

Darin
-
Posts
282 -
Joined
-
Last visited
-
Days Won
37
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Darin
-
-
Interesting, that's a new one for me.
Yesterday I also discovered that the string-number conversion primitives work on arrays as well.
Sort of blew my mind as well. Never stop learning...
Should have been following the micro-nuggets thread on the NI-forums, somebody even pointed this out:
http://forums.ni.com/t5/LabVIEW/Micro-Nuggets-Post-em-if-you-got-em/m-p/1880159#M635520
This lets me replay a conversation I have had on numerous occasions:
Me: Strings in LV are really byte arrays, you should be able to auto-index and pass them into any function which accepts an array of bytes.
NI (usually AQ): Oh no, strings may appear to be byte arrays, but they aren't really.
Me: That is funny, all of the byte-protocols such as TCP/IP use strings as the data type. OK. prove it, give me a single example where: String->[u8]->Array Size does not equal String Length? Any ini keys, magic strings, unicode this or that.
NI: crickets chirping
This thread shows some string functions are also very useful for numerics. I think there should be complete interchangeability. The surprises should come when the polymorphism does not exist, not when it does. Besides, there is so much more to searching arrays than finding an exact match, when you unleash the pattern matching normally reserved for strings to numeric arrays amazing things are possible.
This does bring up a sore spot for me, trying to use the Number to HexString function with an array has a brutal coercion:
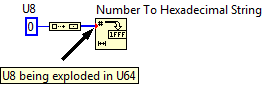
Actually much faster to wrap a For Loop in this case.
-
Those are local variables. <Insert snide remark here>
-
It happened in LV10, and I would probably follow the excellent advice given in the linked post above and do the conversion explicitly yourself.
Changing undocumented and ill-defined behavior is uncool, but not unreasonable. (By the time you compound the decisions to not document the original behavior, then not document the new behavior, and then not document the change in behavior it does seem especially lame).
Relying on these undocumented behaviors is unreasonable. Unless you document the undocumented behavior you were expecting then you are just as culpable as NI, hopefully it was easy to track down (but not too easy that it was not a lesson learned). I loathe text comments in a graphical language, and especially the ones that tell you what a chunk of code is doing. I can read your code, but I can not read your mind (and I often forget what I was thinking a few weeks/months/years ago). If I am using an undocumented behavior or working around a known bug I will add a comment and when I come back to the code I pay attention because I know I went out of my way to comment on something.
And for those keeping score, my C++ compiler gives a very useful warning message when I try a conversion like this.
-
-
Hard to tell from the picture, but it appears that F2 and G2 are switched in your graphs. You are joining the data F1,F2,G2 and Splitting it up F1,G2,F2. The upper output of Split 1D array is the beginning of the array.
-
Add a second Split 1D array to the second (lower) output array and give it the same length as the first Split function.
-
For each additional function (assuming they all share the same x values) you make three changes: first add the data to the y data array fed into the Nonlinear Fit VI, second modify the F(x) vi to calculate the new function and add the results to the end of the F(x,a) array and third add any parameters to a that are new to that function (if any). That's it.
-
I fit both functions with a single piecewise function. That piecewise function is F1(t) for all t followed by F2(t) for all t. The effect is that F1(t) is used for the first N points of the y data and F2(t) is used for the next N points. Each curve gets its own function, and they can share parameters as needed.
-
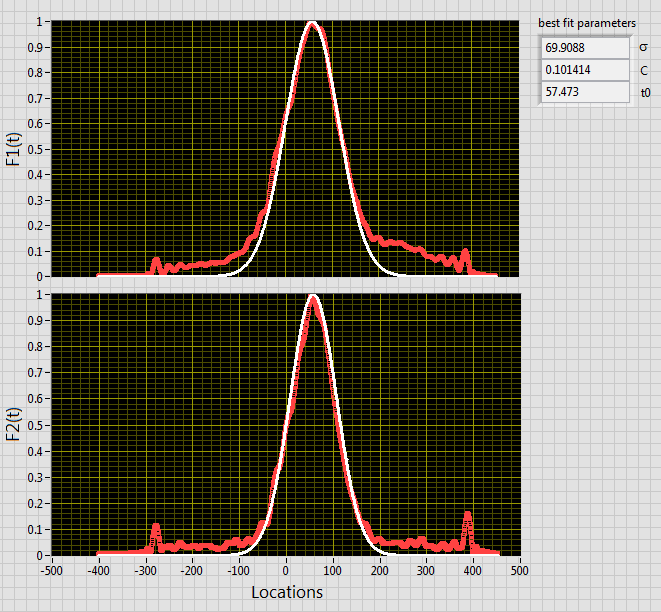
Found out why I thought your data looked out of whack, there were more y points than x points so they were not aligning quite right for me. Now I think your data looks fine and is well described by a single sigma parameter.
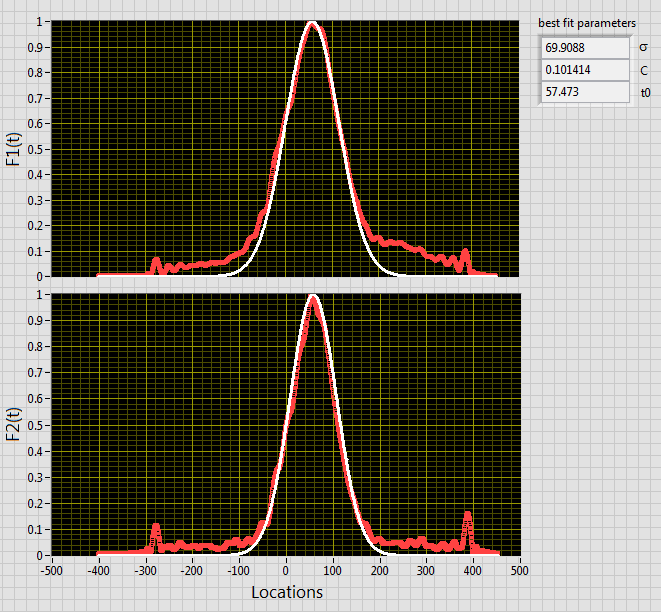
Same sigma for both. I will attach the VIs I used. I use a single fit but the fit function VI returns F1(t) followed by F2(t).
-
I can also get a very nice fit for both curves like you show when I allow sigma to be different (I think one is near 70 and one is closer to 80). I have forced a single sigma between the two curves (what you are tying to do) that is why the fit I show is not as good. Basically the two curves have different widths and sigma is the parameter most strongly correlated to that width.
-
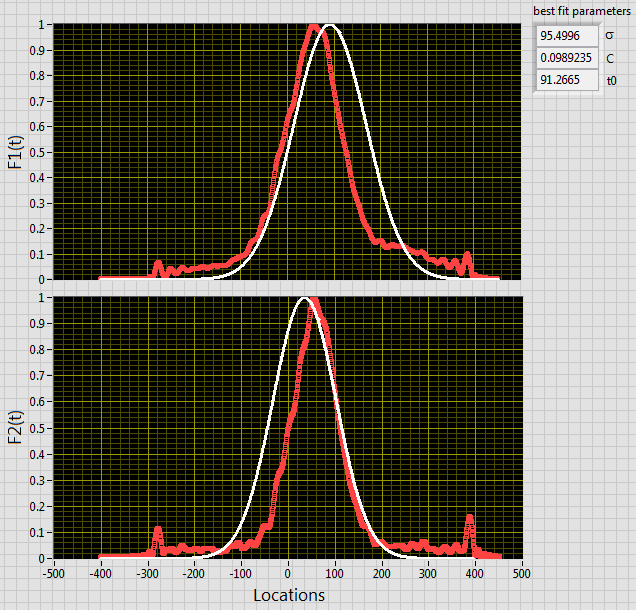
As is often the case, removing a degree of freedom seems to degrade the quality of the fit (The best joint fit is not a great fit to either of the individual curves.). By forcing the sigmas to match, the fit finds the point where the rising edge is well matched by one function and the falling edge by the other.
Right now it looks to me like the model is not a great fit to the data with the sigma value constrained. You could either try to refine the model (effectively return that DOF) or try to find the best constrained fit.
Here is what I see, I'll post the VIs here after I double check for pilot error.
-
Post a VI with the data saved as default values inside controls and I can show you how to ditch the Express VIs and get the job done.
-
I stream internet radio and FM radio amongst other things for hours on end, it is not so difficult. These sources have a well-defined data rate determined either by sampling frequency or the stream parameters. The only fundamental problem you face is whether you can decode the data for a frame of audio in less time than it will play. For MP3 it is easy, for decoding FM radio it requires some work to get things right.
The Write function for the sound buffer is blocking, it will not return until the data has been written to a buffer (or it reaches a specified timeout). This means it fits very nicely into a producer-consumer scheme. If there is room in the buffer, the write returns immediately, when it is full, there is a wait while the buffer empties. The queue of the P/C can take up the slack, and you can make it fixed size to limit the memory usage. You effectively keep the buffer as full as possible, and you can monitor the queue size to see if there are any backups. In fact, by using the P/C architecture up to the source of the data you can throttle the source with a fixed-size queue. For example, instead of reading an entire file I read chunks in a producer loop and feed it to a consumer queue. By making that queue one or two elements I can control how much is kept in memory at one time, much more effective than trying to read an entire file at once. Similar chunking is done automatically by streaming sources such as internet radio, DLNA servers and the like.
In short, I would not abandon the sound VIs unless I encountered a real problem.
-
Changing the password erases the undo history.
-
 1
1
-
-
Speaking of in place structures, is there much point cascading them (top) or is all data inside an in place structure automatically acted upon in place (bottom)?
As drawn, there is not much point of doing the upper version. No need to do a meaningless index operation and incur the small but measurable performance hit of the IPES to do a simple replace. If I am actually going to perform an index+do something+replace operation then I prefer the IPES.
-
I'm wondering if any of you see odd behavior when trying to maximize/restore a window that contains a splitter with subpanels.
If something like that worked flawlessly it would strike me as pretty odd.

-
You could fake the execution state (set it to stopped=2) set the 'DoNotShowSavedChangesDialog' to True and then invoke FP.close.
Smells like something, maybe that is why there is so much brown on the BD.....
-
Ah. I see, those will compress decently. I typically use PNG for images and I do not see good compression with no filtering. Line art such as graphs I export to SVG or EPS.
-
Right now my experience suggests that you are using a method which depending on the image is either marginally better or marginally worse than simply using the bitmap format. The sub and up filters are both very easy to implement and often quite effective at increasing the compression.
-
There is a reason that the return value from the double to ascii function is a boolean. I dropped it into a while loop and get a success rate of 99.6-99.7% for random samples over different ranges.
Running something which is roughly twice as fast 99.6% of the time and something which is 1.5 times slower (both in series) 0.4% of the time is still a net win. That is of course in C++, in LV the CLFN implementation of the fast method is roughly 1.5x slower than the primitive implementation of the slow method.
I have not used this for speed, I use it to get the smallest representation. I have written custom graph and table views in C++ and needed to do the float to string conversion.
-
1
-
-
Even in a CLFN the code is slower than the built-in primitive so I would not even bother a G implementation unless you are curious about the integer math. In C++ code I use it all of the time, it rocks. I do not care about the speed as much as a nice way to autoformat floating point numbers (it will do SGL as well).
-
RT! yes. yes. yes that is the difference.
The joys of LVOOP+DD+RT I try to leave to others more glutton for punishment.
-
Quick update: The first time I tried to run the posted code I got a crash, but now I suspect that was LV12 doing its thing and not directly related to the code. When I try it this time I actually get a quite helpful error message:
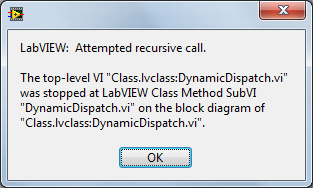
This is a good start but still bugs me a little bit. When you move from the world of strict, static typing into the world of dynamic typing then you expect a lot of errors to move from compile time to run time. This is the price of doing business sometimes. What I wonder is if it is really necessary to stop everything when this happens, could this be an error you could recover from?
This is mostly curiosity, I find recursion and DD to be a bit slow and avoid both as much as I can, combining the two is getting into slow-squared country, population unknown but not me.
Edit: That is a great explanation by AQ, but it did not address what seemed to be happening at the time. I understand what is and is not recursive and agree it is best to wait until run-time. The OPs description was that real, honest-to-goodness recursion was happening and your reply was not a bug, that had me confused. The error window I see makes all of the difference. If the OP did not see it for some reason, ouch.
-
1
-
-
Not a bug. It's called recursion and it is totally legal.A parent class's Dynamic Dispatch method had an instance of itself on its block diagram. The method was not set to reentrant execution, but also did not give me a broken run arrow. This caused the VI to recursively call itself until the application died.
I assume from reading this that the OP is aware of recursive functions, including the prerequisite(?) reentrency settings. If I quote from the NI OOP FAQ:
You can configure a dynamic dispatch member VI to allow recursion by setting it to be reentrant and to share clones between instances.
I assume this means a DD VI is like all other VIs in this regard.
So am I to understand that DD VIs are in fact different from other VIs and support recursion even in the absence of the usual settings for reentrency? That would be interesting, and probably very inefficient, and does seem to contradict the documentation I have come across over the years.
Don't write a recursive function without a base case... you'll use up all of memory.This also runs counter to my experience (in LV). The "normal" LV recursion mechanism places a limit (32000?) on the recursion depth. I do not run out of memory in the normal case, I simply get an error message about too many nested VI calls (no crash). The fact that a do-nothing VI here called recursively runs until crashing hints (to me, at least) that it is operating outside of the normal LV recursive mechanism.
-
1
-
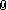
Stop Control inside While Loop
in LabVIEW General
Posted
Until recent LV versions there was a very interesting behavior. If you wired a dynamic event refnum with multiple events to an event structure but only handled a subset of them, even the unhandled events firing would reset the timeout counter. Yuk.
In a different discussion I was one of the few (close to only one) who advocated using multiple event structures on a BD. This is an example of one of those cases, where I like the decreased coupling. As mentioned earlier by drjdpowell, there shall be no mouse handling events in the data handling event structure. I have a cohesive set of events, and a timeout pertinent to those events if desired. Easier to read (for me), to write, and to reuse.