

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
204
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
> So that must be documented somewhere
No, it doesn't have to be documented anywhere. And as much as you are willing to bet that it exists as a spreadsheet somewhere, I'm willing to make the counterbet. Why would I make the counterbet? Because I was working on this exact problem last month, and the only definitive way I found to identify whether a given primitive/datatype/control/subroutine/configuration was valid on a given target was to let the target syntax checker run. An individual node may be generally known to work on a target, but not in one of its configurations. Or only if the project is configured a particular way. The edge cases are rare relative to the total number of nodes, but there are still plenty of them.
-
Wait... so you want to be able to do this *without* loading the VI on the actual target?
I'm fairly certain that *we* could not write something that a priori said whether or not a VI would work on a given target because each target defines what it accepts. It allows us to write new features into core LV and have targets add support for those over time. Functions that work on one FPGA may not work on all FPGAs... functions that exist on one desktop target may not exist on all desktop targets. It is up to the particular target to decide whether to accept the code or not when the VI loads on that target.
So, no, I don't think there's any way to do this short of loading the VI on the target and seeing if it is broken and, if it is broken, removing it (if your goal is to only include non-broken VIs). And if you build any sort of caching scheme for that information, you would want to invalidate that cache whenever the LV version bumps.
I think this is the only (reliable) way.The documentation is a broad categorization of yes vs no, but any specific target may have differences with the general declarations. I would say the only reliable way is to load a VI on the target and see if it is broken. (Notice that table doesn't say anything about FPGA, for example.)
-
I have not tested whether the type testing or the following is better performance, but my tweak below fixes the undetected coercion problem.
-
 1
1
-
-
This is easy.
Write a VI that has a conditional disable structure on the block diagram for each of the cases you want to identify. "Desktop" or "RT" or "FPGA". Then have each frame output the appropriate value of an enum. When you call that subVI in your code, you can test that enum value.
Now, as for why you would want to do that instead of including the conditional disable in the calling code so as to avoid the runtime check, I have no idea. But assuming there is a good reason to do that, the solution above should solve your problem.
-
mtat76's concerns are true but irrelevant. No matter what you do, there is work going on in the UI thread, and any blinking LED is going to have to do some work in the UI thread in order to affect the UI. This is not an "unfortunate aspect", it's the way things are designed to work. LabVIEW timeslices the UI thread to all requesting parties. Can you do things that hang the UI? Sure. Such a hang will hang all of your UI processes, not just this XControl. By and large, when those processes occur, they are at times when your user is not paying any attention to the rest of the UI.
-
Rolf has the right answer... there is no relative path from one drive to another drive, so the path that gets stored is an absolute path.
-
Fabiola de la Cureva: "I hide the configuration file in a hidden directory with a strange name. I do that to avoid the 'users with initiative' problem." [i.e., debugging why the system is broken only to discover that someone has been fingerpoking the setup.]
That little phrase "users with initiative"... so much more tactful than the terms I've heard developers use over the years. Not that I would ever say that about any of *my* users. :-)
-
1
-
-
In situations where failure to filter a message may allow state diagram violations, the presence of a race condition is almost certainly undesirable. Then filter and state knowledge need to be in the same place.
So when that case arises, Filter would send a message to Nested to handle it, perhaps packaging as a single message a whole block of messages that lead to the problem. Doing so means that Nested assumes that it is launched by a Filter for correct operation since it does not include its own filtration system (something that would be redundant under the design of a private Nested actor class).
Any other holes?
-
I am not sure I'm following your terminology. But if I'm reading this right, your example isn't quite what I was thinking, and tweaked, I don't think the race condition exists. Check my logic, please...
Here's the original launch stack...
Caller Actor
|
Filter Actor
|
Nested Actor
Nested Actor is given Caller Actor's direct queue so Nested can send to Caller directly... the advantage here is that Filter then only has to worry about messages coming one way and not about sometimes having to pass them up to Caller. Now, here's the fix that I think stops your race condition: Filter should *never* send messages to Caller. Filter's job is all about shielding Nested. If Filter wants to say something to Caller, that's actually a real job, so have it send a message to Nested that says, "Please tell Caller..."
Does that close the hole? All the state knowledge is now in Nested, in one place.
-
There's a "mini-language" approach that I've seen done. You give your child classes (TCP/UDP/CAN/etc) a method "What To Do About This Error.vi"... that VI takes the error in and returns an array of string output. Each string is a command like "Log the error", "Drop the error", "Retry Operation", "Consign The Network To The Flames Sanctum Ignious Eternum", etc. The framework then does the commands one by one (like processing a message queue in one of the string-based state machines).
Variations on that system abound... you can make the mini-language be an array of message classes, each of which invokes a particular method on the framework. Sometimes you can get away with having the "What To Do About This Error.vi" call methods of the framework directly, but most people don't like that because giving the child classes scope of the methods generally means the child can call methods at other times, potentially destabilizing the system. The string and msg class approaches strictly limit what the child can request and when.
-
An actor receiving requests is generally in charge of its health and destiny; an actor sent commands is subject to DoS attacks or other hazards from external sources, whether incidental or malicious. As Dak mentions, separating incoming messages from the job queue is a great implementation for receiving requests (I owe a lot of my understanding and respect for this concept to the JKI State Machine).
I haven't worried about this aspect much because it seemed to me that any actor that needs to shield itself from incoming messages from its caller can be implemented as two actors, one that listens to the outside world and drops abusive requests, and an inner one that actually does work. The inner one doesn't even necessarily have to route through the outer one for outbound messages. Thus separating the two queues is trivial for those actors that happen to need it, but most don't.
Is there something wrong with that approach?
-
Could you point me to that thread? I had a quick scan but couldn’t find it.
Here's the most detailed one:
https://decibel.ni.com/content/message/33454#33454
There have been others, but they've been tangents in the middle of other threads. It's basically just me listing off the same workarounds that have been listed here, but a bit more detail about the options. So far, everyone I've pointed to that thread has found something there that works for them.
-
Personally, I think the tradeoff in flexibility would be worth it, but it would mean that that flexibility would be used to build some problematic code.
What use cases are you trying to solve? I want paragraphs describing particular functionality that you cannot achieve with the AF as it stands before we introduce new options. I created the AF in response to one repeated observation: many users need to write systems for parallel actor-like systems, but it takes lots of time to design one that is actually stable, and it is incredibly easy to destabilize them with the addition of features. I've built a few of these systems both with the AF and with other communications systems, and they are *hard* to debug, simply because of the nature of the problem. The more options that exist, the more you have to check all the plumbing when considering what could be wrong. We need the plumbing to be invisible!
I stuck "learnability" as one of the AF's top priorities. I get mocked for that claim sometimes ("You call this learnable?!") but when compared to the nature of the problem, yes, it is a very approachable solution. Introducing options is a bad thing unless we are solving a real need. So don't tell me "I can't do filtering on the queue," because that's a solution. Instead, tell me "I can't process messages fast enough" or "I need to only handle one copy of a given message every N seconds". And then we can talk through how best to implement it. In the case of filtering, there's a fairly long thread on the AF forums about various ways to do this with the current AF, and general agreement that those are *good* ways, not hacks or workarounds to compensate for a hole in the AF.
I'm not criticizing his decision to go that route, but the consequences are that end users are limited in the kind of customizations they're able to easily do.But are they limited in the types of applications they are able to write? That's the real question. Yes, the AF demands a particular programming style. That consistency is part of what makes an AF app learnable -- all the parts work the same way. If there is something that cannot be written at all with the AF, that's when we talk about introducing a new option.
So, please, spell out for me the functionality you're trying to achieve. In terms of filtration, I think that's been amply (and successfully) answered. In terms of proxying, take a look at version 4.3. If there's something else, let me know.
-
1
-
-
Not necessarily. MJE just posted a classic example of exactly what I am trying to get accross.
I posted a reply to MJE, but one section of my post there is relevant here:
> When I add a flexibility point, I prefer to do it in response to some user need, not just on the off chance that
> someone might need it because every one of those points of flexibility for an end user becomes a point of
> inflexibility for the API developer, and, ultimately, that limits the ability of the API to flex to meet use cases.
That pretty much sums up what I've learned over my years of programming for component development.
Advanced users get the flexibility of choosing whether or not they want to enforce the same requirements the original developer thought were necessary, and casual users get the reassurance of edit time errors. Win win.I had actually been putting together notes -- based on this conversation -- for a concept I was calling "a class' optional straightjacket". Where it falls short -- at the moment -- is module interoperability. Suppose we say that "all actors will stop instantly all activity upon receiving an Emergency Stop message". And we made that an optional straightjacket for actor classes. An actor that chose not to live by the straightjacket isn't just a loose actor, it is actually not an actor... it's ability to be reused in other systems is actually decreased. It is, in a sense, unreliable.
That lead me to consider "a class that chooses not to wear the straightjacket *is not a value of the parent class*". Bear with me here, because these notes are a work in progress, but you brought it up. If a parent class has a straightjacket to let it be used in an application, and the child class chooses not to wear the straightjacket, then it can still inherit all the parent class functionality, but it cannot be used in a framework that expects classes that use the straightjacket. This makes it very different from an Interface or a Trait because the parent class *does* wear the straightjacket, but inherited children do not necessarily do so.
Thoughts?
-
Before everything else: Have you looked at experimental version 4.3? Does the option to add actor proxies satisfy your use cases?
If that does not address your use cases...
There's a whole lot of thinking behind the walls in the Actor Framework. I'll try to walk through them.
Up front, I want to say that I'm totally open to changing parts of the AF... lots of it has already changed over the last two years of user feedback. These are the arguments for why it is the way it is now. They are not necessarily reasons for why it has to stay that way.
1) Assertions of correctness. Can you guarantee the correctness of a message queue that drops messages? Maybe but not necessarily... the message that gets dropped might be the Stop message. Allowing the plugability of arbitrary communications layers into the framework breaks the assertions that allow the framework to make promises. I've tried to make sure that no one can accidentally reintroduce the errors that the AF is designed to prevent (a slew of deadlocks, race conditions and failures-to-stop, documented elsewhere). "The queue works like this" is a critical part of those assertions. What I found was that too much flexibility was *exactly* the problem with many of the other communications frameworks. When people tried to use them, they quickly put themselves in a bind by using aspects of the system without understanding the ramifications. This is an area where even very seasoned veterans have shown me code that works most of the time but fails occasionally... generally because of these weird timing problems that cropped up from mixing different types of communications strategies.
2) Learnability of apps written with the AF. My goal was to build up a framework that could truly be used by a wide range of users such that a user studying an app written with the AF he or she has certain basics that are known for certain. I wanted debugging to be able to be straightforward. I wanted a module written as an actor to be usable by other apps written as a hierarchy of actors. Plugging in an arbitrary communications link causes problems with that.
3) Prevent Emergency Priority Escalation. I went to a great deal of trouble to prevent anyone from sending messages other than Emergency Stop and Last Ack as emergency priority messages. Lots of problems arise when other messages start trying to play at the same priority level as those two. In early versions of the AF, I didn't have the priority levels at all, and when I added them, the successful broadcast of a panic stop was a major problem that I kept hearing about from users developing these systems. An actor that mucks with this becomes an actor that breaks the overall promise of the system to respond instantly to an emergency stop. "But I don't want my actor to respond to an emergency stop instantly!" Well, tough. Don't play in a system that uses emergency stops... play in a system that only sends regular stops or has some other custom message for stopping. Actors are much more reusable in other applications when they obey the rules laid down for all actors.
4) Maximize Future Feature Options. The Priority Queue class is completely private specifically because it was an area that I expected to want to gut at some point ant put in something different. Maybe it gets replaced with primitives if LabVIEW introduces a native priority queue. Maybe it gets an entirely different implementation. I did not want anyone building anything that depended upon it because that would limit my ability to change that out for some other system entirely or to open up the API in a different way in the future. I firmly believe in releasing APIs that do *exactly* what they are documented to do and keeping as much walled off as possible so that once user experience feeds back to say, "This is what we would like better," you don't find yourself hamstrung by some decision you didn't intend to make just yet. When I add a flexibility point, I prefer to do it in response to some user need, not just on the off chance that someone might need it because every one of those points of flexibility for an end user becomes a point of inflexibility for the API developer, and, ultimately, that limits the ability of the API to flex to meet use cases.
5) Paranoid about performance. Dynamic dispatching is fast on a desktop machine. Very low overhead. But I was writing a very low level framework. Every dispatch, every dynamic binding to a delegate, gets magnified when it is that deep in the code. I kept as much statically linked as possible, adding dynamic dispatching only when a use case required it.
5) Auto Message Dropping Is A Bad Idea. There's a long discussion about message filtration in the http://ni.com/actorframework forum. It's generally a bad idea to try to make that happen with any sort of "in the queue" system for any sort of command system. The better mechanism is putting the filtration into the handler by using state in the receiver... things like "Oh, I've gotten one of these recently and I'm still working on it so I'll toss this new one." Or by introducing a proxy message handler... a secretary, you might say... who handles messages. Putting the proxy system together is what I was working with people to put together the networking layer that I published in January as version 4.2. (I added a cut point in response to a use case.)
6) Lack of use case for replacing the queues means lack of knowledge about the right way to add that option. Who is the expert about the type of communications queue? The sender? The receiver? Or the glue between them? MJE, you mention querying the actor object for which type of queue to use. Is that really the actor that should have the expertise? Perhaps Launch Actor.vi should have a "Queue Factory" input allowing the caller to specify what the comm link should be. Honestly, I don't know the right way to add it because no actual application that I looked at when modeling the AF had any need to replace the queue. What they generally needed instead was one type of queue instead of the three or four they were using (i.e. communications through a few queues, some events, a notifier or two, and some variables of various repute).
And I just noticed Daklu's signature. In light of this discussion, it makes me giggle:
Yes, the QSM is flexible. So is Jello. That doesn't make it good construction material. -
Is gaining compile time checking worth unnaturally twisting around the requirements so they flow up the dependency tree instead of down?
IMHO, the answer is "yes" in the initial writing the code case and "hell yes" in the event that you're releasing version 2.0 and the requirements have changed. Every error caught by the compiler is worth months of runtime errors and errors that potentially are not found until end users are seeing them.
-
Deprecation as opposed to deletion. If you just delete it you will break any existing code anyway. It's nice to give developers a heads up before just crashing their software

And that's why you make something private: so it can be deleted without breaking any existing code.
What have binaries got to do with anything? That's just saying use it or use something else.The binaries ensure that when you ship something as private, someone doesn't make it public and then blame you when you delete it.
-
Of course you can change or delete them. You just need to "deprecate" them first (which to me you should always do anyway).
Deprecation? As a common solution? Do you work in an environment where revisions of classes take two years between iterations and where you can support all the old functionality during that time? I definitely do not. Backside functionality of a component is revised on a monthly basis. I mean, sure, deprecation *sometimes* works for widely distributed libraries of independent content, but that is a non-starter for most component development within an app.
As for them making changes to your own code, that's one of the strong arguments for distributing as binaries, not as source code. Myself, I prefer the "distribute as source and let them fork the code base if they want to make changes but know that they are now responsible for maintaining that fork for future updates." But I understand the "binaries only" argument. It solves problems like this one.
-
Personally? More the latter (but I have heard reasonable arguments for the former). For example. In languages where you declare the scope of variables, then it's imperative to define variables that maintain state as private (this restricts creating debugging classes). Methods, on the other hand, should generally be protected so that the you don't restrict the ability to affect behaviour and I have never seen *(or can think of any) reason why any should be private. Even those that the developer sees as private "may" be of use to a downstream developer.I think that here we fundamentally disagree. There is only "re-use"; one "instance", if you like. Can it be re-used without modification. Re-purposing without modification goes a long way towards that and the more restrictions, the less it can be re-purposed. One is aimed at the user, the other at downstream developers but they are not in opposition (we are not looking at Public Vs Private). When re-purposed, you (as the designer) have no idea of the use-case regardless of what you "intended". Suffice to say a developer has seen a use case where your class "sort of" does what he needs, but not quite. Placing lots of restrictions just forces down-stream developers to make copies with slight modifications and that is an anathema to re-use.
Alright, I'll concede that with your phrasing I am abusing the term "reuse". Let me rephrase -- designing for reuse is often in conflict with designing for inheritance-for-original-use. The parent class is not being incorporated into other applications or systems. The parent class is being "reusued" in the sense that its code is part of all the children, all of which are participating in the same original system. Speaking to Daklu's argument that these are restrictions that are better placed by the caller... the children do not know the caller necessarily. Oh, they may know "I am used by that EXE over there", but they do not know how that EXE works, or what all the intricacies of that environment are. The parent is the one part of the system that they know. The parent knows the rules it itself had to follow to be a part of the system. It needs to communicate those rules to its children and -- where possible -- help its children by making those rules more than just documented suggestions and instead compiler checked enforcement.
When I used the term "reuse", I'm speaking of the fact that the parent is reused by each child because the child does not have to duplicate all the code of the parent within itself, one of the first motivators of inheritance in CS.
And, as for the "private" argument -- the other reason for having private methods, like private data, is because they are the parts of the parent class that the parent may reimplement freely without breaking children in future revisions. They are often precisely the parts that you do not want children using as cut points because then you cannot change those function signatures or delete those methods entirely in future releases without breaking the child classes.
A trivial one... I have a private piece of data, which, you admit, is useful to keep as private. I may implement private data accessors for that piece of data because it can aid the development and maintenance of the class itself to be able to breakpoint and range check in those accessors. But if I make the accessors protected or public, I have substantially limited my ability to change the private data itself.I have never seen *(or can think of any) reason why any should be private.There are lots of others, IMHO, but that seems to me to be an easy one.
-
This is also the crux of the Private Vs Protected debate. What is it better to do? Put so many restrictions that they have to edit your code for their use case (and you will get all the flack for their crap code), or make it easy to override/inherit so they can add their own crap code without touching your "tested to oblivion" spaghetti - regardless of what you think they should or shouldn't do.
There are two different types of reuse, and two different "ease of use" requirements, and they oppose each other. So the answer is that you put as many restrictions on the class as makes sense for the intended usage.
If I am creating a class that fulfills a niche in a product that others are going to plug into, that parent class is going to be shaped very closely to match that niche, and is going to have as many rules in place as I can have to make sure that any child classes also fit within that niche... in that case, I am *not* designing for this parent class to be pulled out of its context and so I am *not* making it easy for the person who has a use case I've never heard of. Instead, I'm trying to make it easy for the person who *wants* to fit within that niche because they're trying to implement some alternative within an existing system.
If I am developing more of a "top-level library class" meant to be used in have wide utility, then I will create more "cut points" within the class, i.e., dynamic dispatch VIs where people can replace the parent class' functionality with their own.
But suppose I'm looking at a class that is a top-level library class, and that class has a method A that implements the general algorithm, and A calls B that implements a detail of the algorithm, I might make both of these methods dynamic dispatch, so that new users can override either the general algorithm or can continue to reuse that general algorithm and only override B to replace a specific detail. But that has a curious effect -- anyone who overrides A never even calls B [in most cases] because B is specific to the one implementation of A and the override of A does something entirely different. That's a clue that perhaps you really want more like *two* separate classes with a strategy pattern between them.
There are lots of variations. The point is that the parent has to decide which use case it is going to serve, and if it is serving the "I'm helping children to fit this niche" then it benefits from more ability to specify exactly the dimensions of that niche and throwing every restriction in the book on its API. And the whole continuum of use cases exists, such that the language itself benefits from a class *being able* to specify these restrictions, whether or not every class actually uses them.
And, yes, sometimes you have a parent class that you wish you could reuse except for some small restriction... I ran into that recently with the Actor Framework... I actually have a use case for an actor that does *not* call the parent implementation of Actor Core.vi. But removing the Must Call Parent restriction from Actor Core.vi does a disservice to the 90% use case of people trying to correctly implement actors. And, indeed, my use case *is not really an actor*. So that was a big clue to me that the inheritance might not be the best way to handle this, and I looked for other solutions.
-
1
-
-
I'm questioning the (perceived) assumption that the guarantee belongs in the parent class in the first place.
And I'm trying to answer that question by saying, wholeheartedly, without reservation, hesitation or exception, that yes, the parent must, should, needs and wants to declare the restrictions. I'm saying that the parent has to declare what it itself is to be used for. If that design is "I am a free-floating class meant to be used in any number of applications as one of my child classes", then it will have few restrictions. If the parent class is designed to be used as a framework, then it will have many restrictions. But it is the parent class that decides its own usage. And that has ramifications for the children because the children *are* instances of the parent. And as instances of the parent, they want, need, must and should adhere to the rules of the parent.
To go further, the reason for the parent needing to specify its own usage pattern is that a class that is designed to be used as part of a framework is designed completely differently from a class meant to be just a reusable base class for other components. A parent class has to make some assumptions in their own internal code about what is going on around them, and those assumptions are very different for a framework class as for a free-floating class.
And, so, yes, a parent needs to be able to lay down restrictions and a child class must follow them.
And this has NOTHING to do with NI or LabVIEW. This is fundamentals of programming correct code in *any* language.
-
> My persistence was because I was trying to understand why
> you continued to appear to claim it is universally better for the
> parent class to impose restrictions on child classes when (imo)
> that clearly isn't the case.
My persistence is because it is universally true. Whatever requirements that the parent class has, it should be able to impose it through code. It is only the emphasis that shifts, not the nature of the restrictions. As I said, there are still internal restrictions of the class that may need to be met for the class itself to function (the primary purpose of Must Call Parent). It was only the "Must Override" and frequency of "Must Call Parent" as particularly useful that I was downgrading.
-
Can you explain this a little more? If you are creating a framework for other developers to use, why do you need to specify "Do not return something outside the range m-n?" You implemented the framework code, surely you know what values your code is able to return?
The parent defines a method A that says, "I return values within this range." The framework is written to call method A. At run time, a child the framework has never seen goes down the wire. It is this child's override of method A that gets invoked. That override VI needs to be within the range promised by the parent.
You -- the author of the parent class and the framework -- know what values that method needs to return. You have to document it so that anyone overriding your parent class FOR USE WITHIN THE FRAMEWORK knows what values to return.
That bold-italics-screaming part is the assumption underlying everything I and flintsone have been saying: that the primary purpose of inheritance is to reuse a class within the same framework as the parent, not for freeform use of the child class. Classes that are designed for freeform use (i.e. the Actor Framework, various Vector/Hashtable/etc classes, that sort of thing) don't make those sorts of external usage promises, but they still may put requirements on child classes to fulfill internal requirements.
-
shoneil: In this particular case, I'm talking about how many pipeline segments the child class uses in its override VI. If the parent specifies 2 feedforward nodes, the caller will be expecting that it takes two iterations to move data through the pipeline. If the child takes three iterations, it will be out of sync with the rest of the program. In a straight linear program, that doesn't matter, but if you have two parallel pipes where the results get merged at the end of the pipes, you need both pipes to be the same length.
flintstone's comments about RT determinism also apply. I just wasn't addressing those directly, but I have talked about that as a similar problem elsewhere.
@Daklu: I was working on a class today and realized that you are likely primarily concerned about "code reuse" in the sense of inheriting from a parent class and then *calling the child directly*, where the caller does not care about most promises the parent made. I am primarily concerned about "code reuse" in the sense of *calling the parent directly*, which may dispatch to the child, where caller cares exclusively about the promises that the parent made.
If you're not taking advantage of inheritance for actual dispatching but just for inheriting functionality, then you have less need for Must Override and Must Call Parent. Not zero need, but substantially less (you only care about promises made to fulfill parent's internal API requirements, like Must Override on protected scope VIs, not its external API requirements, like Must Override on public scope VIs). And I can imagine that a class designed to be called through the parent could indeed cause frustration if you then tried to write an app where you call it directly through the child, possibly enough frustration that I would suggest you investigate containing the class instead of inheriting from it.
I think this is at the heart of the difference in viewpoint between your position and mine.
For Loop Pass Through Utility *Cross Post Link*
in VI Scripting
Posted
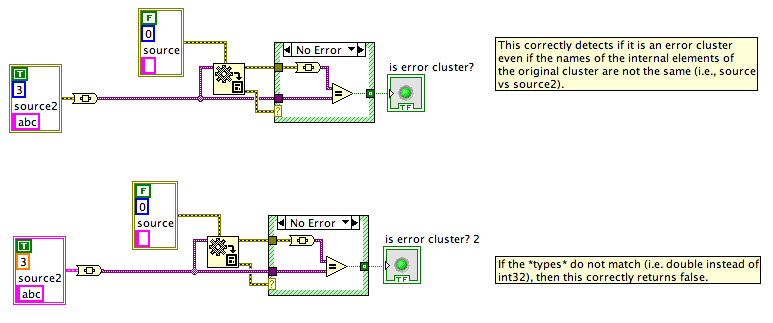
A) There's a minor bug in your existing implementation... you need to close your VI reference. I've fixed this in my version (moved the open of the VI Ref inside the "BD" case and then closed that ref at the end of that frame).
B) The new version that I've put up here detects whether any of the wires are Error Clusters and, if so, turns on the Conditional Stop terminal for the For Loop and wires it. If there are multiple Error Cluster wires, it adds a Merge Error node before the Conditional Stop.
My version is incomplete in one way... if you use this on a For Loop that already has a Conditional Stop terminal wired, it does not add the Or node to blend the existing stop conditions with the error cluster. I started to write that code but got bored. It wasn't the main use case for this VI -- it is intended for new For Loops, predominantly -- but I've left my start on that code inside a diagram disable structure in case someone wants to finish it.
BEFORE:
AFTER: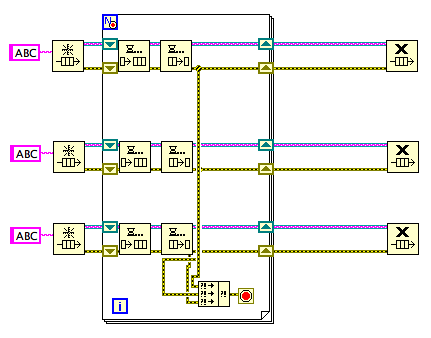
This new version still needs the other subVI from the original post.
Scripting - For Loop Pass Through_With Conditional Term.vi