PaulL
-
Posts
544 -
Joined
-
Last visited
-
Days Won
17
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by PaulL
-

A class questions about my system
PaulL replied to Maxwell_Peng's topic in Object-Oriented Programming
1) LabVIEW does have some sort of native object reference support. I (somewhat controversially) don't recommend that you use that, however, since a) it is neither clean nor pretty, and b) the better thing to do in most or all cases is to clean up the design. 2) Take a closer look at your design. I think it would be preferable if the Parameter Class didn't know about the instrument at all, but it is hard to tell that for sure from your description. (I can actually see why you might have such a relationship, but without knowing more details about the system it is impossible to offer a recommendation here.) Again, I recommend creating a UML model of your system, both to clarify the issues in your mind, and to facilitate sharing your vision with your interlocutors. It is essential to understand the relationships between the different classes here. There may be a more appropriate way to relate these items. Paul OK, you wrote that that "different parameter class may use the same instrument and I think the instrument is a static part of the test system." So, why not make a test system class that has an instrument as one of its attributes, and a collection of parameter classes (that do not have references to the instrument!) as another attribute? The answer will get slightly more complicated if, as I suspect is the case, multiple instruments may be present within an application. I don't think this will be difficult to accommodate, though. (As a first approach, for instance, you can have a an array of clusters, where each cluster contains an Enum indicating the instrument, and a set of measurement parameters. Or something like that.) Let's establish what you need, though, first. -
As ShaunR and rolfk have already indicated, the architectural questions your requirements derive will require significant understanding to satisfy. In particular, you will need to understand state machines and effective network communication communications. Part of a good solution may include a publish-subscribe communications paradigm. (That's what I would use, but I build systems like this all the time.) You may want to take a close look at which requirements you actually need to achieve. (Which external interfaces do you really need to support?) You will likely need to implement this in phases, designing in such a way as to support new features in the future.
-
A class questions about my system
PaulL replied to Maxwell_Peng's topic in Object-Oriented Programming
My first piece of advice is to create a UML model of your system. This will help you and others understand it better. Second, it's not clear to me what your "parameter classes" actually are. It sounds to me like they are actually tests, but also include test configurations. Perhaps you can clarify. -
NI Support said this was a known issue and will be addressed in a future version. CAR 451107.
- 8 replies
-
- 1
-

-
- source control
- git
- (and 3 more)
-
OK, thanks! I did submit open a support case yesterday, too.
-
Note: In post #1 where I have "project" I should have written "library". In this specific example I only used the library interface, although the results are the same with the project interface. Another note: LabVIEW wants to save all the accessor methods, even those that deal with the other attribute of the class. On the other hand, the *almost* virtual methods that are also members of the class have object instances (in and out control and indicator), but LabVIEW does not feel the need to save these. This may show the problem is with the class private data bundle/unbundle nodes.
-
Yes Yes, I have seen that thread. Yes, there is a nebulous promise that NI is working on something, but whether or not it will address this specific issue is unknowable from that thread. I understand the font issue as a cause, but that clearly is not the cause in the problem I have presented.
-
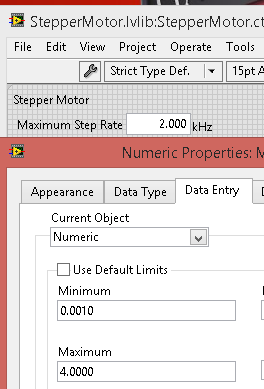
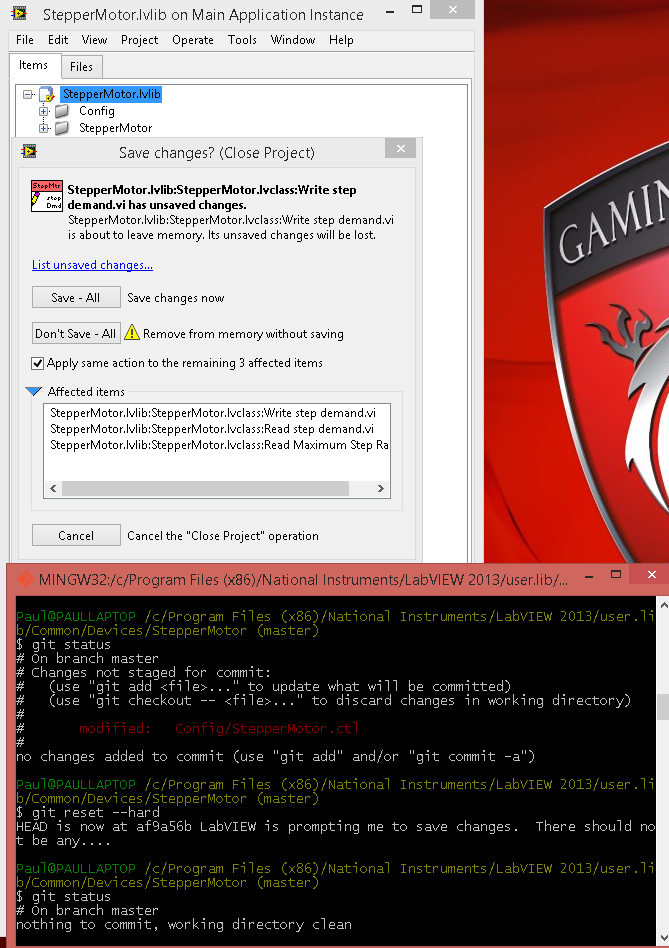
Here is the set-up: I have a component project library (StepperMotor.lvlib) that I have moved to the userlib in order to facilitate reuse over multiple projects. Within the library I have 1) a strict typedef (StepperMotor.ctl) cluster that contains a numeric control for expressing the maximum output step rate. 2) the StepperMotor.lvclass, an abstract class that contains effectively virtual methods (they do nothing but wire inputs to outputs) and LabVIEW-generated accessor methods for the two items in the class private data. This is LabVIEW 2013 SP1 on Windows 8.1. OK, so I start with everything clean (git status reports clean, LabVIEW opens and closes the library without prompting for changes). 1) Then I open the StepperMotor.ctl directly from Windows Explorer (hence not opening the library), change the range of the numeric from 2 kHz to 4 kHz, and save it. 2) Then I open the library, make no further changes, and attempt to close the library. LabVIEW correctly prompts me to save changes. I opt to close the project without saving changes, however. 3) Next I discard the change to StepperMotor.ctl using git. (I have been using Discard in SourceTree, or a git reset --hard command.) Then git status returns a clean status. 4) I open the project and attempt to close it. Since I have reverted all changes, LabVIEW does not prompt to save changes. So far, so good. This is expected behavior. Now, I repeat the steps, except that in step 1) I open the library first, open the typedef control from the project, make the same change, save the control (without applying the changes), and close the project (without saving). 2) is the same as above (OK). 3) is the same as above. Again, git status shows me everything is clean. 4) I perform the same action as above, but this time LabVIEW prompts me to save all the accessor methods on the class, citing a changed typedef (even though if I open the typedef the range is indeed back to its original value). This is unexpected behavior. Worse yet, even if I perform a git reset --hard and verify with a git status that everything is clean, if I open and immediately attempt to close the project, LabVIEW still prompts to save, citing "Type Definition modified". This is indeed problematic. (Further note: If I let LabVIEW save the changes, git status still shows clean, and LabVIEW opens and closes the project without prompts.)

-
Configuring Git to work with LVCompare and LVMerge
PaulL replied to PaulL's topic in Source Code Control
Atlassian support and Git support have both pointed out that local and remote are consistent with the definition in the manual for difftool http://git-scm.com/docs/git-difftool.html. So, what we have is, in the global .gitconfig file: [diff] tool = "sourcetree" [difftool "sourcetree"] cmd = ''C:/Users/Paul/AppData/Local/Programs/Git/bin/_LVCompareWrapper.sh'' "$REMOTE" "$LOCAL" The associated wrapper script contents are: #!/bin/bash # Method to determine absolute path # The -W parameter on the pwd command is necessary to return the Windows version of the path. # Not using the -W parameter will result in a conversion of temp directory to a 'tmp' path meaningful only in the Linux # environment. # Piping the result through tr '/' '' translates the forward slashes to backslashes. # Windows understands forward slashes, but LVCompare.exe does not. abspath () { ( DIR=$(dirname "$1") FN=$(basename "$1") cd "$DIR" printf "%s/%s" "$(pwd -W)" "$FN" | tr '/' '' ) } lvcompare="C:Program Files (x86)National InstrumentsSharedLabVIEW CompareLVCompare.exe" local=$(abspath "$1") -
I guess I'm a little puzzled why some people see this and some people don't. What is different? I use strict typedefs quite frequently. Quite often I place instances in class private data and constants fromt the typedefs in class methods. Note that the .ctl files for the typedefs are in separate .lvlib files. When I need to change a typedef I open it within the project, make modifications, apply the changes, and save. I avoid things like renaming an item and inserting another item in the same step, which could obviously cause problems. As long as I am careful in this respect, I don't (or haven't yet) encountered major issues. Maybe I've just been lucky. I'm puzzled what the difference is.
-
Configuring Git to work with LVCompare and LVMerge
PaulL replied to PaulL's topic in Source Code Control
A further note on the parameter reversal: Note that If I switch the order of the parameters the results are flipped (but still mismatched). I actually now think this is a problem on the Git side, since I see the issue if I call git difftool directly. It's hard to believe, though, since the distinction between local and remote is quite essential for Git to work (although maybe not so much for difftool). Still, when I run git difftool, clearly the local parameter returns the remote path, and vice versa. Quite puzzling indeed! Paul -
Configuring Git to work with LVCompare and LVMerge
PaulL replied to PaulL's topic in Source Code Control
Success! OK, it seems this is a problem with MSys or MSysGit mangling the Windows paths. Our local Git guru, with background input from Git support and my tests, helped me write a shell script to do two things: 1) Return the Windows absolute paths. 2) Convert the forward slashes to back slashes. Here are the details on _LVCompareWrapper.sh: File location: On my machine, this file is in the C:UsersPaulAppDataLocalProgramsGitbin directory. The actual filename does not matter, as long as the configuration item in the .gitconfig file points to it. The file contents are presently: #!/bin/bash # Method to determine absolute path # The -W parameter on the pwd command is necessary to return the Windows version of the path. # Not using the -W parameter will result in a conversion of temp directory to a 'tmp' path meaningful only in the Linux # environment. # Piping the result through tr '/' '' translates the forward slashes to backslashes. # Windows understands forward slashes, but LVCompare.exe does not. abspath () { ( DIR=$(dirname "$1") FN=$(basename "$1") cd "$DIR" printf "%s/%s" "$(pwd -W)" "$FN" | tr '/' '' ) } lvcompare="C:Program Files (x86)National InstrumentsSharedLabVIEW CompareLVCompare.exe" local=$(abspath "$1") remote=$(abspath "$2") exec "$lvcompare" -nobdpos -nofppos "$local" "$remote" # For the options, see http://zone.ni.com/reference/en-XX/help/371361H-01/lvhowto/configlvcomp_thirdparty/. Of course we need to modify the global .gitconfig file, too. Here are the details: This is the global .gitconfig file. On my machine this resides in the C:UsersPaul directory. The relevant part of the file (set up to work with SourceTree, but it is possible to use another tool or to use the wrapper tool via the git difftool command) presently is: [diff] tool = "sourcetree" [difftool "sourcetree"] cmd = ''C:/Users/Paul/AppData/Local/Programs/Git/bin/_LVCompareWrapper.sh'' "$REMOTE" "$LOCAL" # Note that the parameters are actually passed in reverse order to the wrapper. The parameter reversal does seem to me to be a bug in SourceTree. Paul -
Configuring Git to work with LVCompare and LVMerge
PaulL replied to PaulL's topic in Source Code Control
Greg, I would indeed by interested in how you put together your batch file. I would indeed enjoy discussing these and other issues with you and other interested parties at some event, perhaps NI Week or a virtual event. -
Configuring Git to work with LVCompare and LVMerge
PaulL replied to PaulL's topic in Source Code Control
Greg, I'm not sure I will be much help on this. I think you are actually a little ahead of me a the moment on GitFlow workflows. That is the direction in which I want to go, but I haven't used that in an actual project yet. I haven't used the Git Flow button in SourceTree. I understand what you did, but I'm not following why you didn't merge develop into feature. You may be onto something (it's the key point!), but I'm not following. __ By the way, on the difftool issue in this thread, I have verified that I can call LVCompare.exe with filepath parameters from the Windows command prompt (not connected to any kind of version control) successfully. With Git I can set up the .gitconfig file so that calling 'difftool' does summon LVCompare.exe, but the remote path Git passes to LVCompare is malformed (the path starts out C:/). (That is a backslash followed by a forward slash.) I started a discussion on Atlassian's forum (https://answers.atlassian.com/questions/254737/sourcetree-external-diff-path-issue-on-windows?page=1#comment-263644) and opened a support case with Atlassian (https://support.atlassian.com/servicedesk/customer/stsp/problem-report-956), but I have since reproduced the behavior using Git directly (difftool) so I started a case with Git directly. (I'm not sure this will go anywhere, since I have yet to receive even an acknowledgment to the issue request, which I submitted through e-mail. I had to send the e-mail three times. The first time it was automatically rejected because I was greylisted because they hadn't received an e-mail from me before, and the second time it was rejected because it supposedly had HTML in it--maybe in the headers? I then sent a plain text version, and nothing happened, so I am good? This is not a great system to make a great product.) At this point I'm pretty sure it's a Git bug (and a bad one!). I think it is possible to work around this using a batch file, but I'd rather fix the bug. Paul -
So... how is your project going?
-
Library & Class Naming Convention Advice
PaulL replied to MartinMcD's topic in Application Design & Architecture
The naming policy we have adopted is as follows: We use UpperCamelCase for class and library names, as well as controls. We use lowerCamelCase for attributes and methods. We do not allow spaces. [The accessor methods LabVIEW autogenerates follow different rules, and we allow that. (I'm not sure if this is customizable or not.) Also, we allow exceptions for cluster elements that appear on user interfaces. These have Friendly Names With Spaces. (It is possible to have a caption this way and have lables that follow our other rules, but this is more work than it is worth.] -
OK, the other advice I have for someone moving forward designing systems using objects (not because objects are bad but because there are object-oriented design tools that make this straightforward) is to design with the goal of eliminating inappropriate code dependencies in mind. (This is part of the high cohesion and loose coupling concept, which encapsulation helps accomplish.) Skillful application of the UML, with some deep thinking in the process, makes this a lot easier! Paul
-
I recommend you check out the appendices in the paper linked in this thread: http://lavag.org/topic/14213-strategy-pattern-example/?hl=%2Bstrategy+%2Bpattern. One way to see the interdependencies is to create an empty project and add, say, a class to it, and see what comes along with it. Look at the tag-alongs and think about whether the linking is logically necessary or not. Paul
-
Mike, From what you say I would venture that the problem is that there are very many source code interdependencies, which will result in lengthier load times. If that is true, packed project libraries (which I generally don't recommend anyway) will not help. The appropriate solution is to use interfaces to minimize source code interdependencies. (I explain how to create an interface--or something very much like one--in several of my papers linked in LAVA threads. Basically you will need to add a layer above your existing abstract classes, and this new layer will have abstract methods as well. There are other steps to take to minimize interdependencies, but this is the main one.) I do not buy the argument that greater hierarchy depth alone dramatically increases load time. For instance, I have a class hierarchy 6 layers deep in my current project, which is not at all atypical in this part of my applications, and load times are quite normal. Paul
-
First, I looked at your other thread later yesterday and saw you posted a draft of a state machine there. I had a question on that: what are the triggers for the transitions between states? On the Actor Framework (AF): My experience with the Actor Framework is limited; I have worked through Actor Framework examples, but I don't use it, largely because we previously developed our own template that has many, many more features, does what we want it to do (e.g., works with multiple components distributed over a network), and, in my opinion, has a more sound and user-friendly design. What I like about the Actor Framework (as I have seen it): The broad concepts of actors and Model-View-Controller are the way to go. (Our own approach uses M-V-C and components, which are identical with actors, although we use them more sparingly--see below.) Providing a solid architectural baseline for users is a worthy goal, and the Actor Framework is a big step in the right direction. What I consider caveats are: The Actor Framework makes more or less everything, even within a component, an actor. This is one of the factors that leads to what I consider an overuse of by-reference native LabVIEW objects, which, in my opinion, have an ugly API and the overuse of which tends to obfuscate the workings of the code. [An application programmer should not be dealing with Data Value References (DVRs) and In Place Element structures (IPEs). Our template has none of these, so that the developer only focuses on the details of the particular application. Moreover, a subVI call is easier to follow and preferable in many cases.] The Actor Framework does not use appropriate interfaces, so that code dependencies are hopelessly tangled. These make the AF more difficult to use than it should be. Nonetheless, the broadest strokes of the design are sound and worth understanding, whether or not one uses the AF itself. In the end the AF does offer a ready-made path to a working application with a reasonably good architecture.
-
Configuring Git to work with LVCompare and LVMerge
PaulL replied to PaulL's topic in Source Code Control
As far as resolving the issue on this thread goes, I did get further in that I was able to get LVCompare to start (not difficult once I figured it out), but I encountered a problem with malformed paths passed as parameters to LVCompare. I documented this in a discussion on Atlassian Answers (https://answers.atlassian.com/questions/254737/sourcetree-external-diff-path-issue-on-windows). When no one commented on that thread, I started a support case with Atlassian. Much to their credit, Atlassian's support responded promptly. At the support person's request, I verified that I can get LVCompare to work with test VIs in a text project. I'll update this thread once I know more.... After I started this thread I did discover for myself the {Open 'Before'} and {Open 'After'} buttons in SourceTree, to which Greg refers in comment #2 above. These are quick and easy to use to open VIs to compare (although we don't have the cool features that automatically highlight the differences). It has been helpful in my tests so far. 1) I have used LabVIEW's diff capability on occasion in the past with TortoiseSVN. Within limits (there is the problem Greg noted above if the hierarchy has changed) the results are good, although the process could take some time to complete. 2) I've done merges to see what happens, but in the end on the rare occasions where I really wanted to merge code files I ended up doing this manually rather than configure and trust the merge tool. 3) The merge tool has a problem in that the number of required inputs isn't suitable for all use cases. On the other hand, both tools do a reasonable job (and are really pretty cool) if you go through the trouble of setting them up correctly and going through the pain (unavoidable?) of patiently using them. In my previous project we avoided the issue by maintaining a single development trunk (no branches whatsoever) and carefully managing development so merges were unnecessary. That worked well for that project, but it isn't appropriate for my new project, where branches will, I expect, be common, due to the nature of the product releases, the version control system (Git, which is a Distributed Version Control System), and the process we plan to use (GitFlow Workflow looks to me like the way to go). I'm trying to ensure we will be able to do merges when we need them, which I expect we will need to do regularly (even if we just merge branches, manually resolving any differences in individual files). I actually like Git and the DVCS approach for the most part. One big difference is that in Subversion we had all the files ultimately in one repository. That doesn't fit the Git paradigm, but it does beg the question of how to maintain the path (and version) relationships between components. Right now I think we will handle this by convention or with an external tool (Fusion, Stash, if it does this, or maybe VIPM can help). -
OK, well, then you will need an independent (orthogonal) state machine for each cylinder. I've done that with a fairly simple variation on an implementation of the State Pattern. I think it is not incredibly difficult, but you will need to choose the design accordingly. I would start by making a state machine diagram (OK, I would really start by assembling a use case and a set of requirements, but let's presume you have those and are ready to do some design) to describe how the system must behave. Creating a model of the behavior won't guarantee that you can implement it, but describing the desired behavior correctly is, in my mind, a necessary prerequisite to writing the code, whichever architecture you choose, and the model will likely drive certain architectural decisions. It will also be helpful to communicate with others if you want to bounce some ideas off them. (Hint: I recommend, for a number of reasons, the use of UML for this purpose, but the necessary aspect is to be able to model or describe accurately and effectively the states of the system.)
-
OK, I looked at your files. The most obvious thing to address is that Move and Position should be in a separate hierarchy from Cylinder. You are moving in the broad direction of the Command Pattern, which is a great thing to use for this purpose. I recommend that you check out the Command Pattern in http://www.amazon.com/Design-Patterns-Elements-Reusable-Object-Oriented-ebook/dp/B000SEIBB8/ref=sr_1_1?s=books&ie=UTF8&qid=1390927051&sr=1-1&keywords=design+patterns or http://www.amazon.com/Head-First-Design-Patterns-Freeman-ebook/dp/B00AA36RZY/ref=sr_1_2?s=books&ie=UTF8&qid=1390927051&sr=1-2&keywords=design+patterns, or read one of my papers. (Maybe you won't have time to comprehend the pattern fully, but I think understanding the basic concept will help, if you want to architect this well.) (Note: a command object can store a context value that defines the target.) There is a long way to go yet before having a full application (there is a lot to making such a thing), but you are generally moving in the right direction, it seems to me. How complicated is the final application going to be, and how much time do you have to complete it?
-
Yes, an array is a good idea. Are the all the cylinders in the same state at the same time? If so, then the array will only need one state machine. If not, each cylinder will have to store its own state. There are several good possibilities for executing a sequence of moves. My preferred approach is to define states so that each sequence step defines a state. I will see if I can download your zip file.
-
event structure into a state machine problem
PaulL replied to pitermann's topic in Application Design & Architecture
OK, I think the view and the controller should operate correctly independently of one another. This means the view should enable and disable buttons properly, but it also means the controller should be able to handle any command at any time (discarding inappropriate commands and perhaps returning an exception). The "Idle" state approach is not, in my opinion, the best approach to achieve this. If you do stick to the approach you have chosen, you should be able to use the debugging tools to follow the execution to reveal where the controller is hanging.