

Lipko
-
Posts
110 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Lipko
-
-
32 minutes ago, ShaunR said:
Not natively in LabVIEW.
You have to use the IShellwindows interface in windows 10.
Thanks!
Stupid question, I'll look into it of course, but could that C code you linked be dumped in a C node as it is with all the includes and stuff and then hapiness, or it's not that simple? Command line options sublick throws 404... -
Hi all!
Is it possible to get which folders are open in all the File Explorer windows? I'd make a simple folder activity monitor program to monitor my own activity, and monitoring which folders I view would be sufficient enough for this. I know, I should be disciplined with documenting my own work hours per project but I'm simply not.
It only has to work with Windows10.
Thanks for any hints in advance!
-
Pretty much nothing. Every once in a while some used monitors you can get for a fair price. And you can bid for old laptops with hard-drive removed.
I took 1-2 too folders too, I'm worried that we didn't made a delivery note about them...
I guess every junk the company (which employs 500+ white collars, 2000+ blue collars) makes is deliberately placed on top of coral-reefs and into the noses of whales by the management.
-
38 minutes ago, Rolf Kalbermatter said:
That would seem very strange. The Get File Size directly translates to a Windows API call on the underlying file handle. Why that would be so slow is a miracle to me.
Never mind, maybe I used File/directory info.vi.
-
I looked at the code and one question (with low relevancy to the thread): Isn't get file size slow? I remember it being almost as slow as to read the whole file. Or did I do something wrong? Would listening to End Of File error be a better option or it has some caveats?
-
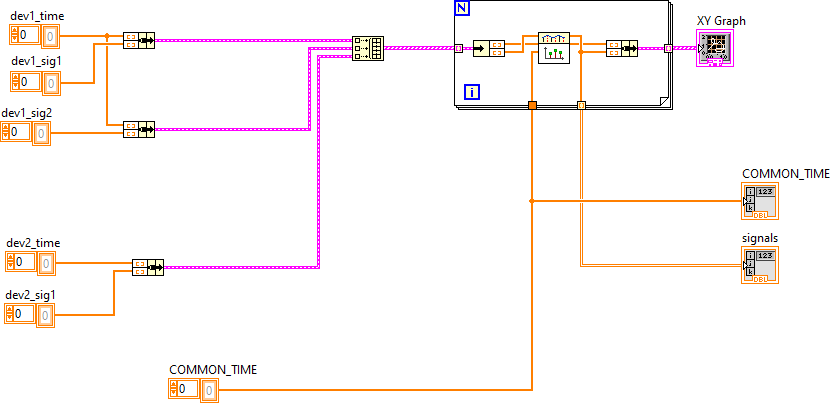
I honestly don't understand how it can work at all, I didn't test your code (for some reason drag-dropping the snippet doesn't work for me). Your signal arrays doesn't match: Y is the original signal while X is the common concatenated and sorted time, so it can even be 0,0,0,0,1,1,1,1,2,2,2,2 and so on. And you fed this to the interpolator, no wonder it might behave strangely depending on the test data. But even if it doesn't look strange, your code will produce wrong results.
Did you try my code? It's not a big change to implement.
-
Forget my previous reply, I was in a rush.
The loop where you use the interpolation is wrong, because of different array lengths. Y and X should be of same size for Interpolate 1D.vi.
The time channels for each device should be fed to the Interpolate 1D.vi, not the concatenated time channel.
You shouldn't build a 2D array from your raw signals anyway (what happens if your different devices are not in sync and array lengths differ?), you should compose it as an array of clusters, and each cluster should be of the time array and the signal array. It will be easier to work with that and easier to put them on graph.I can't comment on your common time channel generator code, I guess you tested it and is okay. Since the time is "commonized" and everything will have the same length, the interpolated signals can be put in a 2D array.

-
How about usig Threshold 1D array instead? Timestamp-by-timestamp linear interpolation.
-
16 minutes ago, Lipko said:
A related thing: I noticed that the "read JPEG file.vi" (the native one) runs in GUI thread. Is it an expected behaviour, is it the same with any file loading in Windows or am i doing something wrong? I narrowed down this GUI thread problem to "read JPEG.vi" (I replaced it with a simple 5 second wait). It is clear that the read causes the loop run in the GUI thread: with jpg read the main GUI freezes at every jpg load, with dummy wait, the main GUI is responsive without any hiccups. The read jpg is burred in subVIs, so it's not that the prioritry or preferred execution system are set up wrong for the subVIs.
Never mind. I've just tried the Decode Image Stream thing, and it doesn1t halt the main GUI, it runs like a charm. But seems to be slower than the native read JPG. I guess that's the prize of a responsive GUI. Thanks again!
-
A related thing: I noticed that the "read JPEG file.vi" (the native one) runs in GUI thread. Is it an expected behaviour, is it the same with any file loading in Windows or am i doing something wrong? I narrowed down this GUI thread problem to "read JPEG.vi" (I replaced it with a simple 5 second wait). It is clear that the read causes the loop run in the GUI thread: with jpg read the main GUI freezes at every jpg load, with dummy wait, the main GUI is responsive without any hiccups. The read jpg is burred in subVIs, so it's not that the prioritry or preferred execution system are set up wrong for the subVIs.
-
14 hours ago, dadreamer said:
You could probably take a look at this: https://forums.ni.com/t5/Machine-Vision/Convert-JPEG-image-in-memory-to-Imaq-Image/m-p/3786705#M51129 For PNGs there are already native PNG Data to LV Image VI and LV Image to PNG Data VI.
Thank you, that's exactly what I was looking for. I'll come back when I'll have time to implement this. If someone is into spagetti.
-
Hi all!
I have an picture organizer application where there is a picture list, pictures can be selected and there is a full resolution preview indicator for the selected picture. Since image sizes are quite large, the picture is loaded from the image file for the full resolution preview generation (the pictures and the indicator are too large to pre-cache). Simply loading the picture in the GUI input thread slows the GUI down significantly.
For this reason, I would place the file loading in a background thread, but I can't find a way to cancel image loading (the user clicked on another picture before the file read is finished), or a workaround this problem.
The best I came up yet is to have a parallel while loop with the input event loop, and load the image if the requested image path is not equal to the image path that's currently loading. I'd poll the paths for that but mixing polling with events give me mixed feelings. At worst case, this method would roughly double the preview generation time if the user clicks around quickly (the first clicked image is fully loading, but another picture should be loaded so that will be loaded AFTER the first finished). This is much better than I have now (the user quicly clicks on pictures then has to sit out the preview "slideshow"). Maybe having two parallel loops would solve the double load time issue, but I have a feeling that this direction is very very fishy (starting a flie read in a parallel thread while a file reading is still happening. Maybe it would slow both image loading times).
Having a way to stop image loading would be the best, I don't know if there's a method or 3rd party library for that. I can imagine the image (jpg for example) could be loaded as raw data in chunks, but how to generate the jpg from that raw data? I'm not even sure jpg file reading is simple as that.
Thanks for any hints in advance!
-
They got a medal for every single bullet they fired?
Anyhoos, I miss the "outsider" or "I only use local variables" rank.
-
Sorry for the stupid choosing of words. I meant just normal for loops. With "post-process" I wanted to emphasize that I would decouple this empty-cell-filling logic from the logic that produces the table. Because you seem to have solved the much harder part of the full algorithm. It would be much harder to fix your existing code that generates the result table than to have another separate section that works on the already produced table.
sigh... It's easier to write and post the code than to describe it.
Place this one where you have your disabled structure now.
In general, I prefer to have a sequence of loops that do one or a few tasks on the data at once than to have one complicated God loop that does everything. The performace loss of more loops is usually not that significant, unless you have huge data (an image for example). Even in that case the performance loss can be accepted for certain uses in favour of code maintainability.
-
It's not clear for me what you are after.
You simply want to fill the emply cells of the report table for presenting the data (second table in your post)? Or you want the data also be inserted automatically into the database you are referring to in your first paragraph?
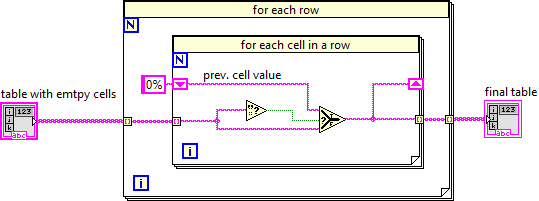
If the first, then fill the cells in a post-process loop (where you have the disabled structure), I think that would be simpler than handling this in the table generator code (the for loop in the middle).
Go through the table row-by-row. Go through the cells in the row. Check if the cell is emplty. If it's emply, fill it with the previous cell value (that you store as a shift register and initialised as "0%"). -
I implemented undo several times in my applications, mainly because I usually do editors.
I did it many ways, usually I check if the data/state changes (after the event structure) and push the data on a FIFO. For most of the time, simply putting all raw data was sufficient. Once (in C win32, not in Labview) I had too much data, so I had to use "command pattern", which means only commands with relevant parameters were pushed on the undo stack and the initial raw data was saved with the undo "object".
It had limited depth (depending on available memory), so the initial datas had to be updated if memory would run out. So the oldest command was performed on the initial data.
Of course in some cases the "parameters" of the commands were bigger data (like paste from clipboard), but it worked pretty well. One caveat: it was quite slow to undo, since all the commands in the command stack had to be sequentially applied on the initial data. If all commands are reverseable without computing errors (which pretty much rules out math operations and delete and such), the stack could re reversely traversed so no slowdown.Back to labview: I can't really exmplain after all these years what's happening, so I'll just post the code of "the most sophisticated" undo I did. It pushes the complete state to the undo stack, because the data was small (sequence editor).
The word "manager" in the name is a bad sign, but here it goes.
Note1: it's implememted in a way that selection changes are not added to the stack, only the last one, or I don't really remember. So you can just ignore the "overwrite" case.
Note2: it's an old code from my newbie times. It fails the single responsibility principle badly, I think both "undo stack" and "stack index" should be action enginified, the outputs besides "output data" is only for optimizing recalculation of data so simply ignore them.EDIT: I've found a later implementation, so changed the vi. The data change check is outside the vi.
-
6 hours ago, ShaunR said:
Then you are already more advanced than the average programmer.
What you will see? Or how long it will take to make it right?
Sub VI, sub VI, sub VI.
Look for reuse. Take a very small section and make it a sub VI (only one click). Clean it up. Nibbling old code from spaghetti to sub VI's has huge benefits. Don't do it all at once. A little clean up goes a long way. Do a sub VI every week or month.
I can guarantee you've rewritten the same behaviors and data manipulations many times in the past; probably even within the same application. As you create the sub VI's you will start to notice some of them are very similar. Look to see if you can make them identical. This is a heuristic way of creating code reuse. Then you can start looking for old code that you have turned into a sub VI that look similar to your current project. Your old code is a test harness for your code snippets. It's been proven to work, right?
Once you have it working correctly in both old and new; fill out the documentation, icon etc if you haven't already and put comments in it. Then stick it in your special toolbox for reuse. You don't need to publish the modified old code but as you gain confidence in your toolkit, you will merge the reuse code into it. If you change the reuse code, run the old software to make sure it still works correctly. This is called Black Box Testing.
Old code is very useful. It's proven code that works. Cleaning it up and sub VI'ing it will benefit your current and future projects too. You will eventually be able to spot reuse code candidates as you create new VI's - the patterns will jump out at you. You will look like you were a master from day one when other people look at your old code. Only you and your source control system will know the truth
.
In my opinion, subVi-ing is only a small thing. There are so many ways something can be solved, and in a long term project that was started as a newbie it can mean a huge mess if you start mixing these ways. SubVI-ing only makes it prettier but the underlying architecture is still going to be a huge mess.
These messy mid-sized projects are very hard to refractor, because it's simply very hard to test throughoutly if you didn't document testing all the way through the project, which you probably haven't if you made such a mess in the first place.
Most of my late cleaning-ups ended up in a buggy software. Sure, those few bugs could be fixed easily but these occured not during testing but during usage.
But I'm no pro, maybe I'm totally wrong. I know that my software testing knowledge is very weak.
-
Yes, I forgot to add this notion to the post. Not a biggie though, it means that's it's not so practical to subVI this function.
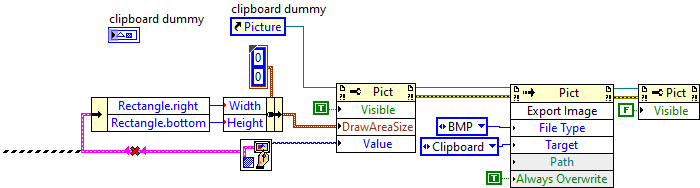
My other concern about such a solution that I'm not sure it works on older platforms if the dummy is off-screen. That's why I placed the dummy on screen and toggled its visibility, but it's not needed nowadays. But I didn't care to test... -
Okay, I did it with the dummy picture method and I found a borderless picture control here:
-
Hi all!
My brain and google skills stopped working and I can't believe there's no simple solution to this.
I have image data (not a displayed image) and I want to copy it to the clipboard. All solutions I found was using getimage or exportimage, which means a dummy indicator and also a small border around the picture (I would use it if I could get rid of that border).
Is there a more sophisticated/simpler method to copy the actual image data/picture? I'm on Windows so it can be platform dependent. Wrapping Clipboard.SetImage would be a solution but maybe some of you have a code sitting around.
Thanks in advance.
-
I usually """solve""" this kind of thing with placing a full-window transparent control over everything and showing it on mouse down and hiding on mouse up event. Fails miserably with multi-pane front panels and have to be extra careful for z-order.
Quick n dirty, the way I do LV.
-
Hmm. I would have answers for (almost) all questions I see in these interview question threads (many "dunno but I'd approach the question like this and that" answers), I even know hooovahh is not really Homer Simpson, but I don't feel any competent for a real Labview job. I can solve problems, made many mid-sized applications (control+daq, data analizers, report generators) that are team uses on a daily basis, I struggled with many architectures, fixed errors in 3rd party APIs, I know error handling is not simply connecting serially every crap with an error terminal to make a huge yellow snake (a thing that I see even in APIs of serious equipment from respected companies). Sounds promising. Yet my code and especially the architectures get so f... spagetti after a while, you'd get brain aneurysm just by looking at.
These questions are only good for first stage screening. If I were hiring, I would definitely go for a test Labview project in some way.
-
As long as there will be any kind of support and it will run on my machine and executables will be buildable with it and runtime engines will run properly, it will be my primary application/tool builder environment. The ability to qickly throw together GUI intensive (and not so intensive) specialized applications is still unmatched for me (though I admit I haven't looked into recent tools).
The intuitive parallellism is also good, but to be honest there were only a few occasions where I did actually need it (control with DAQ).
Okay, my career is not based on Labview at all.
-
4 hours ago, dadreamer said:
Take a look at https://github.com/mefistotelis/pylabview
You will need 3rd Python and Pillow package:
After that you proceed as follows:
- Unpack the .exe into a separate directory (7-Zip unarchiver works fine for me).
- Take \.rsrc\RCDATA\2 file and put it near readRSRC.py.
- Run .\readRSRC.py -x -i ./2 in the command shell.
- Unpack 2_LVzp.bin to get your VIs.
You may also find this thread interesting to read: EXE back to buildable project
Thank you!
I don't have experience with python and I'm stuck at point 3. I have Anaconda, I run the windows command prompt and started python (I see the >>>), I navigated to the plylabview folder (os.chdir), I think I have pillow (typed pip3 install to anaconda promt and it said something about I arelady have it), but no matter how I try to type in .\readRSRC.py -x -i ./2, I get inalid systax errors.
Tried .\readRSRC.py -x -i ./2 in the anaconda promt too.
") .
.
Polling the Currently Open Folder in Explorer
in LabVIEW General
Posted
No, but I'm not talking about booking Labview projects' workhours, just projects in general which are organized simply with folders.