

gb119
-
Posts
317 -
Joined
-
Last visited
-
Days Won
7
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by gb119
-
-
-
QUOTE (Chthonicdark @ Jun 8 2008, 02:49 PM)
http://lavag.org/old_files/monthly_06_2008/post-3951-1212935196.png' target="_blank">
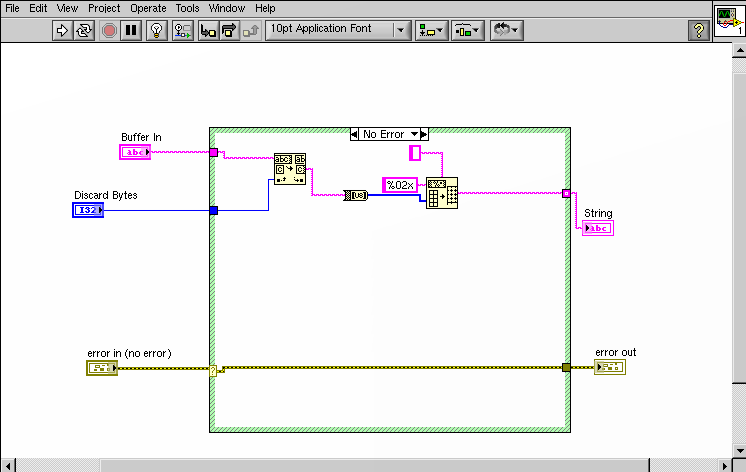
edit: the string wired into the deliminator terminal of the array to spreadsheet string is a single space character (\s) - should have turned on \ codes display - sorry.
-
QUOTE (jgcode @ May 22 2008, 12:55 AM)
Its kinda hard to answer the question with limited detail but if you need the dynamically flexibility of an array coupled with the flexibility of handling different datatypes try the Named Funcitonal Global Variable structure.Someone showed me this structure once and it is really handy as a tagged dynamic store.
This sort of data structure is known as a dictionary or associative array or hash array or map in other languages. There's actually quite a few ways of implementing it in LabVIEW. There's a discussion of the efficiency and speed of a number of these in http://forums.lavag.org/Map-implemented-with-classes-for-85-t8914.html' target="_blank">this thread. My personal preference is to use the attributes of a variant to store the data. Essentially, rather than having two arrays, one of data and one string keys, you have a single variant on the shift register and then use the Get/Set/Delete Variant Attributes to manage the stored data - this seems to be one of the most speedy mechanisms up to several 1000 keys.
-
QUOTE (prads @ May 21 2008, 06:58 AM)
QUOTE (jgcode @ May 21 2008, 07:42 AM)
Maybe try index array?Sounds more like Interleave 1D Arrays to me.
If the inputs to be multiplexed are all of the same type then probably want to build them into a 1D array. If each input is a single scalar number then the node 'build array' will do this. If the inputs are each arrays, but you want the output to take the first element from each input and then the second and so forth, then 'interleave 1D arrays' is what you want.
If the inputs to be multiplexed are all different types. the the bundle/bundle by name nodes will assemble them into a single data structure, although the ordering of the elements is not easily accessible, so it's not perhaps a useful thing to do unless you just want to handle all the items of data as a single entity.
-
QUOTE (Omar Mussa @ May 16 2008, 04:45 PM)
I just posted an article: Fighting Corruption: Using Source Code Control Systems (SCC) with LabVIEW Class Files to ExpressionFlow.com.The article highlights ways that LabVIEW class and project data can be corrupted and some SCC practices that can help you to recover from them.
I've been bitten by a couple of clss/project file mis-features in LabVIEW 8.2.1 (and as far as I know, though I've not exhaustively checked, 8.5.1).
One I detailed in this LAVAG thread - basically you can lock up a class file so that you need to use a text editor (or revert using your SCC system). This method doesn't rely on LabVIEW crashing and doesn't strictly corrupt the class file - it's all a perfectly legal albeit un-editable class.
The second one that strikes with depressing regularity is LabVIEW corrupting the project file. As far as I can work out the sequence goes like this:
* You have a project file that includes several files in different directories with the same name - say dir.mnu for example. Some of these directories are not in the LabVIEW search path (e.g. My Documents\LabVIEW Data\....)
* You move the whole directory structure to a new location using the OS file manager.
* You try to reopen the LabVIEW project. LabVIEW realises that the project has moved because some files aren't where they were supposed to be, so LabVIEW starts searching for them. LabVIEW picks the first matching name it comes to. With a file like dir.mnu that's not going to be too difficult...
* LabVIEW repeats this several times for each missing dir.mnu file, each time locating the same wrong dir.mnu and happily changes the project file.
*You save the project file and then re-open it. LabVIEW now complains that the project file (or library) is corrupt because iit has two or more entries with the same URL.
The immediate problem here is that LabVIEW doesn't check for duplicating URLs when it 're-finds' a moved entry, thus allowing LabVIEW to corrupt its own project and library files. The underlying problem is that the re-finding algorithm isn't as clever as it needs to be. If the project/library files stored their own save path in the file then they could detect and calculate what the move 'vector' was and then before searching the standard search path for a matching name, could try looking for a new relative path. 9 times out of 10 a whole directory structure has been moved so that should relocate entries correctly. Again, a revision control system which can diff two files quikcly puts it right, but it should not be possible for LabVIEW to corrupt its own files except of course in the case of a power loss or program crash.
-
QUOTE (Justin Goeres @ May 18 2008, 02:55 PM)
My questions are these: Are any of the rest of you doing anything like that? Is it even possible to enjoy doing LabVIEW development with less than 17" of real estate?I use a 13.3" (1280x800) laptop which is even a bit smaller than your proposed 15", with an addional external 22" monitor on my desk. The laptop screen does for most development tasks, but the extra real-estate is a nice luxury. Still, I tend to feel that if I have a vi whose diagram needs more than 1280x800 is probably got a little bit out of hand and needs some refactoring

-
QUOTE (Tomi Maila @ May 15 2008, 07:29 AM)
The only way to get the right clone instance of right dynamic dispatch VI to a subpanel is to ask the VI reference or the clone name from the dynamic dispatch VI itself. First assume you have a class hierarchy with multiple dynamic dispatch VIs of the same name in the hierarchy. Any one of those VIs can be called when the dynamic dispatch VI subVI node is executed so you cannot use static linking to some specific VI. Also, if the dynamic dispatch VI is reentrant, then also any clone instance of any of those dynamic dispatch VIs in the hierarchy can be called when the dynamic dispatch VI subVI node is executed. As a result, you cannot use open VI reference based linking to any specific VI unless you also know the VI clone name. The only way you can get either the VI reference or the clone name is to ask the dynamic dispatch VI being executed to return it to you somehow while it executes. You can for example use a single element queue to pass the VI reference asynchronously from the dynamic dispatch VI to the calling VI. At least that's what I would do.Yes - I hadn't thought through the problem of reentrant dispatch members. My code did handle constructing a reference to the right version of the dynamic dispatch method, BUT, only if the method was implemented in all the classes. One could probably write code that traverses the class hierarchy looking for the correct dynamic dispatch method yo open a reference to, but it still falls over on reentrant vis. So, there doesn't seem to be a good way that avoids code in the embedded methods to handle doing the embedding. I think I'd probably would (and in fact will do) pass the reference to the subpanel control into the method and handle the embed and unembed within the dynamic dispatch method.
-
QUOTE (Dan Bookwalter @ May 14 2008, 09:12 PM)
But forgot to tell us the answer
Which is yes you can, but it takes a little bit of work to get the right vi reference to insert...
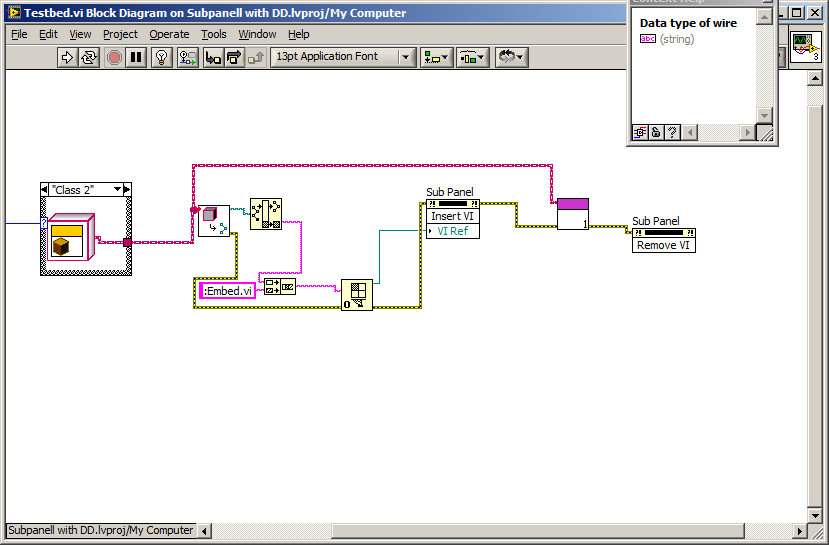
Download File:post-3951-1210796693.zip
Oh yes, and I should have closed that vi-reference....
-
-
QUOTE (Sebastian @ May 5 2008, 09:21 PM)
In your vi.lib/Utility/VariantDatatType folder you will find all kinds of useful vi's for poking around at the datatype of a variant control. Disentangling the datatype of a cluster is a little tricky since you have to handle things like clusters of clusters and clusters of arrays of clusters....
Attached is a quick hack that will give you a string describing the type of any control wired to the variant, including working down arrays and clusters recursively. It doesn't handle refnums, but you can get the basic idea...
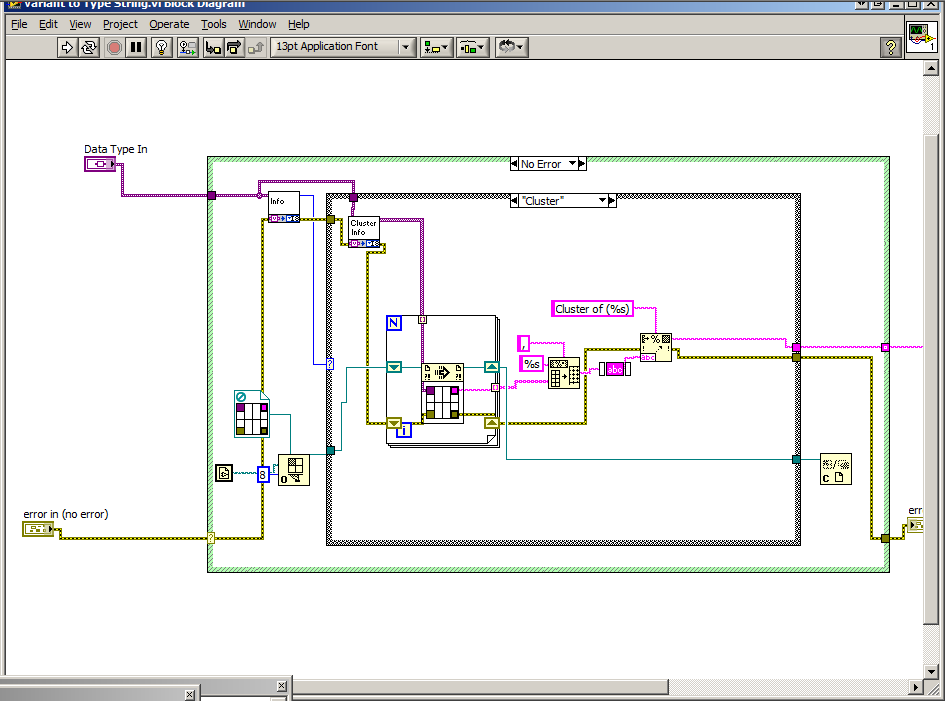
-
Firstly, a caution. Most LAVA folks don't take kindly to be asked to do someone's homework assignment for them. However you seem to have at least made an effort to get somewhere which is better than most...
You might want to think about what the effect of raising 2 to the power of your integer and then looking at the binary representaiton of the resultant number might be. A handy way of inspecting the bits of the binary representation of an integer is to use the number to boolean array primitive. Then you might want to read up on shift registers and also on boolean operations as a way of latching a boolean value to true.
QUOTE (MicrochipHo @ May 5 2008, 05:57 PM)
i have created a front panel which has an array of booleans indicator, and a numeric input.My assignment now is to generate a wire diagram that is used to activate individual elements of the away, turning the lights on when the true case is selected, and only one element should be true at any incident.
After that it is to be put into a while loop to be terminated after each loop after wach element of the array has been true at least once.
What I have is a conditional to see if the input number is even, and I have set a build array function outside the cause structure, to build an array. Right now it runs, but it only builds one element of the array each time it runs. Showing in the indicator when it is indexed at 0 and the input is even.
I am guessing that there needs to be a loop to continuously feed a variable in thru the conditionals, or to have one input compared against three conditionals..
Here is what I have done so far...
can someone give me a starting point
-
QUOTE (wan81 @ Apr 28 2008, 02:24 AM)
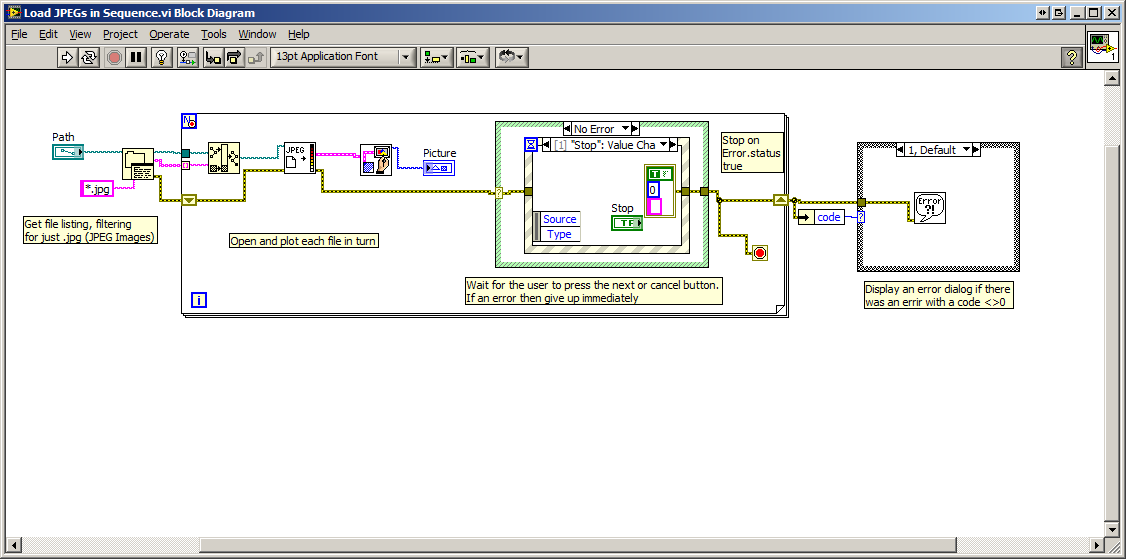
Here's the vi in 8.5.1
-
QUOTE (Micael @ Apr 25 2008, 02:33 PM)
Thanks, I'll fix it in the http://code.google.com/p/lavacr' rel='nofollow' target="_blank">SVN repository version later today and release a new package sometime after that.
-
QUOTE (Tomi Maila @ Apr 24 2008, 01:27 PM)
The code tries to handle the byte order issue but it seems that at least in this one place I fixed, it was ignored. There may be other byte order bugs as well, I only used one type of TIFF image to test the code.Furthermore, be careful when using this code in a parallel application. The library uses LV global to specify the byte order of a single file. If multiple files with different byte orders are read in parallel, the code will fail. This would be rather easy to fix, but I didn't fix it yet. Maybe I will in a month or so as I need to start reading TIFF files for a project.
Hmmm, I'm pretty sure I didn't put the global in there... on the other hand I'm also pretty sure I just ignored byte-order issues all together (the original version of the code read images generated on a Windows machine (from an FEI FIB200 system for those that are interested) and displayed on a Windows LabVIEW).
Perhaps we should put the TIFF library up on the new Lava code-repository project on Googlecode to keep a track of bug fixes to it....
Edit: Now done - in 8.5.x\Machine Vision and Imaging\TIFF File Reader
Probably the easiest thing to do is to LVOOP up the internal file processing routines and then the endian-ness can be kept to a per image setting without globals. I think I can see one bug already with the Get Tag value has two outputs - single value and multiple value, but for one type of endian-ness the former isn't being set...
-
QUOTE (Michael_Aivaliotis @ Apr 21 2008, 11:55 PM)
Perhaps we should create folders at a higher level that break down the code based on LV version. I was thinking of doing this for the LAVA CR downloads but it is less important than during code development, since the LV version is indicated on the download page.Would seem sensible to me. Do we create separate directories for every minor bug0fix version - how big is the binary difference between an 8.5 and 8.5.1 vi ? Is it worth it stop the reporistory filling up with trivial recompile differences ?
-
QUOTE (Cat @ Apr 21 2008, 05:45 PM)
For example, one of my current projects is a data recorder (to vastly over simplify it). I need to set up a connection to a data server, read data, save data, manipulate data in different ways, and then save the results. I would usually write this as a series of modules that perform those functions. Is my only class "Data Recorder" and all of those functions methods of that class?Over the years I have written tons of code that basically does just this. I can't imagine it all falls under 1 class. It seems rather ridiculous to have an Ethernet Card class and a CPU class and a RAM class, and a Hard Drive Class, but that's the only other way of looking at this I can come up with.
Am I making this too hard?
I can't pretend to be an OOP guru - lI too have spent most of my programming time working in non-OOP languages (and a lot of that in LabVIEW at that). Because of this, I've never really done much with the various GOOP frameworks, on the otherhand I have found that I'm gradually shifting more of my coding over to LVOOP where the by-value encapsulation of data and inheritance seem to work reasonably naturally to my mind.
Where I've found myself writing LVOOP classes in measurement code has been in two distinct ways:
- I've converted a lot of my instrument drivers to a LVOOP heirarchy - I have a base Instrument class that providess methods like Initialise and Close and protected methods like Wrtie-Read, and some utilitiy methods for doing things like reading data from SCPI compliant nstruments. On top of this I layer classes that define generic instruments e.g. source-meter, temperature controller, lockin - these just define an interface but don't implement any actual code themselves. Finally, I write classes for each instrument that implements one of the generic instrument classes - this my measurement program can be written in terms of "Source-Meter" class and its methods, but then switching between e.g. Keiithley 24xx and 26xx source meters is just a question of sending the right child class down the wire. This makes adding new instruments to the code base really very easy...
- Most of the measurements that we do boil down to "measure y=f(x,a1,a2,...an), extract some parameters, adjust a1,a2,...an, repeat. So I've started to write classes heirarchies that implement this - I have a base X-Y class which I then create child classes for doing e.g. I-V measurements with a source meter, G-V measurements with a current source and a lockin - again adding a new measurment just means implementing a new child class and common methods like saving data, plotting data are defined only in the parent class. Similiarly I'm doing classes to adjust the a1,a2 parameters - which are typically temperatures, magnetic fields, gate voltages.
None of this is rocket science, and I keep discovering that I've made some error in my design of the class hierarchy, but I think it gives a flavour of how OOP (and for me LVOOP in particular) can be made to work in "real-world" applications. As for the by-ref vs by-value debate - I can see that for experienced C++ programmers by-ref is the only way to go, I suspect for LabVIEW developers who have never done any OOP, by-value seems more natural modulo those times when you have a class representing a physical thing that you need to work with in parallel loops, when by-ref is the only sensible way. It's certainly not worth a jihad

-
QUOTE (Michael_Aivaliotis @ Apr 21 2008, 08:50 AM)
If you give me your Google email address in a PM then I can add you as a project member. Google Code supports SVN. There is currently no source code in there. Feel free to grab any code from LAVA or new code and put it in there. Let's see where this thing goes. I'd like to keep discussions on the code on LAVA.Ok, I've stuck in my Rusty Nails stuff - VI Scripting Tools and some XNodes, including my XNode for determing how a sub-vi is wired at runtime. In the process I've arbitarily established a directory structure that mimics the CR structure. It occurs to me that we might want to do something to indicate which LabVIEW version files are in... my stuff is all in 8.5.1 which I've switched to for primary development of new code.
Share and Enjoy
-
QUOTE (Gavin Burnell @ Apr 19 2008, 11:59 AM)
QUOTE (Aristos Queue @ Apr 20 2008, 04:21 AM)
-You may also be interested in this article "Command Line Interface for LabVIEW"To output the results of yourLVprogram back to the command line, use the System Exec.vi (which you can find by searching the palettes). It has the ability to output to either standard output or standard error.Ok, now I'm feeling pretty dumb....
Actually, I can see how the System Exec allows you to access the STDIN/STDOUT of whatever process you are running, but how does one persuade it to connect to the STDIN/STDOUT of the process that launched the LabVIEw app ? I mean if I did something like executing "cmd \c cat -" wouldn't I open a new command shell window which would display whatever I wired up as standard input ? Or am I missing soem trick here ?
-
Ummm, I'm pretty sure you can't (easily). LabVIEW doesn't give you access to the standard input/output and pretty much assumes that you are running under a GUI. There are various tricks one can do to make it not run with any GUI e.g. running as a Windows service, but even a compiled LabVIEW application doesn't run inpendently of the runtime and that assumes a GUI.
The broader question is why? LabVIEW is great for many things, but writing console programs is not one of them.
-
-
Every so often someone posts a question along the lines of "is it possible to determine inside a sub-vi whether a particular control of that sub-vi is wired up or not in the calling vi ?"
The normal answer to this question is no, followed by various workarounds. One obvious way is to make the default value of a control an obvious "bad" value, e.g. NaN or -1. This is not always possible, since sometimes you can't predict what a 'bad' value is. There are also other various workarounds floating around on LAVA. As fas as I can tell, most of these involve parsing the diagram to locate the sub-vi reference and then examining which of the sub-vi node terminals are wired. This has various problems:
* You need to parse not just the top-level diagram, but all the sub-diagrams of case strictires and sequence structures etc.
* What happens if the sub-vi is called twice in the same vi - which sub-vi node is currently executing ?
* It only works in the development environment
* It's slow
The last time the question was asked, I thought maybe an XNode could wrap a sub-vi call and somehow pass in the wiring data into the sub-vi. Here is my initial implementation of this scheme. You need to download the very latest version of my Scripting tools from the Code Repository (0.17.01) and possibly do a mass compile of them to ensure the linkages are all correct for whereever you keep them. The magic XNode is in the attached zip file along with a very simple demo. NB This is pretty much hot of the wireworks and barely tested proof of concept.
To wrap a vi, drop the xnode onto the callers block diagram and right click on it. Select the option to Load a vi into the wrapper. The wrapper then takes on the icon of the wrapped vi and has the same terminal pattern as the wrapped vi. When you wire anything into the wrapper it generates code that will set a control on the wrapped vi with the wiring data. The control should have the same name as the wrapped vi and should be an array of clusters of string, string and variant (there is a term types.ctl in the Subvis folder of the XNode wrapper for this). The two strings in the cluster are the terminal name and an ID which is the order of the terminal on the connector, pane.
Doublie clicking the wrapper will open the wrapped sub-vi
Bugs and outstanding issues:
*LVOOP and XNodes don't mix and may therefore break LabVIEW in unpredictable ways (like this code doesn't :!: )
* If you don't wire anything up then it probably doesn't generate anycode ever...
* The help window doesn't (help that is). I need to write a help ability that clones the help info from the wrapped vi
* I tried to get it so that you could drag a vi onto the wrapper to load it, but I can't get it to work - any XNode Gurus know how to fix that ?
* subvis with icons that are not 32x32 will probably look ugly
* The directions of the wiring stubs may be a bit wrong
* I'm fairly sure that the code that is used to connect terminals to the cal-by-ref node in the generated code is slightly wrong.
* Oh yes and did I mnetion that this is almost entirely untested code that I've written to see if it worked at all....
-
QUOTE (yasmeen85 @ Apr 1 2008, 07:06 AM)
Hi allI would to ask about this error how can i solve it
(requested VI is not loaded into memory on the server computer)
Thanks
Ah, that's easy. You just have to load the requested vi on to the server. Then you won't get the error.

Seriously, you need to give us a lot more context to even begin to understand what might be the problem that you're having.
What is your program trying to do - which vi is it not finding loaded into memory and how does it normally work. Is this a program that runs on just one computer or is it somehow distributed across a network ? Does it have any fancy architechture like plugins or is it just one program loaded up in one go ? Are you working with a compiled executable created by someone else or are you working with a LabVIEW development system and can access the source code ?
The error message is pretty self-explanatory in as far as it goes - you are trying to use Vi-Server functions to access a vi that hasn't been loaded into memory and so can't be accessed.
-
QUOTE (Aristos Queue @ Mar 31 2008, 08:32 PM)
No, it's not.But it would be really really nice if it were. Sure the trick of using a 'null' default value works but I've done too many enums that go ["don't change","on","off"] to represent what ought to be naturally boolean data that I might want to change.
Actually, how about having an XNode that wraps the sub-vi calls and somehowpasses the connected term types into the sub-vi - trivially by the sub-vi having a 'special' terminal that is only used by the XNode to tell it which of the other terminals are wired. Perhaps there's a more elegant way thi can be done with tagging a reference to a contro on the subvi with the connection data. It's sort of cheating, but might do the trick.
-
QUOTE(ibbuntu @ Mar 7 2008, 07:41 PM)
Just a random thought: Wouldn't it be nice if when you right-clicked on a class' wire there was a menu option to insert a method vi of that class?I have a feeling that this has been suggested before, but Aristo Queue (aka the great god of LabVIEW Native Classes) had said that it was extremely difficult to implement because it would involve loading not just the class, but the entire set of ancestors to work out what methods were available (or something like that anyway).
Personally, I'd settle for right clicking on a class wire and doing an insert bundle by name and have it wre up the cluster prototype and output correctly
Rate of Change
in LabVIEW General
Posted
QUOTE (mross @ Jul 3 2008, 06:30 PM)
LV 8.5 (PDS anyway) has a point-by-point differentiation vi, although I've never actually used it myself. What I've tended to do is to use a shoft register to store thae last n data points (and timestamps if the data is not being evenly sampled) using a rotate array and replace array element to insert the new data points and having initialised the array with the first datapoint repeated n times. You then feed that to a linear fit and use the slope as the first derivative. That is more robust against eexperimental noise than just using (y[n]-y[n-1])/t[n]-t[n-1]), although it does mean that the derivative lags behind the data by n/2 points, which is a problem if the data changes slope suddenly. You can work around this a bit at the expense of a noiser derivative by fitting a higher order polynomial and using the co-efficients of the fit to calculate the derivative. That's broadly what http://en.wikipedia.org/wiki/Savitzky%E2%80%93Golay_smoothing_filter' rel='nofollow' target="_blank">Savitsky-Golay filtering
does.