing this is at http://digital.ni.com/express.nsf/bycode/spartan3e and there is some training material for it available at http://zone.ni.com/devzone/cda/tut/p/id/6848 if you take the plunge!
Cheers,
James
-
I think in the video he is probably referring to the academic top board at http://sine.ni.com/nips/cds/view/p/lang/en/nid/207010. The is no way to generate the VHDL for non NI targets from LabVIEW FPGA.
Tge top board may work for you. Have a look through the manual but I believe you could power and use it without the ELVIS. You can also target this using Xilinx ISE and by drawing digital schematics in Multisim (requires particular versions of ISE to script but it's pretty cool!
The next cheapest way onto the platform would be the single board RIO eval kit. It has recently dropped in price and included 180 days of FPGA and RT.
Hope this helps!
-
Hi,
Thanks for the point about the data buffers. I had not experimented much with the buffering but it certainly does improve the situation (I will upload a comparison to the NI community shortly)
EDIT: If you want to see the effect of buffers I have now uploaded code to https://decibel.ni.com/content/docs/DOC-20522
I think this discussion sums up that the whole decision comes down to the fact it is going to depend where you want the data to end up. TDMS is easiest the NI ecosystem although I have had people impressed with the way the data is pulled into excel (theres also a plugin for open office) and the C dll does allow it to be added to custom applications (including Matlab). If you need the data to work with notepad or another specific program then you have to stick to with an ASCII format or a custom binary format that the program supports.
Where I would say TDMS is a must is when your talking big sizes. With the advanced API you can actually write to disk faster than with the standard binary VIs and dealing with large files requires the random access available in the API or with DIAdem's ability with large data sets.
-
Hi Alex,
This is expected behaviour. LabVIEW does not identify the subject of a dynamic call as a dependency because this could change by you changing the path. The same is the case on Windows but this is not so much of an issue because all the files are on your local system anyway but on RT they have to be deployed down.
Not sure if there might be an easier way but you could whip up a VI that uses the project API to programmatically deploy the VIs in one hit to make your life a little simpler. I haven't used a huge amount of dynamic VIs on RT so there may be a better way. (See Mads last paragraph as well).
Cheers,
James
-
Hey Guys,
Thanks for your advice. I have been looking through the properties I have in the project API and it does appear I can get all of the callers/subVIs through that so I can remove those arrays.
I will still use OOP for dynamic dispatching but it will like be a wrapper for the existing objects.
(null)
-
Just one bit to add. The method you have described with the exe is great. But just FTP often wont work because the VI is compiled for Windows. You should use a source distribution to move VIs to the target as this will recompile them for the target.
Cheers,
James
(null)
-
The reason I was looking at by ref is to make sure I have one object with all the information before generating the page. Part of the issue with the original code was it got complicated editing the existing pages. I figured it will easy easier to generate the whole page at once.
I suspect you may be right though that a I could be missing a simpler method!
(null)
-
I have been working on some basic experimentation with OOP and want to apply it to a project that I have wanted to do for a while.
At university I created a VI that would traverse a LabVIEW project, print a HTML page for each subVI etc. and then create a home page and link the pages together. It worked quite nicely but when I started to look at additional features or customisation I knew that it was not scalable enough and I would treat that as a prototype and start from scratch. That was 2 years ago now and I am finally looking at it again!
I thought back then that OOP is going to be the best way to approach this and it's a good chance for me to write a largish OOP application (I have used bits before and understand practicalities but not some of the higher level design priniciples). Attached is an initial class diagram which is currently fairly simple. The basic idea is:
- The project class to generate my ProjectItem classes (This will be the parent class for various item types).
- It will generate these as references (I want to only generate a single page for each project item) and store them in a dictionary. For this I have been told that variant attributes are actually highly optimised.
- I will use scripting or similar to find each items subitems (e.g. SubVIs) and generate an array of these references.
- As each subitem is found it will identify itself as a caller to that subitem.
- Then I just have to generate the pages...
My thoughts are that each project item will have an array of DVRs to it's callers and one for it's subitems so that any methods for generating pages should have all the information they need. This however is naughty according to LVOOP as it is a recursive type. I see 2 potential ways around this:
- The children of project items contain their own arrays of DVRs to project items. I believe this is allowed however it seems like I will then be repeating functionality accross these child classes.
- I can "override" LabVIEW and cast the DVRs to I32 or similar and do it how I want. The thing is in my experience that LV has often known better and when I have forced it to do something like that it has come back to bite me in the arse!
- Having just been doing a bit of reading, there may be a 3rd. Is this a case for some sort of delegation pattern?
I would be interested if anyone had any suggestions for best practice on this or whether there is another option that I am missing.
I have just thought of a 4th possibility would be rather than using the arrays of objects and dictionary would be to use a database implementation instead but that feels like overkill for this.
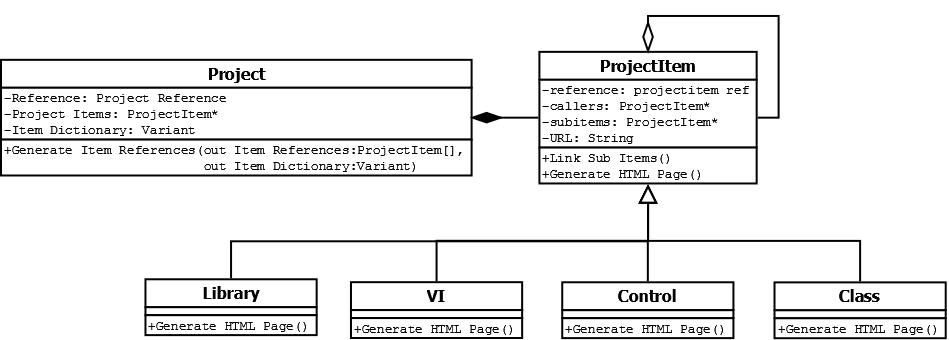
- The project class to generate my ProjectItem classes (This will be the parent class for various item types).
-
I think all the points above are great. I always get a good reaction when showing it to customers and the excel importer can produce easier data to go though that your own text files.
One thing to just be aware of with it is fragmentation. It's a common problem that we see, esp. on embedded platforms where file size is more sensitive. There is a white paper describing the exact implementation but the short version is that each time you use TDMS Write a "chunk" of data is written to file (Im not sure if this is the proper term). If that chunk matches the previous (same channels, datatype, I think size) then it is written just as binary data and maintains the efficiencies. If it does not match then it writes a new piece of XML header data with the data, which is very inefficient. The result is if you mix the reads to a single file your XML header becomes huge, as does your file and your access becomes slow.
The solution is to try and keep to a single write function to stream to disk. If it is unavoidable then there is a TDMS defrag function which will then reduce the size again but this can take some time and CPU.
Don't misunderstand me though, this is the main caveat you could run into but overall the benefits outweigh this (and it is avoidable as long as you know it exists!) you do get extremely compact, searchable data that can be easily shared. To get similar write performance you would have to go to a binary format which means the end user will need a program capable of reading that.
Cheers,
James
-
Hi Hugo,
Nice tool! I have done some work on a similar function for my department but I bottled out a bit on proper right-click integration and just put a shortcut in the send to... menu. What did you find the best way of customising the right click menu was?
Cheers,
James
-
To echo what has been said a bit, using serially directly or through a USB converter shouldn't really impact much other than USB is more widely available. There are hundreds of converters out there, functionally I am not sure if there would be a key advantage to using NIs but it is going to be a higher quality than a cheap converter off eBay!
The USB instrument is an interesting point. My experience when you have this choice is that the manufacturer has simply built the converter in. This is the case where it gives you a virtual COM port in which case there is no reason not to go with that. What I wanted to add is that if it is not a virtual COM port, I would avoid at all cost! VISA USB programming is more difficult than serial.
EDIT: Unless it conforms to USB test and measurement class
Cheers,
James
(null)
-
Hi Val,
Official LabVIEW for Linux support is currently limited to 3 distros (although unofficially I am aware people have managed to run on many more). The key distros targeted are Red Hat and SUSE but support for Scientific Linux has increased in the past few versions. The full support table for Linux is at http://digital.ni.com/public.nsf/allkb/4857A755082E9E228625778900709661?OpenDocument.
From my experience I have tended to come across more people using Red Hat but I think this is an enterprise thing rather than any technical reasoning.
Cheers,
James Mac
-
Another technique for this (but only in 2010 onwards) is network streams. They suit the command model well although the disadvantage is they are 1:1 like TCP so can require an element of connection management.
(null)

TDMS non-contiguous waveforms
in Database and File IO
Posted
I think all of the ideas you have mentioned are valid but the right decision is going to be based off how you view the data (and how much data there is). If you were going to view it in DIAdem or another tool that can plot non-continuous waveforms based off timestamp channel I would be tempted to add a time channel and keep it in one channel (this will also impact your file size of course). If you did do this though you would also need to be aware of file fragmentation (I wrote an comparision of the affects of TDMS fragmentation here: https://decibel.ni.com/content/docs/DOC-20522)
I would probably agree with asbo though, you can add some nice features then like adding the properties related to the trigger as well. But again if the channels are very short you are going to see a lot of overhead from the headers (which will look like fragmentation although is really an expected consequence of the format).