David Boyd
-
Posts
181 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by David Boyd
-
 I first started developing in LabVIEW (v4, pre-undo) in '97 and joined info-LabVIEW shortly thereafter, and that was already several years after Tom Coradeschi started it, so I recall feeling like I was late to the party. Wow! I just remembered, it's info-LabVIEW's birthday today (February 14, 1991)! And I think my toolbox at home still has an NI screwdriver with their Mopac address printed on it. Cheers!
I first started developing in LabVIEW (v4, pre-undo) in '97 and joined info-LabVIEW shortly thereafter, and that was already several years after Tom Coradeschi started it, so I recall feeling like I was late to the party. Wow! I just remembered, it's info-LabVIEW's birthday today (February 14, 1991)! And I think my toolbox at home still has an NI screwdriver with their Mopac address printed on it. Cheers! -
Also, sorry X___, I realized belatedly that you're NOT an anonymous user. A few of my elder brain cells were recalling old days where NI's LabVIEW forum reflected comp.lang.labview on Usenet, and postings from there ended up with a default anonymous identity. (Perhaps that's what inspired you?). No offense was intended. Dave
-
Shaun, you rock! Thanks also for quickly turning around that anon's request for a back-save. I'm still a bit mystified about the execution settings for the VIM. The editor breaks the VIM if you attempt to enable debugging, or if you forget to set it to inline, or leave it non-reentrant, but it DOES permit either reentrancy setting. Since VIMs are, by definition, inlined into their caller's diagram and adapted at edit time to the caller's datatypes wired in, I can't really see how the "shared" vs. "preallocated" clone selection can make a difference. It would seem that the content of any USR within the VIM would depend upon the caller's reentrancy settings at that point. That being said, I did look at the online tutorial on building malleable VIs and noticed that "preallocated" is explicitly called for: So, um, oops. I hope you corrected the reentrancy settings for the two malleables in the library when you backsaved to 2021. I'm certainly going to correct that in my own library. Thanks again! Dave
-
Shaun, I would always assume that the LUT code path is more performant that the eight shifts per byte of the brute force method, but only after you've amortized the execution cost of building the table (which is specific to the polynomial input value). So for one-off calls to compute CRC on a sufficiently short array of bytes (and since it is a well-known pattern), I left the brute force BD code. I set the LUT gen to only trigger on first call OR a change in poly between calls and for the table to live in a USR. VIMs have to be set to reentrant - are you thinking that "shared" (vs. "preallocated") clones will not handle the "First Call?" primitive correctly here? I hadn't really thought that through; I could certainly set the code to be preallocated. Somehow I thought it didn't matter here, since I thought VIMs just really embedded their code into their caller's BD. (But it's late and I'm too tired to ponder this much right now.) As far as the Xnode suggestion - I've never actually created one. I'm uncertain how that would work - the code to gen the LUT at edit time would need to know the poly value, which I left as a part of the normal parameterization (poly, init, and input and output reflection, output XOR), so it would only be known at execution time. Again, if I'm thinking straight. Thanks for the quick feedback, BTW! Dave To "X, the unknown": sure, I can back-save the whole thing, or you can put it up on the version-conversion forum if you need it that way immediately. I find the LV back-save process really cumbersome in that it seems to mangle dependency paths in a non-intuitive way. I'll try to get around to it eventually.
-
After making someone's day on the NI forums last fall for yet another CRC variation, I decided to go look for a fully-implemented LabVIEW reuse library I could just link to for the next such request. I really couldn't find one. Hence, the attached. It's intended to be a user.lib reuse library (although the attached zip includes a small demo project with a test VI). There's really only about two genuine VIs in the library, both are malleable to adapt to the poly/init integer sizes. One is the CRC computation VIM and the other is a lookup table builder; you have the option of pay-as-you-go (eight shifts/tests and conditional XORs, aka "brute force"), or you can take the computational hit upfront once and build a lookup table. Outputs are tested correct for the lengthy list of "well-known" CRCs (included in the library as some handy typedef'd cluster constants), when tested against some reputable online calculators. What is NOT done: I haven't made any serious attempts at benchmarking performance, brute force vs. lookup table. I'd be happy to have the LAVA community beat this up and suggest improvements in: speed, code elegance, style, whatever. Dave CRC.zip
-
Can I ride the LV/TS train to retirement?
David Boyd replied to Phillip Brooks's topic in LAVA Lounge
Nearly my entire career has been spent with employers in two industries: medical device manufacturing, and military/government communication manufacturing. I am guessing here, but I strongly suspect that this has shielded me from the effects of manufacturing, and its associated testing, being moved offshore and/or to the contract manufacturer du jour. Device and system testing where everything is traceable, and out-of-box failures are intolerable, means more investment in what would otherwise just be an expense area to the industries where yield just needs to be "good enough". Also, meddev, mil, avionics, space etc. industries are slow to adopt change, so if it was "done in LabVIEW" fifteen years prior, it probably still is. Only other industry that immediately comes to mind in this category would be some specialized instrumentation manufacturer (perhaps serving e.g., chem, biological, oil and gas) where the clever scientific/entrepreneurial types who brought that tech to market, are still in charge of things. Those folks perhaps want to see smart testing strategies and good instrumentation testing their instrumentation before it goes out the door. That's the closest I can come to suggesting a strategy for your next move, Phillip. But I'll be darned if I can find much of anything that smells like that being offered up in the incessant LinkedIn emails I get. Heck, they can't even settle on what the term "test engineer" means. Dave -
Can I ride the LV/TS train to retirement?
David Boyd replied to Phillip Brooks's topic in LAVA Lounge
Just stumbled into this discussion a day or two late. Since I'm gainfully employed and developing in LabVIEW, but now 65+, I'm going to follow any further discussion. (Also, when was the last time I saw anyone make reference to HTBasic??) I do feel your level of discomfort, though, Phillip. A lot of good points made here about why LabVIEW may be slipping in its position of being a premier development environment for automated testing, data acquisition, etc. My text-based development experience (RMB, MS-C, MS-C++... and let us never speak again of TekTMS) is largely a distant memory after using LV for so many years (apart from begrudgingly still having to do a little VBA coding for some business-mandated Excel). My most recent relevant story comes from watching a 20-something coworker developing with Python for a data-gathering task in an R&D lab. He seemed to be struggling mightily with a third-party graphing library, and I noted (nicely) that in LV, setting up that charting would be relatively trivial. Bright guy that he is, he installed LV (enterprise license here at Abbott), and while I feared he'd be all lost/sullen/blame-the-tool, he remarkably picked it up far faster than I recall myself doing so. I diligently provided feedback and little bits of LV code to help him get started. His first project had all the hallmarks of a first-timer, but he seemed happy with the process. The really bizarro part of this story is the postscript; he left Abbott and is working with his father on a financial modeling project. Astoundingly, he's using LabVIEW, at least for the run-up. He says it allows his father to most easily visualize the arcane calculations and add extra inputs and outputs with a minimum of effort. Like others, I suspect that regardless of the Emerson future plans, there will be an ongoing need for LV developers even if only to maintain projects. I still can't figure out how Python developers get good integration with the various hardware interfaces needed, nor how they create good technical graphical displays, and I very much expect I'm never going to figure that out. Dave -
I've spent way too much time this morning looking for a simple set of three line art drawings to represent a closed door, an open door, and a locked door, so I can simply display the status of the door of an environmental chamber. Still haven't located a coherent set that is (IMO) easy to interpret. I don't do this often enough to have favorite online places. Anyone want to chime in here? Thanks, Dave
-
[CR] Data Matrix Generator v1.0 LV2020
David Boyd replied to David Boyd's topic in Code Repository (Uncertified)
I downloaded the code linked to by @huipeng8and looked at it a little over the past weekend, and I can tell you that I'm not especially impressed. It appears to be based off an older open source project (written in C) called libdmtx, started by Mike Laughton, but long since moved to GitHub and maintained there by others. I found that code to be harder to follow than the Zebra Crossing open source project (which I perused during my development; linked as reference code in my lvlib). Though likely I just didn't look at libdmtx long enough to grok it. My main grief with the LabVIEW code (written by NI user carroll-chan) is that it has absolutely zero BD comments, nor VI descriptions, so far as I've seen (s/ though it does have an endless variety of "interesting" VI Icons /s). And for any effort like this, implementing a very exacting ISO standard, IMO it needs to have some ties back to the standards doc. Also, please don't ask me how I feel about LLB packaging/distribution in the modern era. -
[CR] Data Matrix Generator v1.0 LV2020
David Boyd replied to David Boyd's topic in Code Repository (Uncertified)
It amazes me that I never found that bit of code, and it's right there on NI's site. I'll need to download it and have a look. Especially because I noticed that it claims support for all the encoding methods (ASCII, C40, X12, EDIFACT, etc), whereas I've left that for a future implementation - my 1.0 upload only supports ASCII. Just to be clear what that means - my library will encode any arbitrary string of 8-bit chars, it just means that there may be more optimal (meaning: shorter run length) alternatives. I did implement ISO 16022's rather arcane "look-ahead" test which tells you when to switch in/out of the other encodings for optimized length; I just don't have them implemented, so I don't make use of "look-ahead". Thanks, @huipeng8, for alerting me to this code, and for the good report on execution speed. Dave -
[CR] Data Matrix Generator v1.0 LV2020
David Boyd replied to David Boyd's topic in Code Repository (Uncertified)
Rolf, I must say that at least this ISO did have some example code written in C which I found helpful (and I quoted from on some block diagrams where the LabVIEW code might otherwise have been incomprehensible). I also included a link in my library documentation to the GitHub repository for the Zebra Crossing (zxing) Data Matrix encoder sources (Java). I will say that the LabVIEW is far from a "straight port" of either of those. -
[CR] Data Matrix Generator v1.0 LV2020
David Boyd replied to David Boyd's topic in Code Repository (Uncertified)
Brian, Darin's library implements QR, mine does Data Matrix; they're both popular 2-D barcode symbologies. QR seems to be ubiquitous (looks like most phone cameras now natively identify and decode it). Data Matrix (actually, the very specific GS1 implementation) is used throughout industry (especially med/pharm) to encode serialization/batch identification, use-by/expire-by dates, etc. I think every imaging scanner out there will read both QR and DM along with the endless variety of linear barcodes. I do believe DM encodes more data, at least it supports pretty large patterns with more capacity. When I came across Darin's QR library, it did inspire me to offer up a solution for Data Matrix. As I noted in my readme/release notes, I thought "how tough could it be?". After reading the ISO 16022 standard I think I nearly had a brain hemorrhage! Dave -
[CR] Data Matrix Generator v1.0 LV2020
David Boyd replied to David Boyd's topic in Code Repository (Uncertified)
Meh, I just used the stub to save some real estate on front panels (which are generally never going to be called directly by consumers of the library, so not really important). I'm aware that stubs have caveats, chiefly that they hold no actual default value, but that shouldn't be an impact here. Where used, they pass all the metrics of the pattern being generated (as a typedef). If it's bothersome/objectionable, the solution is simple - replace the stubs with instances of the control. But really, I was hoping the discussion would tend more to the "wow, cool..." or "when would you ever need to make these symbols..." or even "hey, there's already libraryX that does this...". I'm looking forward to hearing any discussion of the merits of having a pure-G implementation. Thanks all! Dave -
Version 1.0.0
70 downloads
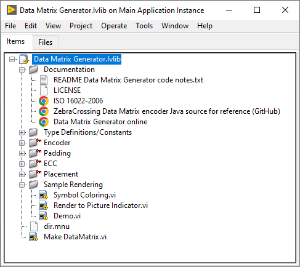
This project library enables conversion from string data to a 2-D integer array encoding Data Matrix ECC200 symbology. The library includes demo code to render the output to a LabVIEW picture indicator. -
View File Data Matrix Generator v1.0 LV2020 This project library enables conversion from string data to a 2-D integer array encoding Data Matrix ECC200 symbology. The library includes demo code to render the output to a LabVIEW picture indicator. Submitter David Boyd Submitted 05/07/2023 Category *Uncertified* License Type MIT
-
Thanks, Dataflow_G! I really needed to see all those CRT monitors to be reminded of the passage of time...
-
The fullscreen point I get, sort of; coupled with a touchscreen, the corner "X" may not be the easiest to access. The target hardware will have a touchscreen monitor, although we'll undoubtedly leave them the mouse. And while they might fullscreen the main app window, by no means do they need to. For dialogs, I would generally offer a "cancel' button, and an "OK" (or "submit" or "proceed" whatever seemed appropriate labeling), and map keyboard enter and escape keys.
-
And I was errant in my description above, as you've both uncovered. On the original application, someone dropped the canonical rectangular pushbutton which comes with red "STOP" text; but they did actually change the text to "EXIT". My original point remains, though - what other desktop (non-LabVIEW) application features a button as the way to dismiss an application? For years I've just trapped window close attempts, and used those to start the decision process of whether it's proper/safe/etc, and handle the app exit gracefully (hardware known state, file/db management, etc). Dave
-
I've been working on a total ground-up rewrite of a production test application that was crafted in LabVIEW 7.1 in the early-mid 2000's. I got approval to do this since I really didn't want to glom the real required changes (mostly about hardware evolution) onto ageing software architecture, and (IMO) *way* overbusy UI. I'm talking multiple layers of tabs-within-tabs-within-tabs. I've worked to make a still-pretty-busy UI a lot flatter/simpler. I'm getting tweaked in validation reviews because I declined to include an explicit "stop" button to close down the application. (The application typically runs for multiple hours.) No matter how I try to explain that no other desktop application has a "stop" button (I just intelligently handle shutdown via the filtered window close attempt), I'm being told, "NO, it NEEDS a STOP button". Of course I'll give my manager what he wants, but I don't have to like it. OK, let's hear the sage advice and similar tales come rolling in... Dave
-
Reading twenty-plus-year old articles like that really starts to make me feel ancient. I was about to reply with the obligatory grumble about preferred-case spelling ("it's LabVIEW!"), and instead looked up the author. Found out he passed away just before MacWorld Expo 2007. Thanks for locating and posting this. Dave
-
I still have my "Power to Make It Simple" tee shirt that I "won" at the end of my three-day Basics I class (I think it was fall of '97... does that seem right?). The black is pretty faded. I was excited to upgrade from 4.1 and try out the miraculous "undo". And real multithreading (under NT 4.0)...
-
Getting a ref to a clone VI inherently unsafe?
David Boyd replied to David Boyd's topic in Application Design & Architecture
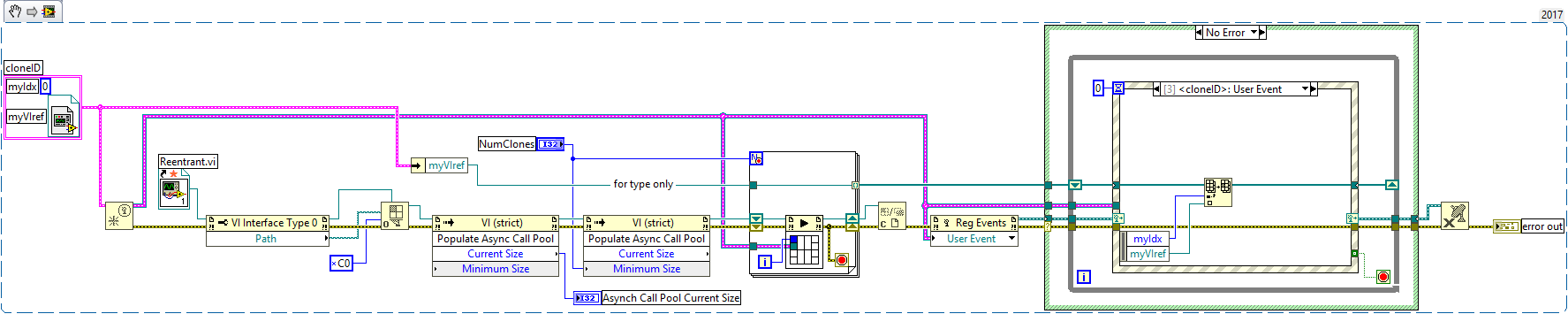
Thanks, @hooovahh, for pointing me to those older discussions, which I probably totally missed. @drjdpowell's comment about a clone's reference having guaranteed validity when passed to its subVIs doesn't seem to apply to my/@Neil Pate's use case - we're sending a cloneVI ref to another VI via messaging. So no telling when the original VI ref might go out of scope. And I just realized that my demo code for launching off clones (and then later gathering their refs for subpanel use), explicitly closes the original VI ref after they're launched. There is still a static ref on the caller's BD though - I think there has to be since you need a strictly typed ref to make the ACBR work at all. My demo code is below. Dave
-
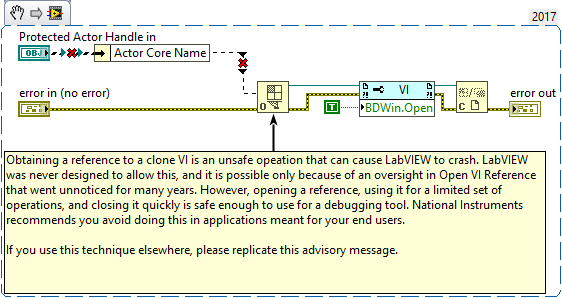
I was browsing through class code from the Actor Framework (ashamed to say I haven't used this framework, yet, but that's changing), and stumbled across what appears to be a dire warning. (See the attached, or if you'd rather, read the BD comment here.) I've used an architecture for years now where I launch N clones of a VI using the ACBR in fire-and-forget mode, and subsequently the clones get a VIref to themselves and register that (with an assigned index) by message back to a GUI VI. The GUI then allows the user to switch through the clones' FPs to be shown in a subpanel. I've never had an issue traceable to this. Note that in my code, the clone refnums are NOT obtained by an Open VI ref with clone name string (as shown) - they are implicitly obtained within the clones via a VI class property node. Does this warning imply that this architecture is somehow unsafe? I'm hearing AQ's authorship in my head when I read this warning. @Aristos Queue, are you listening? Can you comment? (Apart from chastisement for my only now learning about the AF - sorry.) Dave
-
I might have a tactical advantage there... who would bother to load up on old LabVIEW versions just to look at my rookie LV4.0 code. (Now, where's that chart Scott Hannahs did that shows the last version that'll open 4.0...?) Actually, I have plenty of much newer code I'm ashamed of, so who am I kidding?
-
Here you go... Get_Default_Data_from_TD_JK_01.zip