

David Boyd
-
Posts
181 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by David Boyd
-
-
Somewhere in the dawn of the ES (6.1? I think), while wrapping my head around this great new paradigm, I took it as a commandment that THOU SHALT HAVE NO MORE THAN ONE EVENT STRUCTURE PER DIAGRAM. I've frequently been appalled by the code of some of my coworkers who blithely put down 2, 3, or 4 ESes in separate loops. (Heck, I don't even like to have more than one ES in an entire execution hierarchy, maybe I'm carrying it too far?.)
So it wouldn't bother me. But I am curious, AQ, if you went ahead with this enforced limitation, what kind of upgrade mutation could possibly save such (IMHO, barely maintainable) code that's out there?
Dave
-
 1
1
-
-
Just so I don't run afoul of Michael, a summary:
I have been in touch with Jim by email. With his help I got set up with TortoiseSVN and have pulled down the OpenG string source, for starters. I plan to update Scan Variant into String per the code above (but not with the FXP support, just yet) and include some new vectors in the test harness for enums (at present there are none).
Beyond this string fix, I'd like to add FXP to the known types in lvdata, but that will propagate through string and variantconfig and perhaps others. I suppose if Mads wants to take on the array package changes we can all get what we want in a pretty comprehensive set of new releases. And Jim told me he's cool with moving OpenG up to LV2011. It's good to know that OpenG still gets support!
Dave
-
1
-
-
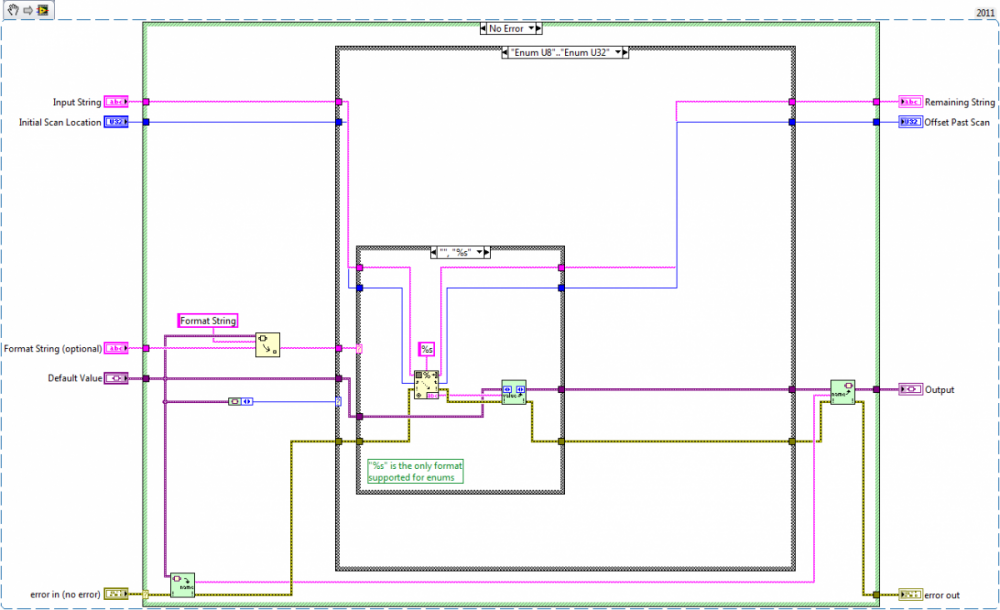
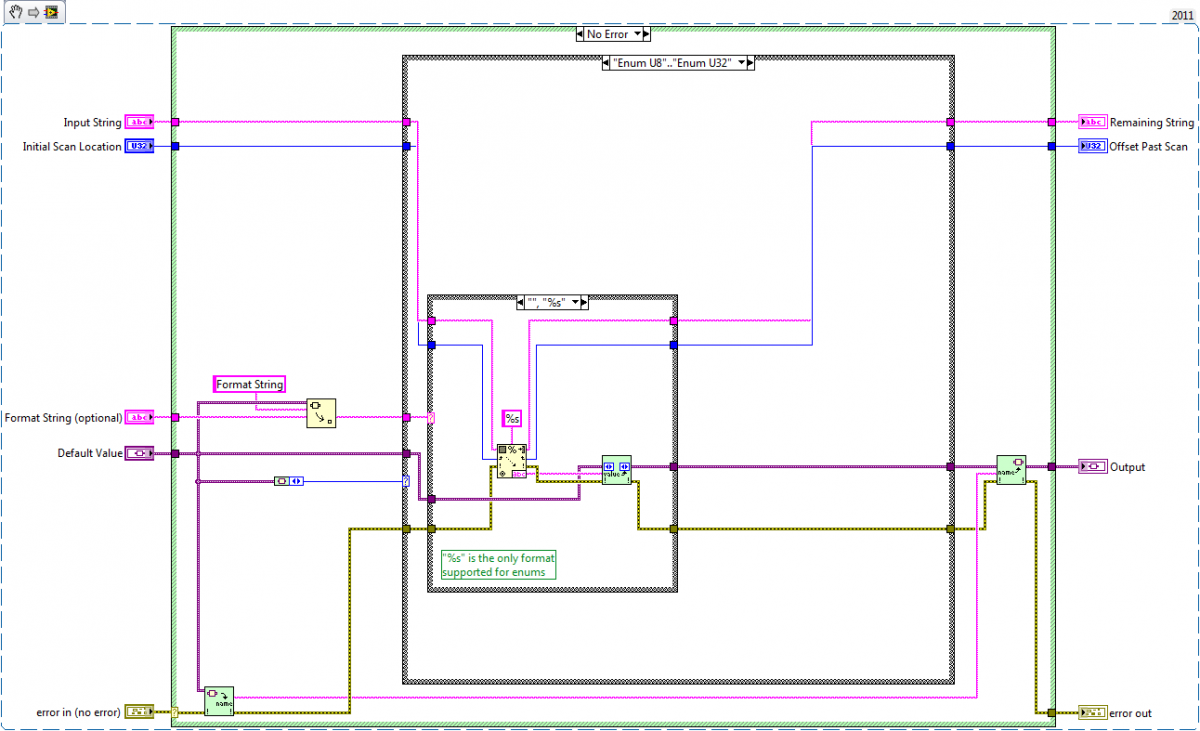
Attached is the existing code for Scan Variant to String_ogtk and a proposed alternative/fix to the enum case.
-
Michael: so noted, will do.
I just created an account on SF (as respdave). Also noted in the OpenG buglist here that Jim McNally reported the enum-to-Scan Variant From String issue just a few months back. I'll try to post my proposed fix here shortly so others can evaluate it.
Should I switch this to the 'Developers' forum at this point? Also: I've eliminated LV2009 from my work machine, my oldest installation is 2011. Do I need to back-save to 2009 for discussion/review purposes?
Dave
-
Here are my notes for modifying OpenG LabVIEW Data, String, and VariantConfig to support FXP. I did this originally to support FXPs in structures populated from INI files. I am not certain of what other packages have lv_data as a dependency that might also be affected.
_OpenG.liblvdatalvdata.llbType Descriptor Enumeration__ogtk.ctl:- change value 0x5F to "FXP"propagate type changes_OpenG.liblvdatalvdata.llbGet Data Name from TD__ogtk.vi:add case "FXP" (as dupe of case "I8".."CXT", "Boolean", "Variant")change Pstring offset from 4 to 36_OpenG.libstringstring.llbFormat Variant Into String__ogtk.vi:add "FXP" to existing case "SGL".."EXT"_OpenG.libstringstring.llbScan Variant from String__ogtk.vi;add "FXP" to existing case "SGL".."EXT"_OpenG.libvariantconfigvariantconfig.llbWrite Key (Variant)__ogtk.vi:add FXP to existing case "SGL".."CXT", "SGL PQ".."CXT PQ"and do same modification for internal case structure under case "array"_OpenG.libvariantconfigvariantconfig.llbRead Key (Variant)__ogtk.vi:add "FXP" to existing case "SGL".."EXT"and under "Array" case, add "FXP" to case "I8".."I32", "U8".."U32", "SGL".."EXT", "SGL PQ".."EXT PQ"and under *that* case, add "FXP" to case "DBL", "DBL PQ"
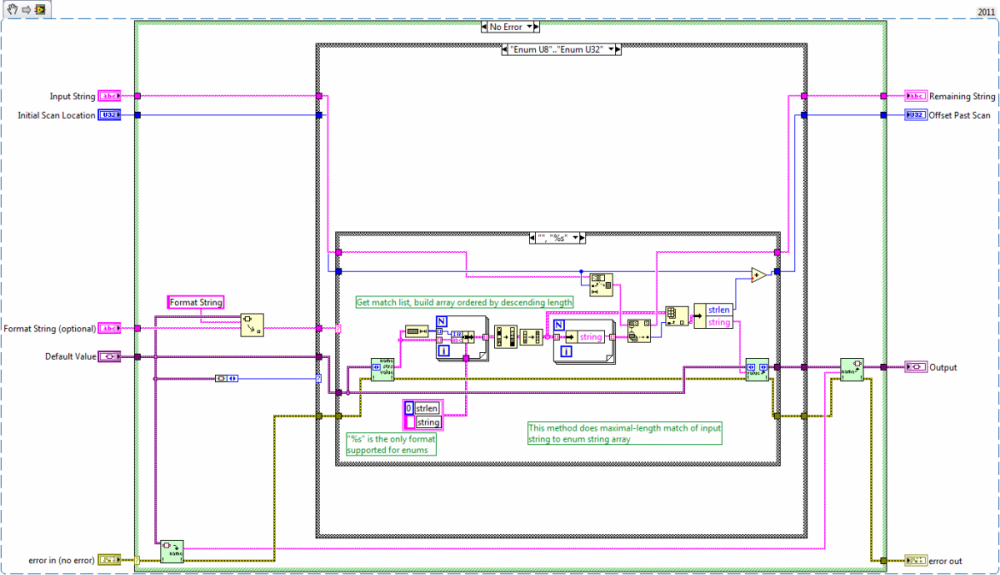
I have a separate change to Scan Variant From String__ogtk.vi, to fix the aforementioned problem with scanning into an enum. To match the behavior of the 'Scan From String' primitive, I find it necessary to do the following:
1) Get Strings From Enum__ogtk
2) sort string array by string length (max to min)
3) use Match First String (therefore, the maximal match)
4) Set Enum String Value__ogtk with string at resultant index
I'm not at all sure this is the most efficient method. But the existing code in Scan Variant From String__ogtk fails for matching enums with embedded whitespace, and may have other issues as well when an enum' strings share common initial character patterns.
I don't seem to be set up to get timely alerts from LAVA by email when someone posts a reply. If anyone wants to follow up directly, please drop me an email. I'll try to fix the alert thing in the meantime.
Best regards,
Dave
-
So, if I created an ID on SourceForge, I could check in my updates, as long as I did the work in... LV2009? (Is that the backmost version currently still supported?)
And then those in charge could accept those changes for a future release, or modify, or reject/rollback?
Meantime, if I posted here the textual description of changes, it would garner some attention and hopefully provoke a discussion?
Does that sound like the proper way forward?
Thanks for the replies.
Dave
-
Not sure whether I should post here, or on the developers' forum... so here goes...
I've used parts of the OpenG tools for a number of years, particularly the data tools, string, and variant config packages. Recently I've taken to modifying a few VIs and typedefs and carefully segregating out the modified bits. The specific modification I'd like to discuss was the inclusion of support within the variant and string routines for fixed-point datatype. (I have a concise list of the changes needed to support FXP.)
So, first question: are any of the members of the OpenG developers' community planning to officially roll this in? I saw it brought up as a request (perhaps informally) over a year ago.
Second question - if I have identified what I feel is a bug/incorrect behavior, to whom do I direct the description? I've found some inelegancies with how the Scan Variant from String VI behaves with enums, and have a proposed fix. Any takers?
Thanks,
Dave
-
1
-
-
- Popular Post
- Popular Post
I've used Digi devices for years, with few issues. Biggest system to date has four Etherlite 160's (total of 64 ports); sixty ports are tied to UUTs spewing 6400 char/sec each, all of which is digested by my LabVIEW application. The other four ports are used for instrumentation, doing query/response (a few dozen chars per message, as fast as the instrument responds).
These terminal servers are setup to use the Digi RealPort driver, which provides standard Windows comm API, so VISA treats them like local asynch serial. When you get up to this level of activity, with array-launched VI clones, and lots of queue/notifier/event structure support, you have to be pretty careful about the details. Seemingly minor changes to cloned code, reentrancy settings, execution system assignment, etc can mean the difference between a working app and a quivering heap of unresponsive code.
Dave
-
3
-
Thanks, Crystal. As one of the "Old Guard", you already (IMO) have a credential that surpasses anything a CLD certifies. Funny, though, perhaps we're not as tightly regulated as you, but we've never given a second thought here to migrating to newer releases when starting fresh projects. Sometimes I think we are still flying a bit under the radar. We focus more on qualification of test systems, rather than V&V of our LabVIEW-developed code apart from those systems. If we were to do more formal software verification, we'd surely need to add personnel to handle that workload.
Anyway, I took the test today. Got an 85. Way lower than my previous CLD-Rs and the original CLD. Not proud, not pleased, just relieved.
But I still feel as though too much of the test was of the form:
13) Which of the following (blah, blah,...)?
A. A twisty little maze of passages, all alike
B. A maze of little twisty passages, all alike
C. A twisty maze of little passages, all different
D. A maze of twisting little passages, all different
(With a nod to Colossal Cave, Zork, etc.)
Dave
-
I'm scheduled to take my CLD recert exam on Monday afternoon; this will be my third recert (took the CLD in Austin during NI Week 2004). As my LAVA listing shows, I've been using LabVIEW continuously for nearly thirteen years. I consider myself a pretty sharp guy (LV-wise), with a background in automated test, and the programming (in various environments) that goes with it, since the early eighties. My current employer didn't ask me to attain certification, I just did it on a lark.
I forget the specific scores, but I know that the original CLD and two subsequent CLD-R's were all scored in the high 90s (I think one recert was a 100%). So I waited until today (Sunday afternoon, quiet around the house) to work through the practice exam. Ouch! Not a very pleasant experience, and when I scored it, not surprisingly, I barely scraped a pass.
Random thoughts:
I expect that with each passing recert, there will be a few questions added in that will demonstrate that I haven't adopted a new feature in my own development. And I know this has been discussed elsewhere on the forums. I'm OK with not knowing every new feature intimately. (Network Shared Variables; just haven't needed 'em, though I remember when they were DataSockets, before they grew up. Feedback nodes still confuse me with their syntax, I so prefer shift registers. And sorry Stephen, but I just haven't found a programming challenge yet that whispers "LVOOP, LVOOP" in my ear. Someday I'm sure I will make the leap.)
Some of the example code snippets seem SO convoluted in their purpose, I can't help but wonder - am I being evaluated on how well I can troubleshoot some newbie-LV-minion's code? (I don't have any newbie-LV-minions at my command at my place of work, for better or worse.)
Guess I'll read some of the dustier corners of the online LV help on Monday, if I can spare the time. Wish me luck, never thought I'd need it.
Dave
-
Is Windows server 2003 a supported target for LabVIEW 2009? I know that it specifically WAS NOT under prior versions, though over the years there have been reports of folks running LV apps on WS2003. I'm just asking to point out that you may not be able to get support from NI for any issues you have. Whether this is an issue for you, I couldn't say.
Along other lines, have you checked the Windows event log on the target? Perhaps there is an application error event getting recorded which could suggest what's going on.
Good luck!
Dave
-
Setting up scales with virtual channels in Measurement and Automation Explorer(MAX) could be more intuitive. I would like a change in the hierarchy of these settings.
I've been bitten by my misunderstanding of custom scaling and min/max definitions too.
Classic example: I have a 0-15psi pressure transmitter that's 4-20mA current loop. I create a custom scale thusly:
- prescaled units in Amps
- scaled units in psi
- slope 937.5
- intercept (-3.75)
I specify this custom scale while defining a virtual channel that uses an NI current input, and am tempted to specify the channel min and max as 0-15 psi. Bad choice on my part! While trying to perform a software cal on a sensor, if the raw current reading is 3.7ma, the scaled value is pinned to zero psi even before I apply software correction factors. Perhaps this isn't really particular to the custom scaling, but I would still somehow expect the scaled channel to return all values within the chosen range of the underlying hardware. Having the max and min values specified in terms of the scaled value is just confusing here - what I SHOULD have done was to specify (-3.75psi) as the min value and (+16.41psi) as the max since the hardware will choose an input range that can actually report (0ma) to (+21.5ma). If I DON'T do this, and go with my original impulse, my scaled readings will never appear outside their valid ranges even if the hardware disconnects (goes to 0ma) or otherwise "goes south".
Dave
-
QUOTE (LV_FPGA_SE @ Jan 21 2009, 08:02 PM)
Geez, Christian, that was priceless. So simple an idea, it just took one clever person to conceive of it and create the website.
I didn't piss myself, but I narrowly avoided blowing coffee across my laptop keyboard.
Thanks for this.
Dave
-
-
QUOTE (miab2234 @ Dec 7 2008, 12:06 PM)
I got how to make the number of measured points but the thing,if i dont use semicolum and the end of my every measured point but the labview has to defrencitate everypoint of its own.for that i have to use the match pattern right ?Now see my measured points.I tooked out the semicolum now .I doest want to make everytime semicolum at the end of every measured point. I need that labview automatically take every X,Y.
How can i deferenciate everypoint ?
waiting for reply
I got it
 .Hope its right what i did.If there is something wrong please tell me
.Hope its right what i did.If there is something wrong please tell me Best regards,
Miab
Well, the Match Pattern you added back in is still not doing anything for you, and is still not needed in the example.
See how the string enters the left border of the While Loop? As a solid little rectangle? That is a simple tunnel. This means that the entire input string is on the wire on the inside, unchanging through all the loop iterations. Your Match Pattern looks for a semicolon character, and since there isn't one (in your revised sample data), passes the entire string out of its 'Before Match' terminal. Every iteration, unchanged.
The Scan From String node has a format string input which says it should find two floating point numbers - that's the %f specifiers. The leading format specifier, the one that is a %,; is a special token that says that the decimal radix character is a comma. My LabVIEW needs this since in my locale (USA), the radix is a decimal point, and your input strings 'look' European. You may not need this specifier. (This would be a good time to update your LAVA profile to proudly declare your nationality. It can be helpful to others, as in this example. Plus, it's always interesting to see.)
So, the Scan From String finds two floating point numbers separated by any amount of non-numeric characters - maybe a semicolon, maybe just whitespace, works either way. Now, here's the magic part: the Scan From String also returns an integer which says how far into the input string it had to look. We pass that around through a shift register for the next iteration. This tells the Scan From String to start looking for the next two numbers that far into the original string, skipping over the ones it has already converted. It's much more efficient to do it this way than to keep breaking up the original string, which moves the (potentially huge) string around in memory.
You got the array size, though not in the way I would have recommended. The iteration terminal starts with zero, so the last iteration number is one less than the count of iterations - it's important to understand the distinction. You 'got lucky' because the last iteration in this example, by definition, is a failure - we exit the loop after we fail to parse any more numbers. That's what the Delete From Array node does at the end - it throws away the last, invalid array element. I would have recommended you use the Array Size? node on the final output. Neat, tidy, and clear (to a LabVIEW programmer) what the intent is.
I still think you have your notion of X and Y reversed when your dataset is plotted. The data suggests a function to me, which implies only one Y value per X. Your plot would not describe a function.
Finally, and no offense intended, please don't PM me about examples. Use the forums for this. It allows others to follow the dialog, so you'll have more chances to get good help, in case I'm too busy to respond.
Best of luck with your LabVIEW learning! (It can be both fun and profitable!)
Dave
-
I've attached a modified verson of your VI. It's a little simpler than you had. Look on the block diagram for a few notes.
Best of luck,
Dave
QUOTE (miab2234 @ Dec 4 2008, 10:38 PM)
Hallo Guys,I made an experiment and i cant come further with my programm. i want to know with my programm,how many points it measured and then i want to make the Graph (X,Y) of that points:
Check out my programm.I have given the measuredpoints in block diagramm.
I thought that everypoint is seperated with semicoloum.The other thing is how can i change the measuredpoints in realnumbers so i can make a (X,Y)graph of that measurednumbers
I my programm it has to show the number of measured points 10 and the Graph.
Check out my programm
Waiting for reply
Miab
-
Tried the member map recently and couldn't get it to work. Page loads OK and the map frame draws, but no contents (neither map not pins). This was using IE7 on my work laptop, both behind the corporate firewall and from home. I've also tried from my home PC, using IE7 and FireFox 3.03, all same results. Is this a known issue?
Dave
-
QUOTE (jdunham @ Nov 11 2008, 08:10 PM)
Let me add a "me, too!" reply to this. Like others who have responded, I've written VISA serial code for countless devices (sometimes it's an instrument, sometimes it's the UUT) where the single-character termination simply does not apply. Invariably I end up with some sort of looping, scooping, bytes-at-port?/shift-register/string-appending/match-pattern/splitstring... ...you get the idea. All because the reply from the device has a two-char termination sequence, or some DLE-escaped format, or the checksum follows the term sequence, or the message starts with a length byte, or they use a CRC16, or any one of a dozen variations on the theme. I've long wished for a VISA extreme makeover that would include advanced pattern matching built in to the API. I don't have a clear vision for exactly how it would work, but I trust that those clever folks at NI would come up with something very useful...Well I think it's a lame way for VISA to give you that information. It would be better to have a boolean output for "TermChar found?"...Until then, I just have fun writing drivers for the stuff nobody else wants to take on. Which isn't so bad.
Dave
-
1
-
-
QUOTE (Minh Pham @ Nov 10 2008, 07:55 PM)
Here is another one to discuss:What is an advantage of using For Loops over While Loops when working with Arrays?
A A For Loop can tell LabVIEW ahead of time how many elements to allocate in an output Array
B While Loops force LabVIEW to change the size of an output Array after every iteration of the loop
C Both A and B
D None of the above
I would choose A as A is an advantage of the For Loops over While Loops as the question stated.
However B is showing a disadvantage of the WhileLoops over ForLoop, so would this counted as another For Loops advantage?
I recall that the statement in B is NOT specifically true. While loops DO NOT resize output arrays after every iteration. IIRC there is some intelligence to the algorithm which allocates array elements - I think it allocates as needed by powers of 2 over some range - and when the loop exits, the LV memory manager does a final resize as needed to return unused elements to the heap. My recollection could be:
A Rather dated
B Outright faulty
C Both A and B
D Spot-on correct

Dave
-
QUOTE (Sparky @ Sep 30 2008, 03:13 PM)
I *must* be missing the point of both your original question and the responses you've received so far. I don't see why you need a reference to the picture control in the subVI to change the contents of the picture on the caller's front panel. Can you not simply pass the subVI the existing picture data and pass the modified picture data back from the subVI, to the indicator on the calling VI FP?I would like to be able to update a picture control in the main application VI from a sub vi. I need to reference the picture control and send the reference to the VI. I am not sure how to do this. I have been reading on refnum's and refnum controls, but cannot seem to see how to do this. Can anyone help?
Thanks
Unless you need to change an attribute of the picture, as opposed to its data, the reference passing just circumvents dataflow. Perhaps if we asked the same question with "numeric indicator" substituting for "picture control", my objection would be more obvious.
Best regards,
Dave
P.S. to Paul: all I found in your zip attachment was an .lvproj file - no VIs. Also, you might want to update your profile to show you're posting LV8.6.
-
You might try creating an event handler, then in a single event case for the control, registering at least key down/up/repeat, plus value change (of course), perhaps a few others.... then in the event case, read the property of the numeric "Numeric Text->Text". I would take this text into a "Scan From String" node, plus probably a "Match Pattern" as well, and check both the numeric value of the scanned string to your limits and also whether the Match Pattern finds non-numeric cruft. Not exactly easy, but from this you might be able to get an as-they-type peek at what the user is doing, and recolor the numeric's background in response, even before the control is validated. If that's really what you need to do...
Just my 2 cents' worth.
Dave
-
Thanks, AQ. That makes perfect sense - the use case of overlap of common data elements from distinct events, that is. I still wish there were an option to get the entire user event data in the "original" wiretype, though, for convenience sake.
Dave
-
QUOTE (Michael_Aivaliotis @ Jun 3 2008, 12:27 PM)
Michael,A bundle can give this for you. I know you don't want this but hey.Does that not give you a broken run arrow? When I just add an unnamed bundler LV complains:
The input data type is unnamed or has cluster fields with no names or duplicate names. You must wire a data type with unique names for each element, since Create User Event uses the type name of the input to name both the user event and data the event carries. These names are visible downstream when a user event is handled by an Event Structure.I end up having to either 1) use a named bundler, which implies a source-typing wire from somewhere, or 2) modify the original control (generally a typedef instance) to include the extra, named cluster frame. All in all, not a big hassle, but hey.

Dave
-
Just curious if anyone else sees this the same way I do...
If I create a user event for a simple scalar datatype (which I probably never do anyway), the event data is of course returned as the scalar value, with the data name label intact. But, when I use a cluster as the datatype, LabVIEW discards the cluster label and returns the elements of the cluster as individual items in the event data. I have no option to get the entire unbundled cluster within the event case. The workaround is to add an 'extra' cluster frame around my original cluster, and of course, name-label the outer cluster frame. Does this seem syntactically inconsistent to anyone? Is there a compelling reason for the way it's implemented?
Dave
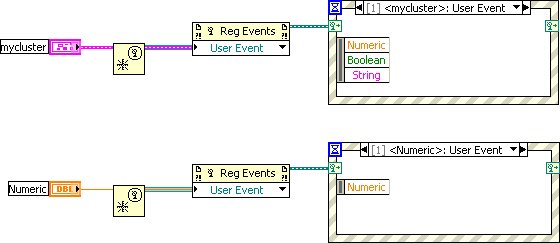

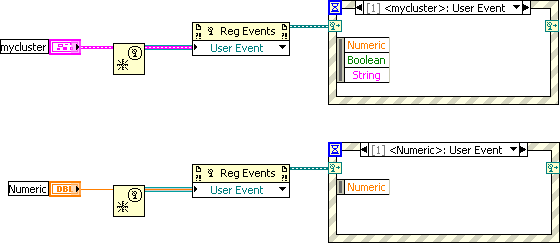
Suppose we limited 1 event structure per block diagram?
in LabVIEW Feature Suggestions
Posted
OK, having heard from all my multiple-ES LAVA colleagues, I'm seriously in need of a reality check.
AQ: do you recall any early caveats from NI (either in release notes, or help, tutorials, online discussion, etc.) that warned against the practice? I'm vaguely recalling there was an issue with the way ESes invoked some behind-the-scenes setup as soon as the VI was loaded into memory, well before user code started executing.
Or maybe I was living in some alternate reality back in the 6.1 days?
Dave