LuP
-
Posts
4 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LuP
-
Ah It's not a bug it's a feature. I'll try not to generate too much work for you.
-
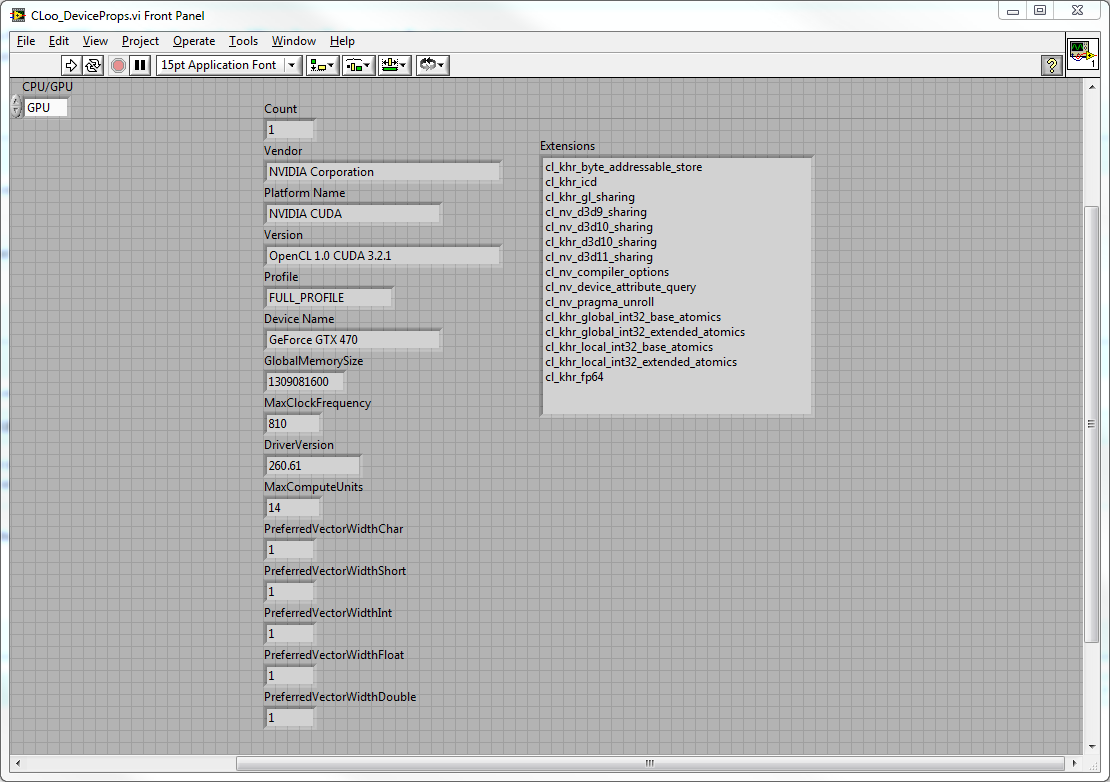
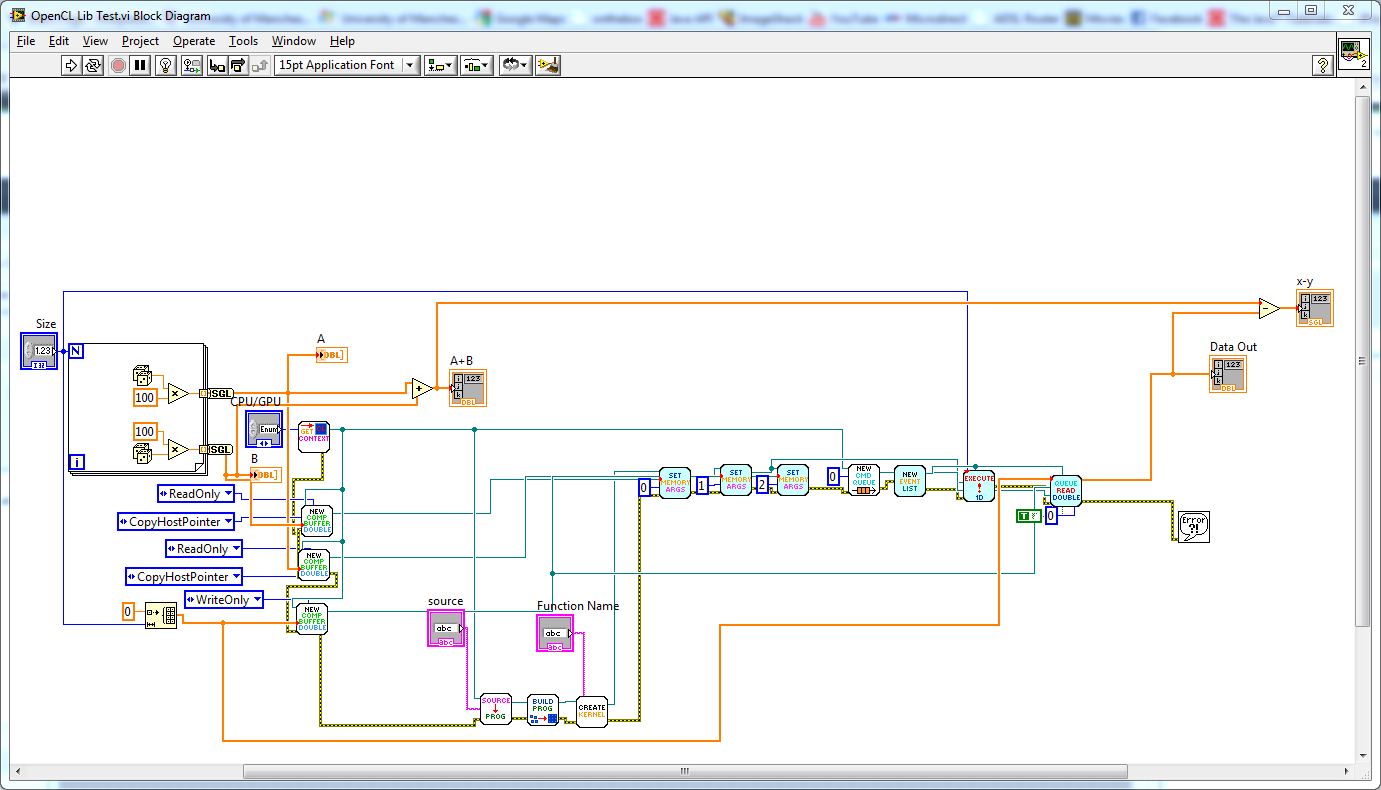
As promised screenshot of OpenCL on an Nvidia GTX 470: Thanks. I probably should have posted the Cloo OpenCL code it was designed to replicate for comparison: int count = 10; float[] arrA = new float[count]; float[] arrB = new float[count]; float[] arrC = new float[count]; Random rand = new Random(); for (int i = 0; i < count; i++) { arrA[i] = (float)(rand.NextDouble() * 100); arrB[i] = (float)(rand.NextDouble() * 100); } ComputeBuffer<float> a = new ComputeBuffer<float>(context, ComputeMemoryFlags.ReadOnly | ComputeMemoryFlags.CopyHostPointer, arrA); ComputeBuffer<float> b = new ComputeBuffer<float>(context, ComputeMemoryFlags.ReadOnly | ComputeMemoryFlags.CopyHostPointer, arrB); ComputeBuffer<float> c = new ComputeBuffer<float>(context, ComputeMemoryFlags.WriteOnly, arrC.Length); ComputeProgram program = new ComputeProgram(context, kernelSource); program.Build(null, null, null, IntPtr.Zero); ComputeKernel kernel = program.CreateKernel("VectorAdd"); kernel.SetMemoryArgument(0, a); kernel.SetMemoryArgument(1, b); kernel.SetMemoryArgument(2, c); ComputeCommandQueue commands = new ComputeCommandQueue(context, context.Devices[0], ComputeCommandQueueFlags.None); ICollection<ComputeEventBase> events = new Collection<ComputeEventBase>(); commands.Execute(kernel, null, new long[] { count }, null, events); arrC = new float[count]; GCHandle arrCHandle = GCHandle.Alloc(arrC, GCHandleType.Pinned); commands.Read(c, true, 0, count, arrCHandle.AddrOfPinnedObject(), events); arrCHandle.Free(); It then compares the result of the OpenCL kernel function and the labview addition function - if all went well the difference should be zero. Yes, that is actually the reason we got an Nvidia card in the project computer. There were two main reasons for me using OpenCL instead of that though: That implementation only works on 32 bit windows - I want to use (and am using) 64 bit windows (even though we did dual boot that computer with both 32bit and 64 bit windows so we could use CUDA if we chose to). I have an ATI card at home so I wanted to be able to dev my code at home and in uni, CUDA only works on Nvidia cards. + The ATI SDK lets you run OpenCL on the CPU which is useful it I only have my laptop. N/P this is only work in progress (the main subset of features implemented, minimal documentation) , but functional enough to let people play with. I'm really just throwing this out there because when I was looking for something to let me do OpenCL in LabVIEW all I saw were people asking if it would be supported, so I decided to release it early in a somewhat un-polished state so at least there's something to get people started.

-
I believe I have two problems, the second as a result of the first. Yesterday I attempted to post some code I wrote in a new topic: http://lavag.org/top...ncl-in-labview/ I wrote my post and as I was writing it previewed it a few times while writing it. When the post was complete I previewed it and above the preview was a red box with the words "You must enter a post". I thought this a little strange given that I had filled in all the available boxes and the preview came up fine. When I tried to submit the post the same message came up. Being the problem solving type I then cut all the sections except the first and tried submitting in case there was some formatting that was upsetting the board. The post succeeded. I tried editing and pasting the rest in, but the same "You must enter a post" error occurred. I then proceeded to for each section { edit post paste section submit } until "You must enter a post" error occurred. I then tried pasting in the remaining sections in reverse order, some successfully went into the post. For the sections remaining I tried putting them into a second post as for some unknown reason they wouldn't go in the first. The second post submitted ok, but it appears this board's software automatically concatenates posts by the original poster onto the OP if they are submitted fairly shortly after and no one else has replied. At this point I now have my whole post submitted, slightly out of order, and with a few mistakes (accidental it's/its and use of bbcode not supported by this board). Attempts to edit the post fail because it contains all the content that causes the bug. Since I can't edit the post I have no option to add things I would normally edit in (like restrictions I had forgotten about) in a follow up post with an explanation that I can't successfully edit my post for some unknown reason. Today I find that (I presume) a moderator has gone in and merged my follow-up post with my original and tidied up my bad bb code - thanks! The second issue is that I appear to have lost the edit buttons on my post (I could find them last night, I don't think the fact I'm using a different computer should matter). I don't think I'm going blind: I figured I should try and get these issues resolved rather than making a further mess of my topic by appending information in follow-up posts that really should be edited in (and thus make more work for any moderators who like to keep things tidy). I'm not sure how I managed to make such a mess of what I planned to be a simple task of making a post. Thanks in advance. LP
-
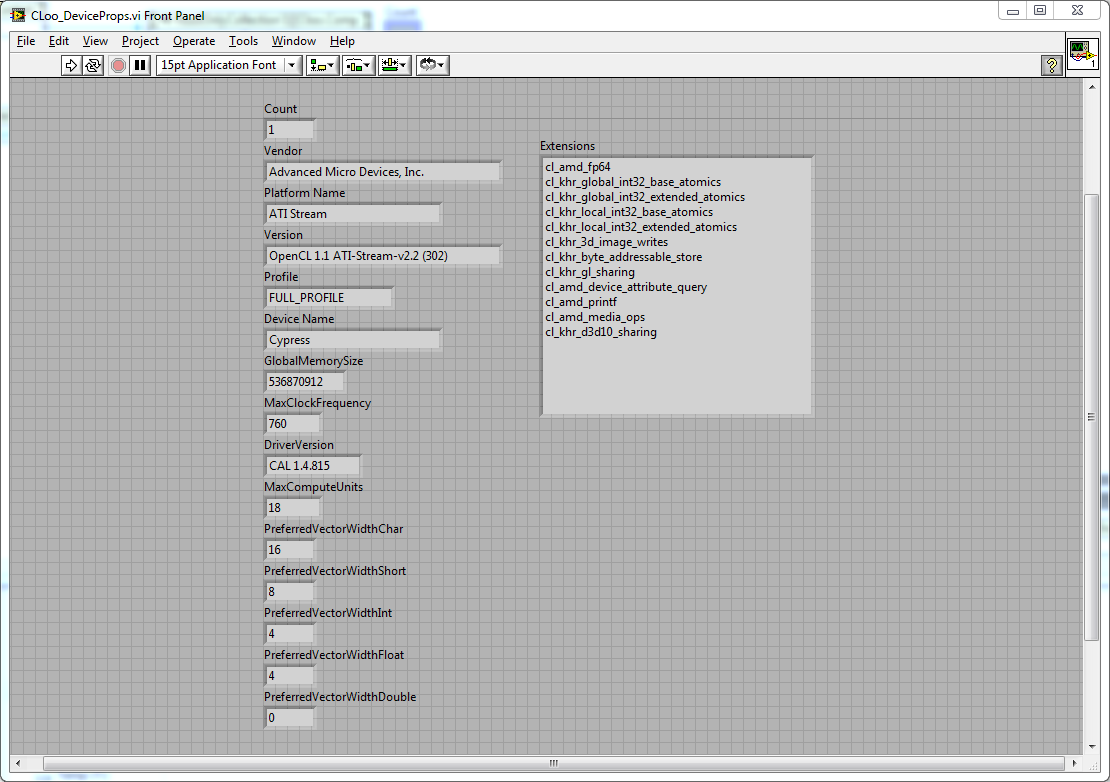
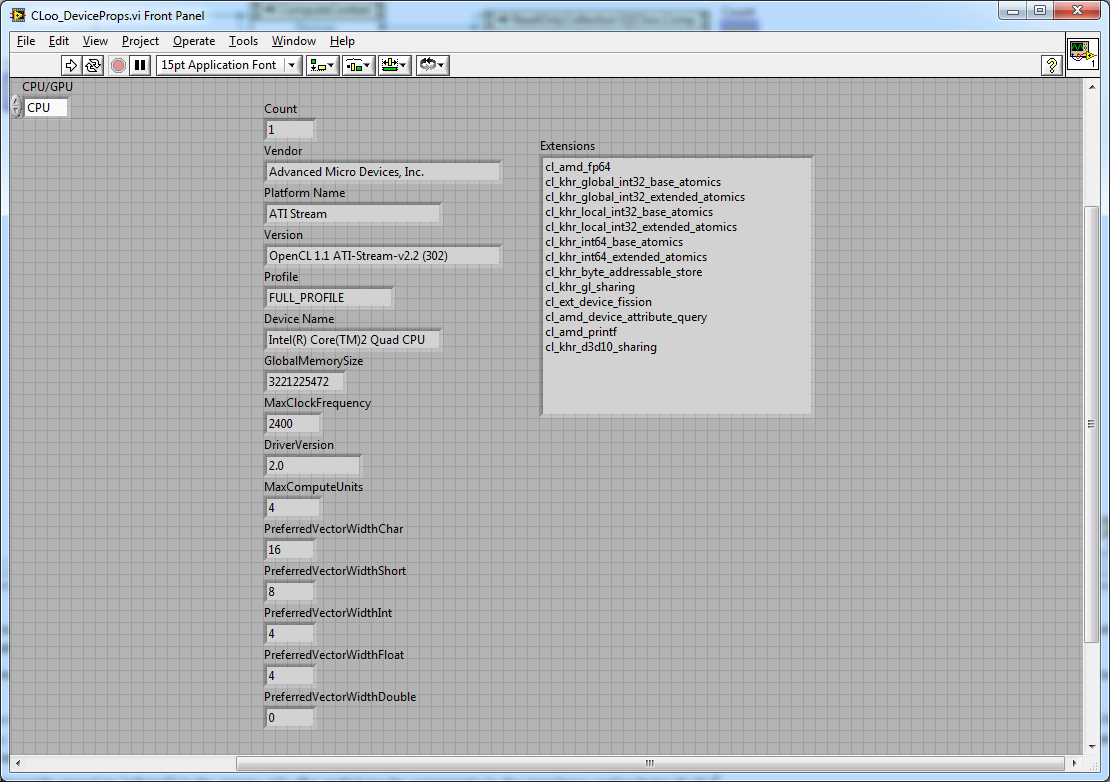
1. What is this? This is a collection of VIs which let labview users use OpenCL without having to learn how to call DLLs themselves. Along with the VIs are two DLLs. Cloo.dll - Object Orientated CL, a OO wrapper library for OpenCL from the CLoo project. The CLoo.dll included is only there to keep VS2010 happy, you may want to download the latest version from the CLoo project page. Cloo4Labview.dll - a utility DLL I wrote containing some code that was easier to write in C# .net 2.0 than in labview. Source is included in the .zip 2. What is OpenCL? It lets you use your GPU to process lots of data. Similar to CUDA or Direct Compute, see http://en.wikipedia.org/wiki/OpenCL . 3. Screenshots Device properties of an ATI 5800: Device properties of an Intel Core 2 Quad 2.4GHz Q6600: OpenCL vector add test results: Vector Add test block diagram: 7. Disclaimer This project is still under development and is being released because it seems functional and others have expressed interest in it (Hey, maybe others will even contribute improvements!). It probably shouldn't be used in mission critical systems. Use of this software is entirely at your own risk. I hold no responsibility for anything bad that occurs through use of this code including system crashes, data loss, release of magic smoke, nuclear war or zombie apocalypse. I have no obligation to provide support, requests for help will be answered if and when I feel like it and have the time - I'm a PhD student, I have other things to do like write an FFT in OpenCL (I don't like apple's one), sleep and solve Britain's nuclear waste storage issues. 8. Download: CLoo4LabView.zip Hope this proves useful. Feedback, comments suggestions and improvements welcome. Have fun I seem to be having problems porting my whole post (It keeps saying "You must enter a post") So I'll try putting the rest of it here. 4. What has this been tested on? I've tested this on two computers and a total of three devices. 1. Computer 1 - GPU - ATI 5800 with ATI Stream SDK (as seen in device properties screenshot above) 2. Computer 1 - CPU - Intel Core 2 Quad Q6600 with ATI Stream SDK (as seen in device properties screenshot above) 3. Computer 2 - GPU - Nvidia Geforce 470 with Nvidia GPU SDK (will post screenshot in a few days) Testing has not been extensive - only the two programs shown above have been run on all machines (I also tested changing the vector add to a vector multiply - change the + to a * in the source text, and replace the + to a x in the block diagram for the comparison). 5. Any limitations? * This inherits limitations from it's dependancies. E.g. I don't think CLoo currently supports non-blocking reads at the moment, when CLoo does, you can download the latest CLoo .DLL and all will be well. * OpenCL doesn't support Double precision floats, if you wire a double to any of the polymorphic VIs they internally cast it to a float. If you are reading this in the future and the double data type is supported in OpenCL, you will probably want to make some changes to remove the casts and change the .net method calls to point to the double not the single version of the method. * I haven't included support for unsigned data types - if you want to use them, you can copy-paste-edit the appropiate VIs and C# code. 6. I have no CLoo! CLoo is available here: http://sourceforge.net/projects/cloo/ The best site I've found that talks about it is: http://www.opentk.com/