

bsvingen
-
Posts
280 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by bsvingen
-
-
In the NI white paper about LVOOP it was mentioned that a by ref system tree could be made by using the parent object in the class of a child object. I didn't quite understand how, but it should be possible (according to the paper)
-
To get an idea of the performance of the LV2 style reference system i have made some test cases using the dqGOOP test cases as templates. In contrast to what i wrote last night, it IS possible to create arrays from clusters with strings (i have no idea why it didn't work list night, i got a strange error saying that LV could not determine the wire type, maybe that was in LV8 because i started with that?? all these test cases are for LV8.2).
There are 6 test cases, dqGOOP(locked), dqGOOP, variant global ref, string global ref, LVOOP global ref and a "specific" ref for the actual strict type def cluster.
They are all similar in performance except for the locked dqGOOP which is much slower. There is little penalty in using variant compared to using a specific typedef (only about 30% slower in set), and there is no practical difference between variant vs string. dqGOOP (unlocked) have a few percentages better performance in get/set, but the global refs are fully asynchronous.
-
I made two examples yesterday that mimics a chunk of memory in a computer in a single LV2 style global with an array inside. It is a ref making system and makes real references for any kind of variable using variants and another version using LVOOP. It is very efficient, particularly the LVOOP, and compared with using queues it is fully asynchronous.
The other thread is here:
-
File Name: General reference system
File Submitter: bsvingen
File Submitted: 11 Sep 2006
File Updated: 18 Sep 2006
File Category: LabVIEW OOP (GOOP)
An LVOOP class that creates and controls reference-data pairs. The basic idea is to simulate random access memory and malloc()/free() by using one single LV2 style global. The data can be of any type (including any LVOOP class and strict typedefs) and can be allocated in any order. The only restriction to the number of references is the physical memory on the computer. The global stores data in a Variant Array and uses a separate Bool Array to control access and free/protect the data.
The "address" to the data that is stored in the reference (LV Object) ,is the index in the Variant Array where the data is stored in the LV2 Global. By using Variant as the type, it is possible to get a reference to all types, and there is no need to manually change a typedef and possibly the names for every vi when more than one typedef will be used.
A small performance penalty is introduced due to the type conversions to/from Variant. However, due to the inherent effectiveness of LV2 style globals, this method is still 2-3 times faster than an equivalent scheme made with wrappers around queue primitives, but slightly slower than using queue primitives directly, (no wrappers around the queues, see example provided). For an even faster reference system, twice the speed of queue primitives, se the separate "Pointer System" on this Code Repository.
In contrast to queues that can be regarded as synchronous references to data, this reference system is fully asynchronous.
Allocation and freeing of data is done dynamically.
Allthough this reference system may at first glance have some resemblence to "classic" GOOP, it is by no means a GOOP system. The main purpose of the reference system is to have a fully asynchronous and fully reusable system for read and write access to one single instance of data in more than one place.
All the VIs in the library are documented.
-
The word you're looking for is "XControl." An XControl of the class type is the initialization that you describe.
And, those of you who don't have Pro edition, forgive me... I didn't know when I posted before that XControls weren't in the base package.
The "XControl bug" (only pro-edition) is very irritating. When i purchased this licence (i have had other licenses in the past from other companies), it was when version LV7.0 just came out. The pro edition back then only had extra stuff for site management and cooperative development that i had little use for, othervise the full development system had everything needed for - well - a "full development". So i purchased Full development system + application builder.
In the last days i have read from NI officials (the white paper about LVOOP and a post in here from NI R&D) that XControl is in fact needed for proper automatic initialisation of objects and that the XControl is "the single reason to upgrade to LV8.0". To me they are saying that the Full Development System is NOT a "full development system" anymore, starting from LV8.0.
-
The XControl works only in the proffesional version of labview (at least for 8.0. I have only the full development version + application builder). If it is meant to be used, it has to be made available, at least now when LVOOP has been released.
-
To be more correct, it is an explicit constructor that is not needed because the objects are already made in the VIs as controls or indicators (you still can have "init" functions, but they won't work as constructor functions in ordinary languages, they are just ordinary VIs to fill the object with data).
I disagree with your point that LVOOP is good for beginners. Students today are seldom teached FORTRAN, C/C++ or Pascal. They are teached JAVA and Matlab. When you start with JAVA, OOP is learned from the start (the way OOP is meant to work). Then when they start using Labview i think they will scratch their head more than once trying to figure out how this call by value objects are going to be used. Personally i can see that LVOOP will protect data and make programs more organized (that is also very much due to the project builder), but i still don't see how LVOOP will make the program structure better.
-
As long as the connector pane is the same, we still can use the same init name for the init method for all inherited members. I see that it will be a rather irritating restriction to keep the connector panes equal, especially when theres alot of inherited functions, and you want to change one of them, but it will work (you will have to wire a correct object constant to the init function though, and therefore i don't think it is vise to initialize objects this way, but use the overriding mechanism for other tasks such as plug-ins for instance). Another option is to use the "to more specific class" in the more specific init functions (with specific names and without dynamic dispatch), that way you cannot use the wrong init function, even by accident due to different connector panes, and you don't need to wire the correct object into the function, and you allways get the correct object out.
But the main point still remains, you do not need to explicitly initiate objects in an "init" function when all objects are call by value and inside a data flow paradigm environment like LV. The objects will be initiated at first use no matter how you look at it, because they aren't really initiated in the correct sence of the word, they are only given values since they already exist in the VIs as controls or indicators just like any other LV types. You just make a VI that takes the input you need, and out pops the correct object.
-
I still think you are pointing to a shortcoming that does not really exist in a call by value - data flow "world". The object may not neccesarily be pointing to a file, rather it would be the file itself or more precisely the data in that file. The file path or ref may only be a part (input) of the method "write data" or "read data". Still, in that data object there may very well be a control for the file ref or path, so that the cluster looks like:
[DATA]
[file ref]
The "initial" or default values would be empty data and "not a ref". IMO it would be just as strange to initialize the file ref to anything else than "not a ref" as it would be to initialize the data to anything else than empty data (all objects are always 100% determined since they are call by value).
Now, if you want something else, you just write a member VI that initiates the object with whatever values you want. There is no need to create the object in any form upfront, the VI inputs all kinds of non-object data and output the object itself. A "read data" or "set data" method may therefore be all the constructor you need. If you use by ref, you will have to create the *ref* before you can create the object. And since a ref without an object is totally meaningless you will be 100% sure that all refs points to valid objects, and therefore you need a constructor.
The only time i see that this may in some strange cases cause problems is if the object is created as a constant and used directly with no other considerations, but this would be the same as opening a call by ref object with default parameters on the constructor, or use an arbitrary floating point constant in calculations.
-
That is when ever object buffer is created, it is created not only by reserving a block of memory and initializing this block to default values but instead reserving a block of memory and calling some code to do the initialization. I see no reason what so ever that in dataflow paradigm would not allow this.
I don't think anything prevent you from doing this, either by normal programming or by using XControl at those places where you need such functionality. But the main point is that in dataflow "objects" are created when data for the "object" (controls) arrives, or at branches (copies) and then everything is 100% determined.
-
IMO the LV8.2 objects are just strict type defs with their own sets of wires that only VIs "belonging" to the wires can act on. Or in other words, some sort of protected clusters, since they only can be called by value. However, they also have inheretance and overriding. All in all, considering that they shall be used in a data flow setup, and be consistent with all the other existing types as well as the data flow paradigm, i think NI has done a good job.
In a data flow language there are no need for explicit constructors/destructors and copy methods, because all this is an implicit part of the language (or rather a non-existing part, because there are no variables in the normal sence of the word).
I think LV8.2 objects function exactly as they should. The main problem is that LV is a is graphical DATAFLOW language, and not the GENERAL graphical language that most of us would like that it should be. What it lacks most is an effective way to store data, and effective pointers and references.
-
I think the data flow paradigm is a main issue. For data logging, control and somewhat also for data analysis, data flow in a graphical language is a good choice because it will simplify the programming by making the language very intuitive and straight forward in relation to what you are trying to do. As a general purpose language i don't see any benefit of the data flow paradigm at all, it only complicates and bog things down since everything is passed by value and there is no way to effectively store data without breaking the data flow.
If G was to become an open standard, i think the first thing that would be scrapped was the data flow paradigm, while leaving only the graphics where execution order is mainly determined by passing of error clusters and references/messages and with a much more effective pointer/reference system. But i dont think this would be beneficial (in intuitive terms) compared with the data flow paradigm for most control and logging applications for which LabVIEW is made and used. For instance, GOOP as implemented in all the different versions i have seen uses passing of references, which is a huge step away from the data flow paradigm in which the G language is built. These GOOP implementation (along with ordinary LV2 style globals) simplify the program structure, but they do so because they step out of the data flow paradigm, and consequently will confuse more than help in cases where data flow will do just fine (although they pinpoint the weakness of the data flow paradigm for general purpose programs).
If G was to be opened, i think it very soon would evolve to a state where it no longer would be intuitive and straight forward to use in most data logging and control application, but would be much better suited for general purpose programming that the case is today.
-
Christ, and i used a day just to delete and recreate graphs

Suggestion: What about a separate folder here on LAVA for solutions like the one posted? No discussions or remarks, just the solution. I think that would be great.
-
 You don't need a CD. The application builder is already installed. The only thing you have to do is to write in the license number for the bulder in the license manager - and - voila
You don't need a CD. The application builder is already installed. The only thing you have to do is to write in the license number for the bulder in the license manager - and - voila
-
You are not calling the correct function. SendInput should return an UINT, while your call does not have a return value (you have set it to void).
From MSDN:
UINT SendInput( UINT nInputs, LPINPUT pInputs, int cbSize);
Add UINT (whatever kind of int that is) as the return value, and it should work. Maybe you also should make the call reentrant.
-
I had the same problem when i wanted to save to LV7.1 format from LV8.0 and i made graphs in LV8.0. I think it's because of a major bug in LV8.0 concerning the graph property causing properties in the property window to be different from the actual properties that can be set directly in the graph window (i think??). LV8.0.1 does not have this problem. The only solution i found was to make completely new graphs "from scratch" (a real pain, but it worked).
-
Well this is very usefull, for instance you are acquiring data at a hight speed and need to process this as well. You could 'give' them both a different core, this would mean that data acquisition and calculation don't come in each others way..
Ton
That's the theoretical part of it. But in a practical situation the data acquisition is handled by dedicated hardware, so it's already paralleled and multiprocessed. Besides, analysis demands much more computing power than acquisition (seen from the PC), so the end result is still max 50% utilization of the PC's dual core processor.
I have yet not seen that LV uses both cores within one loop (maybe it uses several threads, but never both cores). This means that it is *extremely* hard to write an analysis package that uses both cores effectively, since you have to prallelize it by hand.
To detach the user interface from the rest of the program therefore seems to me to be the only thing that the dual cores can be used for in a practical setting. But then, this can be very useful in sutuations where you have lots of graphs and stuff, and guaranties 100% responsiveness.
-
Thanks for the info. When i got this PC some 3-4 months ago i was a bit puzled about why LV only used max 50% (only one core) in seemingly all applications i tried, since LV was supposed to be "inherently" multitasking etc. But then i forgot about the whole "problem", since all the other applications also seemed to be using only one core. Today I got NI-News with an article about multicore processors and i got curious again.
-
I don't really know how that happened. I pushed "add reply", and my reply ended up inside my first post although i wrote it at least 10 minutes after the first.
Anyway, are there any rules to this multitascing/multicore thing? Is two loops the only method, or are there more?
-
This link from NI site describes LabVIEW's multicore functionality. But - I have a dual core PC, and i have yet not seen a labview application that runs on both cores simultaneously. Are there some special tricks i have to do in the programming ? two completely separated loops or something?
Yes, two separated loops will do it (just tested)
Rather cool actually to watch the CPU use when one loop is turned off, and only one core is running. But, this brings up some questions about the usefulness of this in a practical application where i need to transfer data between the loops. -
I think this is more a matter of effort vs (potential) income/loss than anything else. If you think the potential income is large, then why give it out for free? If you think the potential income is low, then why charge for it? If it is something in between then you could just give it out for free for non comercial use and charge for commercial use and hope that most people are honest and/or charge enough so that you legally can protect it in court if you have to.
It also depends if your VIs are of an "industrial" or highly technical character (will only or mostly be used by corporations and specialists) or if they readily can be used by "most" people, ie. they are more of a generic character. IMO highly technical and special software can be charged (very) high, and there is no meaning of giving it out for free, while more generic software can only be sold much cheaper and it is the potential quantity that can be sold decides if it is worth while charging for it.
-
Well, right now i am not sure what your problem is. A DLL is a DLL and a C array is a C array no matter how you look at it. I call to that DLL is therefore like any other DLL calls, and those arrays are like any other C arrays. I would try initializing both arrays in your C/Java program before you call the DLL with them.
-
I see that you are using LV 8.0.1 When building a DLL in the project builder you have full control over all data. Make sure you choose C calling.
I tried your filter, and my header file automatically made by the project bulder looks like (the default, i didn't do any changes):
#include "extcode.h"#pragma pack(push)#pragma pack(1)#ifdef __cplusplusextern "C" {#endifvoid __cdecl ButterWorthFilter1(double samplingFreqFs, double lowCutoffFreqFl, double Input[], double Order, double Output[], long len, long len2);long __cdecl LVDLLStatus(char *errStr, int errStrLen, void *module);#ifdef __cplusplus} // extern "C"#endif#pragma pack(pop)here "len2" is acosiated with Output and len with Input. So they are just ordinary arrays.
-
Here is an example of improvements in execution speed with inlining. In general inlining is useful when you have lots of small numerical formulas that have to be executed often, for instance when you have two or more arrays and have to do some more or less complex operations on array element basis. This is typical for most data analysis applications. With inline functions the code maintains the modularity (readability) while all the overhead associated with sub VI calls disapears completely. The increase in execution speed can be dramatic for some applications (several hundred percent), while for others no practical increase is seen.
When inlining, the the code becomes very unreadable, so it is only usefull to gain execution speed when the code or sub-parts of the code is finished. A copy of the un-inlined code must therefore be stored for later modifications.
Here is the execution speed before inlining. The inline sub VI has the same execution speed as an ordinary sub vi (they are identical
 ). The one stored/compiled as subroutine performs more than twice as good as the other two.
). The one stored/compiled as subroutine performs more than twice as good as the other two.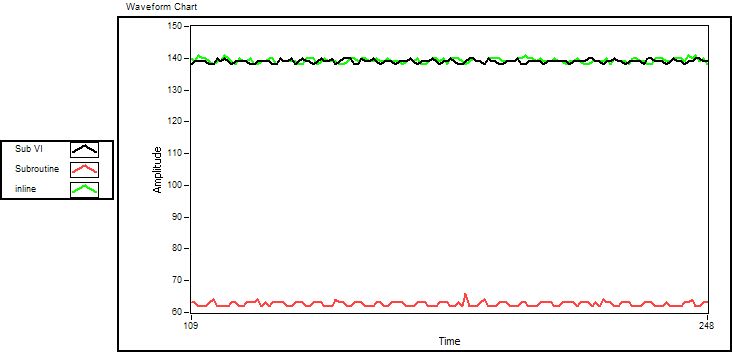
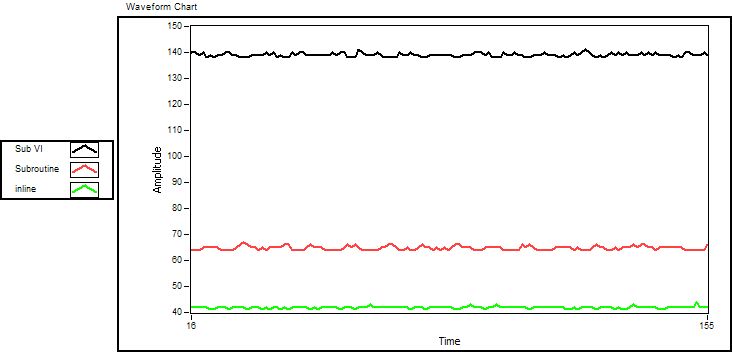
After inlining, the picture is different. Now the inlined code perform almost twice as good as the subroutine, and about 350% better than an ordinary sub VI. This is the effect of one single inline function. For more complicated formulas where the code needs to be broken down into several sub VIs, the improvement will be even more. (Actually the equations in this example are so simple that faster execution speed is obtained by feeding the arrays directly, but that is beside the point and only shows that too simple examples are not allways the best examples
)

[CR] General reference system
in Code Repository (Uncertified)
Posted
Here is another version of the general Variant reference system. In this version it is not neccesary to preset the LV2 global. The arrays will grow according to the number of refs that are created. It is initiated at first use. This means that the LV2 global is completely invisible, it just hangs in the in memory somewhere and do it's job. I allso don't think it is realy nessesary to de-initialize the global, because LV will take care of that in any case when the program finishes. However, it is made so that it still can be initialized if that is wanted.
Download File:post-4885-1156455614.zip