

bsvingen
-
Posts
280 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by bsvingen
-
-
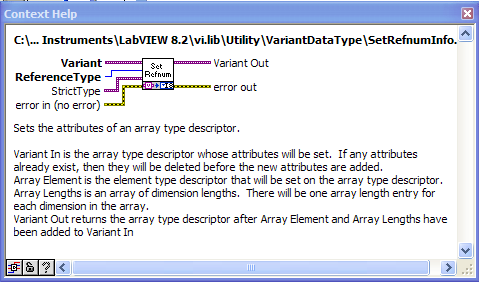
I saw a strange help file some weeks ago. Actually several of these variant VIs have this help file text even though they are completely different.
-
It depends on how this data is going to be used. Is it only saved, or is some of it going back in a loop. My experience with shared variables are that they are incredible slow, a factor 10000 or more for simple read and write compared to anything else you can think of (queues for instance).
You should have plenty of processing power available, however, *steady* 10 ms timing with all that data could still be a problem if you do a lot of memory reallocations etc, so it is probably a good choice not do alot of type conversions unless you abselutely have to.
-
Perhaps I join back to this topic that seems to attract only Scandinavian interest. What I was thinking is that I'll embed the typecasted queue into a LVOOP class as private data. This way I may not get best possible performance, but I do get data protection similar to DataLog Refnums. In addition I can hide the implementation from the user. I start by typecasting to DataLog Refnum as I originally suggested. Later if I feel this is inadequate to my purposes I change to variant as besvingen suggested. I thought implementing the class similar to my last suggestion in topic Refactoring the ReferenceObject example in LV 8.2.
-jimi-
My experience with LVOOP for simple data is that it's actually more efficient than typecasting (and variant). I don't know why, maybe the reason is that when using LVOOP there is no typecasting at all? It would be nice to know what exactly is going on, i imagine it works like this:
Typecast: data is first flattened, then unflattened to the actual type
Variant: data is flattened and the type info is stored along with the flattened data ??
LVOOP: data is just set into the cluster ??
-
But this will be like comparing apples and oranges, besides you are not sending only a ref anymore. Look at my examples 4 and 5 which is a much better comparison.
-
I don't understand how you get those results. Converting a queue ref to variant is just as efficient as typecasting it. Do you do something else than converting the ref?
-
I just have to add one more thing
 When running the version with all the system VIs in a similar test as the previous tests, i get a value around 220 ms. That is when all the system VIs are called. IMO the system VIs are not that abysmal afterall, and can add alot of functionality. The problem is that they are locked (impossible to optimize) and poorly documented, so using OpenG variant VIs for the same purpose could probably be a better choice although i'm not sure if they have the same functionality.
When running the version with all the system VIs in a similar test as the previous tests, i get a value around 220 ms. That is when all the system VIs are called. IMO the system VIs are not that abysmal afterall, and can add alot of functionality. The problem is that they are locked (impossible to optimize) and poorly documented, so using OpenG variant VIs for the same purpose could probably be a better choice although i'm not sure if they have the same functionality. -
Well, I agree that some of the system VIs in labview do have abysmal performance, but i think you are a bit unfair when quoting those numbers. Attached is a much more balanced test. Here i use one variant attribute to store the type (for easy retreival). My numbers are 42 ms for variant and 37 ms for typedef with type. The variant is only slightly slower, but still have all the benefits of variants (full type info and versatility).
Download File:post-4885-1159198639.vi
Here is the "original" test with no type conversions showing variant and typedef with equal performance. Anyway, i'm not saying variant are better. Using variant will be a very different way of passing the data, but they do have equal performance both memory-vise and speed-vise with similar typedef. Variants also have several other very attractive features that only variants have.
-
With variants you get a lot of other posibilities for automation later on, for instance in conversion. See the attached VI where int32 arrays are automatically casted to double array (the default type). It will also be safer because you can add errors when wrong queue/ref types accidentally comes in.
-
Enabling the "Show Constant Folding" options is not recommended. See here.
In short, it does a lot more than "Show" - it turns on a bug!

So, maybe it's not so bad that it's not working for you :laugh: :laugh: :laugh:
Jaegen
Well, unless all it does is to turn on the bug

-
Well, it seems that typecasting the contained types in queues does not work afterall. I made an identical setup as your picture, and although it seems to work for the number zero, putting anything else (3, 4 whatever) in the dbl array, and the int array will consist of just garbage

The utility variant VIs (in ..\vi.lib\utility\variant.something)that seems to be able to set the type etc, will in fact do that, BUT they will also destroy the value. I have no idea if this is a bug, or if it is a feature. Aristos queue may know i hope? When they set the type in variants, but at the same time destroy the values, it seems to me that they have a very limited use, and i'm not sure what they can be used for.
But you can still do the same thing with variant, but the conversion must be done by flattening, then unflattening with the correct typedef. The problem is that this will also produce the exact same garbage for numbers other than zero.
Here is a vi (LV8.2) of the two versions of variant conversion using queue.
-
Even though my show constant folding option is set, it does not show. It was OK in the beginning, but now it just doesn't work. Sometimes when i load VIs from this board, for instance, i can see the folding, but on my own VIs it does not show up.
Edit: It seems that VI in a project is not showing constant folding and/or if the project explorer is opened first. If i open VIs not part of a project the constant folding is showing.
-
OK, what i meant was subroutine priority. Typically for all floating point math is that they are very fast on modern PCs. In Labview an ordinary call to a VI takes often longer time then the math itself. The only way in labview to shorten that call is to set the VI to subroutine priority. The ideal for math functions are stateless VIs, VIs that take the input, do whatever calculations is needed and return the result without any overhead in terms of updating front panels etc. When a VI is set to subroutine priority it is closer to that ideal because it "turns off" alot of state book keeping and control updates. Usually i see a factor 2 improvement when setting a VI containing math to subroutine priority.
-
I think it will be more efficient to convert the queue-ref to variant instead of typecasting the ref. I haven't tried it so i don't know for sure. Just a question: how do you measure the memory?
EDIT: It will use the same memory, but it wont be "transformed" from variant to anything but the original type (at least not without the utility VIs for variant).
-
If you want to interpolate, all the interpolation functions are standard VI with debug option set. The top VI is OK, it can be saved. Also the next level is OK, but then in the third level there is a "remove zero coefficient.. somethong" that is protected and impossible to modify. This means that i cannot set subroutine priority on the top level VI (it will be broken). As they are now (non subroutine and debug) i cannot use these VIs in one of my own applications used for simulation and analysis, they will be too slow.
But it is also the principle. To me it is completely impossible to understand why someone would make a numerical interpolation library, and then set on all the brakes so the library runs as inefficient as possible, and on top of that make it impossible to relese the brakes.
Anyway, i have been in similar discussions before, and if you don't have any applications that is required to run efficient (in terms of execution speed), then please just ignore this post, or the thread will just wander off track.
-
This is one thing that annoys me more and more and degrades the usability of LabVIEW. A lot (most) of the VI included do not have subroutine priority by default. This is not a problem in general, but it starts to be a problem when these VIs are included in my own VIs that have subroutine priority. Before LV8 i had three options, i could:
1. Just change the priority of the system VIs,
2. Save a copy of the system VIs, and rename them slightly (add some __abc for instance)
3. Don't bother at all and change my own VI to "normal".
What i usually did was to save a copy of the VIs. Then i could get everything at the priority i wanted, and i could send it to others, without they needing to change anything on their system (people generally do not want to change stuff like this).
But from LV8 and even more in LV8.2, it is impossible to save copies since most of them are protected. Even worse, it is impossible to change anything on many of them. When upgrading applications from LV7 for instance, this is no problem, since the modded VIs get upgraded along with the rest, but when starting from scratch on an application in LV8.2 I see that this is getting more and more of a problem.
-
In the general case I don't think VIs should be loaded either, but it would be nice to specify some VIs that loads. When you have many VIs and lots of folders it will be very difficult for others to find the main VIs.
-
I just noticed that the "bug" is still there in some circumstances. The counter is only updated when using "Obtain pointer". This makes it possible to use a disposed pointer without an error if the get/set methods are used before obtain new pointer. I think this can be fixed by updating the pointer when disposing the pointer.
-
The update is already there
-
:thumbup: Thanks alot. That was actually pretty neat and i can't see any performance penalty either. This will be included in the update.
-
I agree on that its is a serious programming error, but I do not see why we shouldn't try to protect the programmer from doing such mistakes.
If you should use the upper 8bit value as a counter, the user is more or less protected.
The only drawback is that it will take another 8bit of memory for each pointer storage, and also some additional checks to see if pointer is valid.
I'll see if I can dig up some old stuff that will add that counter to your implementation, if I got time that is...
OK, thanks
I was thinking mostly in terms of efficiency and simplicity, but i'm looking forward to see your implementation. (i must admit i am still not quite sure how the counter is to be implemented, will that be used instead of the BOOL array?) -
I think maybe i understand what you mean. But IMO a pointer is just an integer with a value of an address in memory. When you dispose a pointer, and then decides to use it later, this is bug done by the programmer, and a very serious one. I agree that it is easy to do such an error, but that is just the way it is.
Lets see the alternatives (just on top of my head):
The first alternative is to use pointers to pointers to data, then you can invalidate the pointer at the same time as you dispose of the data. ie when you invalidate a pointer one place, it will be invalidated all places.
A "New" function would then create a pointer that points to a pointer that has the value of -1 (or NIL). When you set data, the second pointer gets the address of the data. Then when you dispose, you free the data array index and set the second pointer to -1 again. In your example the "get data" of the disposed pointer would return an error (invalid pointer), since it will point to -1. Still, this would not be foolproof since you still can call (by accident) the disposed copyed pointer before you actually dispose it (there is no requirement to wire the error wire). Anyway, when using pointers to pointers i see that your solution would be quite meaningful, but it would not be foolprof, using a disposed pointer is still a programming bug.
The second alternative is that by brancing a wire with a reference, you also create a copy of the data that is referenced to. This will be a call by value approach, and is what happends when you branch an Array, but this is not what i want, and would be meaningless to do since i would not get a reference.
The third alternative would be NOT to dispose the data, but simply end the wire (no throughput). This would actually work, but with the risk of filling up the memory.
Anyway, i kind of like the pointer to pointer approach, although i'm not sure if it actually would work (how to dispose the second pointer for instance? You would probably need two functions: dispose data and dispose pointer ?, i don't know).
-
JFM, I think maybe my documentation and naming is a bit uncorrect, and certainly the name "General Reference System" that i have used for the other LV8.2 general system using variants. The system is a pointer system (in a simulated sort of way
), and not a reference system. References in LabVIEW are completely different from ordinary pointers, and therefore it is wrong to call these pointers for references. References in LabVIEW are more like pointers to LV objects (controls, VIs etc), and sometimes they are more like pointers to pointers of LV objects (I don't know if they actually are pointer to pointers, but queue refs seems to act that way). -
Hi,
I think there is a "bug" in that pointer implementation.
The problem is that pointers are generated by finding the next free index. This means that if you dispose pointer p and directly obtains a new pointer q, p and q might be the same pointer value. Dereferencing the disposed pointer p would then still be possible, and would return the value from pointer q.
Please see the attached *.llb.
/J
Good catch
 However, IMO it is not a bug, but simply a natural feature of pointers. It is best to think of the LV2 global as a block of Random Access Memory (RAM). The LV2 global does in fact simulate a block of RAM, and the pointer is just an int32, an address to an arbitrary place in the RAM. There is no connection what so ever between the data stored in the address and the pointer that has this address as a value, other than the fact that the data happends to be stored at the location that the pointer points to.
However, IMO it is not a bug, but simply a natural feature of pointers. It is best to think of the LV2 global as a block of Random Access Memory (RAM). The LV2 global does in fact simulate a block of RAM, and the pointer is just an int32, an address to an arbitrary place in the RAM. There is no connection what so ever between the data stored in the address and the pointer that has this address as a value, other than the fact that the data happends to be stored at the location that the pointer points to.What happends in your example is that you allocate one slot in RAM and receives a pointer (the address) to that slot. Then you get the data, AND you copy the pointer (the address) by branching the wire. Then you dispose the data and the pointer. However, disposing a pointer means only that it does not anymore (neccesarily) point to the data that it first was set to point to. In the implementation it means that the data the pointer is pointing to is destroyd, but it does not mean that the location in RAM (the address) is destroyd, just as physical ram is not destroyd.
Since you have disposed the pointer/data relationship, it is now possible to allocate that address again and put other data into it. So your second pointer now has the same address as the first pointer, and the value they are pointing to must of cource be identical.
The same thing will happen in any other language that support pointers when you copy pointer.
It's not that expensive if you use a dual system the way queues do of lookup normally using the number and only occassionally using the string. Only the Obtain Queue uses string. The others all do numeric lookup using the refnum. Add a function that translates string to "pointer" to your system and you're good to go. of cource. It is strange how sometimes the obvious solution just does not occur
of cource. It is strange how sometimes the obvious solution just does not occur -
:thumbup: That's a pretty neat implementation - have you considered creating a variant version so each of the "memory" spaces can have different structures? Also, have you considered using a string-based reference (so you can name a memory space if you want to, or just have an automatically generated name if not) rather than an integer-based reference to allow subsequent calls to reference a memoery space by name?
I have made a variant version earlier, it can be found here. It is only for LV8.2 since it also uses LVOOP as a class for the reference. This pointer version is really only a stripped down version of the variant ref, with the aim of making references to data as efficient as possible.
I have done some (very preliminary) thoughts about using names. So far I just can't see how this can be done without adding a lot of overhead and difficulties. It will require a lookup table of some sort to be efficient (hash table or binary tree). The only primitives i know that has efficient lookup tables built in is queues and variant attributes, and i therefore think that such a system would have to include either one of those primitives built into the LV2 global or instead of the LV2 global (maybe some sort of dqGOOP style system that i have seen examples of here on the board). Either way, a lot of overhead is added when using names, since that name needs to be "dechiphered" in some way no matter how you look at it.
Probably? the most efficient way to use naming as the "reference", and if you are not too concerned about actually obtaining a "wireable" reference, is to put one single Variant in a LV2 global and set all your data as attributes in the Variant. Then you have named globals that can take any type. I have tested the variant attributes as a lookup table, and it is incredible efficient.
XML scripting
in VI Scripting
Posted
There is a bunch of XML Script VIs in LabVIEW 8.2\vi.lib\_script\XML Scripting Does anyone know what these are for? Is it something to come, or can it be used now?