Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
207
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Aristos Queue
-
Hello, LAVA. My team at SpaceX is looking for LabVIEW developers. We have two job reqs open, one for entry-level developer and one for senior. Ground Software is the mission control software for all Falcon and Dragon flights. Every screen you see in the image below is running LabVIEW. Our G code takes signals off of the vehicles, correlates it for displays across all our mission control centers and remote viewers at our customer sites and NASA. It's the software used for flight controllers to issue commands to the vehicles. This is the software that flies the most profitable rockets in the world, and we're going to be flying a lot next year and in the years to come. If you'd like to get involved with a massively distributed application with some serious network requirements, please apply. You can help us build a global communications platform, support science research, and be one of the stairsteps to Mars. Entry level: https://boards.greenhouse.io/spacex/jobs/6436532002?gh_jid=6436532002 Senior level: https://boards.greenhouse.io/spacex/jobs/6488107002?gh_jid=6488107002
-
- 4
-

-

How deep is you inheritance tree?
Aristos Queue replied to Antoine Chalons's topic in Object-Oriented Programming
Talking G code here only... I don't have a particular max, but most of mine are depth 2 to 4. I've had one get to six. I've had deeper in some other languages. The average depth is shallower these days with interfaces. -
Try it out in the benchmark VI that I posted and see what you get. I believe the answer is yes. As with all performance questions, I hesitate to actually say yes... you [or someone] should benchmark a few cases before committing to that theorem.
-
Just to close the loop: by LV2021, of the three of the Flarn-proof config tokens I mentioned in 2014, two are now public features and one was completely removed from the product as a bad idea. None of them are settable any more. I did not go out of my way to hide any new ones. Good game, Flarn. 🙂 I enjoyed the chase.
-
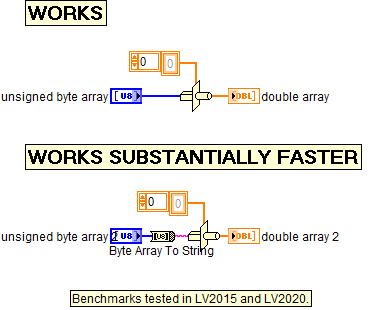
Performance public service announcement. Benchmark is included below for those who want to validate this discovery. "Type Cast" works by flattening the type to string and then unflattening. In this case, it doesn't recognize the special case of the byte array already being a string, but the Byte Array To String node does recognize that equivalence, so doing this eliminates a significant part of the type cast effort. This has been reported to NI as a possibility for future optimization. array-typecast-benchmark.vi

-
To all things there is a season. Jeff Kodosky helped found National Instruments and invented LabVIEW. He inspired hundreds of us who shapes its code across four decades. But Jeff says it is time to change his focus. Today, NI announced Jeff’s retirement. He will probably always be noodling around on LabVIEW concepts and will remain open to future feature discussions. But his time as a developer is done. Maybe you didn’t know that? Jeff still slings code, from big features to small bugs. He’s been a developer most of the years, happy to have others manage the release and delivery of his software. I spent over two decades working at his side. He taught me to look for what customers needed that they weren’t asking for, to understand what problems they didn’t talk about because they thought the problems were unsolvable. And he built a team culture that made us all collaborators instead of competitors. Thank you, Jeff, for decades of brilliant ideas and staying the course to see those develop into reality. Your work will continue on as one of the key tools on humanity’s expansion to Mars.
- 1 reply
-
- 11
-
-
June 3 will be my last working day at NI. After almost 22 years, I'm stepping away from the company. Why? I found a G programming job in a field I love. Starting June 20, I'm going to be working at SpaceX on ground control for Falcon and Dragon. This news went public with customers at NI Connect this week. I figured I should post to the wider LabVIEW community here on LAVA. I want to thank you all for being amazing customers and letting me participate vicariously in so many cool engineering projects over the years. I'm still going to be a part of the LabVIEW community, but I'm not going to be making quite such an impact on G users going forward... until the day that they start needing developers on Mars -- remote desktop with a multi-minute delay between mouse clicks is such a pain! 🙂
- 13 replies
-
- 12
-
-

-
Correct. There's nothing exported about TDRs. It's an opaque hierarchy of types from outside of LabVIEW's core code.
-
I am taking a sabbatical from LabVIEW and NI R&D
Aristos Queue replied to Aristos Queue's topic in LAVA Lounge
I_was_smarter_when_I_was_your_age Can be read two different ways. 😉 -
I am taking a sabbatical from LabVIEW and NI R&D
Aristos Queue replied to Aristos Queue's topic in LAVA Lounge
I have been a community admin for another Stack Exchange site, and the difference in tone between the various sites astounds me. I didn't understand how much rides on the tone the admins take. Stack Overflow, the main Exchange, is really bad to the point that I have shadow accounts to ask questions there because once you ask what is seen by some as a dumb question, they follow you to your next question with "you're still an idiot" type comments. It's massively helpful when it is helpful and deeply insulting when it is not. But it doesn't have to be that way -- it's the choice of the admins for that particular Exchange site. There's a difference between one or two obnoxious persons shining a flashlight in your eyes versus a group of people with laser pointers and magnesium flares. In my experience, Stack Overflow is the latter form of hell. -
I am taking a sabbatical from LabVIEW and NI R&D
Aristos Queue replied to Aristos Queue's topic in LAVA Lounge
I'm honestly unsure how you missed it. If you have suggestions for what would have caught your attention, please share them. Yes, the primary announcement is here on LAVA. But there's signs at multiple booths on expo floor from the sponsoring companies. Many of us include slides at the end of our presentations (assuming we're presenting on a day before the event). Various people wearing LAVA badges are all over who will happily talk about it. But it is not an NI event, so it usually isn't in any NI communication. The event is generally filled at or near capacity with 100+ engineers. We would welcome more if you have ideas. -
I am taking a sabbatical from LabVIEW and NI R&D
Aristos Queue replied to Aristos Queue's topic in LAVA Lounge
But if I just search "LabVIEW" on Google, lavag.org isn't in the first five pages of results when I'm logged into Google, so it knows my interests. My results are similar (but not identical) when I use a non-Chrome browser with private browsing on a new virtual machine (I didn't take time to hide my IP address). That seems like some search engine tuning is in order. -
I am taking a sabbatical from LabVIEW and NI R&D
Aristos Queue replied to Aristos Queue's topic in LAVA Lounge
I skirted the edge of what I'm allowed to say in my last statement. I'm obviously not at liberty to share any numbers, nor can I speak officially for NI on that front, but I personally had no qualms about returning to the LV team based on the data I've seen, at least for now. The future is not as bright as I'd like, but it's good enough for me to keep working. The decline on LAVA is worrisome. I've also noticed the reduction. It might be indicative that all of our new user growth is in experienced groups buying more seats for legacy systems without onboarding more new hires. I worry about that. But there's several other factors that could explain it also: The annual refresh of users from NIWeek/NIConnect has not happened for two years. The forums on ni.com are significantly improved (not as nice as LAVA in my opinion, but good enough to not drive people away like they used to). User groups went virtual during pandemic, which means there are now many more places to go for expert input regardless of geography. The number of other support venues has blossomed -- Stack Overflow is now available to LV in a way that it wasn't just a couple years ago; internal support groups exist at far more large companies than in the past. And the LV population has diversified into non-English countries. So am I worried about the future? Yes. But do I think we are currently in a bad spot? No. -
I am taking a sabbatical from LabVIEW and NI R&D
Aristos Queue replied to Aristos Queue's topic in LAVA Lounge
LV's user base continues to grow. Not as fast as it has at some years in the past, but it still grows at a reasonable clip. -
I am taking a sabbatical from LabVIEW and NI R&D
Aristos Queue replied to Aristos Queue's topic in LAVA Lounge
I don't know if it's the same people, Matt, but I've encouraged a couple folks to jump over to the companies they were temping for because it was better for NI. NI's position with those customers was stronger for having an "insider" on their teams. There is only gain for NI when one of our G developers goes off to be a full-time G programmer for another company! I only worry when our top G developers leave NI *and* they leave G. 🙂 -
Thank goodness I've finally got that promotion. Y'all were holding out on this until I went back to writing C++ code for you, I assume. ;-)
-
I am taking a sabbatical from LabVIEW and NI R&D
Aristos Queue replied to Aristos Queue's topic in LAVA Lounge
Update to this post: My sabbatical has ended. I went from Blue Origin to Microsoft, but as of a couple weeks ago, I have now returned to LabVIEW development. At some point, I may put together a public summary of my experiences as a full-time G dev. For now, be assured that I am feeding that experience back into the feature backlog priority list!- 68 replies
-
- 10
-
-
As Francois noted, no, you cannot prevent it. The default instances are useful in many sentinel and error handling situations -- think like NaN in floating point. The defaults can also serve a role similar to "null" but without all the dangers of open references. Details about design decisions of interfaces can be found here.
-
The restriction on DVRs is the same for interfaces as for classes: it allows for constructor/destructor notation for by-reference entities. Please don't go hyper excited and think "Oh, this is the tool I should have been using all along." By-reference designs are fragile and prone to several classes of errors that by-value code cannot create. Stick to the wires where possible; use references only when nothing else serves! 🙂 Details here.
-
Create pictures with different opacity levels
Aristos Queue replied to GregPayne's topic in Machine Vision and Imaging
Another VI I thought someone reading this forum thread might find helpful. This one calls the one I posted previously as a subVI. "Make Control Glow.vi" draws a fading rectangle behind the specified control. Save it and its subVI ("Offset Glow Rect.vi") to the same subdirectory. For example, here's a glow on a system OK button. Color and border thickness are parameterized. Saved in LV2020. Make Control Glow.vi Offset Glow Rect.vi
-
Create pictures with different opacity levels
Aristos Queue replied to GregPayne's topic in Machine Vision and Imaging
Here is a helper routine that I wrote yesterday based on the other VI. It's the world's most inefficient way to draw a rectangle but it works, and if you're trying to do some sort of animation fade effect, you can do it with this by putting in decreasing opacity. Draw Blended Rectangle.vi -
Create pictures with different opacity levels
Aristos Queue replied to GregPayne's topic in Machine Vision and Imaging
You can't save for previous anything inside vi.lib. Just do Save As >> Copy to a new location and then save that for previous. (It's been that way longer than I've worked on LabVIEW, and I just realized I have never asked why. It's just "one of those things" that I picked up early in my career that became part of the mental landscape.) -
Create pictures with different opacity levels
Aristos Queue replied to GregPayne's topic in Machine Vision and Imaging
New in LabVIEW 2020: C:\Program Files (x86)\National Instruments\LabVIEW 2020\vi.lib\picture\PNG\Draw Flattened Blended Pixmap.vi I didn't create this one. It is not in the palettes. I have asked that it be added in a future version. -
Yes. My current customer does. It is a primary use case that we are currently working around the obvious (and trivial to fix) bug in the toolkit.
-
Allow me to rephrase then. Recording an array when passed a NAMED cluster is definitely a bug, regardless of the behavior of the variants.