

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
204
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
I doubt it. We would have heard an earful from Urs when he visited at NIWeek if this were affecting Mac OS generally.
-
Work fine for me on Win7 and on Mac 10.6.8.
By the way, you have just made me very happy... I had no idea ctrl+shift+E existed. That is a great shortcut... for everyone else: when you're on a VI, it finds that VI in the project tree.
-
I am concerned whenever I see code like the above... people try to write "Load" as a dynamic dispatch function, but that doesn't work most of the time. It does work in some cases, and since I can't find any place where I have typed this up before, I'm going to list off some scenarios... see which one yours matches.
Situation A: There are no child classes to your XML Config class. If you are not creating any child classes, then you shouldn't have any of the VIs be dynamic dispatch. Turn it off and remove the need for the Preserve Run-Time Class function.
Situation B: The config file lists the name of which child class you want to create. In this case, you can't pass in the right object because you do not know it yet when you make the function call -- you haven't read the file yet. In this situation, you have to read the file, create an object of the right type and then *initialize its fields* ... that can be a dynamic dispatch function, but it is not replacing the entire object but rather filling in each field one by one by parsing the XML file. In this case, the Preserve Run-Time Class function will actually work against you because it will keep resetting your object back to the base class that it was when you originally made the function call.
Situation C: You have written a really intelligent XML-to-object parser in that subroutine that is always going to construct the correct child class of the class passed in in the original variant. In that case, this function works fine for all child classes and does not need to be dynamic dispatch at all and the Preserve Run-Time Class is not needed. Note: If you have a parent class of XML Config that is something like "Any File Config", you can then argue that you do need the Load to be dynamic dispatch since you're abstracting which file type is being read. If that's the case then you do need the code as written, but you should wire a constant to the To Variant node so that the conversion to variant will be constant folded and save yourself some performance overhead.
Situation D: This one works with your code. You do have child classes of XML Config. You are opening the config file and doing enough parsing to extract the name of the class so that you know which child class to create. You create the object and then you read the XML file again using this function. It requires you to do double parsing of part of the XML file (once to get the class name and once to actually parse the data) or it requires you to record the class name twice (once for your pre-reader and once in the actual XML of the object). This solution requires that every class *must* override the parent implementation so that the type wired into the Variant To Data function is the exact right *wire* type for every single child class.
-
 1
1
-
-
Yep. It's a good trick. One of those useful tricks to keep in your back pocket.
-
ShaunR -- Yes, that's the sort of puzzle I'm interested in.
-
You do not have to build packed project libraries at all. Just load from source files. I believe that easiest is to save without block diagrams into a .LLB file. Then you have just a single .LLB per class that you want to load, and your EXE can load from that, and without block diagrams, your code is sealed away from modification or inspection, just as it would be during compilation as EXE or packed library.
-
I am curious if anyone has any examples of projects they have worked on that meet ALL of the following requirements:
- Two hardware (real or simulated) elements, each working on its own task
- Some reason why the two parts cannot both be working at the same time at any moment
- Some element of interaction between them at some point in their operation.
A contrived example:
I have two digging machines, both drawing power from the same battery. The battery provides only enough power to move one digger at a time, so the two diggers have to take turns digging. Each digger is digging its own independent hole, but the dirt they dig up is being put on the same truck, and there's only room for one digger at a time at the truck.
In this example, each digger is running its own program, and you can't really sync the two programs to a fixed point because the amount of time needed to dig each hole -- the rocks encountered, the size of the hole, etc -- may vary greatly. So to timeshare, you have to pause one digger at whatever point it is at to let the other digger proceed for a bit. When each reaches the point in the program where it wants to put dirt on the truck, it has to wait if the other digger is already at the truck. Your cooperative multitasking has to realize that there is no reason to pause the digger at the truck because the other digger cannot proceed, but if the other digger is still pulling dirt from the hole, you might pause the digger at the truck to give the other digger some run time.
I know this is contrived. More commonly, you would just have two hardware processes that run in parallel freely and only sync up at their point of interaction. I am specifically looking for examples in hardware of the type of cooperative multitasking that we have to do in software on systems that have only one CPU and do not support multiple threads.
Anyone have any projects they can describe? Any vibration limitation systems (i.e. running both machines at the same time creates too many vibrations)? Power limitations? Etc?
- Two hardware (real or simulated) elements, each working on its own task
-
I confirmed this behavior. Yes, that is definitely a bug. I have filed a CAR to get this fixed in a future LV version.
[EDIT: I confirmed it is still a bug in LV 2012.]
[Further edit:
If you call Quit LabVIEW from any VI that was *not* launched through the ACBR, it does quit LV, including shutting down all VIs that were launched through ACBR. If you call Quit LabVIEW within any hierarchy that was launched with ACBR, it only stops that hierarchy. This definitely seems like a bug, but it will be Monday before I could ask anyone who knows that subsystem intimately.]
-
1
-
-
You can encode binary data in the string of JSON.
-
Another project, also quite small but quite revealing, is, in any text based language, write a program that emits its own source code.
(I've tried doing this in LabVIEW, and the process is very similar but so tedious as to be overwhelming... you need to build a scripting code generator par excellence.)
-
Ah. I've always heard the term in the context of "pulling numbers out of dark orifices." As in, "yeah, that timeline I gave my manager was a total guesstimate."A guesstimate is not a guess. It is an estimate without having all the facts. As Order Of Growth is a simplified relational analysis and usually only denotes a upper bound; it is a "guesstimate" however much maths you put around it. It is a very crude way of describing processes.
-
- Popular Post
- Popular Post
Just someone who needs a more graphical explanation. :-)What do you call a programmer that doesn't understand order-of-growth calculations? Hopeless?
Big-O notation is all about asking the question, "As my data set gets bigger, how much longer will this operation take?" Consider two decks of cards: a standard 52-card playing deck and an Uno deck with 108 cards.
Both of them are in boxes. I can take each deck out of its box in about the same amount of time -- I just dump all the cards out into my hand at once. Since it takes the same amount of time no matter how big the deck is, we call this constant time. As the deck gets bigger, the operation is the same length. Obviously there's an upper bound in this example since at some point the deck will be big enough it'll be bigger than my hand, but we're talking theory here. :-) The time is some constant k. Since the shape of a the graph is the real point of interest, it doesn't matter what number we pick, so this is called O(1).
If I sit at my desk and flip each of the cards into the trashcan, one per second, it'll take me 52 seconds for the standard deck and 108 seconds for the Uno deck. That's an operation that grows linearly -- as the size of the deck gets bigger, the time to do the operation goes up as a pure multiplier. In this case, the multiplier is "1 second". If we say that the size of the deck is N, then the function to find the time is k*N. Or, since the shape of the graph is all we care about, we can ignore the constant, and this is just O(N).
Ok. I tossed all the cards in a trash can one by one. Now I need them back in sorted order. Oh dear. Now, I could get lucky -- I could scoop them off the floor and discover that by sheer chance I have picked them up in order. That's the best case. But big-O is all about the *worst* case. In the worst case, I have to pick up the cards and sort them. Suppose I were to scoop up all the cards and then leaf through them to find the 2 Clubs, and put that on top of the deck. Then look through for the 3 Clubs and put that on top, and repeat for every card. I could be very unlucky -- when I search for each card, it might be the very last card in the deck. If the cards are exactly in reverse order, worst case, then for each card, I have to look through all the remaining cards. Ug. The first few cards are very fast (there aren't many cards to look through), but it gets slower as I go. The early cards and the later cards average out, so for N/2 cards, you have to look through N/2 existing cards. N/2 * N/2 = N^2/4. Again, we don't care about the constant, so this is just O(N^2).
Searching functions are generally O(N) for unsorted data and O(log N) for sorted data. Sorting functions are generally O(N^2) for dumb-but-easy-to-implement algorithms and O(N log N) for intellegent-but-often-have-off-by-one-errors algorithms.
We call any function that is N^2, or N^3 or N to any power a "polynomial time function". These are generally tractable, useful algorithms. We call any algorithm that is 2^N or 3^N or any other constant raised to the N exponential. These often require more time to solve than is available for the time we have to solve the problem. Then there are the N^N algorithms or the N-star algorithms which generally cannot be solved in the life of the universe. N-star means if there is 1 item, the algorithm takes 1 second. 2 items takes 2^2 seconds. 3 items takes 3^3^3. 4 items takes 4^4^4^4, and so on. Ug. :-)
Luckily, we don't have to guess. It's called math. :-)Perhaps you are just more use to the older terminology of "guesstimate"

-
4
-
I like drjdpowell's solution, with the addition of a parameterless dynamic dispatch Reinitialize.vi if you need the "reset later" behavior. Let the class store its initial state as provided by its custom Init.vi and use that when Reinitialize is called.
Queues are the fastest way in LV to move data from one spot to another other than a direct wire. They create no data copies for the data that they shift and can shift large data structures just by moving pointers around in memory. I *believe* events behave like queues as long as there is only one event structure registered to receive the event, but I am not absolutely sure about that.Never mind why I want to implement it, my question is what is the best way to signal the other vi to start working with as little cpu usage and mess. Notifiers? Queues? Events?...
-
If it is any consolation, click-hold-select still works on the Mac in LV 2012. I just tested it.
-
Google this: JSON
-
1
-
-
a) No, you cannot do this. You would need to have an app running that would load the VI into LabVIEW, add the password, then save it, and make sure the user didn't have any unpassword protected copies laying around anywhere.
b) Yes, the password is easily broken.
-
No, it isn't purely academic. Research in this area has lead to new ways of defining data types in programming languages, meta typing in ways that we as humans seem to generally recognize but have been hard to formalize in ways a computer can understand and optimize for compilation. It is an area full of results that have no practical application (so far) and in that sense often appears to be purely academic, but knowing which branches will pay dividends ahead of time is an unsolved problem (and suffers from the Halting Problem).
-
Greg: Yes, making the subVI inline does make it possible for the output to avoid calculation entirely. Doing it on any subVI call is something that the compiler optimization team has on its list of possible optimizations, but not currently implemented.
-
1
-
-
His refnum is explicitly not the same. It's TCP or UDP or whatever.It sounds like your refnum is the same type between each of the child classes?I should note, regarding my solution, that each child class would have to cast its reference as an int32 in order to return it to parent.
Jeffery raises the point about doing more than just checking for Not A Refnum... i.e., checking if a non-zero refnum is still valid. Very important, for (imstuck): read this please:
-
Add a dynamic dispatch protected scope "Get Refnum" to the base class. Make it "Must Override". Call it in the Is Valid implementation.
-
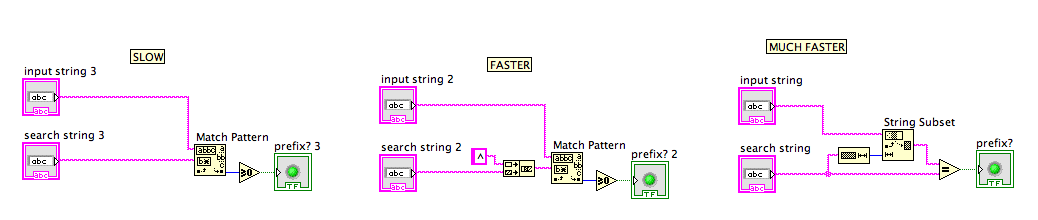
I did some testing... everyone was using Match Pattern... I found a code snippet that was faster than that in every scenario I tested:
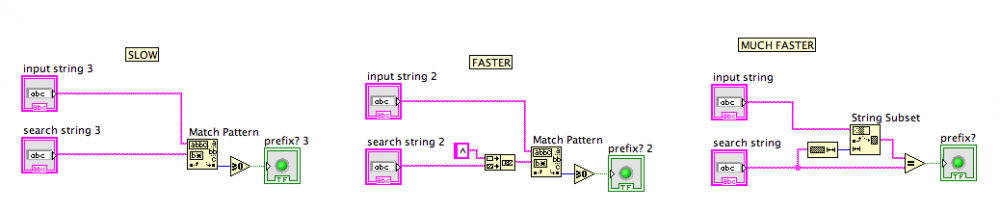
I wasn't sure if it was only prefixes that were being sought ... all the test harnesses only created prefix test cases. If you want "anywhere in the string", then this doesn't help, obviously.
-
Right idea, wrong actual solution. Instead of "Always Copy", use the "Mark As Modifier" option on the Inplace Element Structure instead for this purpose. It signals the same "this subVI could modify this value" on the conpane without introducing an unnecessary copy on No Error cases.Basically, if you do add the error in / error out terminals to your connector pane for 'future use', make sure you place an Always Copy node on the Error wire or any caller could require a recompile if you make changes...
-
2
-
-
Or name your classes differently. I use a combo in the actor framework... there's the "Actor Framework.lvlib" that wraps the generically named but always used together "Actor" and "Message" classes. But the "Batch Msg" class is off on its own, as that's a bit less generic. Chance of collision? Yes. Fact of life, I'm afraid, since LV's libraries aren't merge-able namespaces.
-
We have never introduced any sort of "sealed" concept into LabVIEW. If you do not wish to have to design for inheritance, then you avoid having any dynamic dispatch methods or any protected scope methods.
I'd like to someday add "sealed", but it's not been a priority.
how is the "find text" implemented?
in LabVIEW General
Posted
There isn't. It's all closed C++ code traversing the direct object hierarchy. No hooks have ever been written for G code to plug in.