

Rolf Kalbermatter
-
Posts
3,968 -
Joined
-
Last visited
-
Days Won
281
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Rolf Kalbermatter
-
-
6 hours ago, ShaunR said:
For C/C++ I always use MingW (sometimes in MSYS2, sometimes in Codeblocks) but I prefer Pascal (Free Pascal compiler). Is this something you encounter mainly in MSVC?
Not sure what you mean exactly. In terms of LabVIEW there are not many variations possible:
Windows 16-bit: __pascal + __cdecl
Windows 32-bit: __stdcall + __cdecl
Windows 64-bit: __fastcall, 4 registers for first 4 parameters (shadowed on the stack) + remaining on stack
Everything else uses whatever is the the system default calling convention (not sure about Mac 68k here).
So basically only Windows 16-bit and 32-bit let you choose between 2 calling conventions, everything else was whatever is the platform default for them, usually either __cdecl or something with a number of registers and the remainder on the stack on RISC like CPUs such as Sparc, PPC, PA Risc and ARM.
As to compiler supporting various calling conventions, gcc is probably the most varied. You can get into pretty involved things there depending on platform and version. MSVC also knows a few more than what is mentioned above, but they either apply to kernel driver programming or C++ programming.
-
1 minute ago, ShaunR said:
The main difference is who cleans up the stack after a function. But again, I have avoided name mangling/decoration because it makes it difficult to figure out what to call. I guess being a mid-wit has saved me again

Depends what compiler you use. Some are more difficult to force into compliance with your preferences than others.😁
All my DLLs are always cdecl or whatever the preferred calling convention is (Windows 64-bit abandoned with cdecl in favor of fastcall, and trying to force a compiler to do cdecl there, while possible in some compilers, is pretty much doomed for anyone else who is going to have to use that DLL).
For Windows APIs however you can't choose, that decision has been made by Microsoft when defining the API. For user DLLs I don't see why anyone ever would have decided to go by stdcall, unless they use a programming environment that could not deal with cdecl.
-
3 hours ago, ShaunR said:
I disagree it is ill advised protection. One of the reasons I chose LabVIEW to start programming in was because it was bullet proof. I think we have had a conversation before that I never encountered crashes in the early days and it would have been because of ant foot-shooting boots like this.
I consider it ill advised since that name decoration is simply a Microsoft convention. Other compilers did in the past not create such names when linking a DLL. So as summary:
1) It's not mandated by Microsoft that a stdcall function should be decorated like that, but simply a convention by their linker. It's also not mandated that a non-stdcall function can't be named that way.
2) So it is not a mechanism to reliably avoid Call Library Node misconfiguration.
3) More importantly, it makes it impossible to call a function that was intentionally named that way but compiled as cdecl.
Why would someone create such a function? Well, I have no idea even if you beat me, but obviously someone did, otherwise NI would not have removed that anti-foot-shooter hack.
-
1 hour ago, ShaunR said:
I would probably never have been able to resolve an issue like that. What kind of monster removes anti foot-shooting boots?
It's highly likely it was just me misconfiguring some CLFN's. It's obviously been fixed in later versions. I still use the API so would have known if there was an issue with 5.0.0. I think version 1.3 was about 2010 so that version is over 16 years old - an amazing testament to LabVIEW's compatibility really.
There are posts on the NI forum about this, the earliest probably around 2012 or 2013 and I was involved in finding the issue. It's not so difficult when you look at a Call Library Node for a Windows API that crashes and then see that it is configured cdecl as there are virtually no Windows APIs with that calling convention except when they have a variable number of parameters as that can not be done in stdcall where the function itself adjusts the stack just before returning.
Why would someone "fix" an anti foot shooting protection? Most likely because there was an important customer wanting to call a DLL that used that naming decoration for whatever strange reason, while it was explicitly compiled to use cdecl, and threatened to sue the poor support person taking their call and sending an assassin squad to the NI head quarter. 😁
And in all honestly it is an ill advised protection that should not be there. What is less nice is that this functionality was simply removed without some mutation code path when upgrading pre 2011 VIs with a Call Library Node to 2011 or later. Yes there are complications, the correction was apparently done at recompilation time by actually verifying the exported name (the Call Library Node doesn't require to enter the decorated name but does the according matching to the real exported function at that moment) so if the VI was loaded in a newer version with the DLL missing, it would be impossible to properly mutate the code, but it would have been at least possible to try to mutate the VI during loading into the new version if the original was older than 2011. As it is that ship has long sailed already and it is a moot point to argue about now.
-
On 6/2/2026 at 7:41 PM, ShaunR said:
Not necessarily but possibly. Pointer to data instead of value or vice versa, enum sizes, pointer de-references of strings etc. Library calls are trixy.
Just one wild guess that recently bit me in another library. Does the SQLLite API in the Windows DLL use stdcall calling convention?
Until LabVIEW 2011, LabVIEW had a "helpful" feature to second guess your choice of that calling convention in the Call Library Node if the exported function had the appendix @xx with xx indicating the number of bytes passed on the stack for the parameters. The calling convention was silently "corrected" to stdcall even if you had cdecl in the configuration. Once you move to LabVIEW 2011 or later, this suddenly crashes as that silent correction was removed without any warning. The correct way when such a feature gets removed would have of course been to mutate the VI when converted from a pre 2011 version to 2011 or later. However the person removing that paternalizing feature did not think about adding an according mutation code path in the InstrumentLoad() function.
The thing bit me because I was developing code in LabVIEW 8.6 and had been also testing it in LabVIEW 2020 64-bit to be sure, wrongly assuming I had been accounting for a fairly large range of LabVIEW versions and platforms. Since LabVIEW 64-bit does not have any calling convention to choose from it did not expose that misconfiguration and someone else loading it into a newer LabVIEW 32-bit version found out the hard way that I had messed up.
Never mind, I see it is 2025 64-bit LabVIEW so there is no calling convention to get wrong.
-
2 hours ago, xabi said:
It seems this is related to the execution level of the constructor. Since the constructor was executed in the scope of the VI I use for testing, once that VI finishes and stops, LabVIEW may unregister the reference before the actor stops.
LabVIEW reference about user event registration:
It is not that LabVIEW MAY unregister the reference, but that it WILL unregister the reference as soon as the top level VI in whose hierarchy the reference was created goes idle. This is by design and the only way to prevent that is to either keep that hierarchy active until any other user of that refnum has finished or delegate creating of the refnum to the place where it is needed, for instance through a LV2 style global maintaining the reference in a shift register and when being called for the first time it will create the refnum if the shift register contains an invalid refnum. True Actor Framework design kind of mandates that all refnums are created in the context of where they are used not some other global instance that may or may not keep running for the time some Actor is using the refnum.
-
 2
2
-
-
20 hours ago, AjayMV said:
I guess it's issue with VIPM 2026.. I tried with other machine with 2023 VIPM and it installed fine. Now I'm looking for licensing details of Lua and looks CIT Engineering is not there any more.. Any leads on this @Rolf Kalbermatter?
Thanks for the feedback. Will try to check what the problem with VIPM 2026 might be.
As to commercial information I saw that you have sent an email to info (at) citengineering.nl and will make sure that the person in question will respond to that.
-
2 hours ago, AjayMV said:
Hey Rolf, one of such project popped up in our side and has old scripts in LuaVIEW.. Unfortunately the VIPM is not happy to open Lua4LabVIEW_Toolkit-2.0.5-2.ogp downloaded from https://www.luaforlabview.com/download.htm Seems it's not listed in VIPM.io as well. By any means you know last LabVIEW version it's successfully installed? We are trying with LV2023 64 bit.
-BR-
Ajay.Can you tell me more about what the problem is with VIPM? Which VIPM version is that? And what error if any do you get?
-
5 hours ago, viSci said:
Just to wanted add another voice to the LuaVIEW fan club. LUA is an excellent scripting language and LuaVIEW is an excellent integration with LV. Keep hoping you might see the advantages of open sourcing it to the LV community.
Thanks for your feedback. I'm not the legal owner of Lua for LabVIEW, only the maintainer. It is unfortunately not my decision how it is distributed/sold.
But even if it was, I don't think I would actually open source it. But I would probably make it free.
-
On 3/6/2026 at 12:10 PM, ShaunR said:
It will eat away at you slowly...at first. Then every time you see the link you will know [it doesn't work]. Drip, drip, drip. It's like those crossed wires on your diagram - you tell yourself it doesn't matter, that it's just cosmetic, that there is no change in function. But eventually you have to do something about it.
") Send that request to the admin, you know you want to
Send that request to the admin, you know you want to
I tried hard to ignore your poisonous whisperings but eventually succumbed to it. 🤫
-
 1
1
-
-
8 minutes ago, ShaunR said:
Your fastidiousness with code tells me this is an outright lie.
Hey, I didn't talk about code! This was about advertisement and commerce.
(And my lost privilege, which indeed hurts my sensitive soul a little 😁. It's soul crushing to read an old post of myself and discover typos in it.)
-
- Popular Post
- Popular Post
On 3/4/2026 at 6:36 AM, Vandy_Gan said:RTK LVButtonGX Installer.exeThis is the installation package
Are you seriously expecting anyone to install a random executable on their system from an unknown publisher, provided by an anonymous person on the web, where one can't even get a proper link in Google to the actual company page?
Sorry, but anyone doing that should not be allowed near 5m of a computer system!
-
3
-
1 hour ago, ShaunR said:
The link is broken for lazy people like me
F*ck! 😁
And I lost my privilege of being allowed to edit posts indefinitely some years ago for unexplained reason.
Ohh well! Not sure I care at this point very much. I just suck at commercial promotional stuff and am admitting it.
-
On 3/5/2026 at 4:08 PM, Neil Pate said:
You resurrecting LuaVIEW?
It's still maintained and sold, although not actively marketed.
-
Not starting but want to try to do a cRIO variant of a few things such as the OpenG ZIP library, Lua for LabVIEW, and especially my OPC UA Toolkit.
-
19 minutes ago, jmog said:
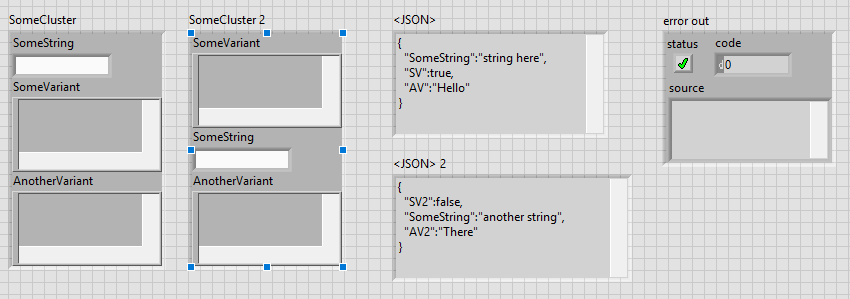
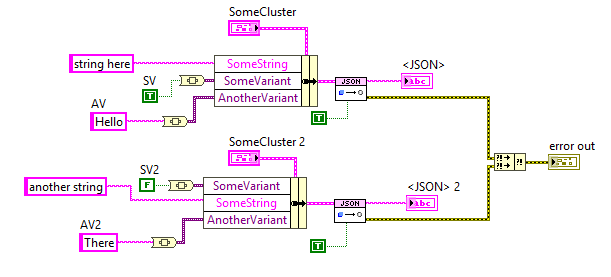
Can't find a way to edit my previous post, so continuing here. After posting, I found the related discussion on page 7 of this thread. So apparently the variant names that get used in the resulting JSON string are not the name fields of the cluster, but rather the names of the pieces of data inside the variant. This feels very counterintuitive to me, but in case someone is running into the same issue, at least one solution is to name the data used inside the variant (see image below).
Would it be possible to use the names of the fields in the cluster instead of the names inside the variant? That would feel more intuitive to me and apparently several others as well.

Nothing is impossible but often so painful that not doing it is almost in every case the better option.
The label of the data in the variant is the label of the data element that was used to create the variant. The variant has also a label but that is one level higher. You could of course modify JSON to Text, but that is a lot of work. And I think it is up to James if he feels like this would be a justified effort. Personally I absolutely would understand if he feels like "Why bother".
-
5 hours ago, Vandy_Gan said:
Francois,
Indeed, as you mentioned, I came across a Chinese video while surfing the internet earlier. It demonstrated examples of generating buttons in both development environment and runtime engine. The video link is provided below. I'm not sure if you can see it
I can't understand Chinese and the video only shows some highlights, not how it works. My assumption it that they might use Windows Controls. It's a possibility but the effort needed to create a toolkit like that for use in LabVIEW is ENORMOUS. If it exists and you really absolutely want to do this for any price, buy the toolkit no matter how expensive. Trying to do that yourself is an infinite project! Believe me!
-
6 hours ago, Adnene007 said:
Hi,
My project is to translate an application into multiple languages,
However, I am facing an issue with the display of the TabControl and the TreeMenu, When I translate them into French, I have spacing problems, as you can see in the picture.I am using:
LabVIEW 2024
Input file format: .json
Encoding/Conversion: Unicode
Thanks for help,
A bit confusing. You talk about French but show an English front panel. But what you see is a typical Unicode String displayed as ASCII. On Windows, Unicode is so called UTF16LE. For all the first 127 ASCII codes this means that each character results in two bytes, with the first byte being the ASCII code and the second byte being 0x00. LabVIEW does display a space for non-printable characters and 0x00 is non-printable unlike in C where it is the End Of String indicator.
So you will have to make sure the control is Unicode enabled. Now Unicode support in LabVIEW is still experimental (present but not a released feature) and there are many areas where it doesn't work as desired. You do need to add a special keyword to the INI file to enable it and in many cases also enable a special (normally non-visible) property on the control. It may be that the Tab labels need to have this property enabled separately or that Unicode support for this part of the UI is one of the areas that is not fully implemented.
Use of Unicode UI in LabVIEW is still an unreleased feature. It may or may not work, depending on your specific circumstances and while NI is currently actively working on making this a full feature, they have not made any promises when it will be ready for the masses.
-
On 2/27/2026 at 4:06 AM, Vandy_Gan said:
Francois,
Is it possible to generate an application that runs in a runtime environment only?
First, attaching your question to random (multiple) threads is not a very efficient way of seeking help.
I'm not sure I understand your question correctly. But there is the Application Builder, which is included in the Professional Development License of LabVIEW, that lets you create an executable. It still requires the LabVIEW Runtime Engine to be installed on computers to be able to run it, but you can also create an Installer with the Application Builder that includes all the necessary installation components in addition to your own executable file.
-
On 2/24/2026 at 2:31 PM, Neon_Light said:
Hello Rolf,
thank you for the help. I did download the source files from HDF5 and HDF5Labview. You're are right it can take some time to get it working. For that reason I'll start with making a datastream from the cRIO to the windowns gui pc and use that for now. At least I'll be able to reduce some risk.
Meanwhile I'll try to get a the Cross compiler working I'll should at lease be able to get a "hello world" running on the cRIO and take some steps if I can find some time. I did find the following site:
https://nilrt-docs.ni.com/cross_compile/cross_compile_index.html
Do you think this site is still up to date or is it a good point to start? I am only targeting a Ni-9056 for now.
I haven't recently tried to use that information but will have to soon for a few projects. From a quick cursory glance it would seem still relevant. There is of course the issue of computer technology in general and Linux especially being a continuous moving target, so I would guess there might be slight variations nowadays to what was the latest knowledge when that document was written, but in general it seems still accurate.
-
4 hours ago, ManuBzh said:
I'd would find useful (may be it's already exists) to choose the editing growing direction of an array. It's used to be from left to right and/or up to down, but others directions could be usefull.
Yes I can do it programmatically, but it's cumbersome and it useless calculus since it could directly done by the graphical engine.
Possible (and I forget about it) or already asked on the wishlist ? (I'm quite sure there's of one the two !)
Emmanuel
I can't really remember ever having seen such a request. And to be honest never felt the need for it.
Thinking about it it makes some sense to support it and it would probably be not that much of work for the LabVIEW programmers, but development priorities are always a bitch. I can think of several dozen other things that I would rather like to have and that have been pushed down the priority list by NI for many years.
The best chance to have something like this ever considered is to add it to the LabVIEW idea Exchange https://forums.ni.com/t5/LabVIEW-Idea-Exchange/idb-p/labviewideas. That is unless you know one of the LabVIEW developers personally and have some leverage to pressure them into doing it. 😁
-
3 hours ago, ManuBzh said:
For sure, this must have been debated here over and over... but : what are the reasons why X-Controls are banned ?
It is because :
- it's bugged,
- people do not understand their purpose, or philosophy, and how to code them incorrectly, leading to problems.Absolutely echo what Shaun says. Nobody banned them. But most who tried to use them have after some more or less short time run from them, with many hairs ripped out of their head, a few nervous tics from to much caffeine consume and swearing to never try them again.
The idea is not really bad and if you are willing to suffer through it you can make pretty impressive things with them, but the execution of that idea is anything but ideal and feels in many places like a half thought out idea that was eventually abandoned when it was kind of working but before it was a really easily usable feature.
-
1
-
1
-
-
It's a little more complicated than that. You do not just need an *.o file but in fact an *.o file for every c(pp) source file in that library and then link it into a *.so file (the Linux equivalent of a Windows dll). Also there are two different cRIO families the 906x which runs Linux compiled for an ARM CPU and the 903x, 904x, 905x, 908x which all run Linux compiled for a 64-bit Intel x686 CPU. Your *.so needs to be compiled for the one of these two depending on the cRIO chassis you want to run it on. Then you need to install that *.so file onto the cRIO.
In addition you would have to review all the VIs to make sure that it still applies to the functions as exported by this *.so file. I haven't checked the h5F library but there is always a change that the library has difference for different platforms because of the available features that the platform provides.
The thread you mentioned already showed that alignment was obviously a problem. But if you haven't done any C programming it is not very likely that you get this working in a reasonable time.
-
Many functions in LabVIEW that are related to editing VIs are restricted to only run in the editor runtime. That generally also involves almost all VI Server functions that modify things of LabVIEW objects except UI things (so the editing of your UI boolean text is safe) but the saving of such a control is not supported.
And all the brown nodes are anyways private, this means they may work, or not, or stop working, or get removed in a future version of LabVIEW at NI's whole discretion. Use of them is fun in your trials and exercises but a no-go in any end user application unless you want to risk breaking your app for several possible reasons, such as building an executable of it, upgrading the LabVIEW version, or simply bad luck.


The effect of the changed licence policy after (more than ? ) a year, observe and tell..
in LabVIEW General
Posted · Edited by Rolf Kalbermatter
I think there is a future and NI has significantly increased their activity and promotion for it (I guess one could be sarcastic and say that considering that NI's promotion of LabVIEW and active support of the community was pretty much zero just 3 years ago, anything more than zero is significant).
It will however not reach the stage that Dr. T once optimistically proposed as "LabVIEW everywhere". But that is not necessary. LabVIEW has still some interesting features and advantages and there won't be any programming environment ever that suits everybody.
The license change is welcome but not to significant, I think, as the new(old) perpetual license is basically quite beyond reasonable in my opinion. LabVIEW was expensive in the old days already but the new perpetual license cost is in my opinion simply to high (it's more than double of what it was before they tried to force feed the subscription). If I had to pay it myself, I would most likely stop with LabVIEW and simply use the Community Edition as a hobby.
However, you should anyhow never build your future on just one leg. LabVIEW can be an interesting and even viable option, but with LabVIEW alone you never could and never will be able to earn a keeping. You need additional expertise. LabVIEW shines in combination with hardware control, so having a good understanding on electronics, electricity, communication protocols, interoperability with other systems is what makes you stand apart in a world of other programmers. The actual world doesn't run on blockchain, LLMs, marketing and stock exchange, even if that seems what a large amount of people believe, since it promises quick profits. But the hype of today is the old story of tomorrow, since there is already another hype to chase then. Almost all the AI hypers on social media today, were trying to peddle their cr*pto hype a few years ago, and will all quickly move to the next hype once AI has been falling down from the hype (which it actually has done already more than once in the past, but most people seem to have a short memory or simply haven't been around long enough to remember).
Of course, I have about 10 more years I need to look forward too, so for me it is quite easy. There is enough of LabVIEW around to keep me full time busy with that until then, (but I like to also do some hardware and luckily can do that too). For someone younger, you definitely need to have some options open.