PaulL
-
Posts
544 -
Joined
-
Last visited
-
Days Won
17
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by PaulL
-
We are completing the last minor systems on the Discovery Channel Telescope, and I am looking forward to the next venture, wherever it will be. My ideal next move would be to design and implement an even larger, more complex system. (The control component template I developed here and, more importantly, the concepts therein are readily scalable and directly applicable to pretty much any type of control system.) I think the DCT software system is an amazingly powerful, robust, and elegant software system! I am looking forward to building the next incredible system! res Oct 2012.docx
-

Storing Initialisation Data in a Strict Typedef
PaulL replied to Zyl's topic in Application Design & Architecture
Well, I admit our situation is relatively simple since we don't widely distribute our software. I would still use the same approach even if we did, however, for the following reasons: 1) Users interact with our configuration files via a configuration editor so they are really not likely to delete the files. 2) If a user does delete the files the user can restore them simply by rerunning the installer. (Of course, this means the user has to have the ability--permissions and skills--to run the installer, but that seems to be a reasonable expectation given that it is common practice in the computing world today. If as a user I mess up an installation of an application I expect to repair the installation or reinstall the application.) We would require the same procedure if a user deleted the executable file. [Even if I had a reason not to give the user the installer I would certainly include the configuration files in the deliverable as data files to store in a safe place in the event of an emergency. I'm not putting anything secret in the configuration files.] 3) I don't want to have to edit my source code every time the default values change. -
Storing Initialisation Data in a Strict Typedef
PaulL replied to Zyl's topic in Application Design & Architecture
We also use XML files for storing configuration. I think this is a great solution. I do not think it is a good idea to use the default values of the typedef to serve as default configuration values, since this is very unreliable and difficult to mainintain. In particular, it means that the developer has to edit the source code (and rebuild the application) to change the default values. Moreover, one has to have access to the source code even to see what the default values are (or maybe you run the editor and view them there?). Our approach is instead to include an additional file for each configuration (e.g., MyConfigurationDefault.xml pairs with MyConfiguration.xml). Associated with the default files we include "Restore Page Defaults" and "Restore All Defaults" buttons in the configuration editor. (We simply read from the Default files as appropriate.) This has worked quite well. (Note that if someone wanted just to know what the default values were they could also just open the XML file; in practice we just read them in the configuration editor.) If a user were to blow away the entire ConfigurationFiles directory (this hasn't happened to us) reinstalling the configuration files (which has its own version so that reinstalling the configuration does not necessarily reinstall the rest of the application) restores the original files. In short, I advocate: 1) Supporting recall of default configuration values in your configuration editor. 2) Storing default values in files in the same fashion you store the user-edited values. [What this means in practice is that to set the default values we open the configuration editor, set the values to be the defaults we want using the editor, save the configuration, and then copy the resulting files as default files. Done.] -
Organizing your projects on disk
PaulL replied to John Lokanis's topic in Development Environment (IDE)
Yes, on everything up to the user.lib. I didn't used to put things in the user.lib, but then we decided to move calling code up or down a directory to group items we decided to group in a subsystem (hence changing the relative path to the common code) and I realized why it was maybe not the best thing that I hadn't taken advantage of a symbolic directory. So, yes, we put our common code in user.lib now. (We actually have a Common folder under user.lib.) Something else may work better for you. On dependencies: We prefer having only the elements we need to edit in the particular context directly in the project. Other linked items (common code, interfacing code belonging to other contexts) we like to have in the dependencies precisely because they are out of sight unless we need to go look for them. (In some projects we have a thin layer we are editing but there is a lot of linked code in the dependencies that we certainly don't need to edit, or even look at, in that context.) As I said, this approach is helpful for our way of working. There are other development processes, to be sure. -
Organizing your projects on disk
PaulL replied to John Lokanis's topic in Development Environment (IDE)
Yes. We actually have this exact situation, and we set it like this: ..\\user.lib\Common\XML, and under this we have a folder for each class (e.g, XMLGenerator, XMLParser) and one for Typedefs. (We usually put Typedefs in a folder--and often a library--at the appropriate level.) Edit: Well, I addressed where we put them on disk. I reread your question, and you actually asked about in the project. For XML libraries these would end up in the dependencies in most projects. (We only generally put what is specific to the project in the project directly. Everything else is in the dependencies. This is quite helpful when we are trying to understand a project.) Hmm... One more thing that I think is important. We set up our directories on our data drive like this ..\\trunk\\src (also bld, errors, platform, test)\Components (also Tools and some others)\<Subsystem>\<Component>. The source for each component is thus is in its own directory, which is essential for the way we work. -
Organizing your projects on disk
PaulL replied to John Lokanis's topic in Development Environment (IDE)
I just discussed this with my teammate and we noted some rules we follow. 1) (Really a must): Each class should be in its own directory. (This means LabVIEW will go automatically to the correct directory when you want to save a method for the class.) 2) We use virtual folders in a class to distinguish between scope (Public, Private, Protected; we don't use Community) and purpose (AccessorMethods) but locate all methods directly under the class directory on disk. I don't see any reason to have subfolders under a class on disk. 3) We group closely related items (often these correspond to a UML package) in a virtual folder in a LabVIEW project and a folder on disk. This is especially true if we add the classes to a project library (.lvlib). 4) We do not, however, make the disk folder hierarchy match the class inheritance hierarchy. There is no reason to do this. Moreover, if we change the inheritance structure (e.g., insert a layer, or just remap the inheritance relationships) we do not want to have to move directories on disk (which is a bit more annoying if we have already checked files into source code control). 5) We find project libraries useful (for instance) when we want to copy a set of code and reuse it, but just with a new namespace. There are differing opinions in LAVA threads on putting classes in project libraries, though. 6) We use a template for our components now. We put code we need to customize or add to in the project and in a template directory. Common code is generally in the dependencies and in folders in the user.lib. (It took me a while to learn to realize the advantages of locating items in the user.lib.) 7) Something we have found useful is to put different applications (or other pieces) within a component (for control components, for instance the view may or may not run when the controller is running; having separate applications for the view and controller is, of course, necessary for cRIO applications) into separate projects. This helps us to concentrate on one piece at a time, and means that we can build the different pieces separately. For each component we have a top-level project that includes the subprojects, just for convenience. 8) On that note, I advocate using interfaces appropriately to separate source code dependencies effectively. This is especially true since different projects may use sections of the code in different ways. Nonetheless, our disk locations generally do match the hierarchies in the project on the macro level, and we have found that to be a really good idea. Generally the level on which we apply groupings matches a package (think diagram) in UML. (On that note, I will put in a plug for modeling. I think modeling is essential to end up with an optimal design.) -
Coordinating Actions Across a Network
PaulL replied to John Lokanis's topic in Application Design & Architecture
I think your concern over a single point of failure is certainly valid. I'm curious, though, why it is that "fail-over will not be a possibility." Why not (if you don't mind sharing)? -
Coordinating Actions Across a Network
PaulL replied to John Lokanis's topic in Application Design & Architecture
We do something very much like this with independent state-based components. (We don't use the Rendezvous construct.) Components interact only by exchangine data via shared variables. Note the shared variable engine (SVE) manages all connections. Note also that in our paradigm a command is just a type of data. If you want to pursue this line of thought read about the Observer Pattern (Publish-Subscribe). The SVE implements the push version of this. Also read about component-oriented designs. -
Thinking about this a little more: A component really only "talks to" the shared variable engine, never another component. Which components send and receive which messages (the communications map) is part of our system design.
-
Well, we have a completely working system and we are fully confident in the architecture. (We build our components on a completely functional template we developed.) Yes, each component dynamically registers for events. This effectively means each component has a list of shared variables to which it wants to subscribe and calls a method to establish subscription. The shared variable engine really handles all the connections. I think our component interactions are a lot simpler than that (because of very careful design upfront). Let me see if I can explain. A component controller subscribes to certain inputs to which it responds (we call this SubData), and it publishes other data (PubData). When we develop a component most SubData comes from the user interface for that component, but once in the system those messages can come from its parent or even a cousin. There is a sense of hierarchy in the system design (not the messaging per se) in that, for instance, the top-level component can send an enable signal to its immediate children, who on their transition to enabled send an enable signal to their children, and so on, so that we have a cascade effect. We very carefully designed our system so that components only need to know what they absolutely need to know about each other. The messaging as we have it is quite straightforward once we have identified the signals each component needs to send and receive.
-
Part 2, I guess: There is one shared variable event per event structure. When we send commands (properly speaking) via user events within a component (or between components via shared variable events--see below), yes, the type is the top-level command class, so we also only have one event here, too. "In my applications a component owns and defines the request messages it will honor and the status messages it will provide." This is essentially our approach as well. We define external interfaces through data sent via shared variables in one of two approaches: 1) Not objects: a) primitives, b) typedefs (Enums, clusters). We define the external interface typedefs in a library for that component (and those are the only items in the library). That means at most another component will have this library in its dependencies. (We convert the values to command objects internally.) 2) Command objects: For certain complex external interfaces have command objects (flattened) on the shared variables. In these instances, interfacing components have the library of interface commands in their dependencies. So, yes, generally each component defines its own interfaces. It is easy for other LabVIEW components to use these interfaces (via libraries and via aliased shared variables). For nonLabVIEW components we convert the same data to XML (not always easy, as we have discussed on other threads). I agree with Daklu that the controller should not assume that the user interface will not send a command that is valid at that moment. There is no way to ensure that under all circumstances. As Daklu also says, a true state machine processes triggers that are valid for that state. (The default behavior for any trigger on the highest-level state is to do nothing.) We do use a combination of invisibility (often for a subpanel) and button disabling on views. The views update the display based on the state of the controller.
-
I will attempt to answer your question, but I think I will need a little clarification from you. 1) All inputs to a component (e.g., a subsystem) in our system go through the same processing pipeline, as you suggest. 2) Stated another way, all state machines are reactive systems (vs. transformational systems--think of data processing) , in that they execute behavior based on events. 3) I consider all events to be inputs of some data (although a simple command may just be the command name, or type). 4) Some of that data I think of as commands. In other words, commands are a subtype of data. (Some are obviously commands, like "Enable", some are obviously status, like "state=Enabled", some are maybe somewhere in between, like "positionSetpointsToWhichYouWillAddCorrections." I have changed the names here to protect the innocent. Lol.) 5) Yes, a higher-level component can send commands (in the strictest sense) to its children (i.e., it can can control/coordinate its children). Children, on the other hand, are unaware of their parents. 6) All communication is publish-subscribe. I'm confused by the last part of your question: "I've read stuff that speaks highly of pure reactive systems that only use status messages. Thinking about all those direct connections makes me shudder and I'm curious what your experience is." I'm not sure what you mean by "direct connections" here. In particular, our components publish status values, so that they are available as needed by subscribers. (Of course, we are careful about how we design the system so that components have exactly the data they need to do what they need to do.)
-
I thought I should clarify: I liked hooovahh's post above not because of the QSM comment but because I think he is on to something here (and above) when talking about user events. The components in our system use strictly events, no queues. This isn't because I think there is anything bad about queues--I don't think that at all--but because we were already relying on events for items on the view (button clicks and so on) and for networked shared variable events. I found it easier to do everything in terms of events (creating user events when necessary) than to support another data transport mechanism. (Also, I am generally more familiar with events.) Our controllers never repeatedly poll (although we do pull preexisting values of shared variables on a few transitions when we haven't previously monitored the value). We also have a very few instances where in practice for convenience our view code polls shared variable values on a timeout event, but almost all our views are entirely event-driven. Again, I don't have anything against queues. For me it is just easier to limit the number of message transport mechanisms; events have met our needs quite well, and I think the event concept is relatively easy to understand. I haven't used a queue in production code in years. I'm not disparaging the use of queues in any way (and if you have an application--probably rare, though--that absolutely requires reordering messages in transport, then you probably need a queue); I am saying it is entirely possible and reasonable to build an event-driven system and ignore queues altogether.
-
No. I think (it's been a while since I looked at that thread in detail) that is something Mikael did to make it possible for a single class to implement multiple interfaces. We think that is too complicated for everyday use so we just use simple inheritance in the relationship between these. (Note that if every interface had a link to a concrete class that would be quite undesirable, since we would lose our source code isolation.) Let me give you some examples of how we use interfaces. 1) State Pattern: State as Interface. We have a Context that invokes methods on State. State is an interface and simply defines the possible operations to perform. Context only has a reference to (i.e., "knows about" State). The concrete State classes that generalize (inherit from) State implement behaviors for the specific states. The developer of the Context does not need to know anything about those classes. We can add, remove, modify, completely restructure, or even swap different sets of concrete state classes without ever touching the Context. We have found that, among other things, it makes the overall application much easier to program. (It makes it a lot easier to focus on one thing at a time.) 2) Factory Method Pattern: creating State objects. In our approach to the State Pattern each method on a State class can determine what the next state is. (I think this is the most common approach. The GoF Designs Pattern books discusses two ways of doing this, but the distinction is not essential for this conversation.) We store the new state as an Enum and then use Factory Method Pattern to create the actual state object dynamically when we need it. Consequently the state objects do not have references to one another, which we found made a big difference when working in LabVIEW, especially on Real-Time.
-
That's a good thread. We use a conceptually and practically simpler approach to interfaces. The tradeoff for the simplicity and clarity is that our approach does not allow a class to implement multiple interfaces. To date we have found the simplicity to be worthwhile. The thread here http://lavag.org/topic/14213-strategy-pattern-example/page__hl__strategy__fromsearch__1 has a link to a document in which we discuss abstract classes and interfaces, what those mean, how we implement them, reasons to use them, and some use cases. (See especially the appendix.) For more real-world examples you might see our slides from our NI Week 2012 presentation, "TS 8237 State Pattern Implementation for Scalable Control Systems." The starting concepts, as I see them, are: Abstract Class: "A class that can be used only as a superclass of some other class; no objects of an abstract class may be created except as instances of a subclass.“Larman, C., [Applying UML and Patterns: An Introduction to Object-Oriented Analysis and Design and Iterative Development], Pearson, Upper Saddle River, 689 (2005). Pure Virtual Method (Abstract Method): A method that has no implementation. This means that if we have a pure virtual method in a parent class, every child must implement that method. Budd, T. [An Introduction to Object-Oriented Programming, 3d ed.], Addison-Wesley, Boston, 170 (2002). Interface: "A class can have abstract (or pure virtual) methods and nonabstract methods. A class in which all methods were declared as abstract (or pure virtual) would correspond to the Java idea of an interface.“Budd, T. [An Introduction to Object-Oriented Programming, 3d ed.], Addison-Wesley, Boston, 170 (2002). We implement LabVIEW interfaces as abstract classes (never instantiated, by policy) with all "pure virtual methods" (in LabVIEW meaning we have implementations that do nothing). The key advantages we derive from using interfaces are source code isolation and the ability to do design by contract. Some of the many cases where we use interfaces are in the Factory Method Pattern and the State Pattern.
-
I have to admit I'm not a big fan of the source files approach, although for certain use cases it might be fine. See this thread here (it's old, but the key points are there) for a discussion of the topic (http://lavag.org/topic/14212-how-to-call-a-plug-in-object-from-an-executable/page__fromsearch__1). My biggest (not only) concern (name collisions resulting in multiple files is another) is that it just seems weird to install source files (even without diagrams) as part of an installed application. Maybe this is more common than I realize?
-
I worked with National Instruments Requiremements Gateway (NIRG) a few years back and found it worked well. My sense was that I think I would have had to work with it more frequently to get really comfortable with it, but it had some good features for traceability and some helpful graphical views (although it takes a bit to become proficient with these). It worked as promised. (Well, I did find one bug but NI quickly provided a fix for that.) Of course, as Becky says, you need your requirements somewhere else first. We had some requirements in DOORS (integrates well with NIRG) but this was an expensive tool and we didn't all have licenses. Putting requirements in Word (we had lots of these) or Excel (by themselves) is less desirable since these are not databases and it can be prohibitively difficult to track a requirement between revisions of the document. Warning: Software Engineering Theory coming! In the end, we abandoned the use of NIRG mostly because we abandoned DOORS and Word in favor of SysML. SysML offers two major advantages: 1) A requirement is a first-class entity (true also in DOORS, although depending on how you use DOORS headings can be as well). It is easy to see, edit, move a requirement on a diagram (or diagrams). It is easy to create and link, for instance, a test case (at least in the tool we use). Moreover, SysML allows us to specify the type of relationship. DOORS links were of only one type (although they do specify a direction). 2) Much more importantly, DOORS, Word, and so on are document-centric approaches. When a requirement or set of requirements from one document apply in another document, you either have to copy the requirements to the new document (so that you have to maintain two copies) or you have to create a reference to the original document, forcing the reader to open the additional document to read the requirements. (Karl E. Wiegers devotes a chapter to this here: http://www.amazon.com/More-About-Software-Requirements-Practical/dp/0735622671/ref=sr_1_1?ie=UTF8&qid=1345135697&sr=8-1&keywords=wiegers+more+about+software+requirements. He concludes that there is "no perfect solution" -- see p. 116 -- but prefers links to duplication.) Anyway, SysML is database-centric, like DOORS, but, unlike DOORS, in SysML the fundamental unit for version control is a package within a project file (where a project file functions like a document), so that we can define which packages we want to include in a project. Since we can include a package in multiple projects, we can include a particular set of requirements (or anything else) in multiple projects while maintaining only one version of the package. (We can also create instances of a particular requirement in multiple views.) For these reasons (as well as the improved ability to work as a team on the projects), we have found the model-based approach for SysML far superior to the document-centric approach. Note that we are not working in regulated industries, so I have not explored whether our tools or the use thereof would be compliant with the strictest standards, nor are we tracing to code modules as NIRG allows you to do. Paul
-
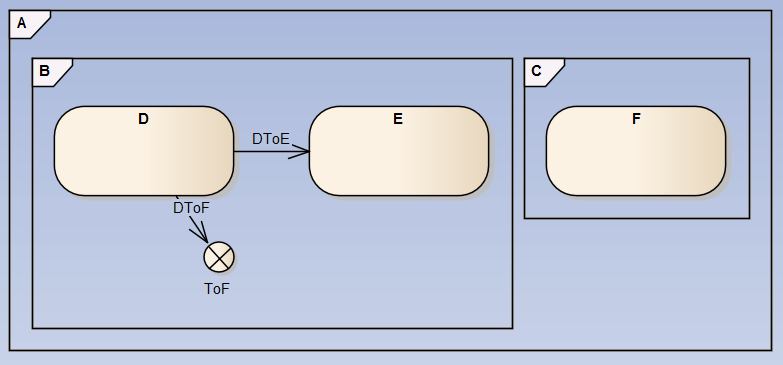
Background: We have implemented many hierarchical state machines of varying complexity using the State Pattern. This was the subject of my NI Week presentation, and the method we show is, I think, quite straightforward. The present implementations we have do not have explicit entry and exit methods defined on the states; we opted to defer consideration of this in favor of a very straightforward implementation in which we select the desired behaviors on each transition. This does, however, result in a certain amount of repetition on a few transitions, so in the process of preparing the presentation I looked more carefully into what it would take to implement entry and exit behaviors as explicit entry and exit methods on the states. I address this in the Advanced Topics of the presentation. Daklu asked, "As an aside, suppose you had an action assigned to the D to F transition. When is the right time for that action to execute?" I address this in my presentation. The UML Superstructure Specification states that the order should be: Exit source state (lowest-to-highest) Execute actions for transition Enter target state (highest-to-lowest) I had independently worked out a solution that differed from this somewhat, since we can group the first and third steps inside a single atomic transition method. Samek (see reference linked above--again, this has been a very helpful reference) suggests the following arrangement as more practical (pp. 78-81): Execute actions for transition Exit source state (lowest-to-highest) Enter target state (highest-to-lowest), where the latter two are in a single atomic method. (I think it doesn't matter much whether the first bullet occurs before or after the other two; it just matters that the exit and entry actions can be atomic.) Anyway, the larger point I am trying to make in this thread is that determining the Least Common Ancestor of the main source and main target states is necessary for this (rather basic and quite valid) use case, and any elegant solution to find the LCA requires reflection.
-
[This is a follow-up on my presentation TS 8237 "State Pattern Implementation for Scalable Control Systems" delivered at NI Week.] Consider the following state machine: . Consider also an implementation of this using the State Pattern, where the different states are objects. Now examine the desired behavior for exit and entry actions for the transitions D to E and D to F. D to E: We expect to execute the exit method for D and the entry method for E (but not the entry or exit methods on the parents). D to F: We expect to execute the exit methods for D and B and the entry methods for C and F (but not the entry and exit methods on A). In other words, when executing exit and entry actions we want to stop at the least common ancestor (LCA) of the main source and main target states. [There is a good description of this here: http://www.amazon.co...&keywords=samek.] It is possible to do this in an inelegant fashion by adding specific code for the purpose in various places, but I'm pretty sure the only elegant solution for this (i.e., within the framework) requires reflection (not yet available in LabVIEW). Comments?

-
Ah! I see, OK! Good point!
-
NSV's are publish-subscribe, so multiple Windows machines can still access the same SVs and therefore communicate with the cRIO. (We actually do this all the time.) (Of course, the host PC has to be running. This could be an important consideration depedning on the use case. For us that is easy to ensure.)
-
I'm not sure what is going wrong, but I suggest you consider deploying the NSVs on Windows.... I don't think there is any advantage to deploying them on the cRIO anyway.
-
Yes, you answered your question correctly! In fact, we originally tried to create configuration objects, but 1) Objects don't have front panel representations. (OK, it is possible to make friend XControls for this purpose, but we did not want to go there.) 2) We could still put the clusters inside objects (and in a few legacy cases we still do that) but we found it didn't buy us anything--it just added complexity. So we just stick with clusters.* *For completeness: Note that clusters don't have the same version handling mechanism classes do. In practice, that has not been a concern for us in any way. We only deploy our applications at one site, though. If we had many versions in many places I could envision that we might need some way to convert configurations between versions, although even then I expect that wouldn't be much of a problem, provided the released versions were reasonably stable in the first place.)
-
The following is our approach, with which we are quite happy: We define configuration elements (usually in a cluster). Each configuration element addresses one setting or group of settings, appears on one page of the properties/configuration dialog, and stores in one XML file. We add configuration elements as attributes (class private data) where needed. (Note that a class may contain multiple configurable elements, and a particular configurable element may appear in multiple classes.) We have a common configuration editor code and initialization (init) code (to read the files). Our applications allow editing of the configuration only when a component is in a Standby or Off State. Each component has an init method (based on common code) that reads and applies the configuration when we transition from Standby to Disabled State. (The init method for the larger model consists of the set of init methods for the individual classes.) Hence each object has its own configuration.
-
LVClasses in LVLibs: how to organize things
PaulL replied to drjdpowell's topic in Object-Oriented Programming
Well, I still think the best solution is, in fact, to use project libraries (.lvlib files) where appropriate. Yes, one does have to think about which classes to put in a library to avoid loading unneeded classes, etc., but I suggest that means the solution is to use libraries carefully, rather than not to use them. Namespacing is important!