

Rolf Kalbermatter
-
Posts
3,909 -
Joined
-
Last visited
-
Days Won
270
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Rolf Kalbermatter
-
-
It's funny that this one found the actual error almost fully and then as you try to improve on it it goes pretty much off into the woods.
I have to say that I still haven't really used any of the AI out there. I did try in the beginning as I was curious and I was almost blown away by how eloquent the actual answers sounded. This was text with complete sentences, correct sentence structure and word usage that was way above average text you read nowadays even in many books. But reading the answers again and again I could not help a feeling of fluffiness, cozy and comfortable on top of that eloquent structure, saying very little of substance with a lot of expensive looking words.
My son tried out a few things such as letting it create a Haiku, a specific Japanese style of poem, and it consequently messed it up by not adhering to the required rhyme scheme despite pointing it at the error and it apologizing and stating the right scheme and then going to make the same error again.
One thing I recently found useful is when I try to look for a specific word, and don't exactly know what it was, I blame this on my age. When looking on Google with a short description they now often produce an AI generated text at the beginning which surprisingly often names the exact word I was looking for.
So if you know what you are looking for but can't exactly remember the exact word it can be quite useful. But to research things I have no knowledge about is a very bad idea. Equally letting it find errors in programming can be useful, vibe coding your software is going to be a guaranteed mess however.
-
On 7/1/2025 at 1:43 AM, bessire said:
One thing I thought about is getting LabVIEW to compile a temporary VI at edit time, storing the compiled code in a buffer on the block diagram, and finding some method to load VI's from memory if one exists. That way it can be used in an executable. Unfortunately, I don't know of any such methods.
I'm pretty sure that exists, at least the loading of a VI from a memory buffer, if my memory doesn't completely fail me. How to build a VI (or control) into a memory buffer might be more tricky.
Most likely the VI server methods for that would be hidden behind one of the SuperSecretPrivateSpecialStuff ini tokens.
Edit: It appears it's just the opposite of what I thought. There is a Private VI method Save:To Buffer that seems to write the binary data into a string buffer. But I wasn't able to find any method that could turn that back into a VI reference.
-
6 hours ago, ShaunR said:

I find it interesting that AI suffers from the same problem that Systems Engineers suffer - converting a customers thoughts and concept to a specification that can be coded. While a Systems Engineer can grasp concepts to guide refinements and always converges on a solution, AI seems to brute-force using snippets it found in the internet and may not converge.
If you consider how these systems work it's not so surprising. They don't really know, they just have a fundus of sample code constructs, with a tuning that tells them that it is more than some prosa text. But that doesn't mean that it "knows" the difference between a sockaddr_in6 and a sockaddr_in. The C compiler however does of course and it makes a huge difference there.
The C compiler works with a very strict rule set and does exactly what you told it, without second guessing what you told it to do. ChatGPT works not with strict rules but with probabilities of patterns it has been trained with. That probability determines what it concludes as most likely outcome. If you are lucky, you can refine your prompt to change the probability of that calculation, but often there is not enough information in the training data to significantly change the probability outcome despite that you tell it to NOT use a certain word. So it ends up telling you that you are right and that it misunderstood, and offering you exactly the same wrong answer again.
In a way it's amazing how LLMs can not only parse human language into a set of tokens that are specific enough to reference data sets in the huge training set and give you an answer that actually looks and sounds relevant to the question. If you tried that with a traditional database approach, the needed memory would be really extreme and the according search would cost a lot more time and effort every single time. LLMs move a big part of that effort to the generation of the training set and allow for a very quick index into the data and construction of very good sounding answers.
It's in some ways a real advancement, if you are fine with the increased fuzziness of the resulting answer. LLMs do not reason, despite other claims, they are really just very fast statistical evaluation models. Humans can reason, if they really want to, by combining various evaluations to a new more complex result. You can of course train the LLM model to "understand" this specific problem more accurately and then make it more likely, but never certain, to return the right answer.
In my case I overread that error many many times and the way I eventually found out about it was a combination of debugging and looking at the memory contents and then going to sleep. The next morning I woke up and as I stepped under the shower the revelation hit me. Something somehow had been obviously pretty hard at work while I was sleeping. 😁
Of course the real problem is C's very lenient allowance of typecasts. It's very powerful to write condensed code but it is a huge cesspit that every programmer, who uses it, will sooner or later fall into. It requires extreme discipline of a programmer and even then it can go wrong as we are all humans too.
-
On 6/29/2025 at 3:10 PM, ShaunR said:
The bug is in the AF_INET case.
inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress));
It should not be an IPv6 address conversion, it should be an IPv4 conversion. That code results in a null for the address to inetop which is converted to 0.0.0.0.
I found it after a good nights sleep and a fresh start.
Copy paste error 😁.
I'm almost 100% sure I did this exact same error too in my never released LabVIEW Advanced Network Toolkit.
Stop stealing my bugs! ☠️
And yes it was years ago, when the whole AI hype was simply not even a possibility! Not that I would have used it even if I could have. I trust this AI thing only as far as I can throw a computer.
-
7 hours ago, sts123 said:
So, MATLAB or Python are more efficient to convert TMDS to .txt?
Of course not! But TDMS is binary, text is ... well text. And that means it needs a lot more memory. When you convert from TDMS to text, it needs temporarily whatever the TDMS file needs plus for the text which is requiring even more memory.
Your Matlab and Python program is not going to do calculation on the text, so it needs to read the large text file, convert it back to real numbers and then do computation on those numbers. If you instead import the TDMS data directly to your other program it can do the conversion from TDMS to its own internal format directly and there is no need for any text file to share the data.
-
On 6/10/2025 at 5:50 PM, JackC6Systems said:
I've seen memory consumption [leaks] when Queues and notifers are used where multiple instances of 'Create Queue' are called which instigates a new queue memory pool. You need to pass the Queue reference wire to each queue read/write.
I've seen this from novices when using Queues and Notifiers....We had this problem of the code crashing after some time.
Just a thought.
Some people might be tempted to use Obtain Queue and Obtain Notifier with a name and assume that since the queue is named each Obtain function returns the same refnum. That is however not true. Each Obtain returns a unique refnum that references a memory structure of a few 10s of bytes that references the actual Queue or Notifier. So the underlaying Queue or Notifier is indeed only existing once per name, BUT each refnum still consumes some memory. And to make matters more tricky, there is only a limited amount of refnum IDs of any sort that can be created. This number lies somewhere between 2^20 and 2^24. Basically for EVERY Obtain you also have to call a Release. Otherwise you leak memory and unique refnum IDs.
-
 1
1
-
-
And are you sure your Rust FFI configuration is correct? What is the LabVIEW API you call? Datatypes, multiple functions?
Basically your Rust FFI is the equivalent to the Call Library Node configuration in LabVIEW. If it is anything like ctypes in Python, it can do a little more than the LabVIEW Call Library Node, but that only makes it more complex and easier to mess things up. And most people struggle with the LabVIEW Call Library Node already mightily.
-
6 minutes ago, Neil Pate said:
@Rolf Kalbermatter the admins removed that setting for you as everything you say should be written down and never deleted 🙂
Drat, and now my typos and errors are put in stone for eternity (well at least until LavaG is eventually shutdown when the last person on earth turns off the light) 😁
-
 1
1
-
-
Unless I'm completely hallucinating, there used to be an Edit command in this pulldown menu.

And it is now for this post, but not for the previous one.
-
I believe that I was able to edit in the past posts even if they were older. Just came across one of my posts with a typo and when I tried to edit it, the Edit command is not present anymore. Is that a recent change, or am I just hallucinating due to old age?
-
As far as I can see on the NI website, the WT5000 instrument driver is not using any DLL or similar external code component. As such it seems rather unlikely that this driver is the actual culprit for your problem. Exception 0xC0000005 is basically an Access Violation fault error. This means the executing code tried to cause the CPU to access an address that the current process has no right to access. While not entirely impossible for LabVIEW to generate such an error itself, it would be highly unlikely.
The usual suspects are:
- corrupted installation of components such as the NI-VISA driver but even LabVIEW is an option
But if your application uses any form of DLL or other external code library that is not part of the standard LabVIEW installation, that is almost certainly (typically with 99% chance) the main suspect.
Does your application use any Call Library Node anywhere? Where did you get the according VIs from? Who developed the according DLL that is called?
-
On 5/10/2025 at 1:44 PM, ShaunR said:
What happened to AQ's behemoth of a serializer? Did he ever get that working?
I believe to have read somewhere that he eventually conceded that it was basically an unsolvable problem for a generic, easy to use solution.
But that may be my mental interpretation of something he said in the past and he may not agree with that.
-
The popular serializer/deserializer problem. The serializer is never really the hard part (it can be laborious if you have to handle many data types but it's doable) but the deserializer gets almost always tricky. Every serious programmer gets into this problem at some point, and many spend countless hours to write the perfect serializer/deserializer library, only to abandon their own creation after a few attempts to shoehorn it into other applications. 🙂
-
 1
1
-
-
3 hours ago, bbean said:
You are correct...I worded my thought incorrectly. My thought was that since the Keysight code was using Synchronous VISA calls and both the Keysight / Pendulum were most likely running in the UI thread bc their callers were in the UI thread and the execution system was set to same as caller initially, the VISA Write / Read calls to the powered off instrument were probably blocking the other instrument with a valid connection (since by my understanding there is typically only one UI thread).
Well the fact that you have VI Server property nodes in your top level VI should not force the entire VI hierarchy into the UI thread. Typically the VI will start in one of the other execution systems and context switch to the UI thread whenever it encounters such a property node. But the VISA nodes should still be executed within the execution system that the top level VI is assigned too. Of course if that VI has not been set to a specific execution system things can get a bit more complex. It may depend on how you start them up in that case.
-
Synchronous is not about running in the UI thread. It is about something different. LabVIEW supports so called cooperative multitasking since long before it also supported preemptive multithreading using the underlaying platform threading support.
Basically that means that some nodes can be executed in Asynchronous operation. For instance any build in function with a timeout is usually asynchronous. Your Wait for Multiple ms timing node for instance is not hanging up the loop frame waiting for the expiration for that time. Instead it goes into an asynchronous operation setting up a callback (in reality it is based on occurrences internally) that gets triggered as soon as the timeout is expiring. The diagram is then completely free to use the CPU for anything else that may need attention, without even having to more or less frequently poll the timer to check if it has expired. For interfacing to external drivers this can be done too, if that driver has an asynchronous interface (The Windows API calls that Overlapping operation). This asynchronous interface can be based on callbacks, or on events or occurrences (the LabVIEW low level minimalistic form of events). NI VISA provides an asynchronous interface too, and what happens when you set a VISA node to be asynchronous is basically that it switches to call the asynchronous VISA API. In theory this allows for more efficient use of CPU resources since the node is not just locking up the LabVIEW thread. In practice, the asynchronous VISA API seems to be using internal polling to drive the asynchronous operation and that can actually cause more CPU usage rather than less.
It should not affect the lifetime of a VISA session and definitely not the lifetime of a different VISA session.
But disconnecting an instrument doesn't automatically make a session invalid. It simply causes any operation that is supposed to use the connection for actual transfer of bytes to fail.
-
On 4/24/2025 at 9:54 PM, bbean said:
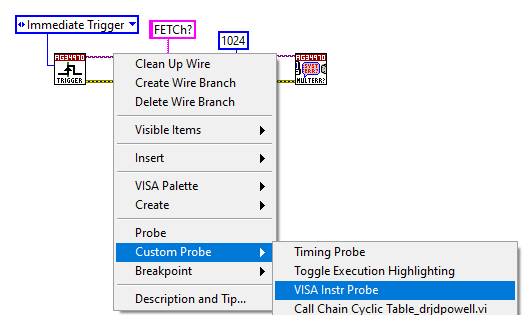
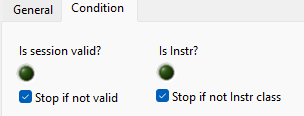
Does anyone know where the VISA Instr Probe (custom probe) source code is located?
I'm interested in how the "Is session valid?" and "Is Instr?" Booleans are determined
A VISA Session is simply a LabVIEW refnum too, just a different flavor (sepcifically TagRefnum) which has an attached user readable string. Same about DAQmx sessions and any other purple wire. As such the "Is Not A Number/Path/Refnum" works on it too.
One difference is that unlike any other LabVIEW refnum, you can actually configure if the lifetime of the VISA refnums should be tied to the top level VI or just left lingering forever until explicitly closed. This is a global setting in the LabVIEW options.
-
4 hours ago, ShaunR said:
I still maintain PPL's are just LLB's wearing straight-jackets and foot-shooting holsters.

The straight-jacket should take care about shooting in your own feet, or actually shooting at all. 😁
-
5 minutes ago, ShaunR said:
*prerequisite.
Packed libraries are another feature that doesn't really solve any problems that you couldn't do with LLB's. At best it is a whole new library type to solve a minor source code control problem.
Well, except that LLBs only have one hierarchy level and no possibility to make VIs private for external users.
I do feel strongly about packed libraries being a potentially good idea with many limitations that I think were not fully thought out.
- Version resource to have some control what version a packed library is? Tacked on by wrapping the proprietary archive format into a PE file and storing it as a custom resource in the PE file. And of course only under Windows, sorry Linux and Linux RT users, we forgot about you.
- And the project environment is terrible in supporting them, as LabVIEW does not isolate packed libraries into their own application context. A PPL loaded into one application context, contaminates the entire LabVIEW memory space with its symbols and trying to load the same PPL but compiled for a different architecture into a different application context (RT target for instance) just messes up your project and sometimes beyond repair. And this is even so insane that if you load two projects separately at the same time with the same PPL with different architecture, you just managed to mess up both projects equally! Why does (almost) everything properly observe application context isolation except PPLs?
-
On 4/11/2025 at 10:21 AM, ShaunR said:
I don't see them as a poor-mans class, rather a llb with project-like features.
I didn't say they are a poor mans class, just that they are similar in several ways. 😁
The entire low level mechanics underneath are very similar, the interface provided to the user is somewhat different.
Classes can have private data, libraries not.
Libraries are the pre-request to creating packed libraries, or as you found out to use the 3rd party Activation Toolkit.
They both have their use cases that are distinct from each other.
-
On 4/4/2025 at 12:38 AM, Dan Bookwalter N8DCJ said:
I have never used them before , I have been reading about them lately...
is there anyone who uses them extensively who would be willing to schedule a phone call to discuss/inform me more about them...
it is too much to type out everything etc...
if you are willing to , I guess, send me a message on here and we can go from there...
Regards
Dan
Have you used LabVIEW classes? A LabVIEW Library is in many ways similar except that you do not have methods and properties but simply only functions (a sort of method) in them, and yes of course no private class data.
You can set functions to be private, public or community. Obviously there is no protected type function.
-
2 hours ago, ManuBzh said:
Thank you ensegre !
Very strange that diagram property does not appear in LV2019/2021 ! it's the basis for scripting...I can create it without problems in LabVIEW 2018 and 2020! So it is either that Scripting is not enabled in that LabVIEW installation or a bug in backsaving some of the scripting nodes to earlier LabVIEW versions. And I'm pretty sure that the Diagram property (called Block Diagram in the menu) is available since at least 2009 or thereabout. I can check this evening. My computer at work only has LabVIEW versions back to 2018 installed.
-
1
-
-
35 minutes ago, ManuBzh said:
It's the Top Level Diagram reference... no the clone diagram reference (if ever this has sense)
(If you look at the exact name on the property node linked to your diagram ref, you'll see : TopLvDiag )
Top Level here almost certainly doesn't mean the diagram of the template VI. Instead LabVIEW distinguishes between a Top Level diagram which is basically the entire diagram window of a VI and sub diagrams such as each individual frame inside a case structure but also the diagram space inside a loop structure for instance.
The tricky part may be that the diagram itself may indeed only exist once and remains the same even for clone VIs. The actual relevant part is the data space which is separate for each active clone (when you have shared clones) and unique for each clone (when you have pre-allocated clones).
-
1
-
-
On 3/25/2025 at 6:32 PM, ShaunR said:
There is no automatic garbage collector. It's an AQ meme that he used to rage about it.
Technically it is a resource collector, but not exactly in the same way typical garbage collectors work. Normal garbage collectors work in a way where the runtime system somehow tracks variables usage at runtime by monitoring when they get out of runtime scope and then attempts to deallocate any variable that is not a value type in terms of the stack space or scope space it consumes.
The LabVIEW resource collector works in a slightly different way in that whenever a refnum gets created, it is registered together with the current top level VI in the call chain and a destroy callback with a refnum resource manager. When a top level VI stops executing, both by being aborted or simply executing its last diagram element, it informs the refnum resource manager that it goes idle, and that will then make the refnum resource manager scan its registered refnums to see if any is associated with that top level VI and if so, call its destroy callback.
So while it is technically not a garbage collector in the exact same way as what Java or .Net does, it still is for most practical purposes a garbage collector. The difference is, that a refnum can be passed to other execution hierarchies through globals and similar and as such might still be used elsewhere, so technically isn't really garbage yet.
There are three main solutions for this:
1) Don't create the refnum in an unrelated VI hierarchy to be passed to another hierarchy for use
2) If you do create it in one VI hierarchy for use in another, keep the initial hierarchy non-idle (running) until you do not need that refnum anymore anywhere.
3) If the refnum is a resource that can be named (eg. Queues, Notifiers) obtain a seperate refnum to the named resource in each hierarchy. The underlying object will stay alive for as long as at least one refnum is still valid. Each obtained refnum is an independent reference to the object and destroying one (implicit or explicit) won't destroy any of the other refnums.
-
2 hours ago, ShaunR said:
If that's the case then is this just a one-time, project-wide, recompilation? Once relinked with the new namespaces then there shouldn't be any more relinking and recompiling required (except for those that have changed or have compiled code as part of the VI).
That's my understanding yes. I have so far not upgraded to the library versions of the OpenG libraries, so do not have any long term experience with this. When I upgraded by accident one of the libraries I did see that it seemed to automatically relink callers, but that was not what I was prepared to deal with at that point as I was only making a minor edit to the project, so reverted to the previous OpenG version rather than committing the modified VIs to source code control.
System Style Enum that can be modified?
in User Interface
Posted
System style controls adhere to the actual system control settings and adapt to whatever your platforms currently defined visual style is. This includes also color and just about any other optical aspect aside of size of the control.
If you customize existing controls by adding elements you have to be very careful about Z order of the individual parts. If you put a glyph on top of a sub-part with a user interaction you basically shield that sub-part from receiving the user interaction since the added glyph gets the event and not knowing what to do with it will simply discard it.