
crelf
-
Posts
5,759 -
Joined
-
Last visited
-
Days Won
55
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by crelf
-
-
Super excited to see everyone tonight!!
-
On 5/9/2016 at 5:36 PM, Reds said:
In short: We are all getting older, our jobs are changing, and there is no organic way for this site to attract new users.
+1
-
- Popular Post
- Popular Post
I'm in!
-
 3
3
-
noob:
DO: Skim through the forum to see if your question has already been answered. Use the search function. You might find a great answer to your question, as well as a bunch of other cool things along the way.
DON'T: abuse the PM feature. Only PM people you know personally. If you want to ask a general question, ask it in the forums: you'll get a much bigger cross section of experienced responses, and you won't upset people you PM.Experts:
DO: Try remember what it was like when you were first starting out with a technology, Try not to rush to judge newbies, as today's newbies are tomorrow's champions.
DON'T: Admonish a newbie on forums. That's not your job, and experts on crusades loose a lot of respect of their peers. If you think a newbie's post is inappropriate in any way, click "Report to Moderator", that's what they're there for. -
I've always thought of us here, in the LAVA community, as members of a global independent without-physical-barriers user group. We don't all need to be in the same place to share knowledge, ideas and a little fun, and some of the most insightful and important knowledge I've gained in my career has come from me being a member in this user group right here.
Wouldn't it be great for the user group, and all its members, to get a little more love for everything that you've all done here? That's why I'm asking you to take two minutes to head on over to the 5th Annual LUGnut Awards page and nominate LAVA. I'm not going to tell you to nominate us under any particular category, or if you should suggest an addition category to NI, but I'd really appreciate it if you could help all of, together, get a little more recognition for AFAIK an important user group that has arguably done more to shape the independent LabVIEW community that any other resource.
-
The LabVIEWWiki has a collection of these, compiled from a lot of different sources. Unfortunately, it's down right now, but you can browse from an archive: http://web.archive.org/web/20150531121321/http://labviewwiki.org/LabVIEW_configuration_file
-
I'd be wary of making a fully customer solution on your own. There are already good resources that can help you deploy and manage systems (and their components), so you can keep control of your test sequences, support files, drivers, etc, without having to design that stuff up front. Ultimately, this isn't a "test" challenge, it's an IT challenge, so I strongly suggest you engage with your company's IT department and ask how they would do it.
FWIW: Microsoft System Center is my solution of choice - you can manage systems across multiple sites/domains/companies, group them as like-types, push software updates (sequences, drivers, OS patches, etc), and it gives you a traceable environment so you can audit what system has what, with history (important if you get a recall or a batch of parts coming back for warranty repair).
-
Looking for a LabVIEW or TestStand contractor for development work or consultancy? I'm available! I'm certified, have a ton of experience, and have very reasonable rates - check out my LinkedIn profile and ping me if you're interested!
-
1
-
-
Great intro presented by hooovahh at our local user group meeting today: https://decibel.ni.com/content/docs/DOC-46897
-
1
-
-
- Popular Post
I wasn't quite sure which category to post this in: I know guys like Jack and Jon have been looking into some of the visualization capabilities of other languages and how to extend the LabVIEW IDE with them - check out this cool dependency visualization tool Jon put together:
http://www.labviewcraftsmen.com/blog/labview-class-dependency-viewer-
3
-
So, how did you get on? Did you get what you were looking for?
-
Don't mark up NI hardware - NI doesn't like it when you do that. They prefer you to have a relationship with them (partner) where they can give you a discount and you sell the HW to the end-customer at lost outside.
-
With the load option as 0x48, that means your Sub.vi is going to have to be set for shared clone reentrant execution, so I'd say you'll get [3,6,9].
-
2
-
-
Programmers that advocate "Ad-hoc reuse" are cut from the same cloth as...
I mostly agree. I'm okay with it, if it's only but a step in the path to true reuse.
My oldest software that hasn't become "vapourware" seems to be the "windows_api_1.0.llb".
Great stuff! I still use a VI from that llb on the odd occasion

-
"Data mining" just isn't a phrase I use for programming at all. I don't see software as data - more a tool for manipulating data.
In the context of the conversation we're having, "data mining" is completely valid, semantically speaking.
"Ad-hoc reuse" is a phrase made up by script kiddies because they can't write proper code at all and have to steal others'. It isn't a thing..

This made me LOL. For more than one reason

-
If you meant by "data mining" the process of taking an unmodified chunk of an old project and use it "by reference", i,e, place the VIs on diagrams or link via code interface nodes...
I don't know about hooovahh, but that's not what I meant by mining. Well, not really anyway. Mining, to me, is half way between the "by reference" technique and the formally-released component. It's "hey, this is useful enough to modularize a little for this next project that I'm working on" without doing the formal redesign for ruse process. We have several stages that mined chunks go through before they get to the formally-released stage.
-
​That's really sad.
 It probably means that it wasn't modular enough to be re-purposed or adapt to changing requirements.
It probably means that it wasn't modular enough to be re-purposed or adapt to changing requirements.Oh, it was modular enough, it just wasn't aligned enough with our core businesses anymore (the screenshots I shared were of components, there was a top-level framework and UI experience that tied everything together). And a lot of the features had appeared in others' tools, so we left it where it was.
I think it's lying that reuse is 98% though
LOL, yeah I was wondering who'd be the first to call that out. So yes, the project in this example was, indeed, 98% reuse. Only because I threw together a bunch on internal reuse library and OpenG VIs on an empty block diagram
I have software that does the bits of it that are interesting such as coverage...
Nice work - I like this!
Complexity or nesting depth is a poor indication of that...
Interesting you mention that: I've had people ask me in the past about what level of complexity and/or how many GOBs that they should be aiming for - which misses the point entirely. They're relative, and that's why I insisted in having the histograms in there - you're not looking for absolute values, you're looking for out-liers. And yes, some of these out-liers can be logically explained away. Broken VIs et al are quantitative attributes, complexity et al are qualitative.
Then there is reuse that can't really be measured like copying an existing library, or whole project from some old code (data mining), where here reuse is between 0% and 100% but code can't really detect the exact amount.
Right. Mined-from-previous-projects is one thing, formally-released-components is another. But yes, they're still both reuse.
I should probably force myself to get some free time and release my reuse metric, unless VISTA is going open source
Open source, I doubt it. But... if someone were to release a framework (like ShaunR has), we could probably release a plug-in or two...
-
2
-
-
- Popular Post
I was wading through an old SCC repo today, and stumbled upon some of our old tools - the ones that existed before VI Analyzer, execution trace toolkits, complexity metrics, Requirements Gateway, et al. Here's a few screenshots for those that have been in the LabVIEW world long enough to remember the VISTA offerings from V I Engineering, in the days of old - enjoy a trip down memory lane!
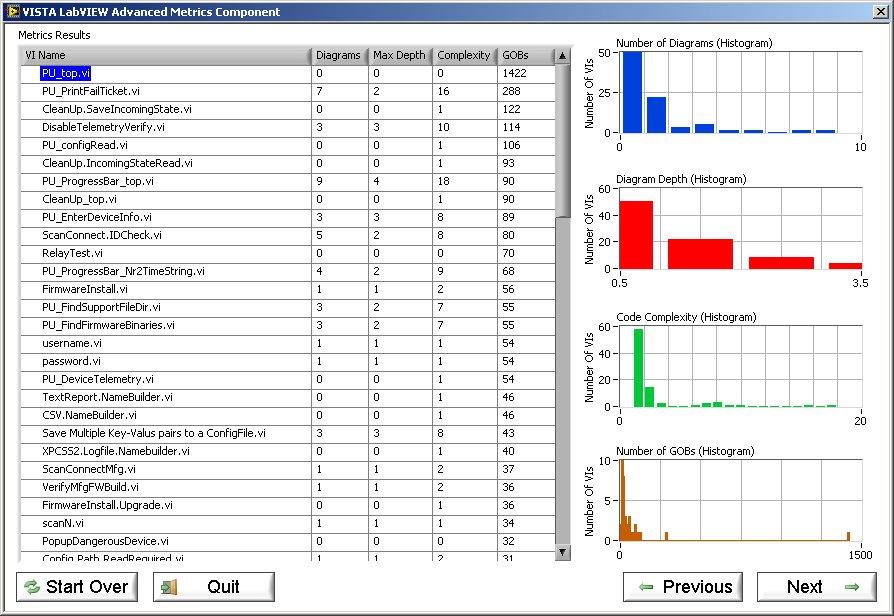
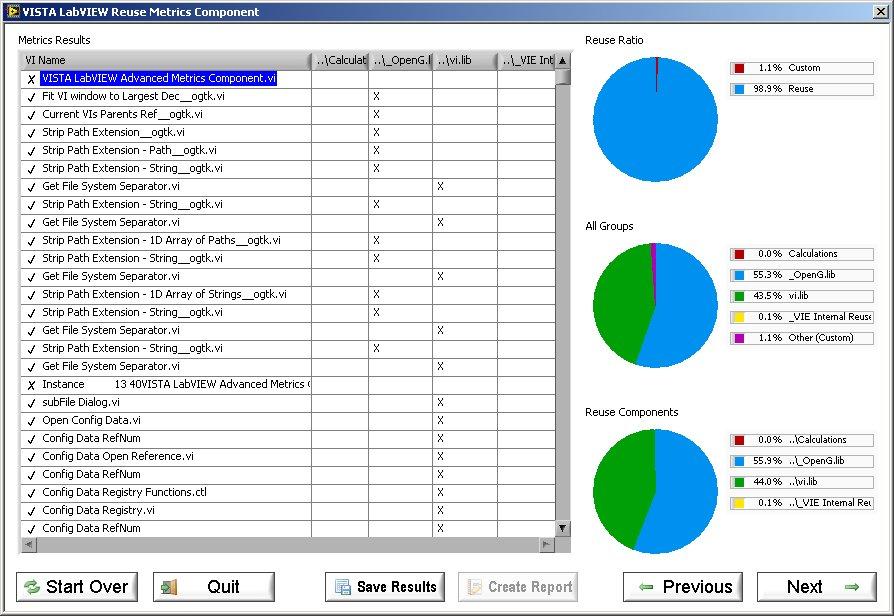
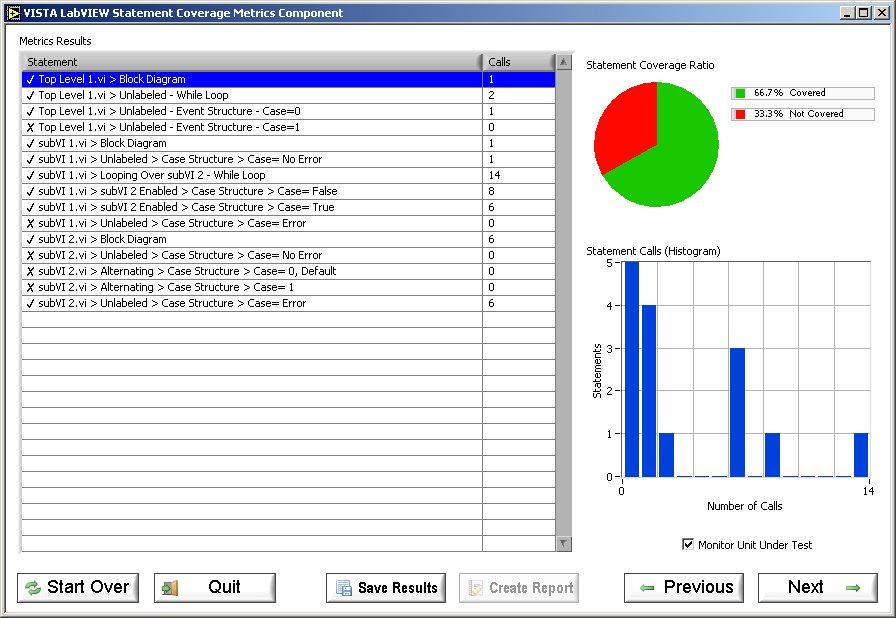
-
5
-
We're looking for a Business Development Manager. Think you've got the right stuff? Join the VI family!
-
We're looking for a Test Software and Integration Engineer. Think you've got the right stuff? Join the VI family!
-
-
Got my tickets - see y'all there
-
2
-
-
OpenG licensing discussion split off to https://lavag.org/topic/18995-keeping-track-of-licenses-of-openg-components
-
Oh and my favorite piece of software I wish I could download is the Infinite Jukebox. Ever get a song in your head you couldn't get out? Try listening it for hours with no obvious start or end.
That site is addicting. Although it seems to stop playing tracks if the window is minimized, or if I go to a different browser tab.
This almost blew my mind: http://labs.echonest.com/Uploader/index.html?trid=TRQDXXM13AFAB66B3F
LAVA LUGnut Award Winner
in NIWeek
Posted
Here's a photo of our superhero moderators/admins with the trophy: