

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
204
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
-
QUOTE
You say "they are set as follows." Does this mean that LV filled in those values for you or you configured them this way? I ask because that configuration is obviously wrong. The data type for your return type and both args should be double, not integer.When I right click on the call library function on the block diagram and configure the parameters, they are set as follows. -
QUOTE (MJE @ Mar 31 2009, 10:00 AM)
Actually, what's unclear is the meaning of "typedef". :-(If the behavior is intended, I think the documentation is unclear.Yes, this is intended behavior.
Any default value you set in a typedef control applies *only* to a control. The type definition is not defining a type of data, it is defining a type of a control.
The data type -- for the purposes of determining default value at runtime, as, for example, the value of an output tunnel of a For Loop that executes zero times -- is the type without the typedef. The typedef is really only meaningful when talking about how it displays on the front panel or if the data type underlying the typedef changes, for the purposes of block diagram constants.
-
QUOTE (rgodwin @ Mar 30 2009, 03:38 PM)
Thank you. I looked up 112627. It is on someone's list to repair -- just not my list. ;-) Usually I know about bugs with LVClass features, but I (according to the logs) handed it off to someone else to fix and (apparently) forgot about it. It is on the priority list to be fixed.I opened a support request about this issue earlier this month. When I received help on the issue I was pointed to an already existing CAR, that was modified to include the specific issue I addressed. Specifically, CAR 112627.Also, I found that the error only occured when the control is a typedef.
-
-
QUOTE (flarn2006 @ Mar 29 2009, 04:23 PM)
You might be surprised at the easter eggs you discover somewhere around the 9,876th click (in a single session of LabVIEW).I was fiddling around with Cheat Engine and LabVIEW, and I found that it seems to be counting the number of times I access the context menu on a numeric constant. Does anybody know what's going on? This doesn't seem like something LabVIEW would need to keep track of! -
-
-
QUOTE (Matthew Zaleski @ Mar 24 2009, 09:30 AM)
Partially, yes. Enough so that when you hit the run button, we can do the last bits right then and then run it. Try this ... have a big hierarchy of VIs, 100 or more. Then hit ctrl+shift+left click on the Run arrow. This is a backdoor trick to force LV to recompile every user VI in memory. You'll spend a noticable amount of time. That gives you some idea of just how much compilation is going on behind the scenes while you're working.
From a CS standpoint, LabVIEW has two cool aspects:
The dataflow we talk about a lot -- magic parallelism and automatic memory allocation without a garbage collector. But its the graphical that gives us a real leg up in the compilation time. We have no parser. Our graphics tree is our parse tree. That's 1/3 of the compile time of C++ sliced off right there. The other two parts are code gen and linking. Codegen we do pretty quick from our parse tree. Linking is taken care of when we load the subVIs. When you recompile a VI after an edit (something that is usually only done when you Save or when you hit the Run arrow), it is compiled by itself, and the only linking that needs to be done is to copy the call proc addresses of the subVI into the caller VI.
(I'm going to gloss a few details here, but the structure is generally correct... at least through LV8.6.) The block diagram is divided into clumps of nodes. The clumping algorithm considers any structure node or any node that can "go to sleep" as a reason to start a new clump (Wait for Notifier, Dequeue Element, Wait Milliseconds). It may also break large functional blocks into separate clumps, though I don't know all the rules for those decisions. Each clump is a chunk that can run completely in parallel with every other chunk, so if a node Alpha has two outputs that go to two parallel branches and then come back together at another downstream node Beta, you'll end up with at least four clumps -- the code before and including Alpha, the top branch after Alpha, the bottom branch after Alpha, and Beta and downstream.
Clearly, since clumps never know how long it will be between when they finish and when the next clump in line will start running, each clump writes the registers back to memory when it finishes running, at memory addresses that the next clump will know to pick them up. Thus LV tries to build large clumps when possible, and we take advantage of every cache trick for modern CPUs so that the hardware takes care of optimizing the cases of "write to mem then read right back to the same registers" that can occur when successive clumps actually do run back-to-back.
The actual execution engine of LV is pretty small -- small enough that it was reproduced for the LEGO Mindstorms NXT brick. Most of the size of the lvrt.dll is not the execution engine but is the library of functions for all the hardware, graphics and toolkits that NI supports.
All of the above is true through LV 8.6. The next version of LV this will all be mostly true, but we're making some architecture changes... they will be mildly beneficial to performance in the next LV version... and they open sooooo many intriguing doors...
Oh, most definitely.
 I just know that many programmers have a nose-in-the-air opinion that "scripting is for kiddies." Those are the folks who say, "Well, it might work for some people, but I write real code, so there's no way it could work for me." Thus I prefer everyone to be aware that LV really is a compiler, not an interpreter. :ninja:
I just know that many programmers have a nose-in-the-air opinion that "scripting is for kiddies." Those are the folks who say, "Well, it might work for some people, but I write real code, so there's no way it could work for me." Thus I prefer everyone to be aware that LV really is a compiler, not an interpreter. :ninja:QUOTE (jdunham @ Mar 26 2009, 05:31 PM)
If you get a slow enough machine running, you can see the recompiles as you work. The Run Arrow flashes to a glyph of 1's and 0's while compiling. You can also force recompiling by holding down the ctrl key while pressing run, but it's still too fast on my unexceptional laptop to see the glyph (or maybe they got rid of it). You can also do ctrl-shift-Run to recompile the entire hierarchy, but I still don't see the glyph, even though my mouse turns into an hourglass for a short while.You only see the glyph while that particular VI is recompiling. These days you'd need either a reaallllly old machine or a HUGE block diagram.
-
What version of LabVIEW?
-
QUOTE (Jim Kring @ Mar 26 2009, 01:01 AM)
Jim: In situations where there are several valid choices in behavior, why not make sure that whatever you ship allows all possible behaviors and then improve access in the future if some of the hard-to-reach behaviors turn out to be in high demand? With LabVIEW's current behavior, if you want to rename all the VIs, you can, and if you want to rename only one, you can. All behaviors accounted for. If LabVIEW renamed everything when you renamed one, you wouldn't be able to rename just a subset. Functionality loss. Why didn't we just add both mechanisms initially? Consider the issues this feature raises:AQ: In situations where there are several valid choices in behavior, why not prompt the user to choose (and maybe give them an option to not ask again and use their current choice in the future, if that's appropriate)?- Adding the rename all would be additional code to implement the feature plus new menu items which I am guessing there would be severe pressure against since it would push up the already mind boggling complexity of the Save As options dialog (you'd now have two different kinds of SaveAs:Rename, which is, currently, the one easily comprehendable option in Save As).
- Suppose you chose SaveAs:Rename:RenameAll on a child implementation VI. Do we then rename the child and descendants or do we go rename the ancestor as well? Or do we make more options in the Save As dialog so you have three options for Rename instead of two?
- What if some portion of the inheritance tree was currently reserved or locked because it was read-only on disk... does the entire Rename operation fail or do we rename those that can be renamed?
Very quickly this turns into a significant feature requiring a significant slice of developer and tech writer time. Most editor improvements do. The path of least code provides all the functionality albeit without the pleasant UI experience. We go with that unless there is a compelling usability reason to strive for the better UI -- which generally means either we predict the feature will be unusable without the improved UI or after release we get customer requests for a particular improvement.
I have a list of something close to 100 purely editor UI improvements that we could make specific to LabVOOP (LabVIEW itself has thousands upon thousands). I have around 20 major functionality improvments requested. In general, my team has time to implement between 3 and 5 per release as the rest of the time is generally given to 1 or 2 functionality improvements (functionality improvements are generally much harder than editor improvements because you have to implement the functionality and then you still have all the UI problems that editor improvements have). When you make requests, please phrase the priority of those requests accordingly. It helps us decide what to work on next.
- Adding the rename all would be additional code to implement the feature plus new menu items which I am guessing there would be severe pressure against since it would push up the already mind boggling complexity of the Save As options dialog (you'd now have two different kinds of SaveAs:Rename, which is, currently, the one easily comprehendable option in Save As).
-
QUOTE (Ton @ Mar 26 2009, 03:07 AM)
Some SCC VIs do load with the project, but not all. Those for status load immediately. Those for checking in/out wait until there's something open that you could edit.Well all these nice overlay icons for SCC'd items are the reason why I would expect that SCC VIs load direcly upon opening a project. -
8.5 and earlier: VI Property "Callees"
8.6: VI Properties "Callees' Names" and "Callees' Paths" [The previous "Callees" is equivalent to "Callees' Names"]
Start at your top level VI and visit down the hierarchy.
-
I agree. It was the first feature request I made to LV years ago. No one ever sees it as a high enough priority.
-
QUOTE (Darren @ Mar 25 2009, 11:33 PM)
Because not renaming them is intended behavior. :-) I can agree that it might be nice to have a tool to visit all of the overrides and rename them all in parallel, but not renaming them all is just as valid a use case, one that I've needed frequently.I agree. It seems like something we should be able to do. But then again, there may be a good reason for why it can't be done...AQ? -
Quick note: "library" is not the same as "llb". LLB officially is an acronym without meaning. Library refers to .lvlib files. NI made this change to the standard technical vocabulary in LabVIEW 8.0 in 2005. This detail is important because I was going to give you completely the wrong answer.
LabVIEW does have built in ability, starting with LabVIEW 8.6, to do Merge of VIs both inside and outside of LLBs, and to merge new VIs from one LLB to another. That is built into LabVIEW.exe. There is a tool somewhere for teaching Perforce to call LabVIEW when there are LLBs or VIs that need comparison, and to automatically start LabVIEW in comparison mode, but I cannot tell you where that tool is... perhaps someone else on the forums knows.
-
If you have ever wanted to know the details behind how NI evaluates and fixes bug reports, this blog post from NI's John Pasquarette should answer your questions.
What is our bug-fixing process
If you have any feedback about this post, please respond on his blog instead of posting about it here on LAVA -- that will keep the comments centralized instead of spread across three different forum sites.<p>
-
QUOTE (Ton @ Mar 25 2009, 04:36 AM)
Strange, I would expect that these loaded when a project is openend.Why? There are various uses of the project, most notably building an app, that does not involve opening a VI (note I distinguish loading a VI vs opening a VI, since AppBuilder obviously must load VIs). The project loads the pieces it needs as it needs them.
-
My bet: Source code control and/or installed LV modules.
The first time you open a VI in a project, if you have SCC enabled, all the SCC VIs that manage that connection load into memory and then stay there.
The various LV modules (real-time, FPGA, PDA, etc) can also add plug-ins to the project that respond to the loading of VIs.
-
QUOTE (gmart @ Mar 18 2009, 07:20 PM)
XControls (.xctl) are another kind of library that load all their member VIs. I do not know the behavior of StateCharts (.lvsc).In general, no. I was trying to cover my bases since it's possible that a library owns a class and such. In that case, loading a library would load VIs but only due to a class being a member of the library. -
QUOTE (Matthew Zaleski @ Mar 23 2009, 10:00 PM)
No, it isn't. LabVIEW is a compiled assembly language. The engine simply exists to schedule blocks of code to run. There is not a JIT compiler or a script interpreter underlying LabVIEW. Some of the optimizations that C++ can do LV cannot because those optimizations would cross clump boundaries (clump == chunk of nodes that are scheduled to be run as a block before offering the thread a chance to go pick a different clump, possibly on a different VI running in parallel). But you'd be surprised I think just how many of C++ optimizations are possible within LV, and we have a few tricks of our own that C++ can only dream about. When the next version of LV comes out, we'll have some new surprises in that arena.It is still a scripted dataflow language (graphical prettiness notwithstanding).Sometimes we can piggyback on C++. There are some nodes on a VI that are compiled into assembly that calls back into the LV engine -- essentially precompiled chunks that are written in C++ that the VI does a call and return to access. Those are exposed in the runtime engine lvrt.dll.
The PDA and FPGA targets go even further, not relying upon the lvrt.dll at all and generating the entire code structure of the VI hierarchy in their code. We could do the same thing on the desktop, but it is more efficient for VIs to share those large blocks of common code than to have every VI generating the assembly necessary for every operation. But an Add node turns into an "add ax bx" assembly instruction.
-
QUOTE (Ton @ Mar 22 2009, 12:31 PM)
You should be aware that the solution you have hit upon won't detect all types of libraries. There are (currently) five library types: .lvlib, .lvsc, .xctl, .lvclass and the mythical one that some LAVA users believe in. Of these, all but .lvclass can have libraries inside of it (a limitation that would be nice to remove but is not scheduled to be worked on any time soon). You probably want to make this work for all the types, not just .lvlib, which is what testing for "Library" as a type string does, including any future types that LV may introduce. Do I have any idea how to do that? No.
http://lavag.org/old_files/monthly_03_2009/post-5877-1237749800.png' target="_blank">
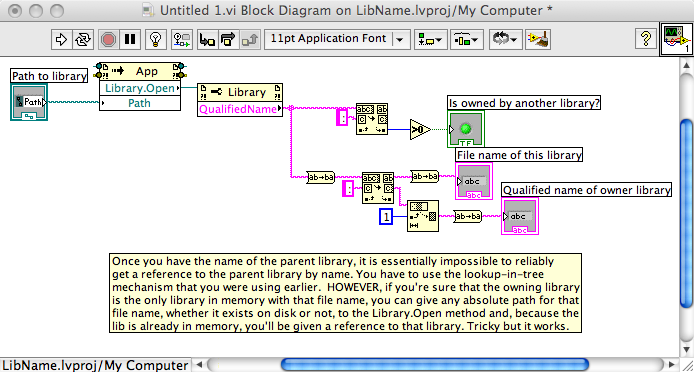
I have no idea why there is no "Open By Name" method.
-
QUOTE (Val Brown @ Mar 21 2009, 03:37 PM)
Ah, the ancient hacker ethos question. I have to admit ... threads like this leave me torn betweenIn other words, you're wanting to hack their security and bypass it. I understand curiosity but, from where I sit, that's not just curiosity, it's tresspass.- cheering on clever applications of software and admiration for those who can make the trick work
- concern for the ethical problems that such hacks raise
- and dread of the bug report when someone does figure these doors out that mean those of us in R&D have to be even more clever next release.
Honestly, I think the best solution is to cleverly figure out the trick and tell no one *except* NI. Under those conditions, you can legitimately claim to be working to make LV better by exploring its weaknesses, and if you happen to learn how certain VIs work along the way -- such as picture to pixmap -- well, that's just a side-effect of your other efforts. Think of it as reward for research.
Of course, under such a model, anyone who did figure a trick out wouldn't post it to the forums. ;-)
- cheering on clever applications of software and admiration for those who can make the trick work
-
QUOTE (neBulus @ Mar 21 2009, 07:37 AM)
Seems like we are breaking some LVOOP rule by making the top level responsible for low level refs etc.I'd counter with the question: who is really the owner of those refs if they have to outlive the state machine? And, actually, it doesn't need to be the top-level that is responsible for those refs. We could have a wrapper around the state machine that is responsible for the refs used by the state machine, and the top-level calls to the wrapper. The encapsulation would then hold.

View cluster FP controls & BD constants as icons
in LabVIEW General
Posted