

smithd
-
Posts
763 -
Joined
-
Last visited
-
Days Won
42
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by smithd
-
-
1 hour ago, Michael Aivaliotis said:
- Package release for every LabVIEW version. Wow, this seems like NI took the one built-in feature of LabVIEW (automatic up-conversion) and threw it out the window. Way to go NI?
- Pre-Post build actions. I would have to look into this further. I thought NIPM had a command-line interface (or at least this is what I was told). You could build a wrapper around that and create a VIPM-like experience, could you not? Then include your pre-bost build steps? Perhaps include palette editing (see item 1).
- No package of packages.- Meh. Nice to have but there are other possible solutions to the same problem.
- Packages can't be loose VIs, they must be in something like an EXE, or source distribution first. - Well, VIPM creates a source distribution behind the scenes when it builds a package. But I get your point. NIPM could hide this complexity. - Not a showstopper though.
(2) I think I've mentioned this elsewhere, but its more accurate to say that NIPM has no knowledge of labview. Its simply a system-level package manager, akin to opkg, apt-get, chocolatey, etc. You can make the same source distribution in say, Labview 2015, but since its an OS-level package manager, you have to make a different package for each of Labview 2015, 2016, ..., 2015 x64, ...
One comment on that, is if you look at the NI installers, they often just make one package and install the VIs anyway. I only have 2017 installed, and yet I have a labview 2014, 2015, and 2016 folder for whatever reason. So nothing stopping a more lazy package developer to make a single package that deploys the same source distribution to 12 different directories.
(3) I believe NIPM can technically do this through a custom XML file, pointing at a simple batch or at cmd.exe: http://www.ni.com/documentation/en/ni-package-manager/latest/manual/instructions-xml-file-packages/#GUID-29BE2213-93C1-4281-8570-7CE1338AEB4A
http://www.ni.com/documentation/en/ni-package-manager/latest/manual/assemble-file-package/
(6) Yeah, an otherwise empty package with dependencies is the traditional fix for this
(8) Actually this is the part I like better about the NIPM build process -- its much more explicit and it seems easier to me to figure out when stuff goes wrong.
Also, a good landing page for NIPM is: https://forums.ni.com/t5/NI-Package-Management/NI-Package-Management-Portal-READ-THIS-FIRST/ta-p/3805952
-
9 hours ago, ShaunR said:
That's a trope initially perpetuated by marketing people. There is no message. If developers discontinue a product they will [almost] always say so in the notes, comments or website unless they were unexpectedly hit by a bus.
For a counter argument, ask NI marketing "is DSC dead?"
Last time I heard that question they bent over backwards to claim it's not, and yet...
-
https://github.com/jkisoftware pulled a few of the repos over to github but it doesn't look like any work has been done (the updates shown are just licenses/readmes).
42 minutes ago, hooovahh said:I made several idea exchange requests for Array, File IO, and Clear Errors to act more like OpenG.
I definitely agree with most of those as 'this would be nice'
Also, and I realize this is kind of petty...but why green? Why on earth...snowy mint?
-
1 hour ago, ShaunR said:
Yeah. I can't claim that one. It was originally a criticism of OOP

I thought it sounded familiar
") 2 hours ago, Michael Aivaliotis said:
2 hours ago, Michael Aivaliotis said:Well, your comments are definitely valid for any tool distributed as a package. Not just OpenG.
Thats definitely true, I just think that in the case of openg theres no real reason not to merge a lot of them (bool, string, error, comparison, array, data, numeric, time, file) because all of those are basically vilib++. While people might not really want all of them, I doubt many would object to "too much bloat".
But to that point, any attempt to modernize openg would have to look hard at whats there. For example, from the error lib:
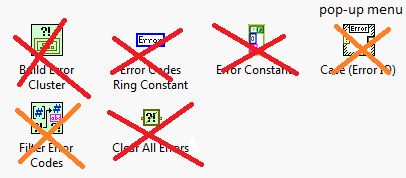
Labview has all of the red items on the palette already, filter error codes is just a for loop around clear errors (from 2014+), and the case structure is...just a case structure with error wires in and out. Personally I use this, although admittedly it took me >5 minutes to find it and I'm the one who wrote it.
And this error lib is a dependency of pretty much every other package, because its also a dependency of the string library.
-
Just for myself, I don't really use openg and never have. I've definitely been using lv for shorter than many on here, so I'm curious if thats part of it (ie lv has picked up the slack over the years) or if its just me. Distributing code that uses it to other people always ends up being annoying. I'd rather write a for loop to remove duplicates from an array than try to explain to some coworker that they need to first install vipm and then look for the specific package and then when it asks to install 17 other dependencies install those too, etc. The for loop is easier.
-
Link is now dead, they got the feedback I guess.
Well, the feedback that this particular install is bad.
Not the feedback of "maybe you should test these installers before uploading them" ?
-
 1
1
-
-
Yeah VIMs are pretty buggy although I'm still back in 17.5. For one particular set (using classes of course) I've had to just convert every instance to static manually, else the exe won't compile. Fortunately I just use them as helpers at the very top level, and drjd's json ones haven't caused any issues.
-
https://dotnetcademy.net/Learn/4/Pages/1
Its roughly analogous to combination of VI server/scripting + lvoop class loading + variant data type inspection VIs + openg type code inspection VIs...except with a more consistent design
His point is just "if you can't call the constructor directly because labview is broken, you can have .net call the constructor manually, by name, using reflection". The direct labview equivalent of what he posted is https://zone.ni.com/reference/en-XX/help/371361P-01/glang/get_lv_class_default_value/
-
Did they fix your issue here?
https://forums.ni.com/t5/LabVIEW/TDMS-Excel-Add-in-18-Crashes-Excel-2013/td-p/3796275
I ended up just removing all of 2018 and reinstalling the driver set because I couldn't make that stupid plugin revert properly (in part because I had NIPM installed)
-
1 hour ago, Michael Aivaliotis said:
Ya, that's strange. I tested it on chrome and safari and it looks fine for me.
I notice the dots are working and the discussion round icon is dimmed. So it seems it's partially working, but not the bolding?What browser? Chrome?
Yeah, chrome, and I have ublock but its disabled on lava
-
any ideas why this might be happening?
Specifically, everything is bold, regardless of being new or not. I only see this on one computer, but its the same profile (and browser, extensions) on both.
-
2 hours ago, rolfk said:
In my LabVIEW 2016 in which I'm still mostly working Clear Error.vi is set as clone and to be inlined!
Yes they fixed some of those silly things in more recent versions. Also turning off the call chain on error cluster to code so that RT systems didn't do tons of string manipulation. If I remember his posts correctly shaun uses some ancient version like labview 8.1 or something
")
-
9 hours ago, ShaunR said:
You forgot the /rant tag
Indeed

-
17 hours ago, ShaunR said:
OK. So what sort of features would we want in a new package manager?
Here are a coulple that I've long hoped for:
- The ability to export a package dependancy list (Just the names and versions? Or more than that?).
- The ability to export licences of a package and all its dependancies.
- Automatic detection of 32 and 64 bit binaries.
- Support installation of VIPM, OGPM, LVPM, executables (like setup.exe) and zipped packages.
- Import from public online repositories (like Github, Bitbucket etc).
What else?
Having spent this morning trying to deal with vipm I have two additional suggested requirements:
1-Dont require a GB of RAM to unzip a few files
2-Dont dick around with the windows API every few seconds in an attempt to get the user's attention

3-while performing long running operations, don't queue up 10M instances of a 'refresh' message so when the long running operation completes your user is still sitting there for five minutes watching the screen refresh.
-
1
-
also, google immediately gives several examples.
-
I don't fully understand what you're wanting to do, but as a starting point it sounds like you want to use the producer-consumer pattern where the daqmx code is a continuously-running data producer and your UI is a data consumer. They communicate using a queue (eg a first in first out buffer, as you suggest). There are sample projects included in labview (eg "continuous measurement and logging" here http://www.ni.com/product-documentation/14031/en/) which may give you a better starting point than a blank diagram.
It also sounds like you may need some assistance with how to trigger and fetch your data -- it sounds like you need something like this (https://forums.ni.com/t5/Example-Programs/Finite-Acquisition-with-a-Software-Retriggerable-Reference/ta-p/3530011) but you might also read through this: http://www.ni.com/tutorial/4329/en/
Also, depending on how much you want to do or how far you want to go, it may be worth the money to just buy an application like FlexLogger: https://youtu.be/hoNoJjMsuGI You can download a demo and see if it does what you want http://www.ni.com/en-us/shop/data-acquisition-and-control/flexlogger.html
-
Except that in this case we're talking about a reference which refers to a type def. Saying this is consistent behavior would be like saying "its OK for any queue refnum that references a type def to break whenever the type def changes" -- something that obviously does not happen.
-
2 hours ago, UnlikelyNomad said:
Any chance you have an example of this? Not sure I've ever run into something like this before
Probably did not explain it right, but attached is an example. Open main.vi, open the type def and add a field to it (eg a 2nd string). Save and close the type def and the code breaks because while the VI ref is tied to the type def, the controls appear to be tied to the version of the type def at the time of their creation -- eg, type prop fails. The solution for bigger projects is to type def the control or wrap it into a class or whatever, and then you only manually update it in one place, but I find that pretty annoying as well so I do the variant form (terriblesolution.zip) as this requires zero manual updates. On a related topic, I would have no objection to someone coming here and saying "you're an idiot, you can make it update if you just do X" but I haven't found any X so far.
-
6 hours ago, Francois Normandin said:
The reason for this typecast is to break type propagation that plagues edit-time performance which occur when you have a large class hierarchy. It is not because it makes scripting easier (on the contrary). In essence, when you edit a class' private member, the class' mutation history is modified and the LabVIEW IDE goes through a series of checks and recompiles to propagate the changes. For very small projects, this is completely trivial and does not affect edit-time performance, but for larger hierarchies (think Actor framework...) it becomes a real issue. One way to reduce this performance lag is to never put typedefs in the class private data... but this is up to the developer to stick to that rule or not. When you use an integer, using typedefs does not affect the edit time performances at all.
Never heard of this, but makes sense. I do the same (using variants of course) when it comes to static VI refs (eg 'call and forget') because any change to a type def in the connector pane breaks controls/indicators -- type prop doesn't update them. So I have my create reference in one subVI that spits out a variant and then everywhere I want to launch an instance I just have another copy of the static ref and a variant-to-data function which casts it back. Avoids annoying labview bugs that way.
-
9 hours ago, smithd said:
To clarify, it can crash labview if you get it wrong and uncast to the wrong type. Or so I'm told. I've never attempted to do this because a variant is a type-safe way of accomplishing the same task.
I tried this out and can confirm that accidentally swapping types has the following behavior:
dbl->dbl = OK
string->dbl = always displays the prior value of the DVR -- probably something bizarre to do with the fact that I started with dbl-dbl and its in debug so the memory space stayed the same. No error though, and the value didn't update as I changed the dvr (string) value.
int(0)->str=OK
int(positive number)->str=crash
-
10 hours ago, UnlikelyNomad said:
I'm avoiding DVR wrapped classes (versus my DVR wrapped in a class) because unless I'm missing something... dynamic dispatch doesn't work with that mechanism. I'd much rather either continue doing this manually or create some tooling to significantly cut down on the bootstrapping effort.
DD doesn't work directly on a DVR (except property nodes), hence my malleable VI suggestion. Of course malleables just make it easier to call -- you still need to have the method in the class, so your tool would still be useful.
1 hour ago, planet581g said:Can you show me how to make LabVIEW crash by doing this? I created and destroyed 1 million DVRs that were cast to integer and cast back to DVR and couldn't get LabVIEW to crash. Attached VI made with LabVIEW 2013.
To clarify, it can crash labview if you get it wrong and uncast to the wrong type. Or so I'm told. I've never attempted to do this because a variant is a type-safe way of accomplishing the same task.
-
14 hours ago, UnlikelyNomad said:
I'm curious what y'all think! Does anyone do similar ByRef designs? Anyone have ideas or suggestions? Once I get the DVR member accessor scripting implemented I'll uploading this to GitHub for public
critiqueconsumption.As a general rule I prefer this style to the DVR-of-a-class (eg session framework: https://forums.ni.com/t5/Reference-Design-Content/Extensible-Session-Framework-ESF-Library/ta-p/3522019)
The argument against it, which is also very valid, is that its hard to indicate that your class has by-ref features because by definition that dvr inside is private. So they must operate as if your class is by-value unless they know the class and all children have no by-value components. You could make the same argument about sticking a visa reference in your class -- its a reference, but you wouldn't go calling your class a by-reference class.
Using a DVR-wrapped class and the malleable VI features added in 2017sp1 would seem to be a nice route. You can template the DVR unwrap and define an interface which the malleable VI will adapt for you.
For context to the below post, I previously commented that I'd prefer a tools menu item because the project provider scares me, but I looked around and theres a lot of examples out there so I decided to remove it...at the same time it was being replied to.
-
25 minutes ago, UnlikelyNomad said:
I'm curious on the effort done to cast DVRs back and forth between an int.Googling doesn't seem to bring anything up so I'm curious how this became a thing and what benefits it provides? Does it stop LabVIEW from doing some tricky thing with DVRS? Does it make the scripting simpler?
Don't do this, it can crash labview. If you need to cast, I think a variant will at least be safer (var to data should return a NaRefnum if its the wrong type, while cast to and from int will have labview attempt to dereference a random pointer you told it was good). There may be guards against it, but its not worth it.
-
I've always done a separate 'data' or 'data formats' library. Its generally useful for your situation as well as the lv real-time situation (don't want to load up a bunch of PC-side libs/classes into RT land, but still want type-safe messages). If its all on a single target, I'd probably be lazy and do what I think you said: the target of the message owns the data type. But of course that breaks down if more than one target uses that type.

VIPM LAVA Repo
in LabVIEW General
Posted · Edited by smithd
I find it amazing how convoluted licensing gets..considering thats literally how all money comes in. And I don't say that to pick on JKI -- I say that to pick on a company I saw today which has no less than 7 core software packages, plus for 3 of them you have to buy an add-on for support, plus there are several add-ons compatible with all base versions, plus one specific add-on only compatible with the upper 2 tiers, plus an additional add-on cost per seat which varies based on which base model you selected. It made me ?
NI vision is another example -- not quite as bad, but I still have no clue which imaq functions are included with what license.